大夥兒,如果你現在的桌面跟我一樣,爲了寫行代碼得開個 GPT-5.3-Codex,爲了查點資料得換成網頁搜索,中間還忍不住想切到 Claude 調戲一下…… 這種“精神分裂”式的 AI 體驗,可能真的要到頭了。
就在剛纔(北京時間3.6日3點左右),OpenAI 毫無徵兆地甩出了一枚深水炸彈:GPT-5.4 正式發佈。
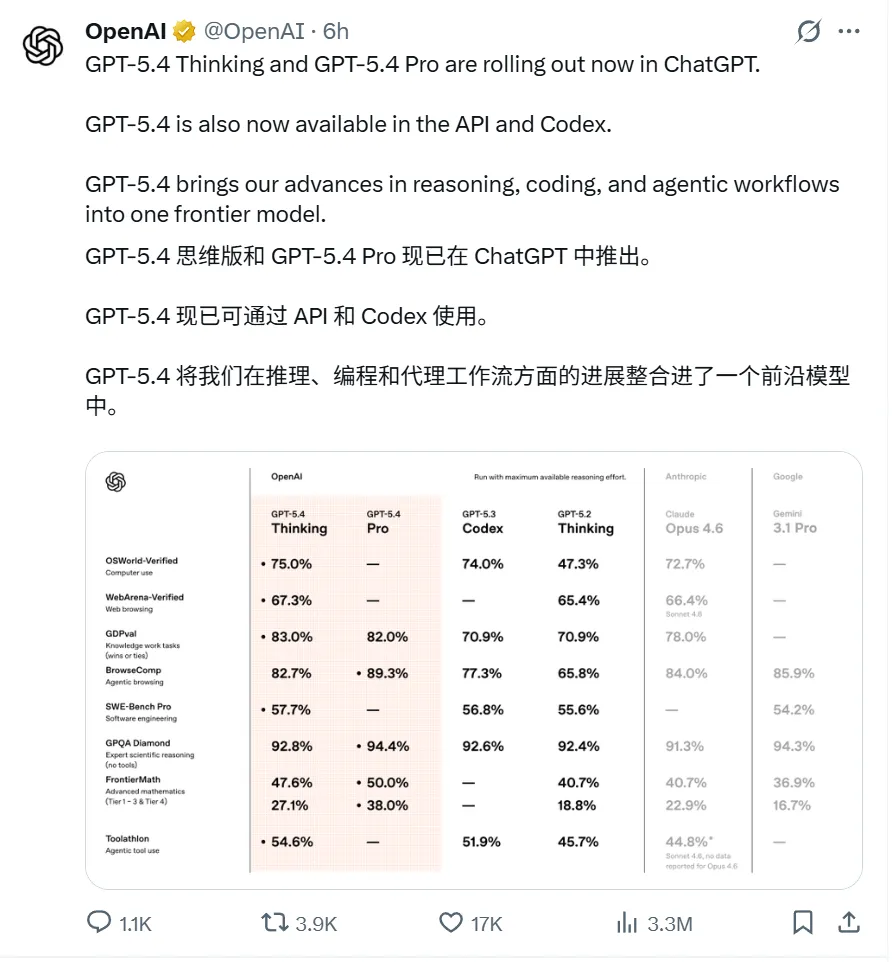
這次的升級邏輯非常簡單粗暴——整合,且拒絕平庸。 它把編程、推理、原生計算機操控、網頁搜索和百萬級別的上下文,全部塞進了一個模型裏,而且各項能力指標非但沒縮水,反而把前代按在地上摩擦 。
山姆·奧特曼也在 X 上發了條雲淡風輕的推文,總結了五個方向:工作更強、搜索更準、原生操控、百萬上下文、隨時介入 。

說白了,OpenAI 這次是想把咱過去兩年用 AI 時最憋屈的幾個痛點,一次性給剷平了。
知識工作:十次有八次,AI 比專業人士還穩
以前覺得 AI 只是個嘴強王者,但這次 GPT‑5.4 在 GDPval 基準測試上的表現確實有點狠 。這個基準橫跨了美國 GDP 貢獻最大的 9 個行業,任務全是職場裏真實發生的,比如給投行寫財務模型、給醫院排急診班次 。
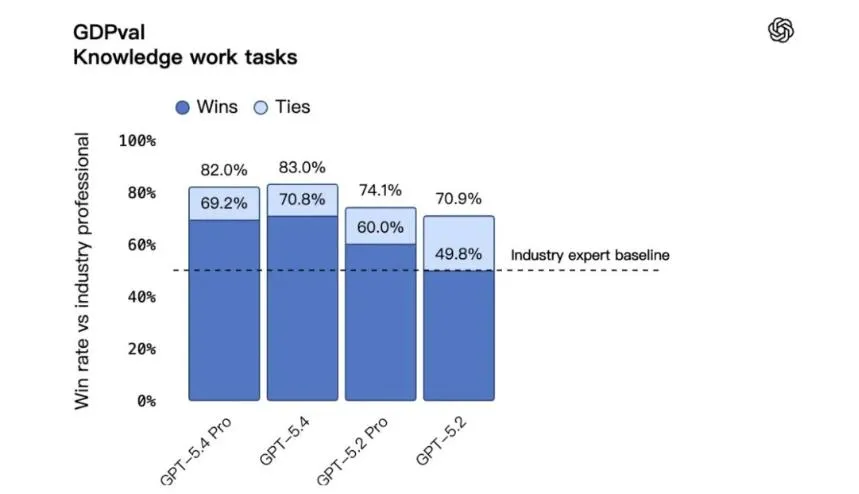
結果顯示,GPT‑5.4 的產出有 83.0% 的比例被行業從業者認爲達到或超過了人類水準 。上代 5.2 版本這個數據是 70.9% 。
