前几天在看论文时看到这样一段话:We observe that a program often exhibits several different memory access patterns with different objects or at different phases, and they benefit from different Cache configurations. For example, sequential accesses fit a small directly mapped Cache with a Cache line size of multiple consecutive data elements, while accesses with good locality but large working sets fit a relatively large set-associative Cache.
这学期在上计算机体系结构课的时候老师提到过Cache的三种映射方式是direct mapping,set associative和fully associative。但是当时只是单纯记住了这个知识点,并没有理解,因此看上面这段话看的一头雾水,Cache里的数据存储形式是怎样的?不同的workload为什么会受益于不同的Cache映射方式?带着这些疑问,我去查了一些资料复习了一下顺便写了这篇笔记。
首先来明确一下Cache是什么,本文中的Cache指的是CPU高速缓存,是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。
其实在遥远的PC-AT/XT和286时代,CPU是没有Cache,直接访问内存的。那后来为什么要在CPU寄存器和内存之间设置一个CPU缓存呢?这是因为CPU访问寄存器和内存的延迟差距太大了。
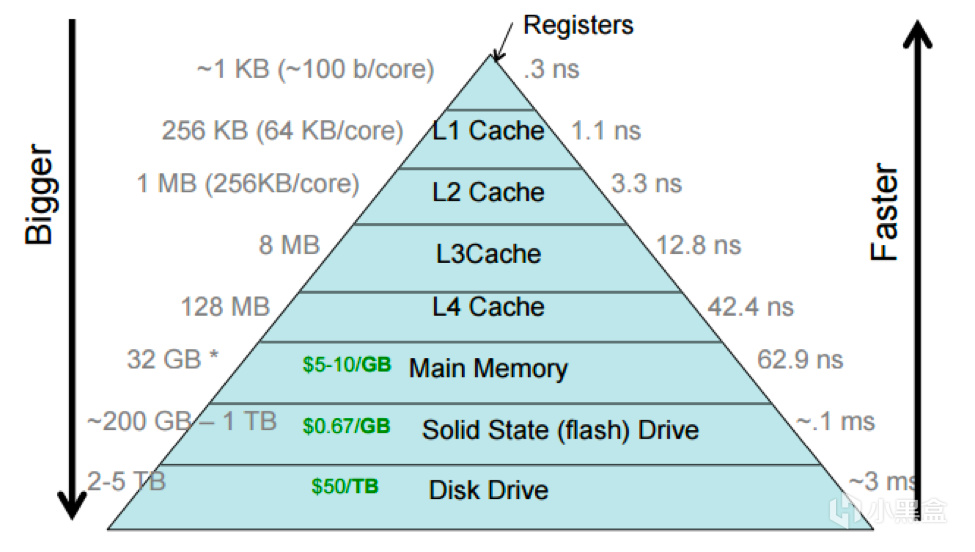
可以看到,访问寄存器的延迟约为0.3ns,而访问内存的延迟为62.9ns [2],两者之间差了数百倍,如果在Cache中没有我们想要的数据,那么CPU就需要等待漫长的load操作将数据从内存copy到Cache中。因此后来引入了多级Cache,等级越高,速度越慢,容量越大。在3级Cache的缓冲下,相邻Cache之间和Cache与memory之间的延迟差距也越来越小。让我们来看一下一个真实的案例——ARMv8-A架构的Cortex-A53处理器的Cache组织方式[3](Switch上的SoC——Tegra X1里就是四个Cortex-A57核心和四个Cortex-A53核心)。
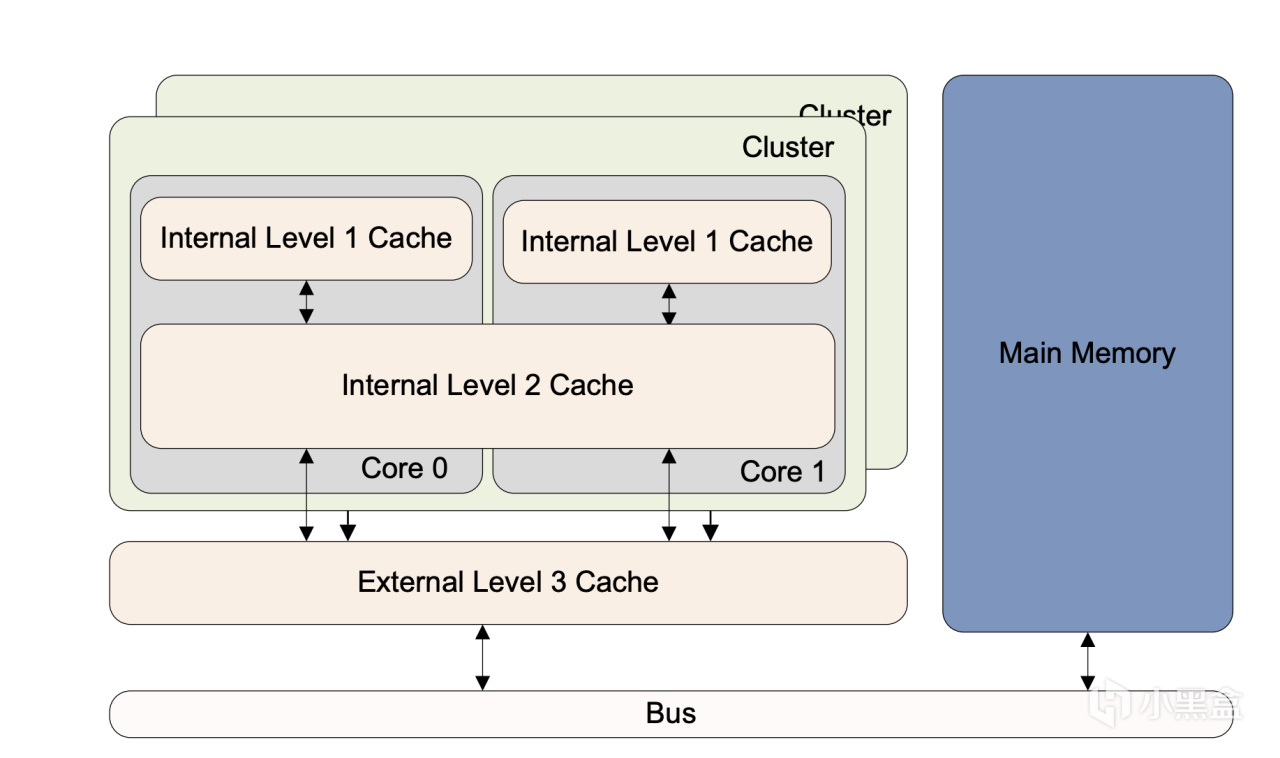
Cortex-A53 通常采用两级或多级Cache来实现,即小型 L1 指令缓存(instruction Cache)和数据缓存(data Cache)以及较大的统一 L2 缓存,该缓存在集群(cluster)中的多个内核(core)之间共享。此外,还可以有一个外部 L3 缓存在集群之间共享。CPU每个core都有一个私有的L1 Cache。一个cluster内的所有core共享一个L2 Cache,L2 Cache不区分指令和数据,都可以缓存。所有cluster之间共享L3 Cache。L3 Cache通过总线和主存相连。
现在我们只知道了Cache是什么,以及为什么要有Cache,那先来思考一个问题,如果是你来设计Cache,你会考虑哪些方面?
