在歷經PC行情反覆,ARM陣營異軍突起之後,COMPUTEX 2024成爲了一個很有意思的節點,前有Windows on ARM和高通驍龍X Elite蓄勢待發,後有AMD啓勢搶佔市場份額,英特爾當下在消費級市場已經開始面對來自多方面壓力。好在帕特·基辛格在掌舵之時很早意識到了這一點,四年五個節點製程計劃和引入臺積電代工,讓英特爾重新開啓追擊的態勢,第二代酷睿Ultra,Lunar Lake正是在這樣的環境下誕生。
如果說第一代酷睿Ultra Meteor Lake是對CPU架構的大改,那麼Lunar Lake幾乎是推倒重來的,無論是P-Core的Lion Cove,E-Core的Skymont,與獨顯架構看齊的Xe2核顯,NPU 4,臺積電N3B+N6工藝,還是首次將LPDDR5X內存放在封裝內,所有的設計與以往大相徑庭。

Lunar Lake也被英特爾寄予厚望,比如它繼續英特爾推進AI PC輕薄型筆記本的AI性能表現,特別是集成的NPU 4達到了48 TOPS,是Meteor Lake NPU 3的11.5 TOPS的4倍左右。
在這個看中AI性能、續航、媒體性能的大趨勢下,Lunar Lake應該可以有什麼樣期待,它會對今年第三季度以後發佈的筆記本產生什麼樣的影響,筆記本電腦格局還會發生什麼改變?趁着技術解禁,不妨讓我們一窺Lunar Lake的架構。
爲了方便閱讀,我們將Lunar Lake的大致變化和特點放在第一章節,如果你時間有限,看完第一章概覽即可,如果感興趣,文章其餘的章節可以給你提供更詳盡的細節。

概覽:英特爾設計,臺積電立功
Lunar Lake的設計和製造是一個很有意思的組合,英特爾讓芯片設計團隊自主選擇他們覺得最好的生產方案,放飛的Lunar Lake選擇了分別使用臺積電N3B和N6工藝生產兩個模塊(Tile),即臺積電N3B負責計算模塊(Compute tile),臺積電N6負責平臺控制模塊(Platform Controller tile)。
同時放飛的還有超線程技術,是的,Lunar Lake不支持超線程,多少個核心即爲多少個線程,第9代酷睿的時候,英特爾也曾經嘗試在桌面端取消了Core i9-9900K之外的超線程技術,達到產品區分的目的。但在Lunar Lake上,設計團隊主要出於執行效率和能耗考慮而取消,英特爾認爲能耗翻倍換取多30%線程性能增加,遠沒有提升E-Core性能來得直接,這裏後續我們會進行詳細說明。

Lunar Lake將擁有4個P-Core,4個E-Core,共計8線程,即4P+4E/8T。在計算核心架構上,P-Core和E-Core都發生了巨大的變化,其中P-Core採用了全新的Lion Cove架構,E-Core則使用了Skymont架構,不僅代替了原來的Cresmont,還放棄了Core Ultra上出現的LP E-Core設計。重點是,E-Core之間也不像P-Core那般使用Ring總線連接,而是讓其具備LP E-Core的特性,並配合臺積電N3B製程效率和新架構設計下每週期指令數(Instructions Per Cycle,IPC)提升,從而獲得顯著的增益效果。
連接計算模塊(Compute tile)和平臺控制模塊(Platform Controller tile)的部分則使用了英特爾引以爲傲的Foveros封裝技術,並將兩個模塊連接到一個基礎模塊(Base tile)上,完成更高效和更節能的連接方式。
不僅如此,內存也首次直接被封裝到Lunar Lake中,在CPU上半部分包含了2個64bit 32GB LPDDR5X內存,總共128bit 32GB,這樣的變化意味着未來輕薄本的用戶不再能自行添加內存。

在AI方面,英特爾啓用了全新的NPU 4,在INT 8上的性能可以達到48 TOPS,以實現微軟的Copilot+ AI PC標準,從而滿足未來的AI PC性能。但Lunar Lake也並非只有NPU提供AI計算性能,核顯Arc Xe2-LPG也帶來了更強的AI算力,總計達到120 TOPS,但全負荷運行耗電量會增多,在輕薄本使用過程中,通常會根據實際負載進行取捨。

與此同時,英特爾與微軟合作將英特爾硬件線程調度器(Intel Thread Director,ITD)進行了增強,旨在與微軟Windows Copilot以及其他AI助手進行鍼對性優化,考慮到Lunar Lake推出時間在今年第三季度,現在硬件和軟件廠商已經在優化和調用上着手準備起來了。
英特爾硬件線程調度器(Intel Thread Director,ITD)承擔着更重要的電源管理和能耗控制工作。因爲在過去幾年中,AMD在PC領域的施壓只是其次,更大的壓力其實來自於Arm、蘋果M系列芯片對傳統筆記本體驗和續航的顛覆,在COMPUTEX 2024上,Arm CEO雷內·哈斯(Rene Haas)已經放出豪言,目標是在五年之內拿下Windows PC市場超過50%的份額。同時高通驍龍X Elite已經開始實裝微軟Surface Pro 11,未來更多品牌的高通驍龍X Elite筆記本也開始蓄勢待發。

這時候Lunar Lake的電源管理和能耗表現就顯得非常重要了。在分配策略上,由於流程比Meteor Lake更爲直接,Lunar Lake只需要調用E-Core和P-Core即可,即最初任務都會先分配給E-Core,在根據需要的時候分配給E-Core和P-Core。同時系統也會對某些特定任務指定內核工作,配合Windows 11實現以最小功耗完成最高效率的目的。

例如當視頻會議結束進入視頻保存環節,這個過程無需P-Core參與,E-Core就能在後臺實現,從而達到能耗節省的目的,這個操作需要操作系統、應用、調度器共同完成。
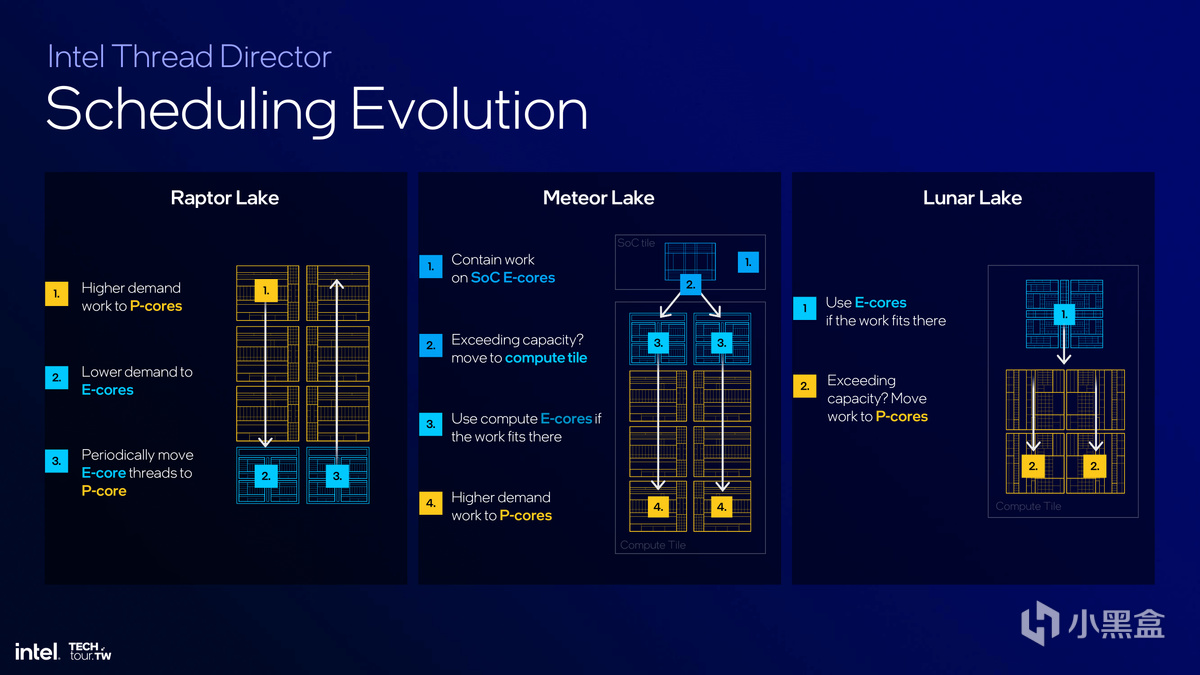
Lunar Lake還擁有着一套電源管理系統(Internal Power Managemant),用來平衡效率、性能模式,與前面提到的硬件性能調度器ITD一起,共同實現能效平衡。同時在調度中,英特爾也進一步增加應用場景的顆粒度,通過AI調度提示和Windows 11跨內核IP調度完成更靈活多變的工作負載。

可以這麼理解,Lunar Lake是英特爾架構設計團隊與臺積電製造工藝合作下產生的一款令人興奮的產品,在接下來幾個章節中,我們會逐一對P-Core、E-Core、NPU、Are Xe2-LPG核顯進行逐一介紹。
P-Core:進擊的Lion Cove
P-Core的性能提升來自於全新的Lion Cove架構做出的重大改變。Lion Cove使用了全新的多層數據緩存設計,包含1個具備4週期延遲的48KB L0D緩存,1個9週期延遲的192KB L1D緩存,以及1個17週期的3MB L2緩存。這意味着在9個時鐘週期內,可以獲得L0D+L1D的240KB緩存。相比上一代Meteor Lake P-Core的Redwood Cove架構,9個時鐘週期內只能有48KB緩存。不僅如此,數據轉換後備緩衝區(DTLB)也進行了修訂,其深度從96頁增加到128頁,以提高其命中率。
與此同時,英特爾還增加了第三個地址生成單元(Address Generation Unit,AGU)以進一步提升存儲性能。負載單元和存儲單元管道數量均達到3個,在英特爾大部分架構中,負載單元通常多於存儲單元。
可以看到英特爾正在嘗試在CPU設計中投入更多的緩存設計來解決性能問題,特別是隨着CPU系統設計愈發複雜,緩存子系統有必要跟進增加,以保持其正常運行,從而成爲提升性能與執行效率的關鍵。

