凌晨1点,Google I/O 2026 开发者大会准时开场。

今年有点特殊,AI圈热闹了大半年,但几乎跟 Google 没啥关系。
OpenAI从去年到现在,不断有新的 GPT 发布,前段时间还有个大火了一把的 GPT Image2;Anthropic 也有 Claude 4.6 和 4.7 以及大家想用用不上的 Mythos,甚至就连 DeepSeek 也因为V4和识图能力的上线都上了好几次热搜。
Google 呢,安安静静的,除了香蕉系列,Gemini 这边一直不温不火的,没啥大动静。
今天的 Google I/O 大会看完才知道,原来 Google 喜欢攒一波,然后在 I/O 上,一口气全放出来。

今年这波,最让我兴奋的,是被安排在首个发布的 Gemini Omni。
Omni 是 DeepMind 的 CEO Demis Hassabis 亲自上台讲的,能让 Demis 亲自出马的东西级别不一般。
Google 给它的定位是 World Model,世界模型。

这个词以前 Google 很少这么直接拿来讲。
虽然之前有Genie系列,能从文本生成可探索的3D世界,但那是给机器人训练用的,普通人碰不到,不过这次Omni不一样了。
它的关键词是,any input to any output(任意输入,任意输出)。
你不用非得写一段prompt。
文本、图片、音频、视频,任何你想的素材,都可可以同时混着喂给它,它理解这些素材之间的关系,然后生成或者修改。

发布会现场宣传片看着蛮不错的,什么手上火焰,材质变换等。

而且它支持对话式编辑。
不用时间线关键帧,直接用自然语言改,比如把背景换成火星、加个爆炸特效,它就能保持人物和场景一致性,同时把你要改的地方改掉。还能锁定视频中某个片段不变,只修改其他部分。
这种局部锁定的能力,对做视频创作的人来说太实用了。
(目前 Omni 模型可以被任意 Gemini 的付费挡位调用,允许使用的次数不同)
这里我用之前 Seedance2.0 上线时的一个视频进行了测试:

图片,视频见公众号“飞碟AI”
主角被我换成了《天国拯救》中,斯卡利茨的亨利,追逐的警员也被我换成了卫兵:

图片,视频见公众号“飞碟AI”
效果也还是真不错吧。
先说个人结论:还是打不过 Seedance2.0,但有进步,个别场景很不错。
我这里还测试了几个案例,大家可以参考参考。
P1:海浪拍礁石
使用Omni生成视频,生成一段海浪排向礁石的画面。

图片,视频见公众号“飞碟AI”
画面没问题,声音也没问题,同时镜头感真的很不错。
P2:保龄装木瓶
使用Omni生成视频,生成一段在保龄球馆中,保龄球滚向并撞倒木瓶的画面,镜头跟随保龄球

图片,视频见公众号“飞碟AI”
这就有点问题了,首先是球速,不知道是Omni为了拖时间还是怎得,球速非常慢且运动速度不均匀,这是不符合现实的,不过好在最后的碰撞还行。
P3:女主买烧饼
使用Omni生成视频,生成一段古装剧中,女主在喧闹集市边吃烧饼的画面,并跟小贩说再来一个

图片,视频见公众号“飞碟AI”
有点一言难尽,画面基本和谐,人物、背景乃至镜头都没问题,但烧饼莫名其妙消失了,同时人物讲话一股台味。。。
不过想想也正常。
今天发布的是Omni Flash,是Omni家族的第一个模型,Google明确说了Omni Pro即将发布,Flash版本拉一点能理解,就像当年Seedance刚出的时候,也是一步步迭代上来的。

关键是这个方向,我是真的觉得对了。
视频生成这个赛道,正在从“我能生成一段视频”进化到“我能理解这个世界然后生成视频”。
Omni 把 Gemini 的推理能力和生成式媒体模型结合起来,开始处理动能、重力这些接近物理世界的问题。
这个进化方向,比单纯追求画面质量要聪明得多。
回到这次大会,Omni 之外还有个重头戏,Gemini 3.5 Flash。