首先,Cache的大小应该是多大呢?里面的内容的组织形式是什么样的?第二,既然是作为CPU寄存器和内存之间的缓冲,那么肯定是存储内存中的数据,怎么存储和寻找呢?另外,既然是将内存中的数据复制到Cache中,一致性的问题也需要考虑,如果内存中的数据改变了但是Cache中的数据没有变,这时CPU再去Cache中访问数据就会访问到过时的数据。
天呐,居然要考虑这么多,那我们还是先来直接看看现在的Cache的工作方式是什么吧。
众所周知,在程序执行过程中,CPU会从内存中读取所需的数据到Cache中,而需要取哪些数据是根据所需数据的地址来决定的,一个地址对应一个字节,32位系统的地址空间就是2^32B即4GB,64位系统的地址空间就是2^64B(以目前的科技发展水平来说基本不可能用完)。一种比较直观的想法是,在Cache中存储一些访问过的数据作为缓存,CPU读取数据的时候先去Cache里面找,如果找不到就去内存里读,读到了顺便就放在Cache里。但是程序访问内存具有空间局部性的特征,短时间内访问的数据或是指令大概率会在一段连续的地址范围内,因此Cache和内存之间的传输却不是以单个字节进行的,而是一次取特定大小的连续内存。这个特定大小我们就称为cache line。它也是Cache的基本组成单位。cache line的大小在4-128字节,一般为64B。Cortex-A53的cache line大小就为64B。注意这里Cache的大小(或者说容量)不包括标记位(tag)和有效位(后面会提到)。
那么现在我们知道了Cache是由一个个cache line组成的,那Cache里肯定不能光存储数据,不然CPU靠什么来查找里面的数据呢?
我们假设这样一种情况:
- 64位系统(地址用64bits=8Bytes表示)
- 32GB=2^35B内存
- 1MB=2^20B L1 Cache
- cache line大小为64B