P-Core Lion Cove架構還採用了一種全新的前端方式來處理指令,包括預測塊的大小增加了8倍,擁有更廣泛的提取和更大的解碼帶寬,Uops緩存容量(Micro-operations,存儲微操作,Uops)和讀取帶寬大幅增加,UOP隊列(UOP queue)也對等增加,從而提高了整體執行吞吐量。
在執行過程中,Lion Cove的亂序引擎被劃分成了整數(INT)和矢量(VEC)兩個域,均具備獨立的重命名和調度功能。這種劃分方式能讓每個域可以獨立增長,並且對於特定領域的工作負載有助於減少功耗。
亂序引擎從6寬度分配/重命名(Allocation/Rename)增加到8寬度,由於處理器流水線中,指令的執行是一個多階段的過程,當一條指令完成了其所需的所有操作後,它就會從亂序引擎中退役(Retirement),以便爲下一條指令騰出空間,從而實現更高的並行度和效率。這裏英特爾將8寬度退役增加到12寬度,確保更多的指令可以在同一時間段內完成執行並離開亂序引擎,進一步提高了處理器的性能。
同時深度指令窗口(Deep Instruction Window)從512條增加到576條,執行端口從12增加到18個。這些變化使得流水線更加穩定和靈活。

然後是整數ALU單元(Arithmetic Logic Unit)。Lion Cove整數ALU單元的數量從5個增加到了6個,跳轉單元(Jump Units)從2個增加到了3個,移位單元(Shift Units)也從2個增加到了3個。乘法單元從64x64提升到了64,數量從1個增加到了3個。
更厲害的是,P-Core數據庫做了重大調整,英特爾將其稱爲芯片設計的重大變革,甚至會深遠影響到未來的迭代。這屬於分區(Partition)定義上的重大變化,在以往,英特爾把分區(Partition)切分得很零散,每個小分區(small partition)可能包含成千上萬個單元(cell),這導致了分區之間的關聯性較弱,以及分區內部的單元數量過多,可能會增加設計的複雜性和管理難度。
在Lion Cove中,英特爾將設計重心放在創建更大規模的分區(Partition)。每個大模塊分區都包含數十萬甚至數百萬個單元(Cell),這時候,處理器設計中的物理邊界減少了。換句話說,現在每個分區內部的連接線路,都代表着一個物理邊界。
這樣的大模塊設計的工具和理念引入後,物理邊界減少帶來利用率和硅片面積效率的提升,設計團隊可以更輕鬆地進行處理器的集成整合,降低了整體的設計成本和複雜度。不僅如此,減少了物理邊界也使得處理器設計的迭代變得更加容易。因爲模塊之間的耦合性降低,修改或調整一個模塊不太可能對其他模塊產生重大影響,這使得設計團隊可以更快地進行迭代和優化,從而讓未來的迭代升級變得更爲容易。

Lion Cove在架構上的變化讓Lunar Lake P-Core的IPC(Instructions Per Cycle,每個時鐘週期指令數)提升幅度達到了30%,動態電源效率提升了20%。換而言之,在不增加核心面的前提下,就能獲得更好的效能平衡,可以讓英特爾在現有的物理約束條件下獲得更好的性能表現。

不僅如此,Lion Cove的功耗管理也引入了人工智能(AI)調節控制器用來代替原來的固定檔位調節。AI能夠以自適應方式動態響應實際的實時操作條件,以實現更高的持續性能。以往的固定檔位調節只能以100MHz進行調整,現在更細的時鐘粒度可以做到16.67MHz爲一個間隔,從而獲得更好的功耗管理。
從直面上看,Lion Cove所打造的P-Core無疑有明顯的進步,無論是緩存系統還是功耗管理設計,可以在不提升頻率的前提下,給IPC帶來了顯著提升。但不提升頻率使得這一代P-Core增加超線程技術的收益遞減,同時耗電量會增加。正因爲如此,我們在Lunar Lake上會暫別超線程技術。

E-Core:比上一代P-Core還強的Skymont
按照英特爾的說法,Skymont架構打造的E-Core能夠與上一代P-Core性能持平,甚至在部分工作場景下戰鬥力更勝一籌。
同樣,Skymont也使用了全新的設計。包括在一個時鐘週期內同時解碼並執行9條指令,也就是9寬解碼,比上一代E-Core的Crestmont架構增加了50%。通常而已,解碼階段的寬度越大,處理器的性能越高,可以更有效地利用其資源,加快指令的執行速度。
9寬解碼是由一套更大的微操作隊列提供支持的。每個微操作代表處理器內部的一條指令或操作,微操作隊列的容量代表可以同時存儲和處理的微操作數量。Skymont的9寬解碼微操作隊列數量達到了96個條目,對比之下,上一代Crestmont只有64個條目。與此同時,英特爾還使用了Nanocode方案讓每個解碼集羣獲得更多的微碼並行性,使其能夠更有效地執行指令流。

然後是亂序執行引擎。Skymont的亂序執行發生了重大變化,分派給執行單元的指令數量增加至8條,即分配寬度增加至8寬,退役(Retirement)擴展至16寬,意味着可以最多16條指令並行完成執行。
這樣的設計讓Skymont可以更有效地同時發佈和執行多個指令,可以不依賴先前的指令結果執行後續指令,從而減少由指令之間的依賴關係導致的延遲。

此外,Skymont將在排隊和緩衝能力方面將重新排序緩衝區加深至416個條目,而之前的版本爲256個。此外,物理寄存器文件(PRF)和預約站(Reservation Station)的大小也已經增加,這使得核心能夠處理更多正在執行的指令,從而提高指令執行的並行性。

與此同時,Skymont的用於向執行單元發送指令的分派端口(Dispatch Ports)增加到26個,其中有8個用於整數算術邏輯(ALU),3個用於跳轉操作,3個用於每週期加載操作,確保資源可以靈活分配。
還有4個128bit的FP(Floating Point,浮點數)和SIMD(Single Instruction Multiple Data,單指令多數據流)向量操作,使得每秒浮點操作次數翻倍,並減少了浮點操作的延遲。
英特爾還重新設計了緩存系統,一組4MB L2緩存提供給4個核心共享,L2緩存帶寬增加到每個週期128B,進而降低訪問延遲,提升數據吞吐量。

