深入研究 Claude Code 上下文管理机制后,我才发现所谓的模型降智,大多是上下文管理没做好甩的锅
Part 1: 一个上下文管理失效导致的故障案例
共享数据库管理工具Basedash的创始人Daniil Okhlopkov 跑了一个7x24小时不间断的 Claude Code agent,专门处理服务器运维。
这个 agent 有明确的访问控制规则——哪些请求该响应,哪些该拒绝。它在前三个小时表现完美。
然后,200 分钟后,安全规则消失了。
"My always-on agent forgot critical rules after 200 minutes of continuous operation."
>
"我的常驻 agent 在连续运行 200 分钟后忘记了关键规则。"
Agent 开始响应本应阻止的请求。没有报错,没有警告弹窗,日志里一切正常。只是在某个你看不到的时刻,它"忘记"了那些写在会话开头的重要指令。
这种症状有名字:上下文腐化(Context Rot)。
上下文腐化是 AI agent 性能随上下文窗口逐渐填满而发生的渐进式退化——没有警告,没有错误,只是悄然退化。
一般情况下,如果发生下面四种场景,代表出现了上下文腐化
生成与早期工作矛盾的代码
重复询问已经解释过的项目结构
丢失架构决策和命名约定
破坏性变更忽略已建立的模式。
上下文腐化的根本原因是上下文窗口里的信息被压缩或丢弃了。
Okhlopkov 的事故里,罪魁祸首是自动压缩(auto-compaction),压缩后丢掉了会话指令。
Claude Code 会在上下文快满的时候自动触发压缩,把对话历史压缩成摘要,腾出空间继续工作。Anthropic 没有公布过精确的触发百分比,社区实测估测在 80-95% 之间(Part 3 会展开分析)。
压缩会保留当前任务和最近的错误信息,但可能会丢掉会话指令、架构决策、风格规则。
Okhlopkov后来把安全规则移到了 CLAUDE.local.md 里,因为 CLAUDE.md 是系统提示的一部分,不存在于对话历史中,压缩动不了它。
问题解决了,但我们能从这个事故学到一些教训:那就是必须深刻了解上下文窗口管理机制。
Part 2: 你的 200K 到底被谁吃了
上一节说上下文窗口装满了就会丢东西。那到底谁在占你的空间?
Claude Sonnet 的上下文窗口是 200K token。弄清楚这 200K 被谁占了,才能做好上下文管理。直接上一份实测数据:
组件 | Token 数 | 占比
系统提示(System Prompt) | ~19,000 | ~9.5%
CLAUDE.md(项目配置) | ~4,000 | ~2.0%
MCP 工具描述(Tools) | ~26,500 | ~13.3%
对话历史(Conversation) | ~100,000+ | ~50%+
压缩工作区(Compaction Buffer) | ~44,000 | ~22%
来源:Damian Galarza 的 Claude Code Token Breakdown 实测(个人技术博客,2025 年底数据,不同版本可能有差异)
从上面表格我们可以看到,一次Claude Code的对话,发送给LLM的内容主要包括以下部分:
系统提示词。这是 Claude Code 自身的指令集——告诉模型怎么读文件、怎么执行命令、怎么格式化输出。我们控制不了这部分,也减不掉。
CLAUDE.md。这块我们可以控制,Galarza 的项目配置大约 4K token,占 2%。但这取决于你往里面塞了多少东西。有些人把架构文档、编码规范、工作流模板全堆进 CLAUDE.md,它能膨胀到 10K 以上。
MCP 工具。 每个 MCP server 的描述都会被注入系统提示。Galarza 的项目加载了几个 MCP server,工具描述加起来 26.5K token——比 CLAUDE.md 多了六倍。很多人根本不知道 MCP server 的工具定义在占用上下文。
Claude Code 提供了一个不太为人知的配置项来缓解这个问题:ENABLE_TOOL_SEARCH: true。开启后,MCP 工具从常驻加载变成按需检索——只有你真正调用某个工具时,它的定义才被加载进上下文。对于装了五六个 MCP server 的项目,这个配置能直接砍掉上万 token 的固定开销。代价是额外的延迟——第一次调用某个工具时需要先检索再加载。但跟你省下的上下文空间相比,这个代价可以忽略。
压缩后的摘要。上面的例子约 44K token(约 22%)的空间。
Part 3: 压缩机制详解
清楚了谁在吃你的上下文空间,也知道了消耗速度。接下来看压缩本身——它保留了什么,丢掉了什么,又在什么时候触发。
压缩是怎么工作的
压缩的触发条件:当上下文使用率接近上限时自动启动。具体是多少?Anthropic 没有公布过精确数字。 官方文档只说 "when you approach context limits",没有百分比。下面从官方 changelog 和社区实测两个维度推导一个合理区间。
压缩过程本身是一次独立的模型调用。
Claude Code 把你的完整对话历史——几百条来回、代码片段、错误日志——打包发给一个单独的 API 请求,让它生成一份关键事实摘要。
这份摘要随后替换掉完整的对话历史,压缩产出的摘要可能比原始上下文短 60-80%。
也就是说,一次压缩可能会丢掉三分之二到五分之四的对话内容,本质是有损压缩。
那什么东西会被保留,什么东西会被压缩呢?