最早的时候Cache使用一种叫做direct mapping的组织方式。在这种模式下,64位地址被分为3个部分。首先,L1 Cache中一共有1MB/64B=2^20B/2^6B=2^14个cache line,因此我们需要14位 Index 来标记是哪一个cache line。找到了cache line之后,需要6位 Offset 来在64B的cache line中找出是哪一个Byte,还剩下64-6-14也就是44位我们将其作为标记位(tag)。可能有聪明的同学已经想到了,我们只需要两个部分也就是Index和Offset就可以定位Cache中一个cache line中的某一个字节了呀,为什么还要设置tag呢?
这是因为我们刚才一直讨论的是地址,这64位地址不仅仅是用来在Cache中寻找cache line的,它同时也是内存中的一个字节的唯一标识,也就是说,后14+6=20位相同但前44位不同的地址,尽管他们指向了Cache中同一条cache line中的同一个字节,但是它们标识的是内存中的不同位置!因此CPU拿着一条地址在Cache中寻找数据的时候需要tag来标识我们正在寻找的数据究竟是不是正确的,相应地,每条cache line中也必须包含tag。
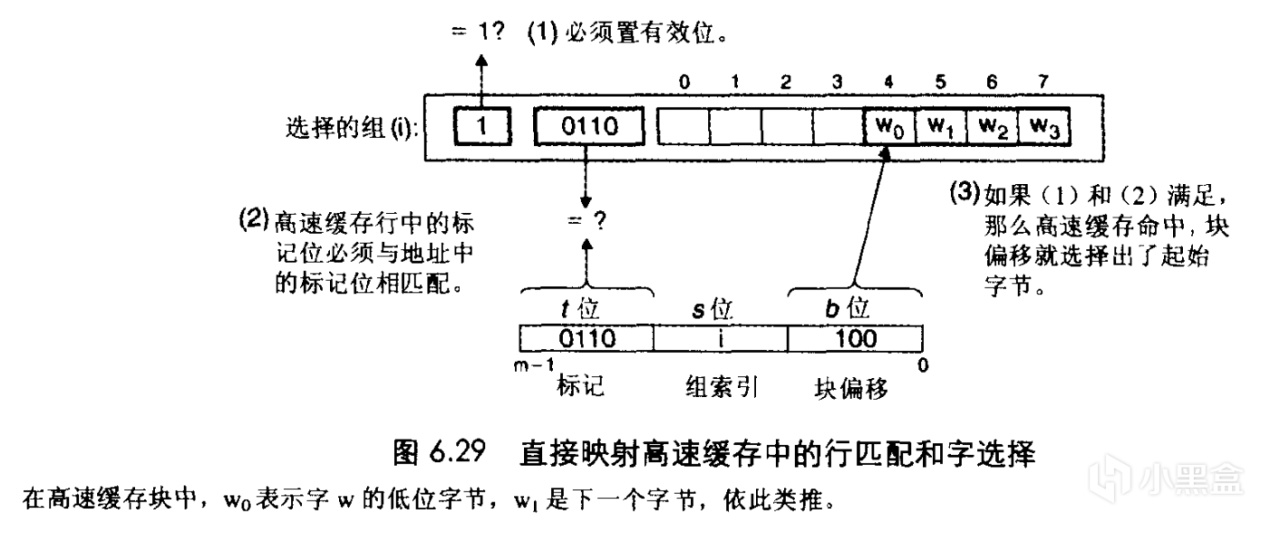
那这种方式有没有什么问题呢?设想一下如果我们需要并行访问内存的多处区域,如果这些区域正好包含了Index相同的内存地址,那么就会频繁地发生冲突,因为它们都要用到Cache中的同一条cache line,从而降低性能。这种现象叫做缓存颠簸(cache thrashing)
那么有没有方式可以减少这种冲突造成的影响呢?思考一下,在冲突发生时,我们可不可以通过某种方式减少这种内存的频繁换入换出?
答案是有的,现在的Cache普遍采用一种叫做Set Associative的方式进行组织,简单来说 n-way associative 就是把Cache进行了分组,使得每个组(Set)里面有n个cache line,这样在遇到Index相同但是tag不同的情况时就可以在一个组中同时存n个cache line,比如2-way associative就是下面这种形式,下面我们假设CPU为4-way associative