這裏英特爾展示了架構修改後的效果。其中功耗效率得到了明顯提升,單線程性能提升1.7倍的情況下,功耗僅爲Meteor Lake LP E-Core的三分之一。
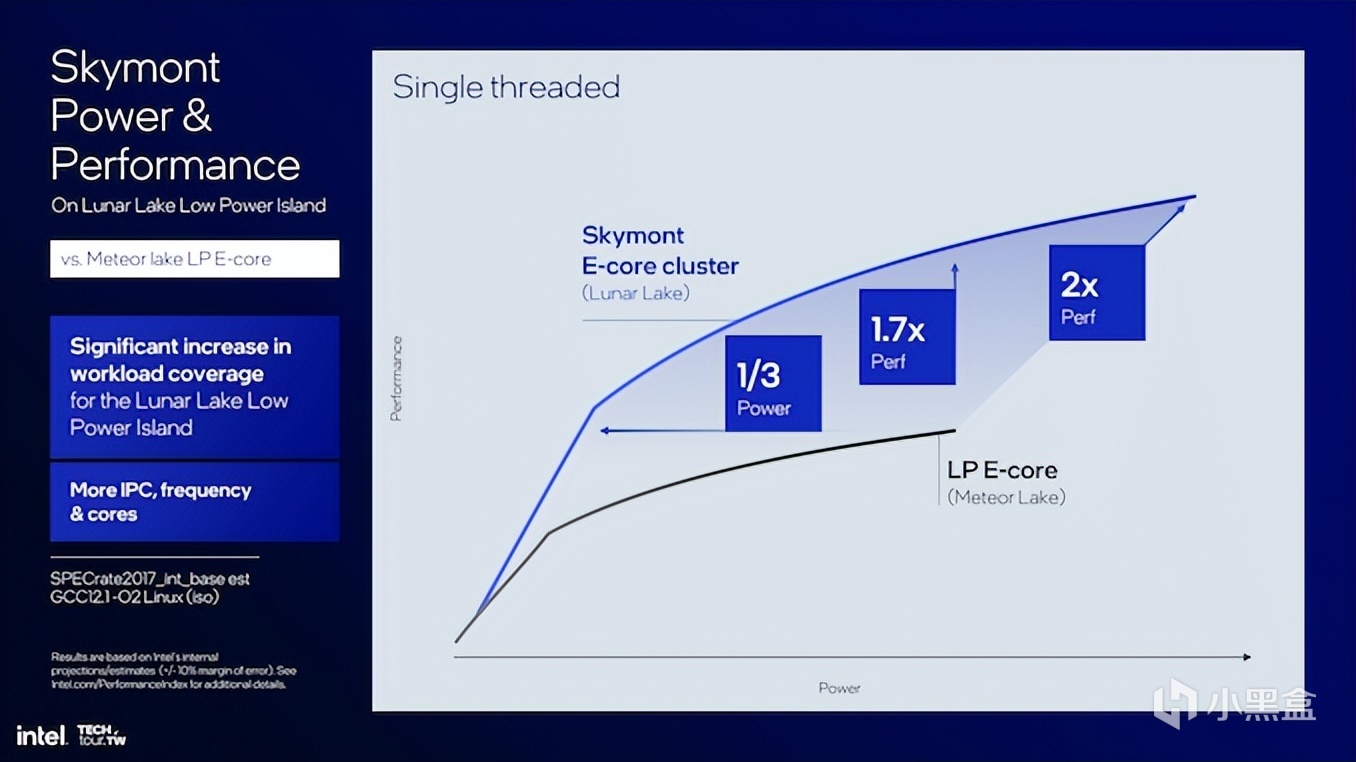
如果用Skymont E-Core集羣與Meteor Lake以及LP E-Core同時比較,功耗相同的情況下,多線程性能提升2.9倍。
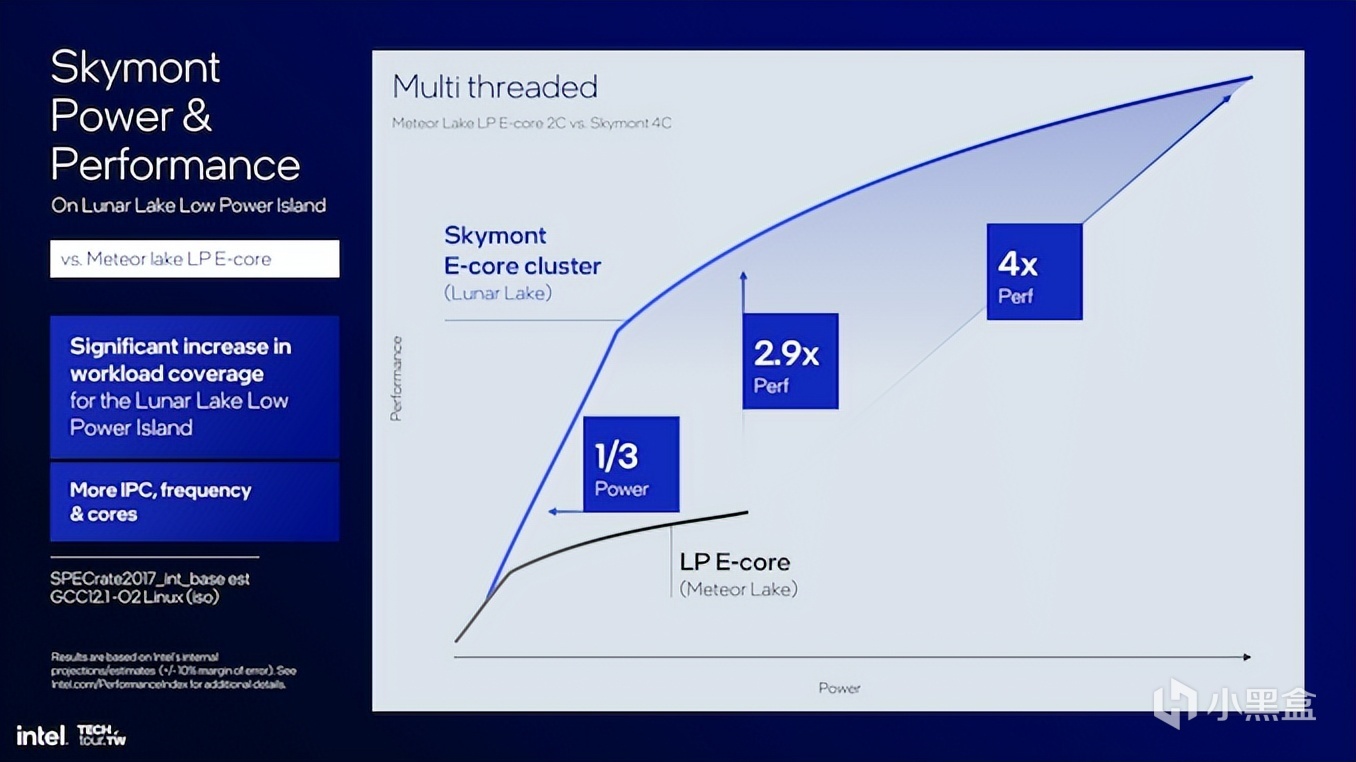
這樣的設計無論移動端還是桌面端都奏效。Skymont E-Core配置非常靈活,不僅可以在移動端方案中降低能耗,也可以在桌面端提升多線程吞吐量。
如果與上一代的Raptor Cove P-Core相比,Skymont E-Core的單線程工作負載中,整數和浮點計算性能提高了2%,但功耗和發熱與之前相同,實打實的這一代E-Core打上一代P-Core。
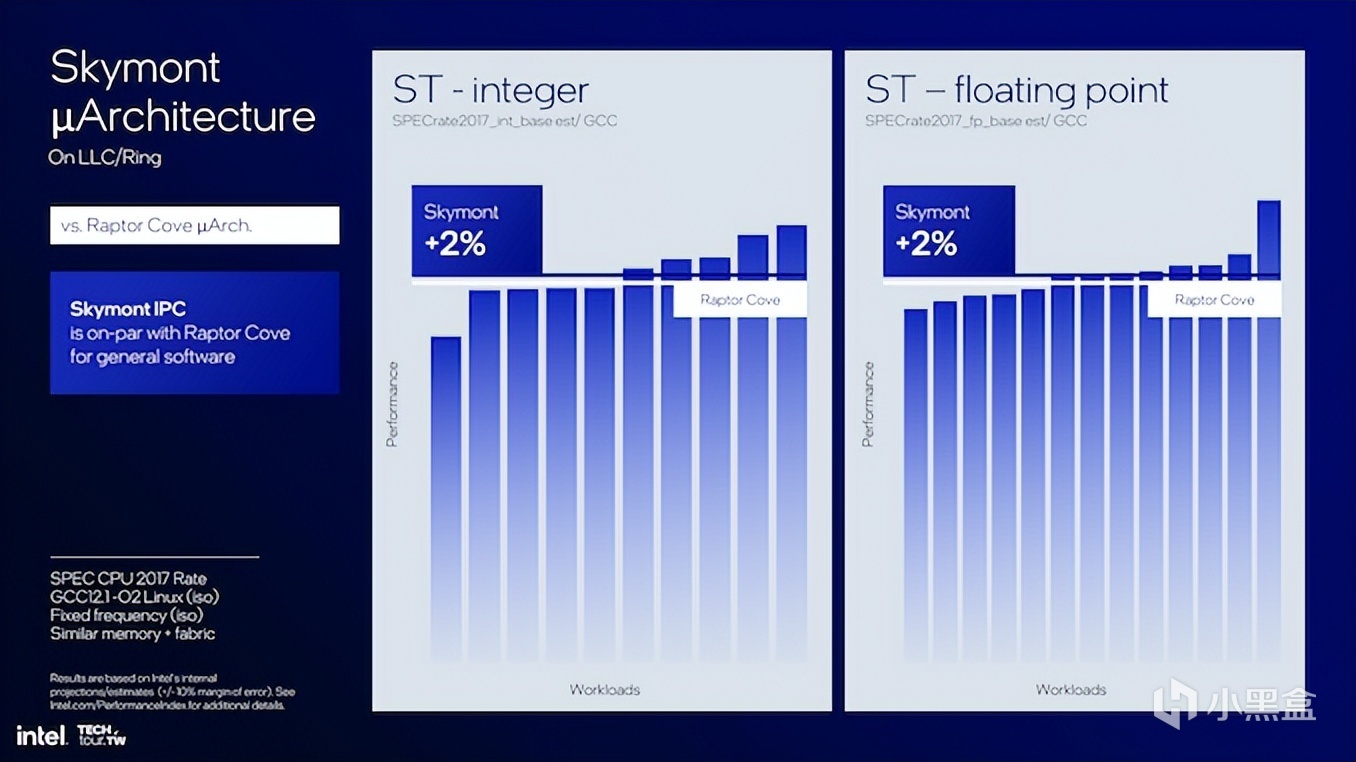
Skymont架構的變化接下來移動端和桌面端升級都做好了鋪墊,特別是解碼、執行、內存子系統和功耗效率的明顯提升,以及更高的IPC收益,都給後續的產品提升提供了廣闊空間。

NPU 4:翻了4倍AI性能
NPU是英特爾近段時間推廣的重點。Lunar Lake上NPU也取得了明顯提升,因此取名NPU 4,性能相當於Meteor Lake NPU 3的4倍,達到48 TOPS。而NPU 4提升的重點在於相對NPU 3在神經處理能力、效率、頻率、功耗架構和引擎上的全面提升,進步也相當明顯。

NPU 4矢量性能本質上利用更多計算模塊來實現。新架構下,NPU 4支持INT 8每個週期2048個MAC(Multiply-Accumulate,乘法累加)計算,FP16每個週期1024個MAC計算,效率顯著提升。

同時NPU 4中的分層也有所增加。每個神經計算引擎中都嵌入了推理管道,包括MAC陣列和用於不同類型計算的專屬DSP(Digital Signal Processor),並且是爲多並行操作而構建的。針對矢量計算優化的SHAVE DSP在NPU 4中起到了至關重要的作用,讓NPU 4矢量計算性能相比NPU 3提升4倍,能夠處理更復雜的神經網絡。

不僅如此,NPU 4提升了時鐘頻率,並引入了一個新的節點,讓NPU 4在與NPU 3相同的功率下性能提升了1倍,峯值性能提升2倍。MAC陣列還具有更高效的數據轉換功能,能夠實現動態數據類型轉換、融合操作、輸出數據佈局,以最小的延遲實現數據流的最佳效果。