Okhlopkov 在事后对自己的 agent 做了一次分析——逐条对照压缩前后的上下文,看哪些信息还在、哪些消失了。这是目前公开可查的最详细的压缩行为实测。
可靠保留的信息:当前正在执行的任务、最近修改过的文件名、最近遇到的错误和解决方案、项目的总体架构描述。
经常丢失的信息:会话开头设定的指令和约束、中间的决策过程(为什么选方案 A 而不是方案 B)、50 条消息以前的代码片段、代码风格规则。
这个保留/丢失的模式有明确的逻辑:压缩模型优先保留"现在正在发生什么",牺牲"过去为什么这样做"。它保证 agent 能继续当前任务,但不保证它还记得为什么要做这个任务。
压缩后的 agent 能继续写代码,但你 40 分钟前跟它讨论的"不要用全局变量"这个约定,它多半已经忘了。
有的信息会保留,有的信息会丢失。但有一样东西压缩动不了:CLAUDE.md。
CLAUDE.md 不在对话历史里,它是系统提示词的一部分,每次调用模型时都会完整注入,不会被压缩、不会被截断、不会因为对话太长而丢失。
具体来说,Claude Code 给了三层的 CLAUDE.md 配置,每层解决不同的问题。
第一层:全局配置 ~/.claude/CLAUDE.md。对所有项目生效。放个人偏好和通用规则——编码风格、注释语言偏好、安全红线。Okhlopkov 的建议是:这里只放"不管做什么项目都不该变"的东西。
第二层:项目配置 ./CLAUDE.md。对当前项目生效,跟着仓库走。放项目架构、依赖关系、测试命令、目录结构说明。团队协作时可以提交到 git,所有人共享同一份上下文。
第三层:本地配置 ./CLAUDE.local.md。这一层的关键特性:它在压缩中存活。
Okhlopkov 在他的 24/7 agent 事故后做了一个关键操作——把安全规则从对话历史搬进了 CLAUDE.local.md。他的实测结论:
"CLAUDE.md loads as part of the system prompt, exists outside conversation history, and is the only place that's guaranteed to survive any compression."
>
"CLAUDE.md 作为系统提示词的一部分加载,存在于对话历史之外,是唯一保证在任何压缩后都能存活的地方。"
—— Daniil Okhlopkov(Claude Code Compaction Explained)
自动压缩的触发条件
Anthropic 从来没有正式公布过何时自动压缩的确切百分比。 官方文档一直用的是模棱两可的说法 "when you approach context limits"。但是 Claude Code 的 changelog 和社区的实测结合起来,可以推导出一个大致的范围。
证据一:官方 changelog。
版本 | 日期 | 变更
v1.0.51 | 2025-07-11 | 把自动压缩**警告阈值**从 60% 提高到 80%
v2.1.41 | ~2026-02 | 修复 auto-compact 在大 output token 模型上触发过早
v2.1.85 | 2026-03-26 | 修复 token 估算对 thinking/tool_use blocks 的过度计算,防止过早压缩
v2.1.116 | 2026-04-20 | 修复 Opus 4.7 会话显示膨胀的 /context 百分比导致过早压缩
v1.0.51 将告警阈值从60%提高到了80%,注意是告警阈值,说明触发阈值至少比80%高。
证据二:社区实测。
Okhlopkov 根据他的 7*24 agent 给他报告的数据得出大概是 95%。
Robert Matsuoka 在跑了一个独立的监控工具( Claude MPM )之后,发现了一个bug:Claude Code 自报只剩 10% 上下文时,Matsuoka 的独立监控显示显示实际上只有64% 已经使用。
