省流總結一下:
Metal0間距通過SAQP繼續做小,成本爆炸,但是Lg不依賴EUV微縮起來困難,N+3 CPP= 57nm,與臺積電 N6 相當,再往下若無EUV幾乎碰壁,n+4還有一點空間,壓單元高度、壓M2到SAQP、CPP微縮到54nm(intel7),如果達到198nm的height和54nm的cpp,n+4密度應該能到137.8 MTr/mm,但每一步的邊際成本和複雜度都在爆炸,沒有EUV的話,平面微縮往下做會越來越不划算,SA估算的n+5革新引入背部供電,最終做到高170nm,cpp53nm,密度163.6 MTr/mm,大致能與英特爾18A工藝的高性能庫處於同一水平,已經是極限中的極限了,最終實現起來的難道可想而知,所以轉向邏輯摺疊也是面對EUV光刻設備缺失這一現實約束所給出的系統性解決方案。
必須客觀指出,中國目前並未縮小與英特爾、三星和臺積電之間的整體技術差距。本次拆解在多個維度上呈現了相反的事實:沒有EUV光刻、沒有背面供電技術、更高的工藝複雜性,以及處處可見的性能取捨。
但同樣真實的是:中國仍然在前進。出口管制並未終結中國半導體產業的演進,EUV光刻設備的禁運提高了尖端製造環節的成本與複雜度,但並未使其停滯,SMIC通過DUV浸入、SAQP和DTCO達到N6級邏輯密度已經向我們證明了這點

專業分析要用專業設備
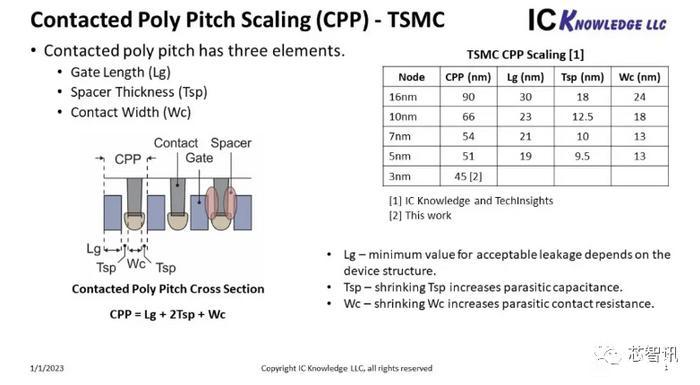
中芯國際N+X是什麼