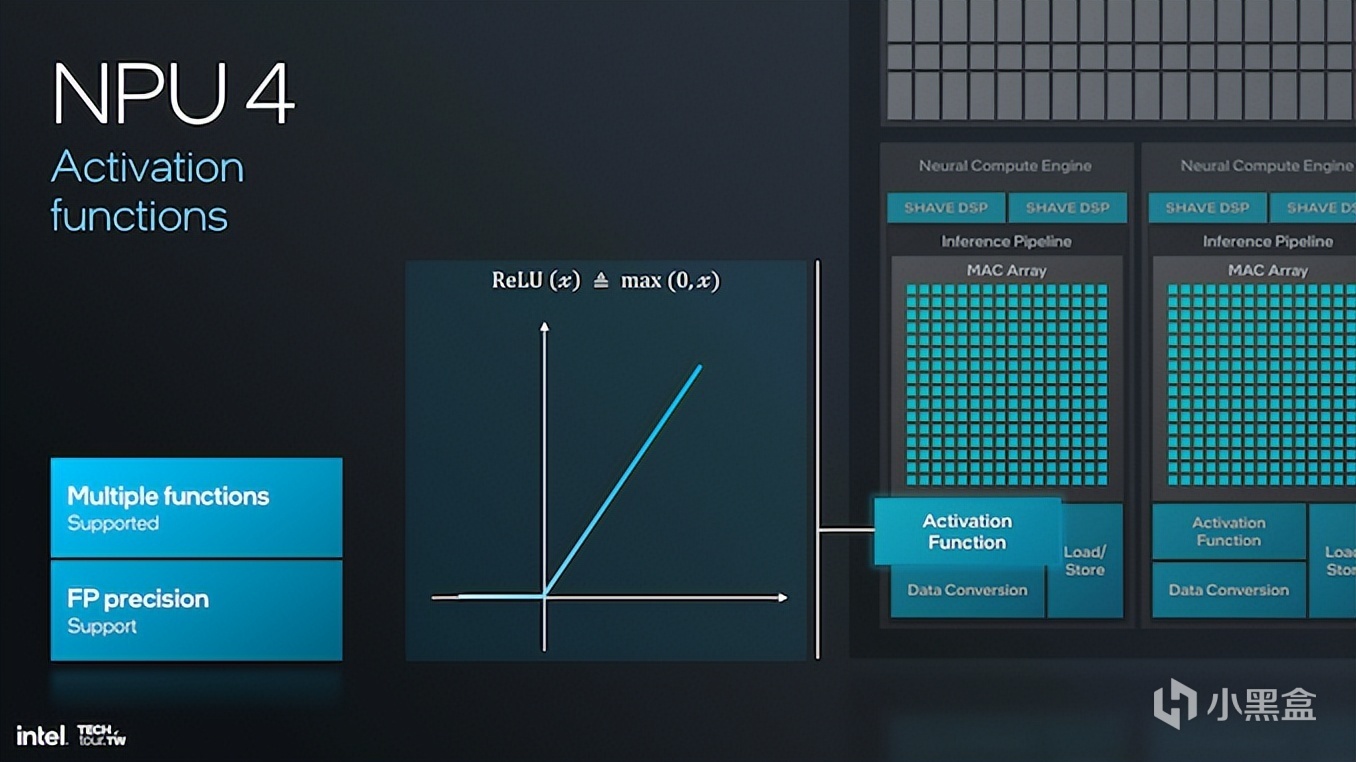
另外NPU 4的帶寬改進對於更大規模的模型和數據集處理更爲重要,特別是在基於Transformer語言模型應用中,NPU 4通過更高的數據流降低數據瓶頸進而實現平穩運行。NPU 4的DMA(Direct Memory Access,直接訪問內存)引擎帶寬翻倍,也讓其對大模型處理更爲有效。此外,NPU 4還加入了嵌入標記等功能,並支持激活函數,可選擇精度來實現不同的浮點計算,應對更復雜的神經網絡脫離模型。
由於MAC陣列可以在單個週期內處理2048個INT8和1024個FP16的乘法累加計算,並且寬度達到512bit,在一個時鐘週期內,NPU 4的矢量運算效率非常高。
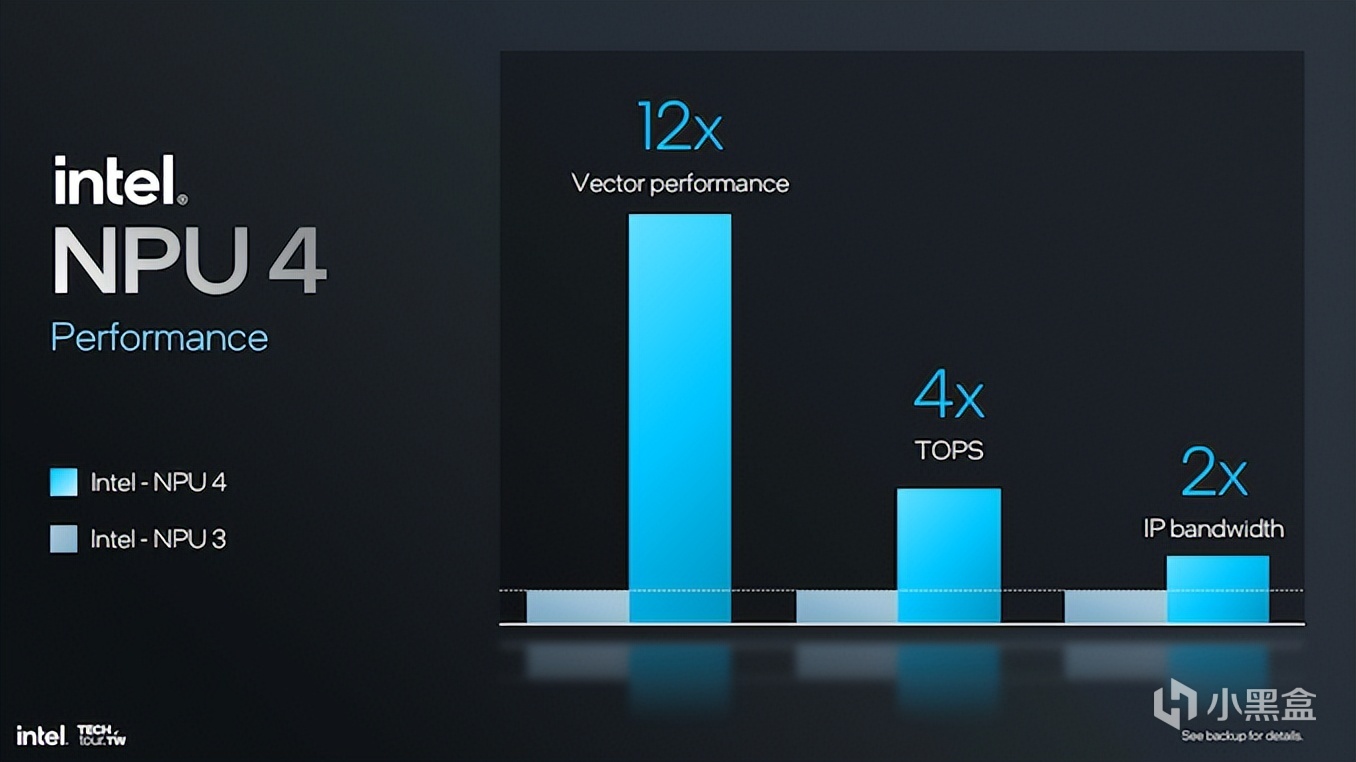
SHAVE DSP可以讓NPU 4帶來4倍的TOPS,12倍於NPU 3的矢量計算性能,也對於Transformer語言模型和大語言模型LLM而言非常有用。