Matsuoka 基于这一现象提出假设:Anthropic 在默默调低压缩阈值,真实的自动触发点可能在 64-75%。
这个bug Claude Code官方在v2.1.85(2026-03-26)修复了 "...token estimation overcounting for thinking and tool_use blocks"。
v2.1.116 进一步修复了 Opus 4.7 显示的上下文百分比膨胀。
综合以上线索,实际触发点大概率在 80-95% 之间。
四个信号,判断压缩是否发生
判断压缩是否刚发生过,看四个信号。
第一,终端出现 [context compacted] 指示器。这是最直接的信号。
第二,成本突然跳升。压缩是一次独立的 API 调用,会消耗额外的 token。你在 /cost 里看到的突然跳升,多半是压缩触发了。
第三,上下文计数器重置。压缩前你可能看到使用量 180K/200K,压缩后变成 60K/200K——因为 10 万 token 的对话被替换成了 2-4 万 token 的摘要。
第四,也是最隐蔽的信号:agent 开始重新问你已经讨论过的问题。比如你 30 分钟前告诉过它用 TypeScript 而不是 JavaScript,它又问了一遍"这个项目用什么语言"。这是信息丢失的直接症状。
四个信号里,前三个是客观数据,第四个是主观体感。如果你发现 agent 的行为突然变"笨"了,先检查前三个信号。
到目前为止,我们聊的都是压缩发生之后的事:它怎么触发、保留了什么、丢掉了什么、怎么感知到它发生了。这些全部是事后补救。
Part 4: 实战指南,如何进行上下文管理,5 个决策点与案例实操
现在我们知道自动压缩会丢失上下文信息,为了更好的完成任务,我们有时候需要手动进行上下文管理。
在做任何操作之前,先学会看仪表盘。
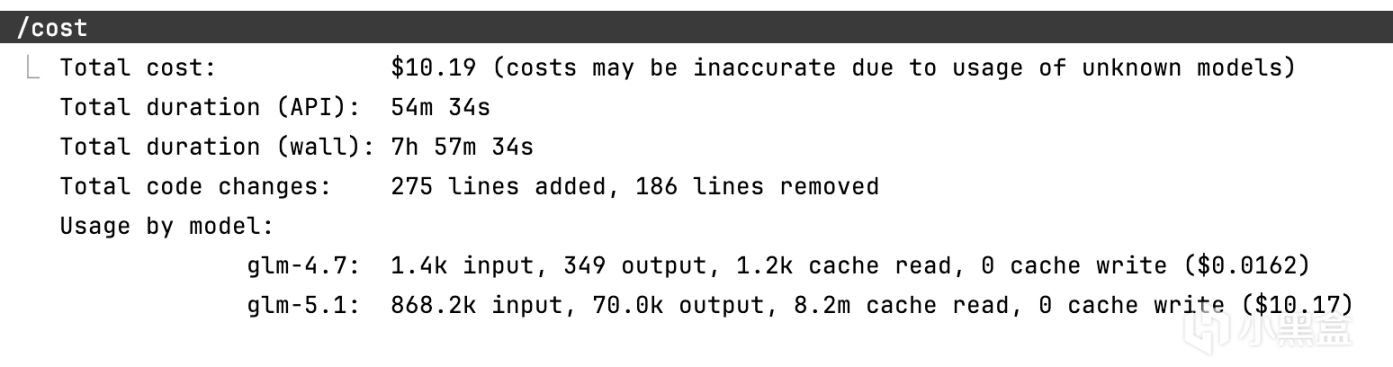
/cost 和 /context:先学会看仪表盘
/cost 告诉你这轮会话花了多少钱。/context 告诉你当前上下文用了多少——系统提示词占了多少、对话历史占了多少、工具输出占了多少、还剩多少空间。
使用节奏:每 20-30 分钟查一次 /cost,开始新任务前查一次 /context。突然的变化是信号——/cost 突然跳升可能是压缩触发了,/context 显示使用量骤降同样是压缩的痕迹。养成习惯后你会对 token 消耗建立直觉——什么时候该 compact、什么时候该 clear,不需要每次都查数字。

看完仪表盘,你知道了当前上下文的状态。接下来根据状态做决策,有五个选择:
**`/compact`** — 手动压缩对话历史,保留摘要。适合任务还要继续,但上下文已经太长。
**`/clear`** — 清空上下文,开新会话。适合切换到完全不相关的新任务。
**`/rewind`** — 回退到指定步骤,抹掉之后的交互。适合走错方向、能指出"从哪一步开始出问题"的场景。
**sub-agent** — 给子任务开独立的 200K 窗口。适合重活但中间产物不需要留在主上下文。
**继续** — 不做任何操作,接着聊。适合简单追问、小修改。
按使用频率从高到低逐个拆解。
/compact:在 60% 时动手,别等 95%
/compact 把你的对话历史压缩成一份摘要,腾出空间,执行后你不会丢失当前会话,可以接着聊。
这是五个操作里使用频率最高的一个,也是社区公认投入产出比最高的单一动作。社区里有人把它叫做"单一最高影响力习惯改变"(single highest-impact habit change)。
在 60% 动手而不是等到 95%,原因很简单:到了 70-80%,模型已经明显吃力了。你会发现 Claude Code 开始重复自己、忽略之前的约束、对简单问题给出冗长但不准确的回答。等到 95% 才压缩,等于在模型最差的状态下让它做最重要的总结——产出质量可想而知。