N+X最爲人熟知的莫過於去年麒麟9000s橫空出世時大家的討論。但是其實大部分人並不知道N+X到底是什麼。要知道什麼是N+X我們得先認識一下業界對製程的命名規律。最開始的時候,Xnm代表的是導線半間距,到了90nm後,這個玩不下去了,Xnm逐步變成了一種代號,通常作爲某個節點的代表,對特徵尺寸的反應嚴重不足。對於tsmc而言,10nm是CPP=66 M2P=44,7nm就是CPP=57 M2P=40。但是,重點來了,隨着製程進步的放緩,單純的結構尺寸已經不太能滿足密度的需求了,比如上面的特徵尺寸,10nm到7nm密度只大了27%,這顯然不夠,所以在N7上tsmc使用了6T庫,相比N10的7.5T庫,從而又帶來了25%,總共60%的密度提升。在N5上,tsmc又通過引入SDB來增大密度。這個時候問題來了,假設我開發一個製程,特徵尺寸是業界公認10nm的,但通過使用6T庫,SDB來達到了7nm的密度,我該如何稱呼這個製程?是7nm還是10nm?SMIC的選擇是都不要,就叫N+X,避免後面的分歧論戰。

N+X會是什麼樣子
從N+1到N+2,CPP從66變成63,M2P變成40,想要進化成7nm,CPP還得減到57,這中間Wc的潛力最大,預計會降到18,而Lg降爲20。在N+3 m上,⼀我們大概率只能看到10%的密度提升,但性能或能提高至N7水平,即在目前的電壓下,頻率提高至2.6GHz。更遠的展望,預計N+4能實現基於CPP57 M2P=40下的2-1晶體管單元,再提升40%+的密度。