基本上而言,NPU 4相對NPU 3性能提升是非常巨大的,包括12倍的矢量性能,IP帶寬提升2倍,也會成爲後續AI PC性能提升殺手鐧。
Xe2:新核顯,很能打
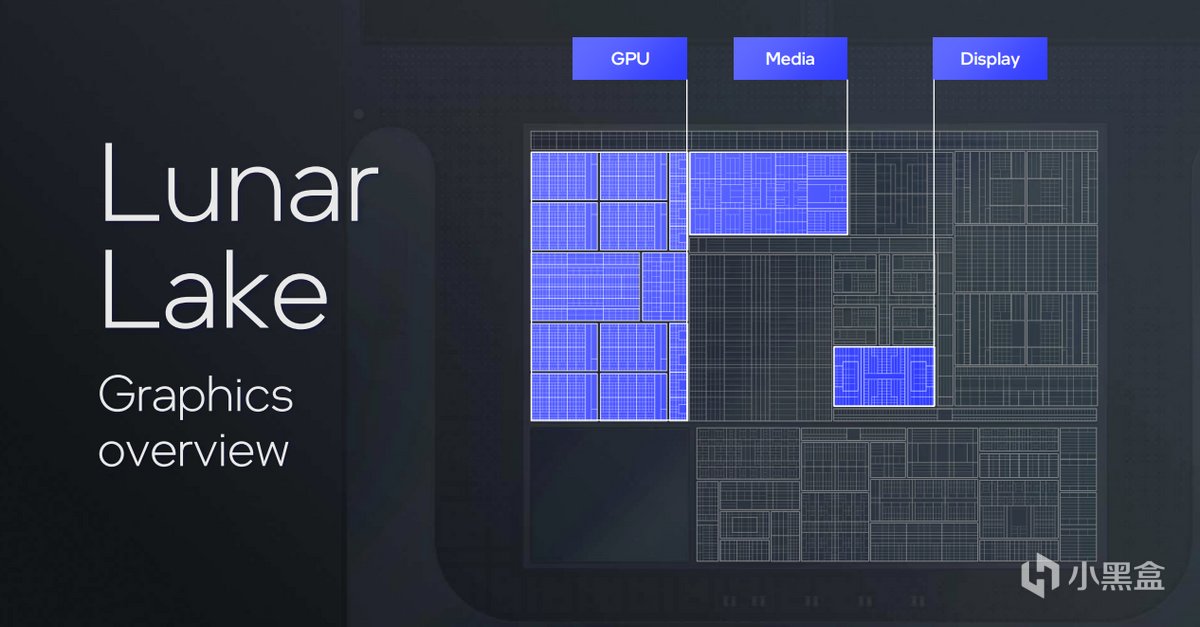
現在進入喜聞樂見的核顯環節。Lunar Lake所採用的Arc Xe2-LPG將會承擔遊戲、AI、媒體引擎工作等重要功能,也是提升PC體驗的重點模塊之一。由於之前提到的大規模分區設計緣故,GPU與媒體部分也不再是相互獨立的部分,而是與其他計算單元融合在一起。
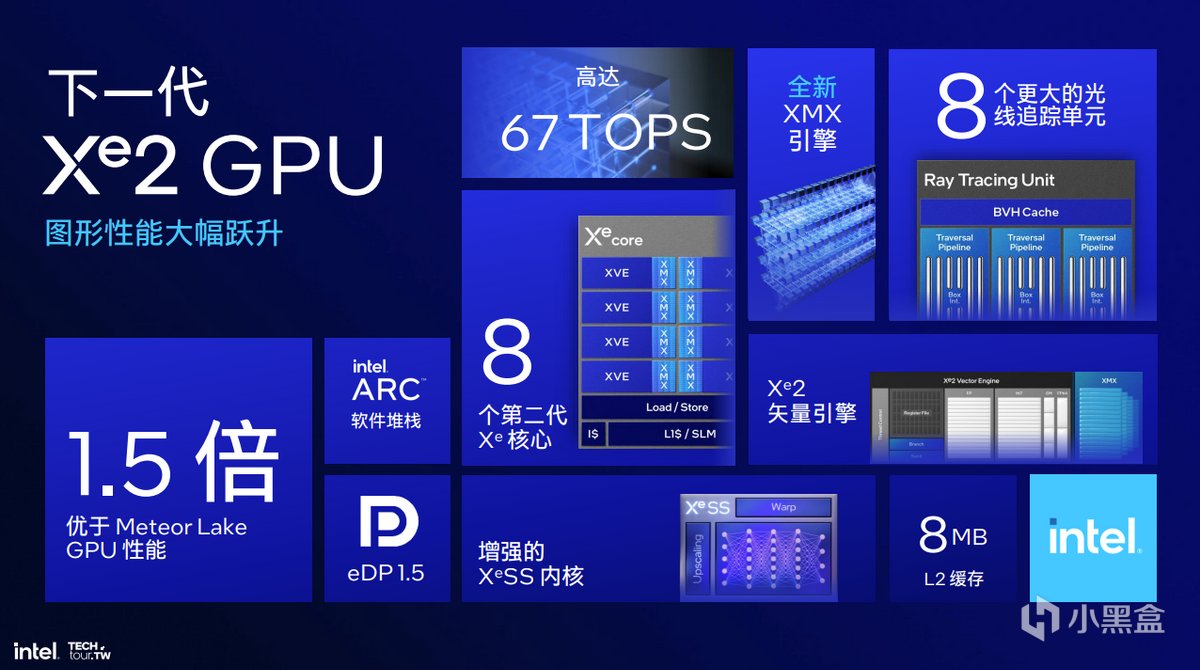
相比Meteor Lake的Xe-LPG,Xe2-LPG提供了67 TOPS的INT8性能和更多的光線追蹤單元,在圖形性能上相對Xe-LPG提升了1.5倍,並採用了全新的XMX引擎,增強的XeSS內核等等。

從核心數量上來看,Xe2-LPG依然包含了8個Xe核心,但是核心寬度增加,並提供了固定功能單元與其配對。
按照計劃,Xe2架構將來也會應用到下一代Arc GPU Battlemage設計中,包括加入XVE矢量引擎、更高效的XMX引擎等。XMX矩陣單元同樣作爲MAC乘法累加計算使用,原本是獨顯Arc GPU的獨佔部分,現在也應用到Xe2-LPG中,讓其具備類似於NVIDIA Tensor Core的AI推理性能,利用專屬的硬件提升遊戲中XeSS分辨率超採樣的效率。在此之前的Xe-LPG利用的是DP4a指令實現,效率自然是跟不上硬件的XMX矩陣的。

