5月15日,米哈遊於北京舉辦AI大模型技術分享會暨頂尖校招宣講,以非公開形式面向高校頂尖人才與技術圈核心人士,官宣千億級AI投入與全棧自研路線,標誌米哈遊發展戰略將朝向AI驅動科技企業進一步押注。

在本次分享會中,米哈遊聯合創始人劉偉(大偉哥)也登臺分享了自己對於AI業務的願景,並拋出了一個頗爲震撼的數字:未來三年,最多投入1000億元以深耕AI領域。他坦言,“就算最終不成功,沒做出來,也認了,就當放一場大煙花。”這份決絕,彰顯出米哈遊深耕AI領域的堅定決心。
戰略層面不搞“大公司病”
在本次分享會中,大偉哥首先提到:“公司的創始人也必須是技術負責人,必須在一線做所有的事情,只有這種方式才能將大模型做成。”
當今時代下,AI大模型範式迭代極快,決策層若脫離了技術一線,只靠彙報來做決策,高昂的管理成本不僅會拖垮團隊,更會讓企業被時代淘汰。因此,最高決策者必須紮根在代碼與訓練曲線一線,只有這樣才能守住極致的技術敏銳度。
事實上,米哈遊早已踐行這一理念。在遊戲日報此前關於劉偉在上海交通大學演講的報道中便提及,聯合創始人蔡浩宇無論公司規模如何擴張,始終堅守技術一線;在AI大模型時代來臨後,他義無反顧的把米哈遊所有東西都拋在身後,從零開始學習鑽研。最近Agent技術十分火熱,蔡浩宇也會親手搭建Agent,即便每日睡眠不足五六小時也始終保持極高的研發熱情。
另外,組建團隊做AI需要警惕“大牛陷阱”,堅持扁平化優先。大偉哥提到,“我們不希望招一個大牛。大牛有自己很強的ego(自我),有自己的scope(負責內容)......但只有一個年輕的、志同道合的團隊,纔有可能真正實現彎道超車。”
這其實指出,傳統AI經驗在LLM時代反而可能成爲“負資產”,影響項目的推進。一些固守局部優化,執着於“守邊界”、“搶地盤”的資深管理者,往往有強烈的自我意識,但這會扼殺全局視角的創新。在今天,從數據、模型到Infra,真正能實現突破的,是志同道合、扁平化的年輕團隊,而非沉迷於個人Scope的“大牛”。
此外,在研發效率層面,大偉哥還提出了“AI for AI,Model with Model”的核心邏輯,讓AI進入自主研發循環。真正的效率提升並非盲目擴招,而是讓大模型自主分析訓練瓶頸、編寫複雜的GPU內核代碼、定位程序漏洞。誰能率先搭建“自動調優沙盒”,誰就能在迭代速度上實現降維打擊。
技術層面的“薪火”
除了在公司戰略層面,遊戲日報也整理了大偉哥在前沿技術層面的一些洞見。
在基建層面,米哈遊重新定義了AI Infra的價值邊界,大偉哥指出,模型能力的上限正由基礎設施重新界定。在萬卡規模下,通信、計算、數據的協同設計早已不是簡單的“底層修管道”,而是直接決定算法模型能跑多大參數、支撐多長的Context。系統工程的核心,就是在正確性與極致性能之間找到最優解。
而在AI預訓練環節,米哈遊強調數據與工程的關係博弈。大偉哥認爲,數據是要佔據0~90分的量級,模型則是做90~95分的突破。在此前提下,數據清洗、去重與配比決定了模型的基礎,小規模訓練下看似有效的模型Trick,在極限Scale下往往會失效,唯有優質的數據分佈才能帶來穩定收益。
同時,大規模訓練的本質是消滅“小概率事件”,要把小概率事件變成一個確定性的工程,不然的話,“一個簡單的Loss Spike(損失值異常飆升)會導致整個模型去瘋。”
即便是在單卡上無足輕重的Token異常、算子Bug,看起來可能毫無波瀾,但在萬卡集羣中則會被無限放大,直接導致模型的災難性崩潰。因此,擁有從梯度到底層算子的全鏈路可觀測能力,是預訓練保持穩定、不被“炸燬”的唯一保障。
在後訓練與多模態領域,米哈遊則提出了通往AGI的真實路徑,提出智能的終極公式是“Context × Permission”,單純喂長文本,或給一個沒有環境的Function Call都毫無意義,真正的Agent需要讓模型讀取真實世界的上下文(如代碼庫、聊天記錄),並擁有執行修改的權限,二者相乘纔是智能的上限。
而在強化學習方面,米哈遊認爲簡單採用RLHF(人類反饋強化學習)已不是未來方向,下一代RL(強化學習)需要讓模型在真實交互環境中試錯,以“修改代碼導致pipeline崩潰”這類真實代價作爲Reward信號,解決長週期任務的學分分配問題。
未來的多模態也要摒棄簡單的“語音轉文字+文字轉語音”的外掛式流水線,而是在預訓練早期就將音頻等模態特徵融入基座,讓模型擁有原生物理感知能力的同時,保留其強大的邏輯推理內核。
米哈遊的野望
綜合遊戲日報之前的報道,不難發現米哈遊近日在AI領域動作頻頻。
米哈遊創始人蔡浩宇在硅谷的AI創業公司Anuttacon剛經歷了一次重大的戰略轉向。公司最初的目標是利用AI技術(包括大語言模型、語音、視頻)打造“像人”的互動系統,併發布了一款實驗性AI對話遊戲《Whispers from the Star》進行驗證。
如今,這款遊戲在Steam平臺的評分定位在特別好評(82%好評率),即便整體上得到認可,同時也有不少玩家反饋AI模型還不夠智能,未能完全實現玩法概念目標。
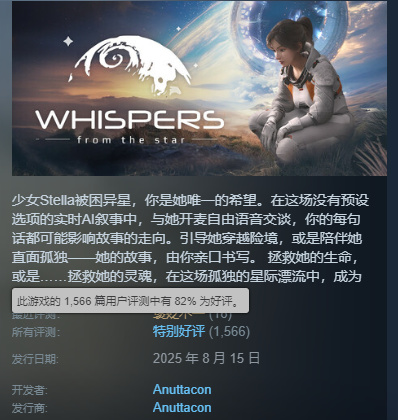
而最近,公司停止了多模態表演模型等原有方向的研發,將幾乎全部算力和核心團隊都集中投入到通用大語言模型(LLM)和智能體Agent的構建上,LLM相關團隊整體迴流國內,進入集中作戰狀態,蔡浩宇也將研發重心從美國轉移回了中國。
在前不久的大偉哥交大演講中,AI也是高頻出現的詞彙。大偉哥指出,人工智能的應用與影響已實現階段性躍遷,其範圍遠超早期的聊天對話(Chatbot)功能,如今已進入能夠自主規劃、使用工具並執行復雜任務的“智能體”(Agent)階段。當前,智能體已能深度參與大部分非圖形界面的軟件工程,成爲開發者的強大協作者。