小結:對於華爲而言,目前最有前途的並不是手機,而是計算卡和服務器市場的商業採購,趕巧的是,這兩者要的是規模是晶體管密度而不是頻率。這也註定了密度纔是華爲目前追求的第一選項。大家想賽博鬥蛐蛐的建議不要在頻率和峯值功耗上下注,因爲註定在這幾年內看不到太多的進步。
兩年前我的看法是N+3將會把CPP縮小到57nm,其中Lg=20nm Wc=18nm,在TEM下我們看到CPP確實降到了57nm,Lg也到了20nm(圖上的測量24nm是錯的,不必理會),Wc比想像更激進些做到了16nm,當然這也說明Tsp帶來的寄生電阻確實給SMIC帶來了不小的麻煩。這些都基中預測中了,N+3確實能稱之爲7nm級別的製程了。

M2P=32,M0=30確實沒在我的預測內,SMIC選了一個很激進的玩法,用30nm的M0做一個7.6T的HD庫。原本按照我的想法,M2P=40 HD庫爲6T,CH=240,完美復刻tsmc N7,但顯然,,SMIC並沒有照我想的去實現,它將佈線密度拉高,將金屬層數做大,處處透露着四個大字:節約面積。

從gate切面的角度你能看出DUV控制CPP大小的艱難:在四重曝光下gate length 上下差值有4nm之多,誤差超過20%,工藝角和體質方差你可想而知,所以我堅持認爲在EUV沒投產的N+4 CPP將會保持57nm不變。其次,堆疊爲面積鬆了綁,2+1fin不再是下一代的追求,我認爲30nm M0+6T的HD庫CH=180nm將是SMIC衝擊的重點,即我認爲N+4的晶體管尺寸爲G57H180,密度提升27%。