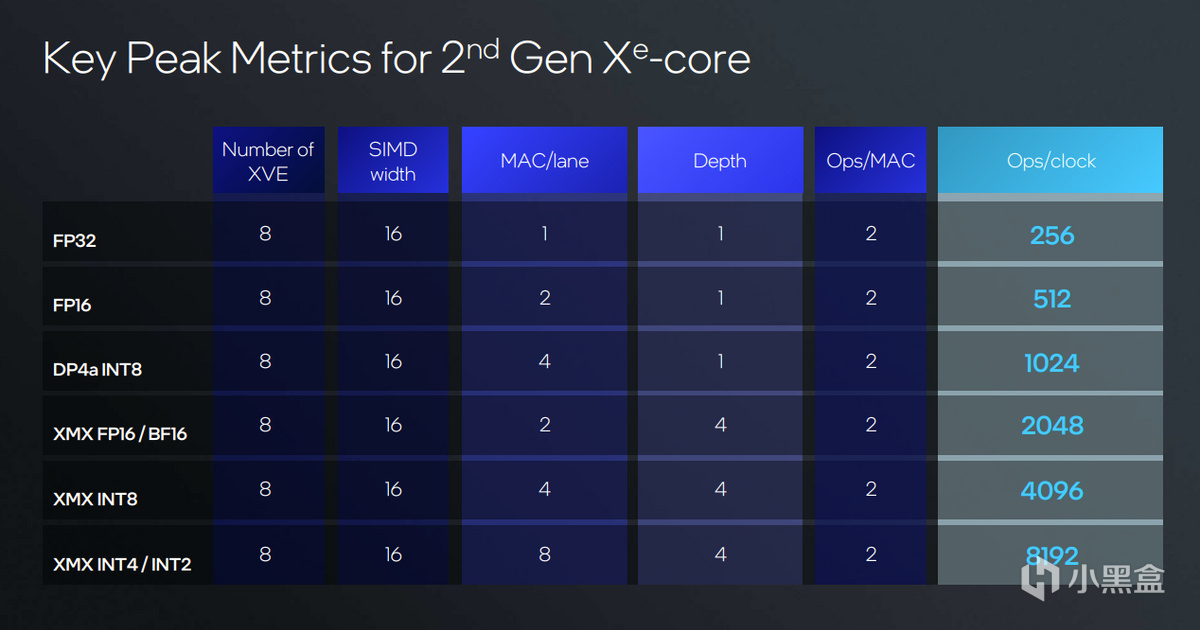
Xe2中的Xe核心包含8個512bit矢量引擎,相比上一代Xe的16個矢量引擎減少了一半,另一半用來放前面提到的2048bit XMX矩陣引擎來實現更好的運算支持。XMX矩陣引擎包含INT2、INT4、INT8以及FP16、BF16在內精度計算,並對FP64提供支持,從而實現對更豐富的推理模型的兼容。
由於XMX引擎支持Int8 4096 OPS/clock和FP16 2048 OPS/clock算力,遠高於XVE矢量引擎,在重負荷AI加速中,Xe2將扮演最重要的角色,成爲新一代Core Ultra 120 TOPS AI算力的核心角色。
繼續向下延伸就是構成Xe核心部分之一的渲染切片(Render Slice)。新的渲染切片引入了對於Excute Indirect的支持,原來3D任務需要CPU把指令給到GPU,然後由GPU去運算執行,而在Excute Indirect功能支持下,部分命令可以直接在GPU本地執行,不需要CPU一條條告訴GPU做什麼,而是GPU本身就具備Draw、Dispatch的能力,這些命令可以直接在GPU裏直接完成。此外,幾何單元改進達成頂點獲取(Vertex Fetch)吞吐提升3倍,mesh shading性能提升3倍。
此外,緩存部分的壓縮率和吞吐量也有了明顯提升,包括提升了L1 Cache的利用率,Sampling吞吐提升2倍,Pixel Color Cache提升1.33倍等等。
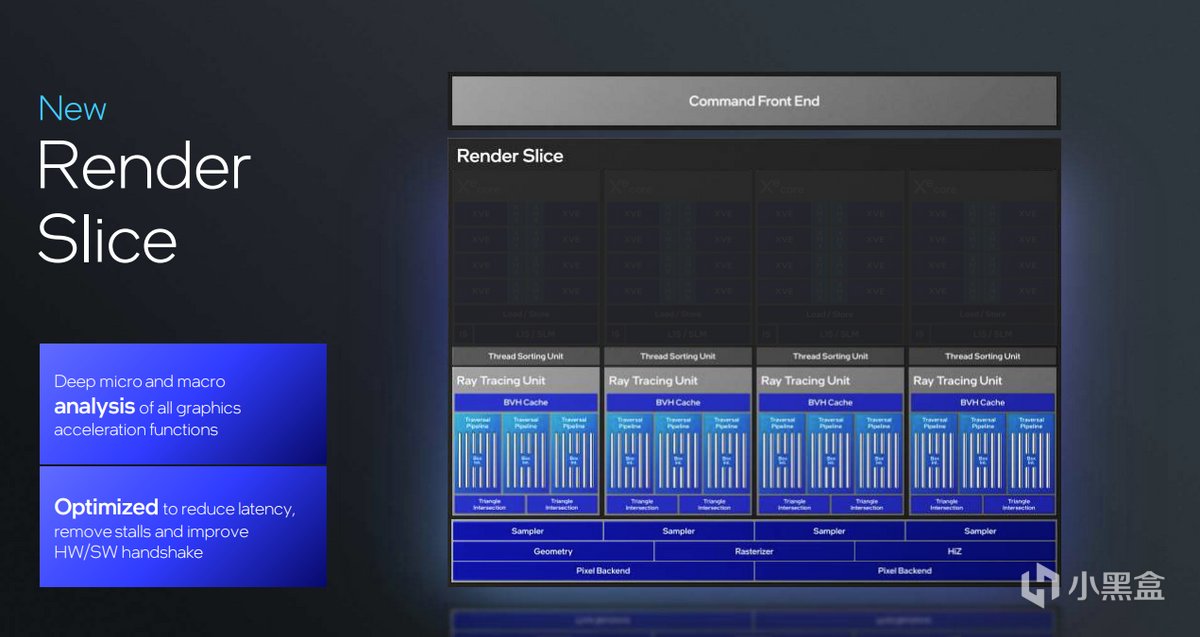
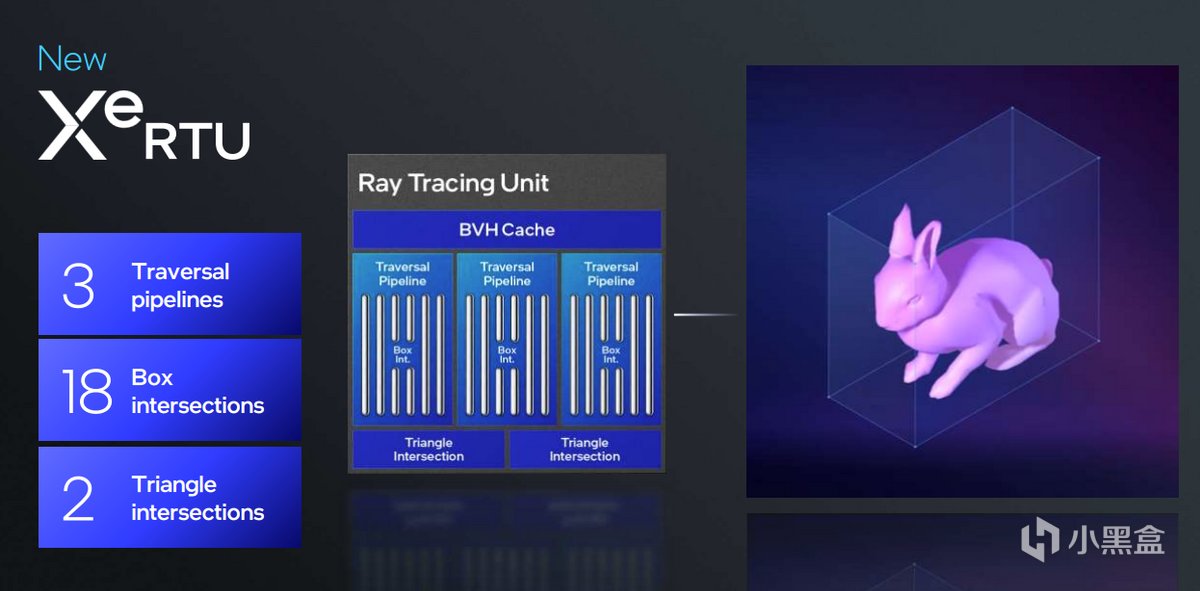
另外Xe RTU光線追蹤單元也進行了拓寬,提供三條遍歷通道,18 x Box intersections和2 x Triangle intersections計算,能夠更快速地進行盒子和三角形之間的交叉檢測。其中Box intersections是指單元在光線與盒子或者說包圍體積相交時所能處理的數量,Triangle intersection指代光線與三角形相交時所能處理的數量。
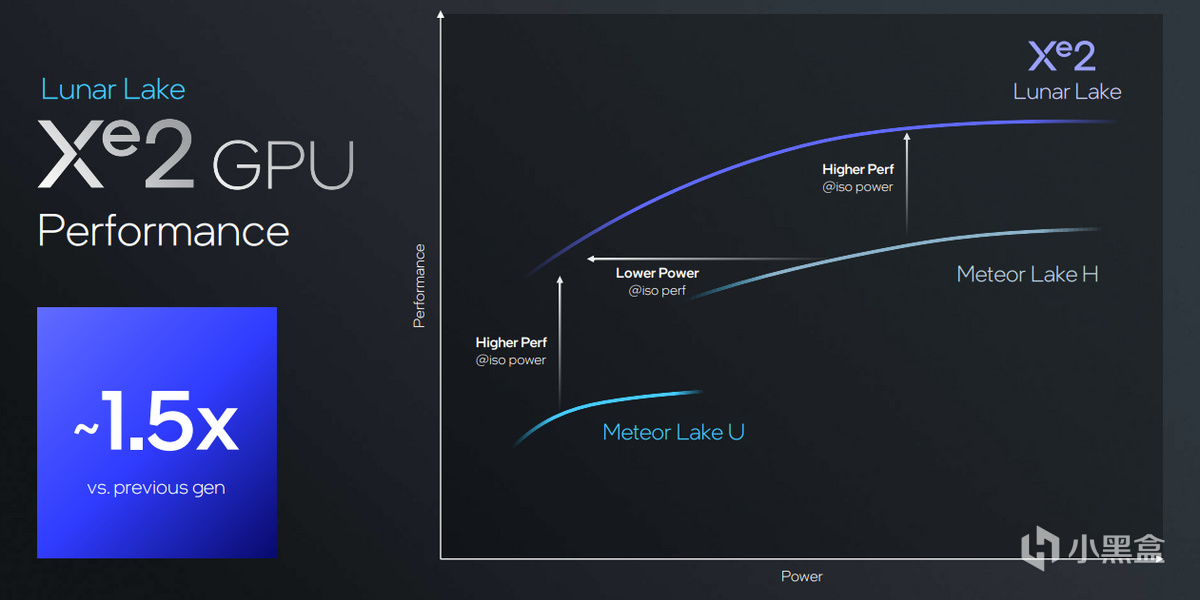
從整體上來看,Xe2-LPG總共包含2個渲染切片,8個Xe核心,64個矢量引擎,64個XMX引擎,8MB L2緩存,在性能提升上,比上一代已經很強的Meteor Lake綜合性能再提升1.5倍。
英特爾還強調Lunar Lake可以在15W功耗之下就能完全發揮Xe2核顯的性能,比Meteor Lake的25W優秀得多,這一代Meteor Lake用作遊戲掌機已經非常可以了,看來未來更多Windows遊戲掌機不再是夢。
Xe2-LPG提供了更靈活的輸出方式,顯示引擎可以相互組合實現多流傳輸,從而實現靈活的接口配置。並且英特爾還專門提供了一個eDP端口,爲高性能、高刷新率、高分辨率顯示器提供硬件支持。
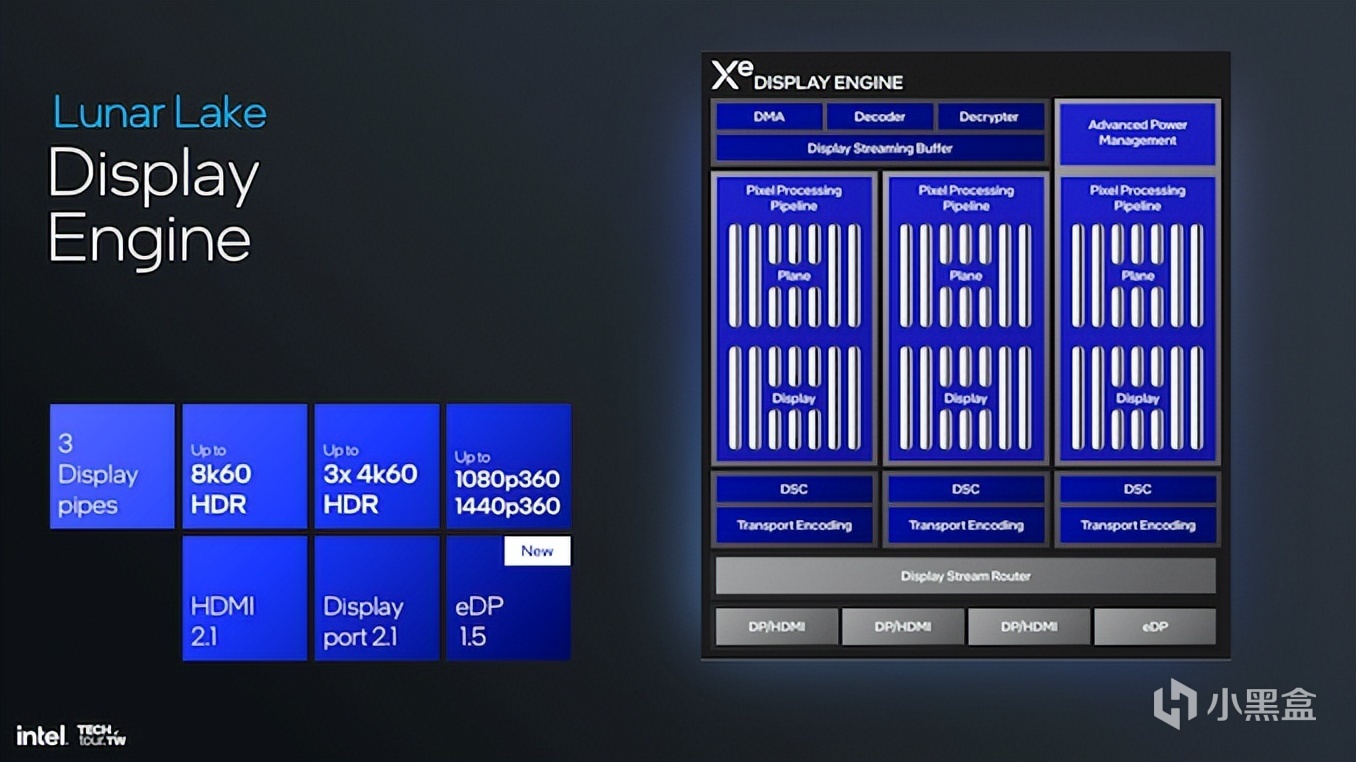