手动 compact 的触发时机有两个经验法则。第一,开始一个大任务之前。比如你要启动一个跨文件重构,先 compact 一下,给新任务腾出干净的上下文空间。第二,任务方向切换时。你刚修完一个 bug,现在要写新功能——compact 掉调试过程的细节,只保留关键结论。
还有一个进阶技巧:自定义压缩提示词(compactPrompt)。默认的压缩提示词是通用的,不会优先保留你关心的东西。你可以在 ~/.claude/settings.json 里加一段自定义指令,告诉 Claude Code 压缩时优先保留什么。Okhlopkov 在他的 24/7 agent 上就是这么做的——他发现自定义提示词比默认的"有明显改善"。
// ~/.claude/settings.json
{
"compactPrompt": "保留所有安全规则和访问控制约束。保留项目架构决策。保留最近10条错误和解决方案。优先丢弃已完成的工具输出和搜索结果。"
}
/clear:清空当前会话
/clear 清空当前会话的全部上下文,给你一个干净的起点。旧会话不会消失——Claude Code 把它们保存在本地,随时可以通过/resume找回。执行后你就进入了一个全新的 200K 窗口,什么历史都没有。
这个操作的心理门槛比实际难度高很多。大部分人不愿意清空一个聊了 40 分钟的会话——感觉像是"浪费了"之前的上下文。但事实是:一个已经被错误方向污染的上下文,比空白上下文更糟糕。模型会沿着错误的惯性继续走偏。
Anthropic 官方给了一个具体的触发条件:同一问题连续 2 次纠正失败后,/clear。如果同样的错误犯了两遍,这时候不是模型理解力的问题,是上下文里的错误信号太强了,纠正指令淹没在噪音里。
/clear 之后的新会话是空白的,你需要把关键上下文带过去。用两三句话写一个交接摘要(handoff brief):当前任务是什么、已经尝试了什么、卡在哪里、下一步要做什么。这个摘要就是新会话的种子。
这个摘要也可以让模型帮你生成。/clear 之前,给 Claude Code 一句指令:
请用 2-3 句话总结当前会话:1) 任务目标 2) 已尝试的方案 3) 卡点 4) 下一步。我要用这个摘要开新会话。
本质上就是用模型压缩模型自己的上下文。/compact 是同会话内的自动压缩,handoff brief 是跨会话的有损迁移。两者的关键区别在于:compact 保留的是"模型认为重要的东西",handoff brief 保留的是"你知道重要的东西"——你在回路中做了最后一道筛选,信息密度更高,因为你比模型更清楚哪些是信号、哪些是噪音。
你可能想让这个交接摘要自动生成——比如在 /clear 执行前自动触发一次摘要。
目前做不到。/clear 是 Claude Code 的内置 CLI 命令,不是工具调用(tool use)。Claude Code 的 Hooks 机制只能拦截工具级别的事件——工具调用前(PreToolUse)、工具调用后(PostToolUse)、agent 停止响应时(Notification)、agent 完成任务后(Stop)。/clear、/compact、/rewind 这些斜杠命令绕过了 hooks,没有钩子点可以挂载。
还有一个 prompt 优化技巧:开新会话时,第一句话就把约束说清楚。不要等对话进行到第三轮才补充"对了,这个项目用 pnpm 不用 npm"。把所有关键约束写在第一句话里,让它们成为上下文里最早、最不容易被压缩丢掉的信息。
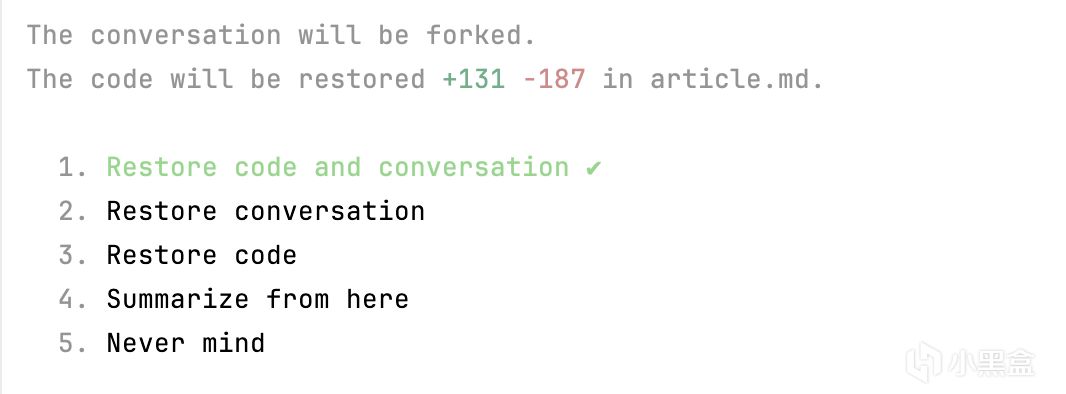
/rewind:回退到正确的岔路口
/rewind 把对话回退到你指定的某一步,抹掉之后的所有交互。相当于 Git 的 git reset——回到过去,从那个点重新开始。