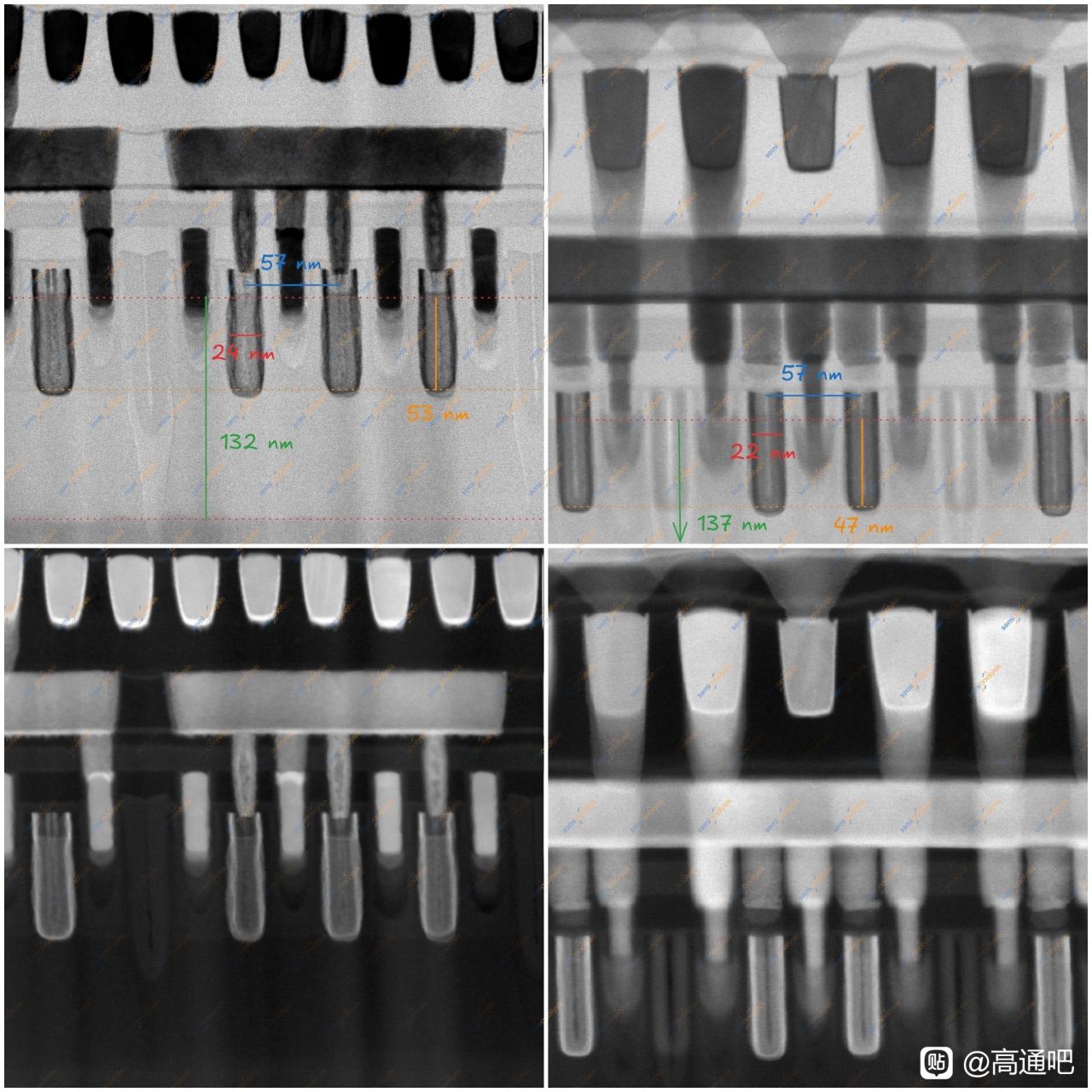
SemiAnalysis 的核心判斷是:SMIC N+3 m 不是“真正趕上 Intel/TSMC 領先節點”,而是用非常激進的 DUV 多重圖形化 + DTCO,把平面邏輯密度推到 TSMC N6 級別附近。N+3 已用於華爲 Kirin 9030,是 SMIC 第三代 7nm 級工藝;它的最小本地金屬 M0 pitch 爲 32.5 nm,表面上甚至小於 Intel Panther Lake 上 18A 已量產版本的 36 nm M0 pitch,但作者強調這是一個“片面的指標”,因爲 M0 只是 cell 內局部互連層,不能代表整個工藝節點的 PPA、良率、成本、互連完整性和設計靈活性。
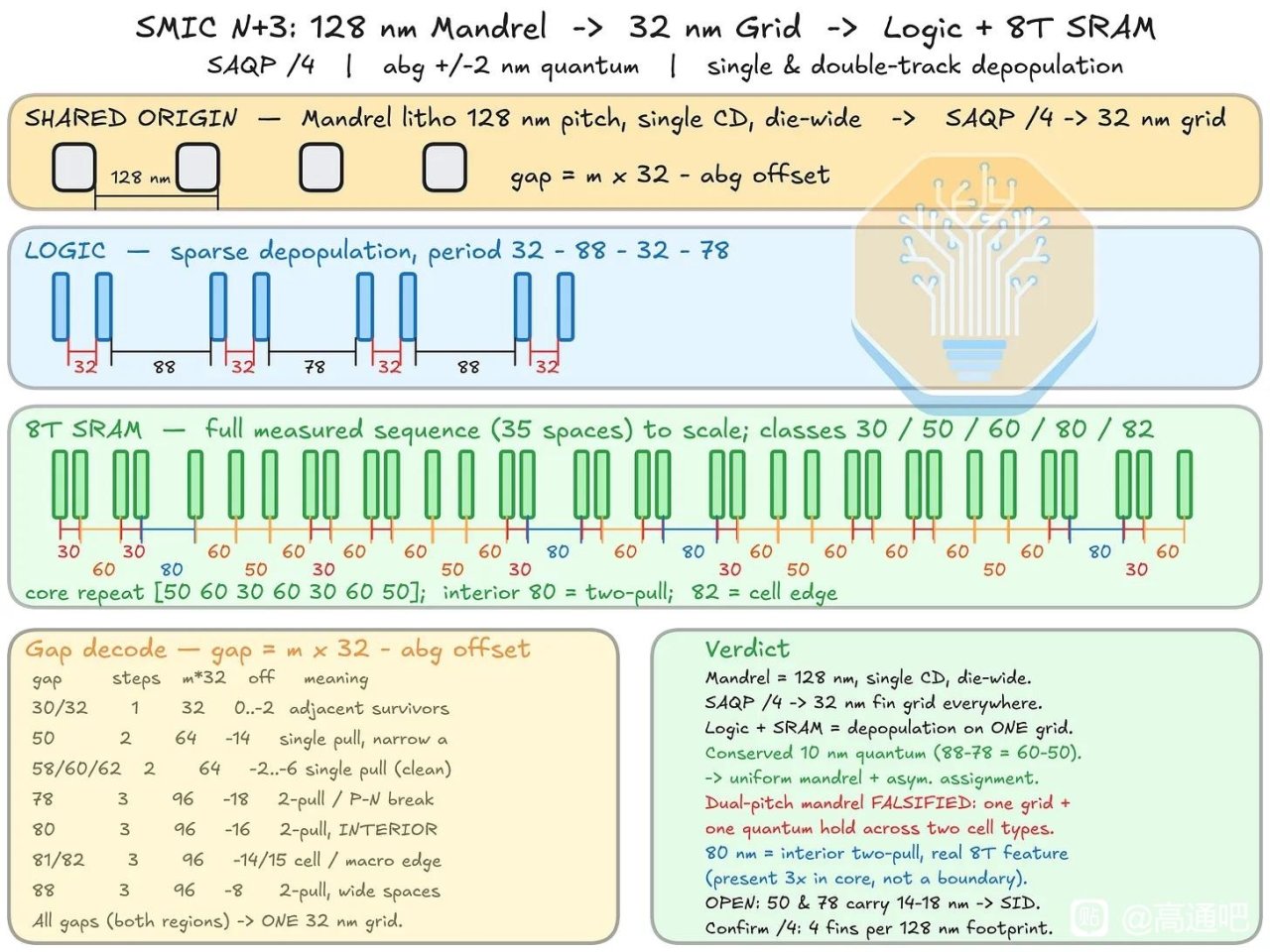
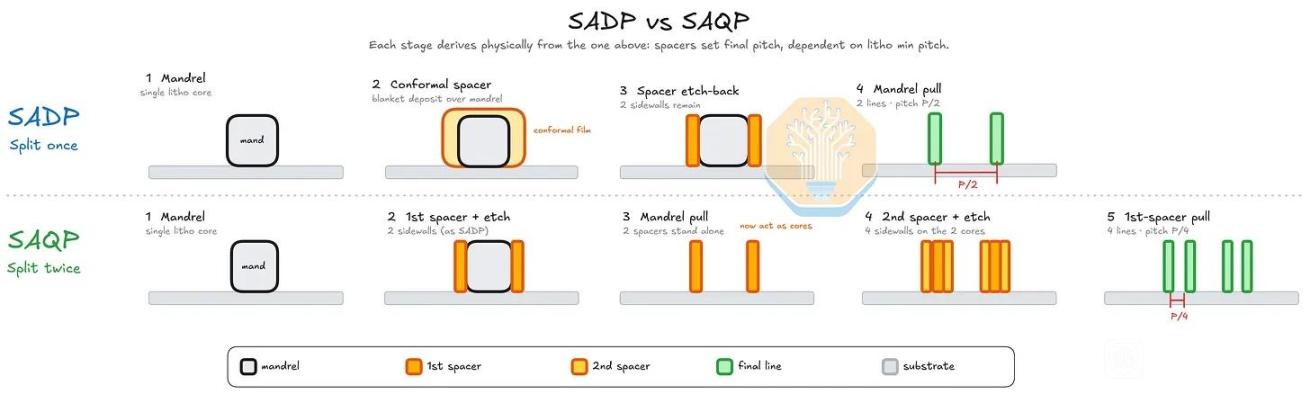
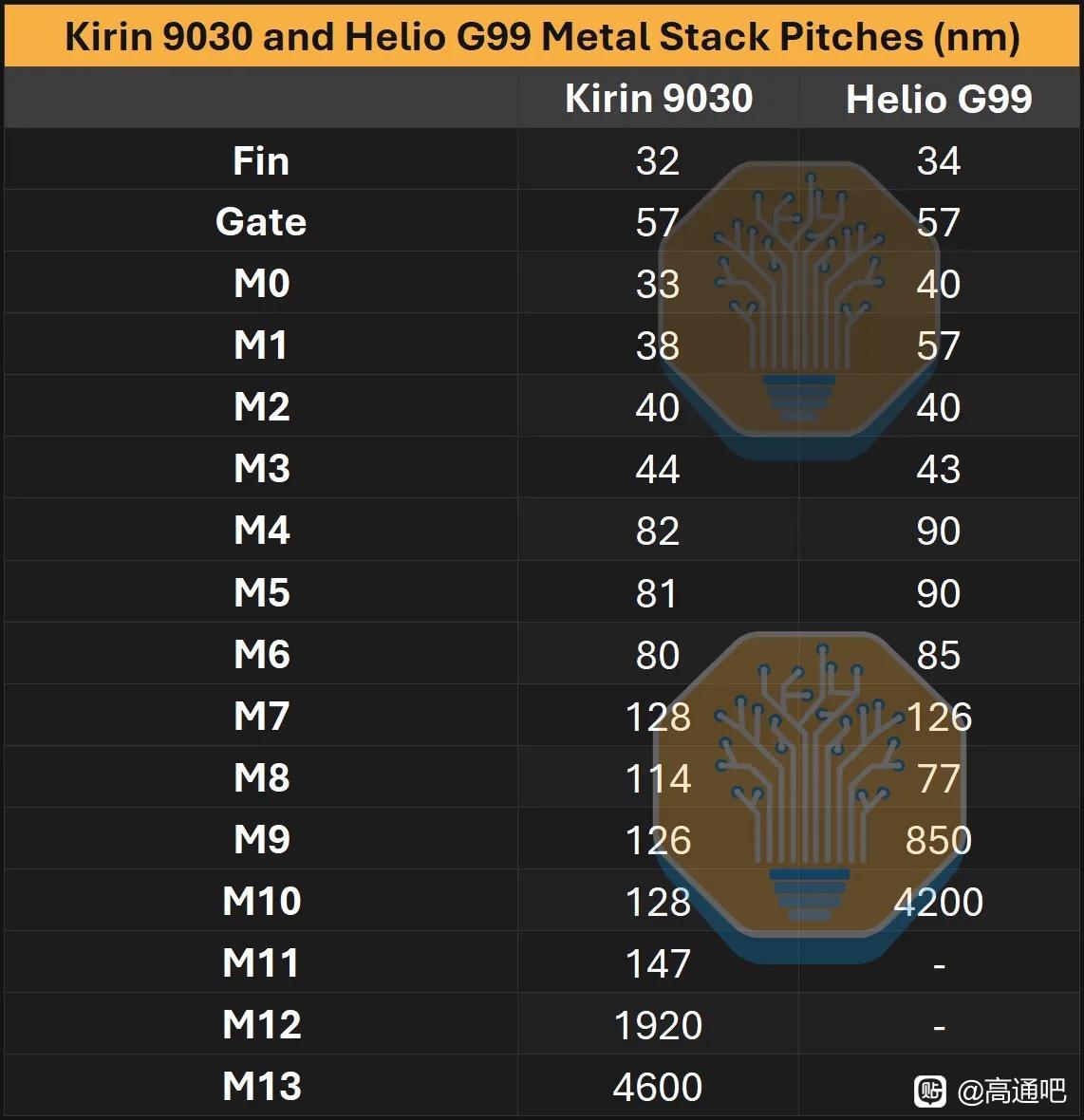
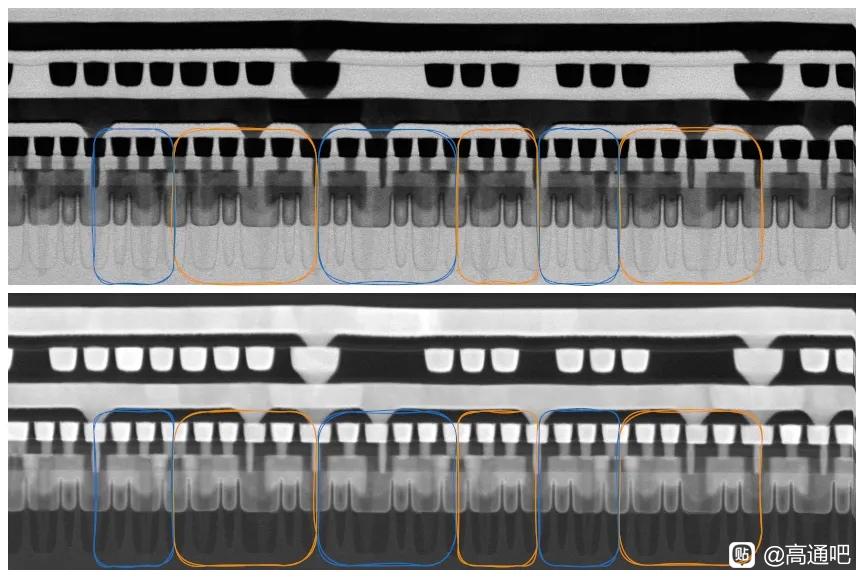