其中Xe2的eDisplayPort 1.5集成了自適應同步和選擇性更新機制的面板重放功能。這有助於通過僅刷新屏幕變化的部分而不是整個顯示器來降低功耗。這些創新不僅節省了能源,還通過減少顯示延遲和提高同步精度來改善視覺體驗。
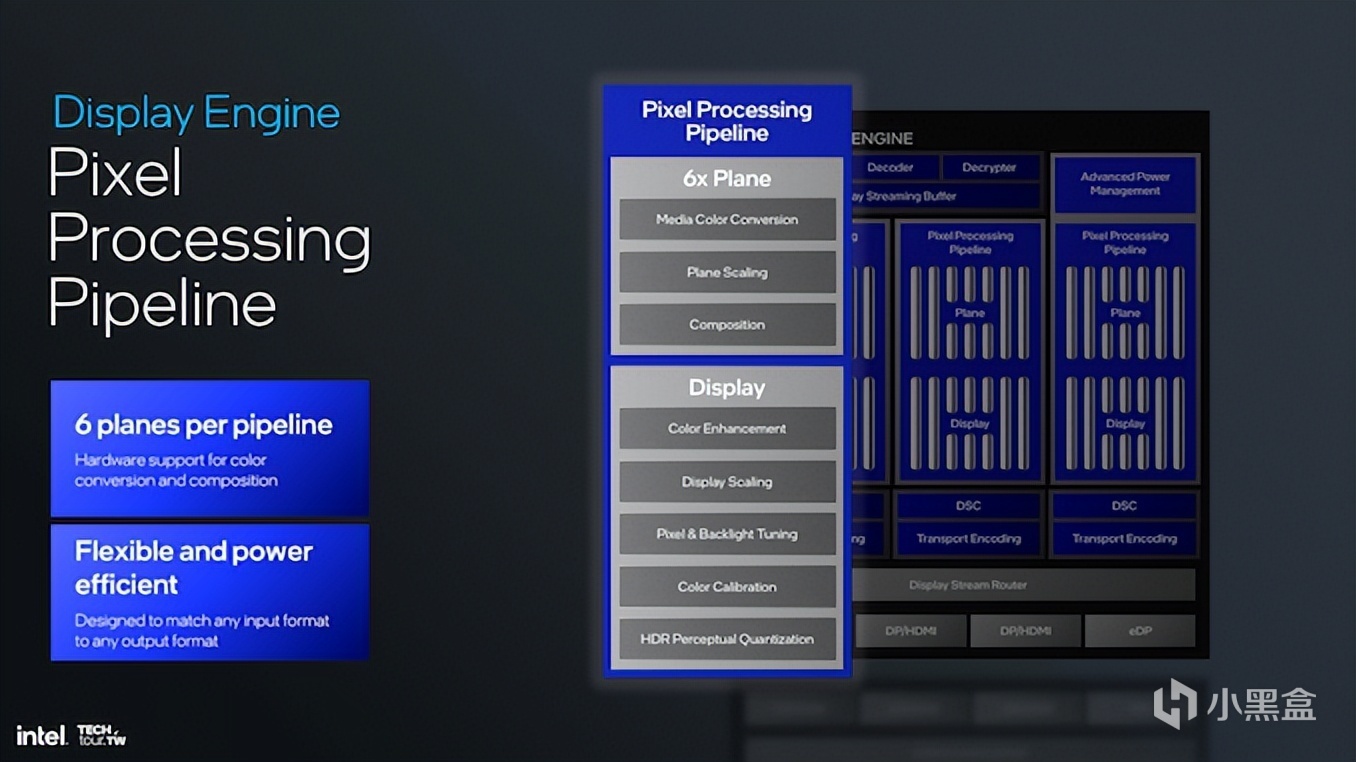
描繪像素處理管線是英特爾顯示引擎的基本基礎之一,爲高級顏色轉換和合成提供了每個管線六個平面。此外,它還集成了硬件支持的顏色增強、顯示縮放、像素調整和HDR感知量化,確保屏幕上的圖形色彩鮮豔準確。該設計相當靈活,高度節能,並且經過性能優化,能夠支持各種輸入和輸出格式,至少在理論上是如此。到目前爲止,英特爾尚未提供任何可量化的功耗指標、TDP或其他功耗元素參考。

對於壓縮和編碼,Xe2架構可以無損擴展3:1的顯示流壓縮,包括HDMI 2.1、DisplayPort 1.5的傳輸編碼協議,降低數據負載,並保持高分辨率輸出。

與此同時,Xe2還使用了VVC編解碼器(H.266),這相對AV1而言又是一個大的進步。可以將文件大小再壓縮10%,並支持全景視頻和自適應分辨率編碼,對於網絡視頻而言更爲重要。

從成體而言,Xe2不僅引入了更強的獨立GPU架構,並且提升了GPU和媒體引擎性能,從而確保Intel平臺筆記本在圖形性能,特別是媒體性能上的優勢。
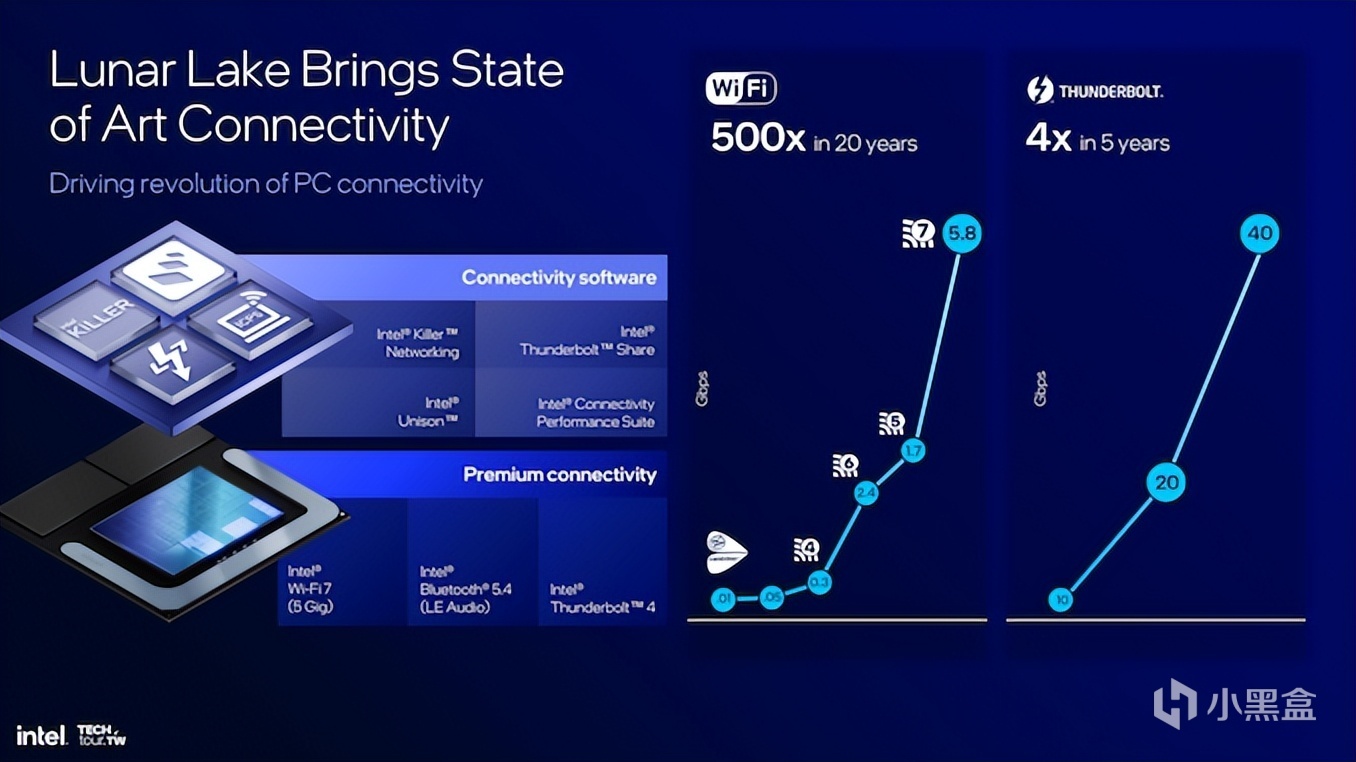
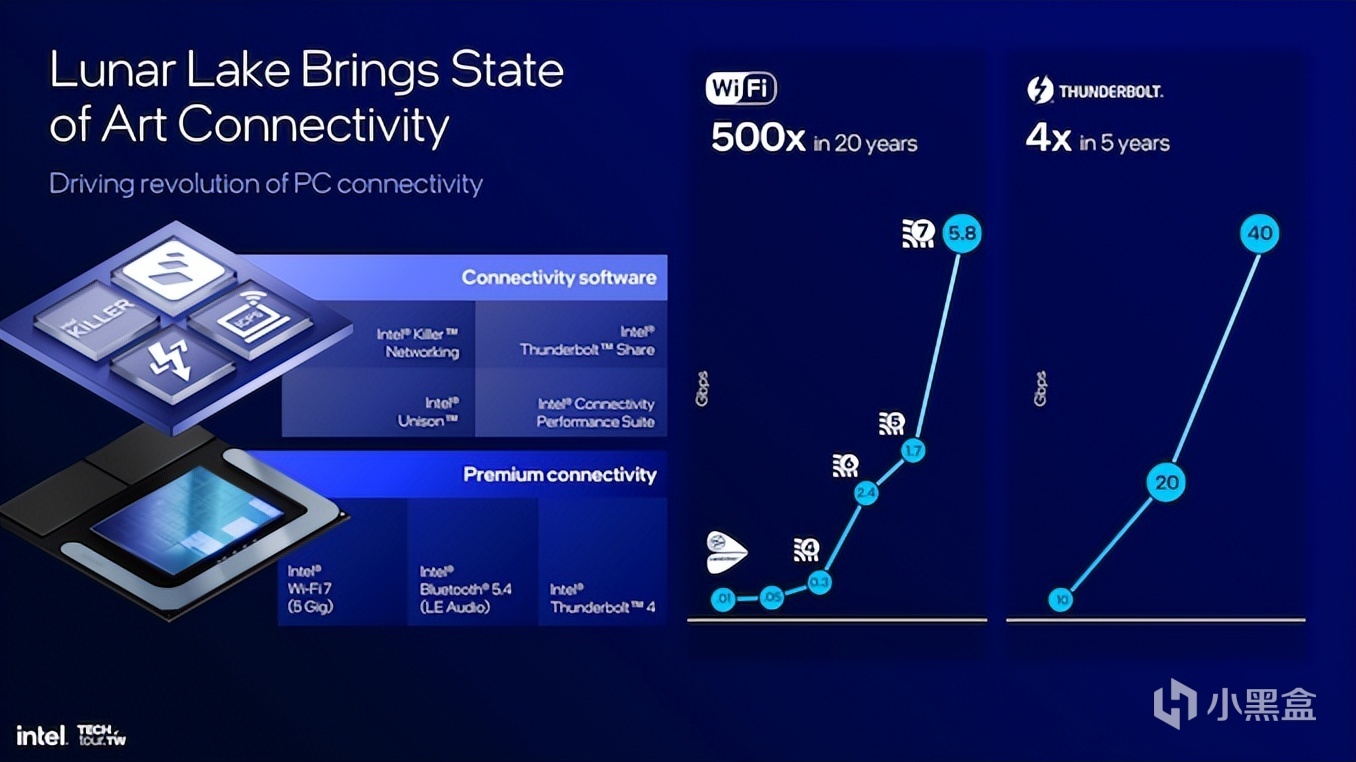
連接性:原生支持Wi-Fi 7
最後再來說說筆記本更爲看重的連接性。Lunar Lake的優勢在於支持原生的Thunderbolt 4連接,全新的Thunderbolt Share功能,並且將Wi-Fi 7的支持放到了芯片裏。
Thunderbolt 4表現比Thunderbolt 3更好毋庸置疑,重點在於提供了更好的連接性和顯示輸出帶寬,原生支持Thunderbolt 4的好處在於,現在Lunar Lake的筆記本最高可以獲得3個Thunderbolt接口,從而實現更靈活的筆記本擴展。
另外一個改進則是在應對視頻編輯、大文件傳輸時,Thunderbolt 4也可以有更快的響應速度,避免外接PSSD的時候出現響應之後的尷尬。