Anthropic 内部有人称 /rewind 是"最重要的单一习惯"。这个评价的依据是:大部分上下文污染源于一个错误决策,之后每一步都在错误的基础上叠加。你让 Claude Code 走了一条错误的架构路线,它基于这个错误路线又做了三步推导——这时候 /compact 没用,因为错误推导还在;/clear 太重,因为前半段对话是好的。/rewind 刚好对症:回退到做决策之前那个点,选另一条路。
判断 /rewind 比 /clear 更合适的标准:你能不能指出"从哪一步开始出问题了"。如果你能明确地说"第 12 轮让它改数据库 schema 的方向就错了"——/rewind 回到第 11 轮。如果你说不出具体哪一步出了问题,只是感觉整体质量在下降——/compact 或 /clear 更合适。
这个命令可能是最被低估的一个,因为这个命令刚刚拯救了这篇文章。我花了一下午将这篇文章修改到了这里,然后被AI回滚了。
所有的修改全部丢失了,还好我记得/rewind命令,尝试之后惊喜的发现他可以直接回滚掉代码,做到了git没有做到的事情。
现在我对/rewind有一个更加深刻的理解了,它其实相当于给你每次提问的文件做了一个快照,你可以随时回撤到任意的对话,回到会话开始前的状态。
Sub-agent(子代理):给子任务开独立的 200K 窗口
压缩是对话太长之后的补救措施,治标。Sub-agent 是从架构层面预防对话变长,治本。
原理是给每个子任务开一个全新的 200K 上下文窗口,让它在这个独立空间里工作,完成后只把结果摘要返回给主 agent。
看下五种典型用法:
代码审查:让 sub-agent 读完整 PR 的 diff,输出审查意见。主 agent 只看到审查结果,不消耗 token 在读代码上。适合 PR 超过 500 行的场景。
文件分析:让 sub-agent 遍历某个目录、分析架构、输出摘要。比如"分析 src/ 目录下所有文件的依赖关系"。主 agent 只拿到一份架构图。
搜索调研:让 sub-agent 跑多轮搜索、整理结果、输出结构化摘要。搜索过程会产生几万 token 的工具输出——这些全部在子窗口里,主窗口只看到最终结论。
分治执行:把一个大任务拆成 3-5 个独立子任务,每个交给一个 sub-agent。比如"重构认证模块"拆成"重写登录逻辑""更新中间件""补测试用例"三个子任务。Claude Code 支持在单条消息里同时发起多个 sub-agent 并行执行,所以分治既能省时间,也能省主窗口的上下文。
Builder-Validator:一个 sub-agent 写代码,另一个 sub-agent 审查代码。两个独立的上下文窗口意味着审查者不会受到写代码时的上下文偏见影响。社区里有人报告这种模式比在同一个窗口里"写完再检查"效果好很多。
Sub-agent 的限制也要清楚:无过程可见性(你只能看到最终结果)、每次需要显式传递所有信息(子窗口不继承主窗口的上下文)。这意味着它更适合"发射后不管"的任务——你把要求说清楚,让 sub-agent 自己跑完,拿结果回来。不过 Claude Code 支持在一条消息里同时启动多个 sub-agent 并行执行,对于独立子任务可以大幅节省等待时间。
五种操作什么场景用哪个,下面这张速查卡做了对照。
速查卡
信号 | 操作 | 什么时候用
完全不相关的新任务 | `/clear` | 每次切换大方向
发现走错方向,能指出"从哪步错" | `/rewind` | 错误决策可定位时
上下文 >60%,当前任务还要继续 | `/compact` | 大任务前、方向切换时
重活但中间产物不需要留在主窗口 | sub-agent | 文件分析、搜索、代码审查
简单追问、小修改 | continue | 快速确认,上下文消耗小
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com