從晶體管層看,N+3 仍是 FinFET,不是 GAA。文章用 Kirin 9030 與 TSMC N6 的 Helio G99 做 TEM 橫截面對比,測得 N+3 fin pitch 約 30–32 nm,TSMC N6 樣本約 34 nm;N+3 可能通過 128 nm mandrel + SAQP 形成全芯片約 32 nm 的 fin grid。它的 fin 更高、更窄,aspect ratio 約 9.5:1,高於 N6 的 7.8:1,頂部圓角也更小。這說明 SMIC 在 FEOL 幾何形貌上確實推得很激進,但這種更高縱橫比、更緊 pitch 的 fin 也會帶來刻蝕、線邊粗糙、器件變異和良率控制壓力。
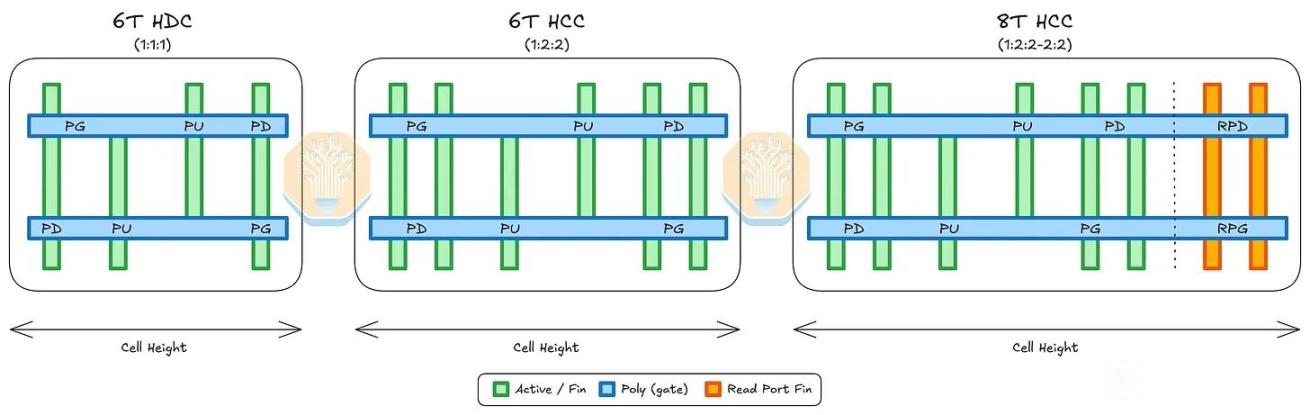
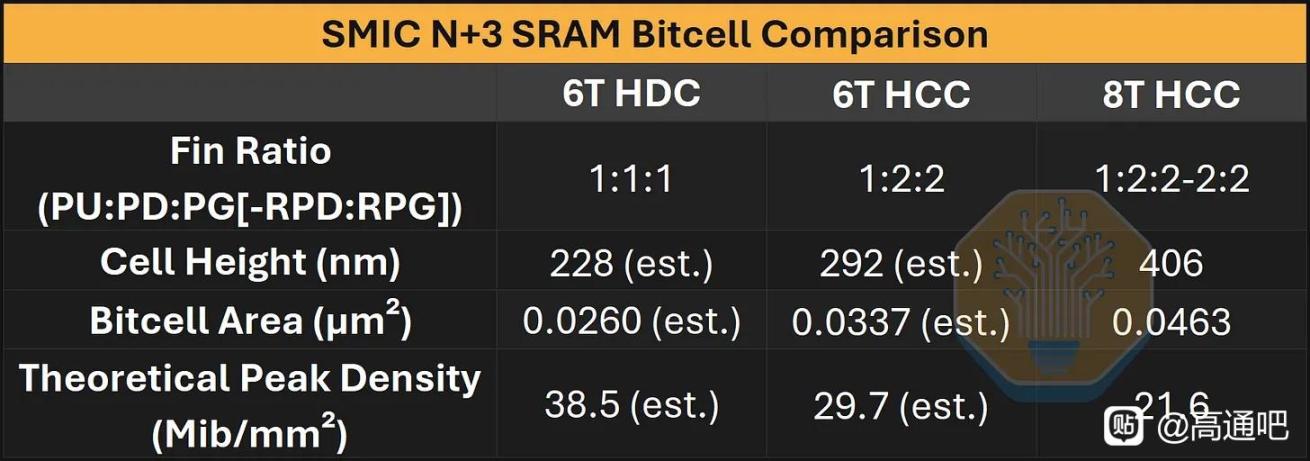
標準單元方面,N+3 的 cell height 爲 228 nm,比 TSMC N6 HD cell 的 240 nm 小約 5%,也比 SMIC N+2 的 252 nm 縮小約 9.5%;CGP 爲 57 nm,與 TSMC N6 HD 相同。關鍵是 SMIC 把一系列 density booster 都用上了:fin depopulation,即每個 NMOS/PMOS 只用 2 根 fin;COAG,即 contact over active gate,把 gate contact 放到 active gate 上方壓縮 cell;以及 SDB,即 single diffusion break,用面積換取更高的局部效應建模/工藝控制難度。