Thunderbolt Share則是近段時間提出來,並直接融合到Lunar Lake中的技術,它可以做到允許PC以60FPS的速度向其他PC共享屏幕、畫面、鍵盤、鼠標和存儲,是的,兩個筆記本互插Thunderbolt就可以傳輸文件了,這可是筆者年少時候的夢想。

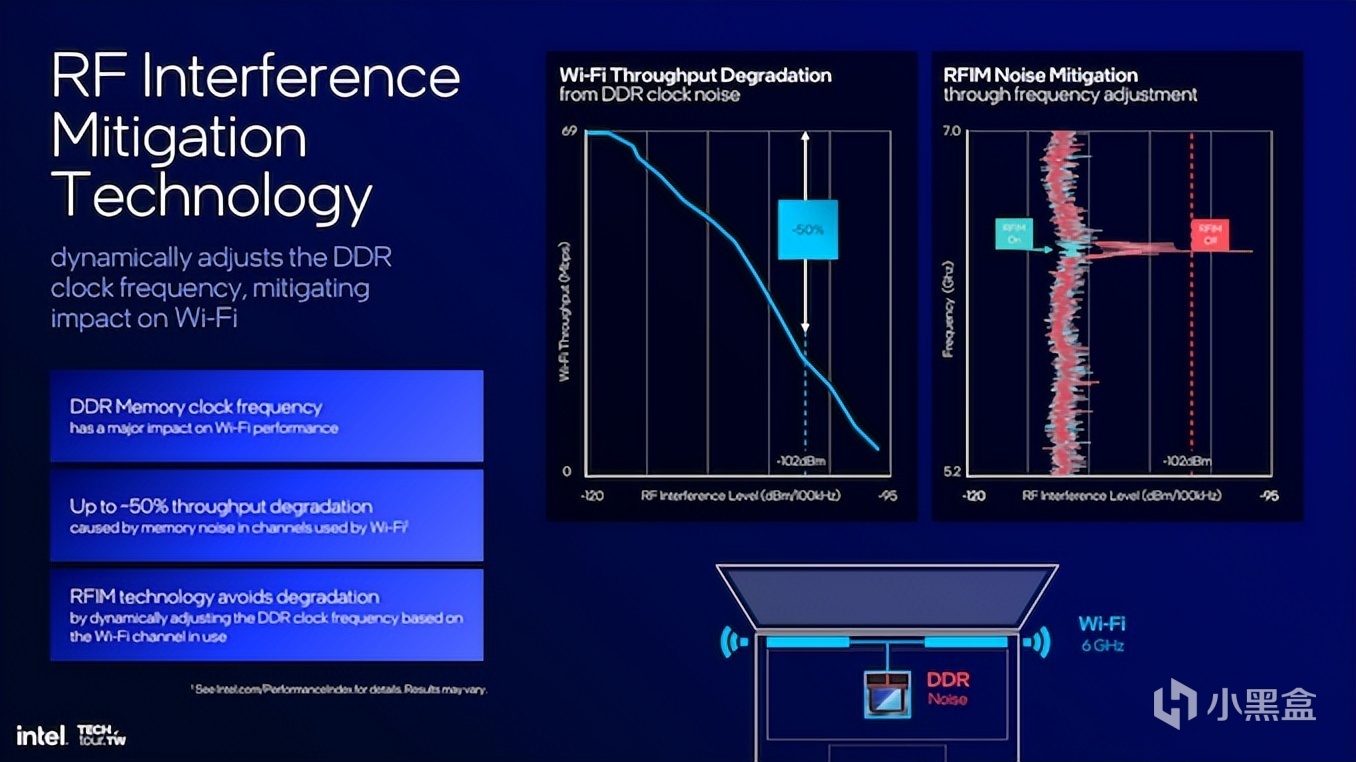
另外一個重要更新就是Wi-Fi 7也繼承到了Lunar Lake中。Wi-Fi 7的好處在於允許用戶處理寬帶密集型任務的時候,也可以提供穩定的無線連接。同時Wi-Fi 7還包括射頻干擾緩解、時鐘頻率自動調諧,提升無線網絡性能等功能。

英特爾表示還將與Meta合作,通過Wi-Fi 7增強VR體驗,讓VR也進入畫面無線傳輸、高可靠、低延遲的時代,這對於VR設備而言無疑是非常利好的。
其中重點還是在於原生支持,只要OEM廠商不過分閹割,下一代筆記本將會直接獲得Wi-Fi 7、Thunderbolt 4和Thunderbolt Share功能,從而提升筆記本的易用度。顯然下半年,家裏的路由器也可以考慮升級到Wi-Fi 7了。
寫在最後:Q3見英雄
無論是架構、製程工藝,Lunar Lake給與的變化近乎是翻天覆地的。這讓上市不到一年的Meteor Lake產品剛剛開賣就感到了壓力,顯然在競爭對手們壓力下,英特爾已然加速了更新步伐。
Lunar Lake是一款完全偏向於效能移動端的產品,它要以x86的身份對抗蘋果M系列、Arm、高通驍龍X的挑戰,即便Windows on ARM聽起來很美好,關鍵時刻某個軟件低效或者打不開,還是讓人頭疼不已,更不要提在輕薄本上開個Steam,暢快玩耍完整的遊戲列表。這份工作現在依然只有x86可以勝任。

Lunar Lake要做的就是在擁有很好兼容性前提下,續航、使用體驗與精簡指令集的新勢力們看齊,利用大刀闊斧的設計和不拘一格的選用最合適的臺積電製程,帶來了120 TOPS AI性能,更長的續航表現,更強的核顯,將會成爲第三季度以後發佈的筆記本新品的基本盤,32GB LPDDR5X和Xe2-LPG的廣泛應用都會讓輕薄本顯得更爲能打。
同時也讓我們更爲期待接下來面向桌面端Arrow Lake的戰鬥力,畢竟狠起來連自己產品都能敢大動刀的英特爾,完全是值得期待的。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