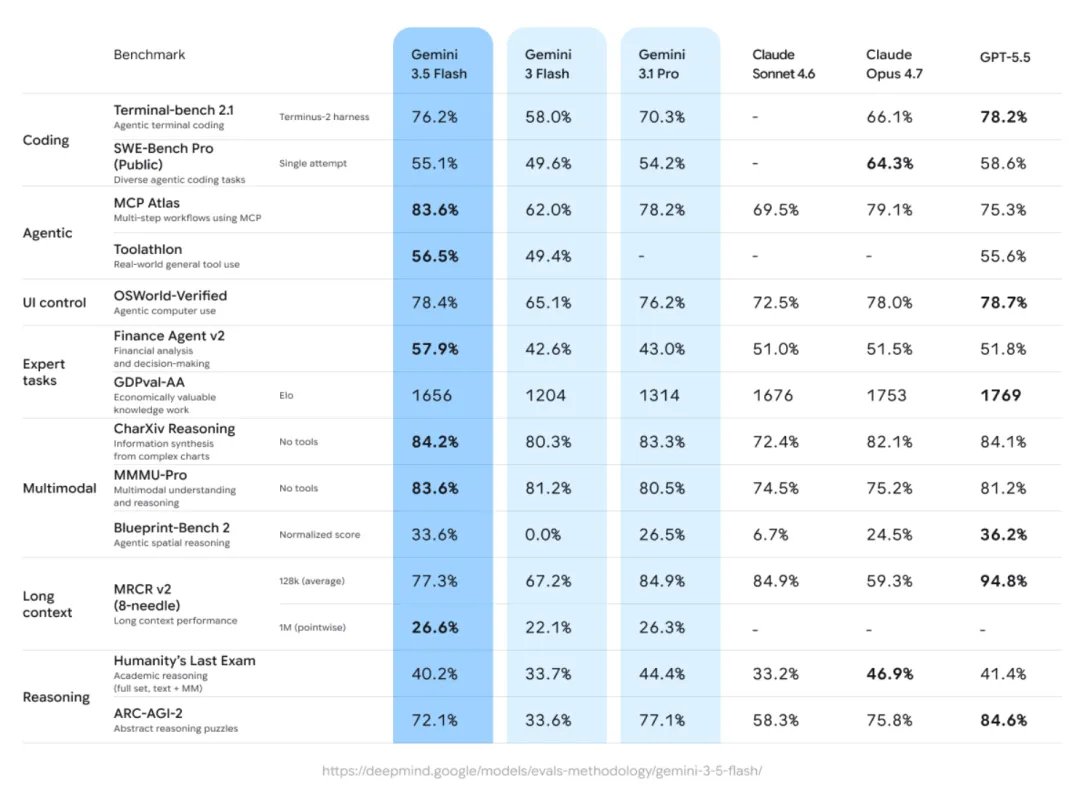
一般来说 Flash 系列是轻量快速版,主打便宜和快,但 3.5 Flash 却做到了编码能力、Agent能力和工具调用能力全面超越了上一代旗舰3.1 Pro。
Terminal-Bench 2.1编码测试,3.5 Flash拿了76.2%,3.1 Pro只有70.3%。
GDPval-AA,衡量真实世界经济价值任务的,3.5 Flash 1656 Elo,3.1 Pro 1314 Elo,差了三百多分。
但也不是没有取舍。
3.5 Flash在Humanity's Last Exam上40.2%,比3.1 Pro的44.4%差,ARC-AGI-2上72.1%也输给Pro的77.1%。
牺牲了知识和推理,换来了干活的能力。
输出速度比其他前沿模型快4倍,在Antigravity里经过专门优化后能达到12倍。
至于价格部分,则没有那么美好,虽然是Flash的名头,但价格却来到了:
输入$1.50/百万token,输出$9.00/百万token,
这个价格不仅远超之前的Flash,且比相当一部分主流模型的普通模式贵了。。。
其他AI相关的内容,还有几个值得提一嘴。
他们这次还发布了 Antigravity 2.0,Google 版的 Claude Code。

这次升级成了以Agent为核心的开发环境,宣传片里他们让93个子Agent并行跑,12小时从零搭了个能跑Doom的操作系统,总成本不到$1000。

还有 Gemini Spark,你的个人AI Agent。
跑在Google Cloud上,24/7不间断,你关掉电脑它还在云端帮你干活。打通了Gmail、Docs、Sheets全家桶,能语音一次说多个任务让它分头执行。
感觉是 Claw 的类似物产品。
Search也来了个25年来最大升级。
搜索框变成了对话框,能接文字、图片、文件、视频,还能创建信息Agent让它持续帮你监控某类信息。Google把Antigravity的Agent能力直接塞进了搜索框,能根据你的问题实时生成交互式界面。

一口气看下来,Google 的方向非常统一。
模型已经变成了最基础设施,Agent 成为了产品,未来更多是看你这个 Agent 能不能办事。
Omni在构建对世界的理解,3.5 Flash在用速度和成本驱动Agent生态,Antigravity在收束开发者入口,Spark在打通消费端场景,Search在做入口防守。
所有东西都在往同一个方向使劲,让AI从“你问我答”变成“你说一件事,我帮你做完”。
我觉得这才是这场I/O真正传达的信息。
你想想看,一家拥有搜索、地图、邮件、文档、视频、Android生态的公司,把AI从App层沉到了基础设施层,然后用Agent把所有产品串了起来。
这比任何单个模型的跑分都更有冲击力。
模型是基础,Agent是未来。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com