SemiAnalysis 用 Bohr metric 估算 N+3 邏輯晶體管密度約 113.4 MTr/mm²,略高於 TSMC N6 的 107.7 MTr/mm²。作爲參照,TSMC 官方也說明 N6 使用更多 EUV 層來提高工藝簡單性、週期和生產率,而 SMIC N+3 則是在沒有 EUV 的約束下靠 DUV 多重圖形化和 DTCO 達到接近密度。
互連層是最關鍵的部分。N+3 的 M0 pitch = 32.5 nm,比 N+2 和 N6 縮小約 19%,需要 SAQP;M1 pitch 爲 38 nm,M2 pitch 爲 40 nm,M3 pitch 爲 44 nm。文章認爲 M0 小於 Panther Lake 上的 Intel 18A 量產 M0 pitch 是事實,但不代表 SMIC N+3 比 Intel 18A 先進,因爲 Intel 18A 有 RibbonFET GAA、PowerVia 背面供電等結構性優勢,而 N+3 仍是傳統正面供電 FinFET。Intel 官方也把 18A 的核心差異化定義爲 RibbonFET + PowerVia,而非單個金屬 pitch 指標。
N+3 的 M1/gate 比例也很有意思:SMIC N+2/N+3 使用 3:2 M1-to-gate ratio,而 TSMC N6 是 1:1。3:2 的好處是局部佈線更靈活,能緩解標準單元內 power/signal crossing 的壓力;壞處是版圖網格和多重圖形化更復雜,對 PDK、EDA 和 overlay 控制要求更高。換句話說,SMIC 不是靠 EUV 簡化流程,而是反過來用更復雜的 DUV 分割、更多 mask、更多工藝控制難度去換密度。
SRAM方面,文章發現了 8T SRAM,其 bitcell 爲 0.0463 µm²,理論峯值密度 21.6 Mib/mm²;估算 6T high-density cell 可到 0.0260 µm²、理論 38.5 Mib/mm²,大致接近 Samsung 7LPP/5LPP,略低於 TSMC N7/N6。實際緩存宏方面,Kirin 9030 相比 Kirin 9020 的 SLC/L3/L2 陣列面積約縮小 17–18%,整體 SRAM scaling 約 19%。但作者也提醒,N+2 的 SRAM bitcell 原本偏大,所以這部分既有真正縮小,也有“補課式追趕”。

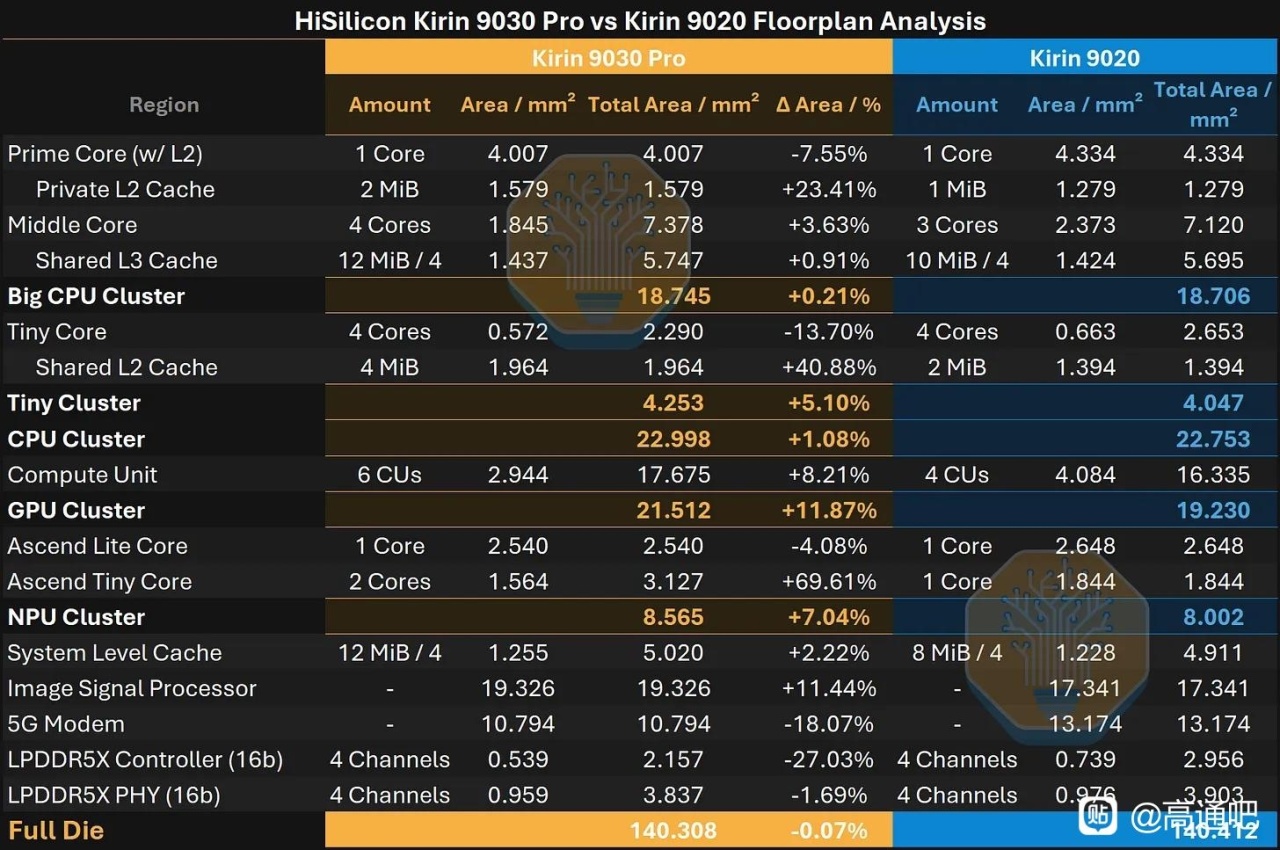
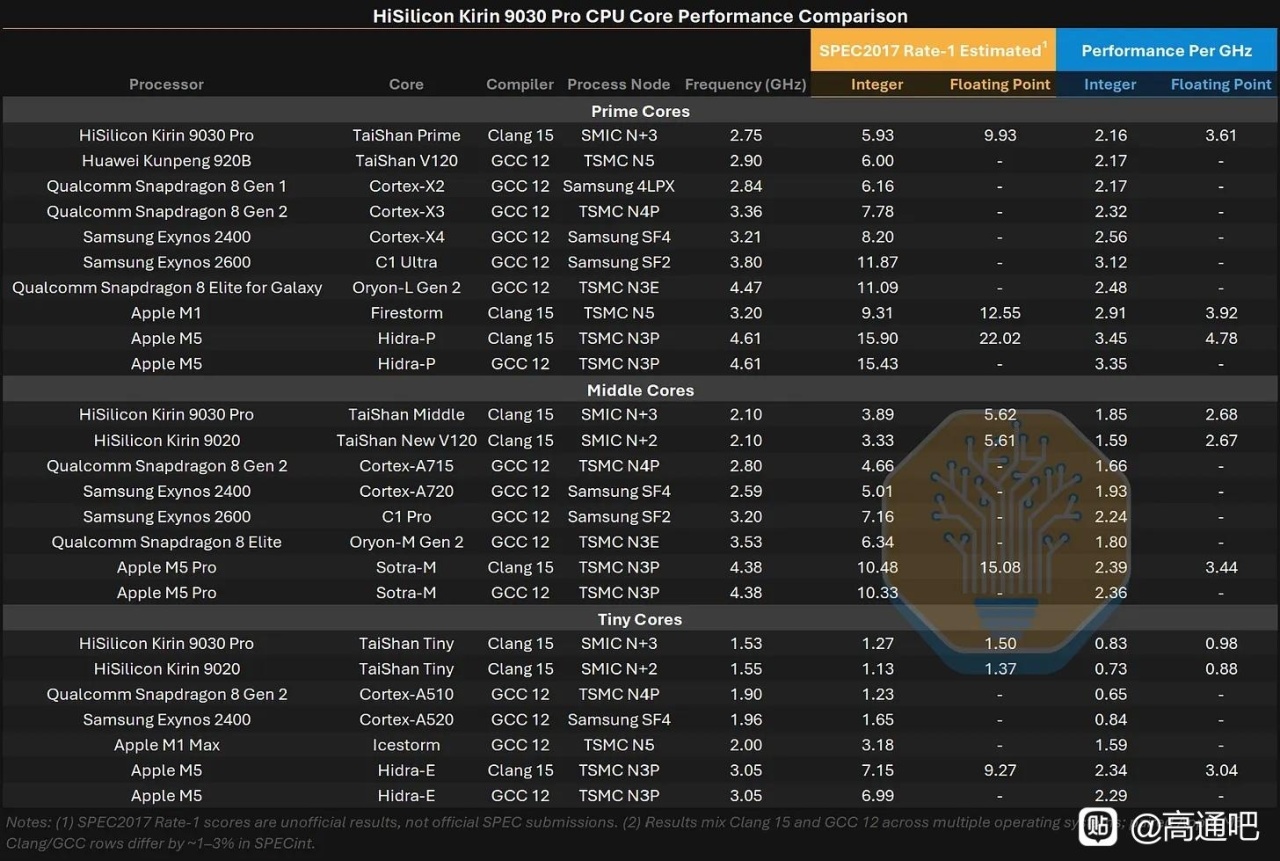
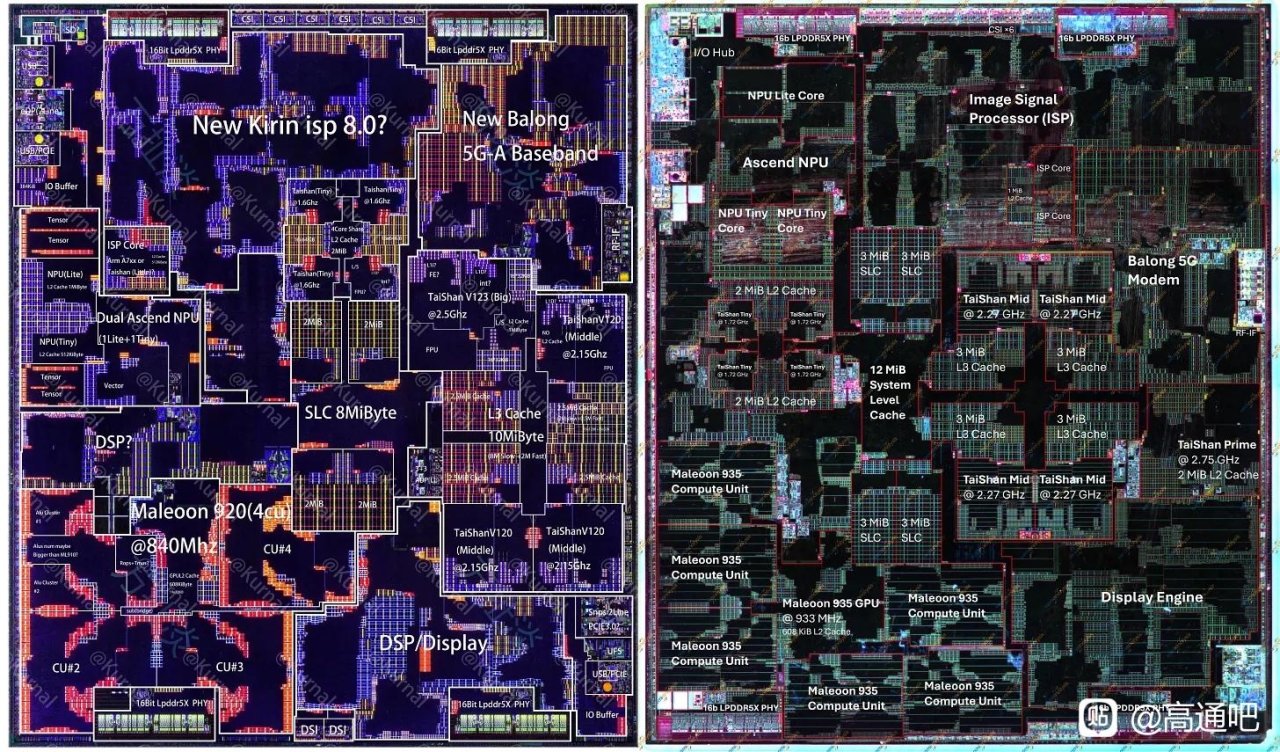