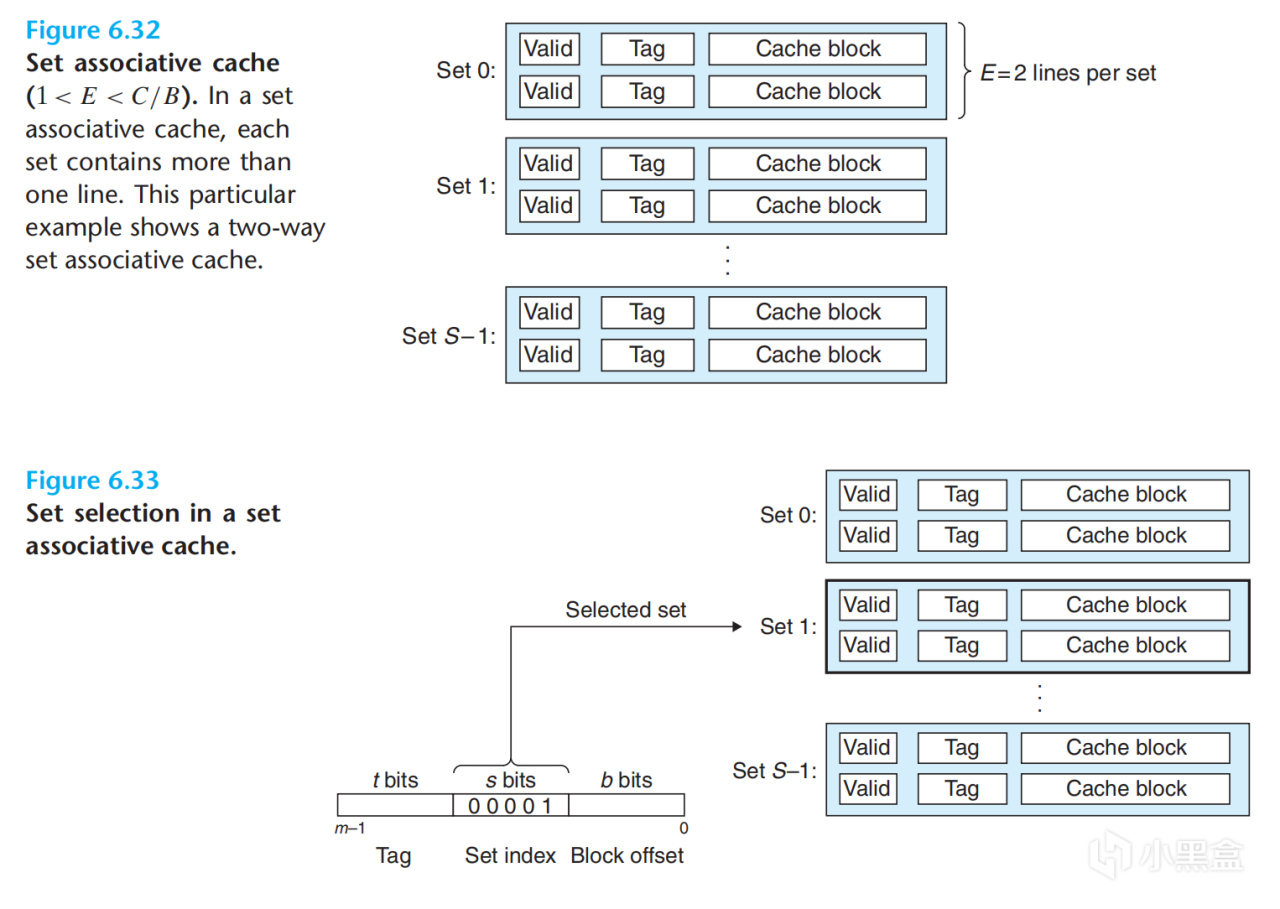
那我们现在看看在set associative的情况下如何寻找cache line,在L1 Cache中一共有2^14个cache line,而又因为是4-way associative,因此一共有2^14/2^2=2^12个组,也就是说我们需要12位Index来找到是哪个组。同时我们同样需要6位Offset来在64B的cache line中找出是哪一个Byte。
那64位的地址我们已经用掉了6+12=18位,剩下的46位我们将其作为标记位(tag)
CPU在访问Cache时,先根据index找到set,然后将组内的所有cache line对应的tag和地址中的tag部分对比,如果其中有相等的就说明缓存命中也就是找到了所需数据。
对比一下direct mapping和set associative,我们可以发现其实direct mapping也可以看做成set associative中set大小为1的情况。那有大胆的同学可能会想,如果把set大小增大,变成整个Cache会怎么样呢?这种情况我们就称为fully associative。
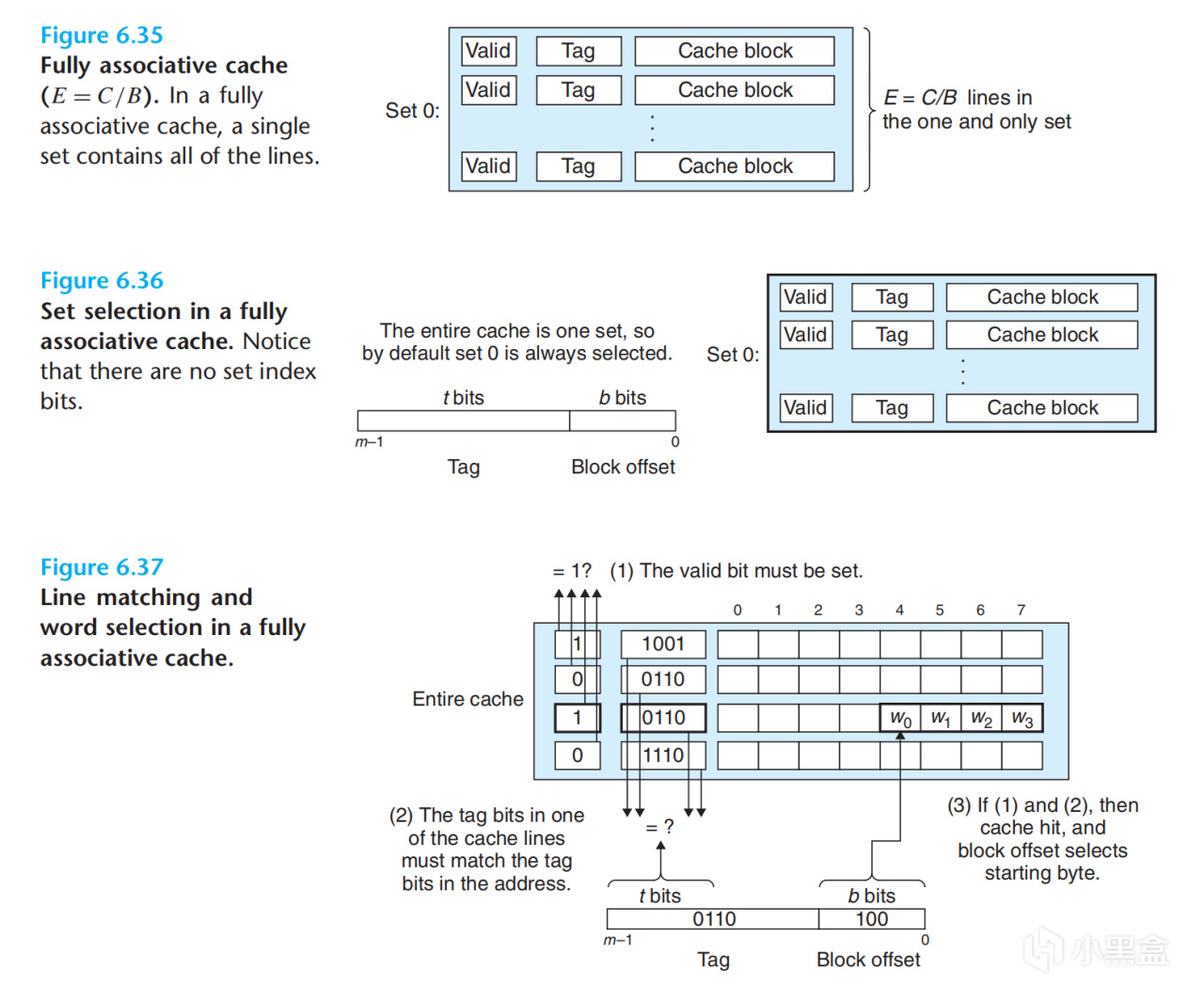
在fully associative的情况下,因为整个Cache就是一个组,那么我们就不需要Index来寻找是哪个set了,因此地址只剩下了tag和offset。因为在访问Cache时高速缓存电路必须并行匹配许多tag,想要构造又大又快的fully associative cache是十分困难且昂贵的。因此fully associative cache只适合做小容量的cache,如TLB(又是一个坑)。