在遊戲產業,這種變革尤爲顯著,其影響是雙重的。一方面,在遊戲製作端,AI正作爲“超級輔助”滲透到美術、敘事、設計、編程等全流程,極大地提升效率並降低創作門檻。另一方面,在遊戲體驗端,更具顛覆性的未來正在臨近:預計未來兩三年內,AI將實現“千人千面”的個性化遊戲體驗,能夠爲每位玩家實時生成獨一無二的劇情、任務和玩法,使遊戲從固定劇本進化爲動態世界。
在這種技術背景下,人類與AI的協作關係正在被重新定義。在當前階段,AI的核心角色是高效的“解題者”,擅長在人類設定的框架內執行任務、生成內容。而人類不可替代的獨特優勢,則在於成爲“出題者”——即擁有定義問題、設定願景和探索未知的能力。
而最近,米哈遊AI技術已實現部分落地——《崩壞:星穹鐵道》中的“帕姆幫幫”(測試版)AI助手就是一個具體運用的例子。通過自然語言交互,帕姆AI能夠主動理解並滿足玩家需求,不僅可以用它查詢攻略(如角色養成、配隊建議),還可以與扮演列車長帕姆的AI進行趣味互動,其回覆符合角色設定,體驗自然。

在技術層面,爲應對千萬級玩家的高併發挑戰,米哈遊採用了多模塊協同系統、將邏輯推理嵌入模型權重以提升響應速度、應用FP8混合精度訓練以降低成本。同時,通過深度定製化訓練將遊戲世界觀“刻入”模型基因,並採用知識庫與模型能力層分離的架構,使兩者能獨立優化,並讓模型具備基於反饋的在線強化學習能力,持續進化。
“帕姆幫幫”作爲米哈遊AI技術進入實際應用階段的標誌,儘管目前作爲“測試版”尚有改進空間,但其底層架構具備通用性,可擴展至其他NPC,就在此前,米哈遊已構想過如“星穹狼人殺”等AI驅動的新玩法,讓AI角色擁有自主行爲與策略。這標誌着遊戲交互方式從傳統UI向自然語言的變革,AI正從開發工具轉變爲遊戲體驗的核心組成部分,目前也收穫了良好的口碑。
同樣的,AI NPC系統也在不久前開啓二測的《星布穀地》中得到了應用。以咖啡店老闆娘“娜洛”爲例,其具備長線記憶功能、個性化的情感反應和擬人化的高自由度對話能力,旨在與玩家建立深度的情感連接,從而構成遊戲的核心差異化競爭力。即便有時回應略顯刻板,但也仍展現出了一定的邏輯反應潛力。

從戰略啓航到階段成果落地,米哈遊AI事業的版圖已然越來越清晰。從短期看,AI是革新遊戲生產方式、重構玩家交互體驗的核心工具;從長期看,集中攻堅通用AI與智能體,是米哈遊佈局下一代數字內容、探索AI原生數字世界的關鍵一步。隨着技術持續迭代與團隊整合完成,這場由米哈遊主導的遊戲AI革命,或將持續釋放更大的產業能量。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