放到 Kirin 9030 上看,N+3 主要帶來的是面積預算改善:Kirin 9030 與 Kirin 9020 總 die area 接近,但 9030 能塞入更多中核、更大的緩存、更多 GPU CU 和更大的 NPU 配置。可是 PPA 並沒有跟上當前旗艦節點:文章認爲 Kirin 9030 大致追到幾年前 Android 旗艦水平,GPU/NPU/CPU 都有進步,但效率明顯落後於 Apple、Qualcomm、MediaTek、Samsung 的最新旗艦 SoC;原因一是 N+3 本身只到 N6 級密度,二是華爲 CPU/GPU 微架構和電壓-頻率曲線仍落後。
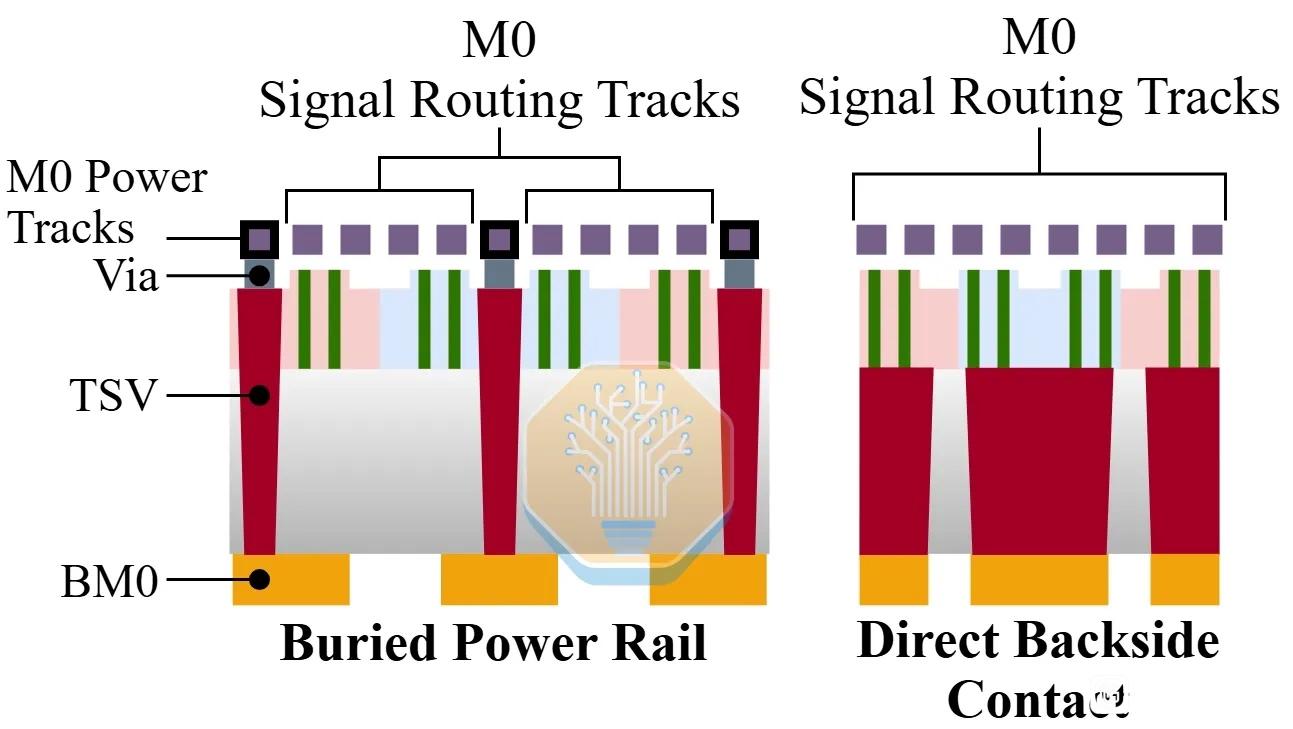
未來路線方面,SemiAnalysis 認爲理論上的 N+4 可能繼續縮 cell height、CGP 和 M2/M1 pitch,例如 cell height 走向約 198 nm、CGP 到 54 nm,Bohr density 估算可到 137.8 MTr/mm²,接近 TSMC N5/Samsung SF4 級別;但這會把更多層推入 SAQP,mask 數、overlay、工藝窗口都會更痛苦。更遠的 N+5 可能需要 backside contacts / backside power 類似思路,纔可能到約 163.6 MTr/mm²,但文章判斷這不會讓它在成本上真正對標領先節點。

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