最后我们回到刚开始的那段话,为什么顺序访问适合具有多个连续数据元素的cache line大小的小型direct mapped cache,而具有良好局部性但较大工作集的访问适合相对较大的set associative cache呢。这是因为direct mapped Cache能够利用顺序访问的局部性,将连续数据元素映射到同一个cache line中,取了一个元素相当于取了相邻连续的多个元素。具有良好局部性说明程序访问内存会比较集中在某一个范围内,因此最好用大一点的Cache把这块内存尽量装下,此外,工作集较大说明程序运行时访问内存范围较大,如果是direct mapped cache很有可能会出现thrashing,因此最好使用set associative cache。
关于CPU Cache这次先讲这么多,后面会(视心情)更新其他关于存储相关的知识笔记。(可能也会更新一些生活方面的?)
[1] 维基百科编者. CPU缓存[G/OL]. 维基百科, 2023(20231213)[2023-12-13]. https://zh.*********.org/w/index.php?title=CPU%E7%BC%93%E5%AD%98&oldid=80104215.[2] https://cs.brown.edu/courses/csci1310/2020/assign/labs/lab4.html
[3] https://developer.arm.com/documentation/den0024/a/Caches
[4] Bryant, Randal E., and David R. O'Hallaron. Computer Systems: A Programmer's Perspective. 3rd ed., Pearson, 2016.
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com
