特別是在財務建模這種髒活累活上,GPT‑5.4 模擬初級分析師的表現直接衝到了 87.3%,比 5.2 版本高了將近 20 個百分點 。連最讓人頭疼的幻覺問題也收斂了不少,單條陳述的出錯概率比 5.2 降低了 33%,完整回覆含錯率降低了 18% 。
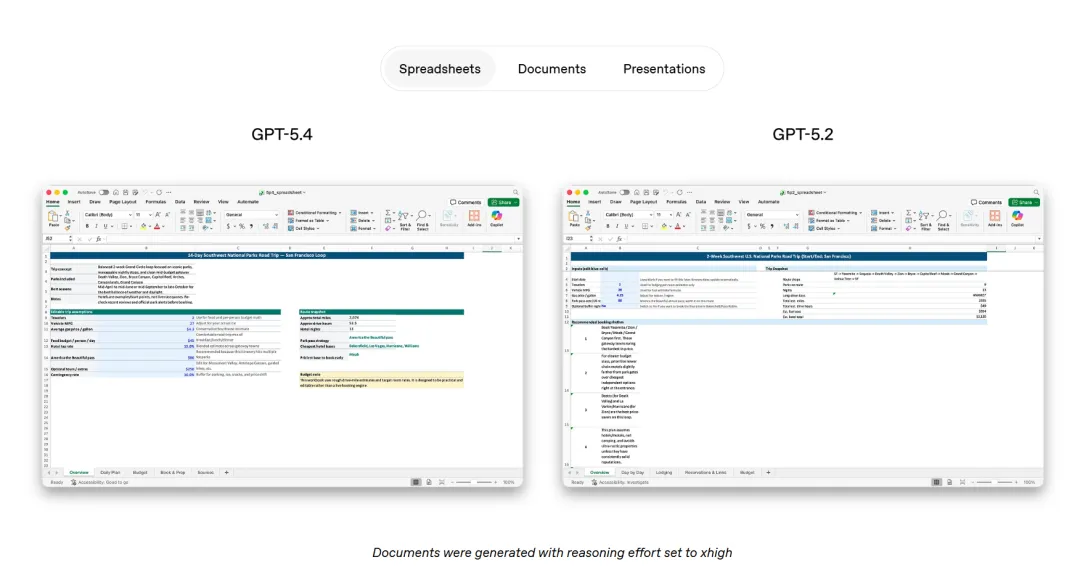
編程:從“寫代碼”進化到“造系統”
以前寫代碼,模型寫完你得複製出來,自己跑一下,報錯了再喂回去。
現在 GPT-5.4 自帶了一個 Playwright Interactive 的實驗性功能。簡單說,就是模型現在能一邊寫代碼,一邊自己開個瀏覽器窗口盯着。它既是程序員,也是測試員。
OpenAI 展示了一個案例:只給了一條輕量提示詞,它就寫出了一個帶遊客尋路、排隊算法、實時資金統計的模擬遊戲。整個過程,從代碼構建到多輪自動化測試驗證,模型自己全包了 。甚至有博主試完後感嘆:“Minecraft 基本上被攻克了,我得找個更難的東西來考它。”
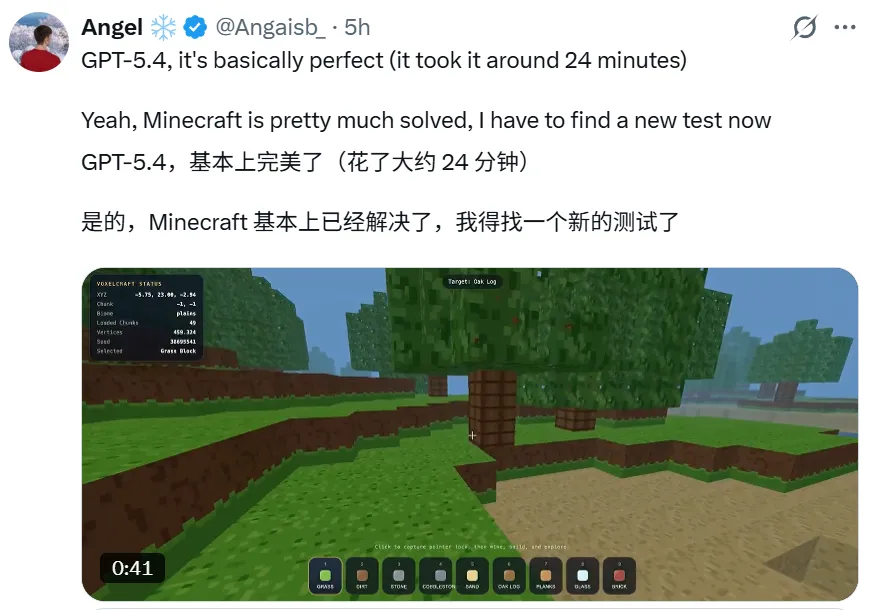
如果你是重度開發者,開啓 Codex /fast 模式後,Token 生成速度還能再快 1.5 倍 。這種流暢感,誰用誰知道。
原生計算機操控:它真的會自己動
這是本次發佈最硬核的部分。以前 AI 操控電腦像是在“隔空指揮”,現在 GPT-5.4 進化到了“原生內置” 。
在 OSWorld-Verified 基準測試裏,GPT-5.4 的桌面導航成功率達到了 75.0%,而人類的平均基線也就 72.4% 。沒錯,在這個領域,AI 已經正式完成了對人類的超越。
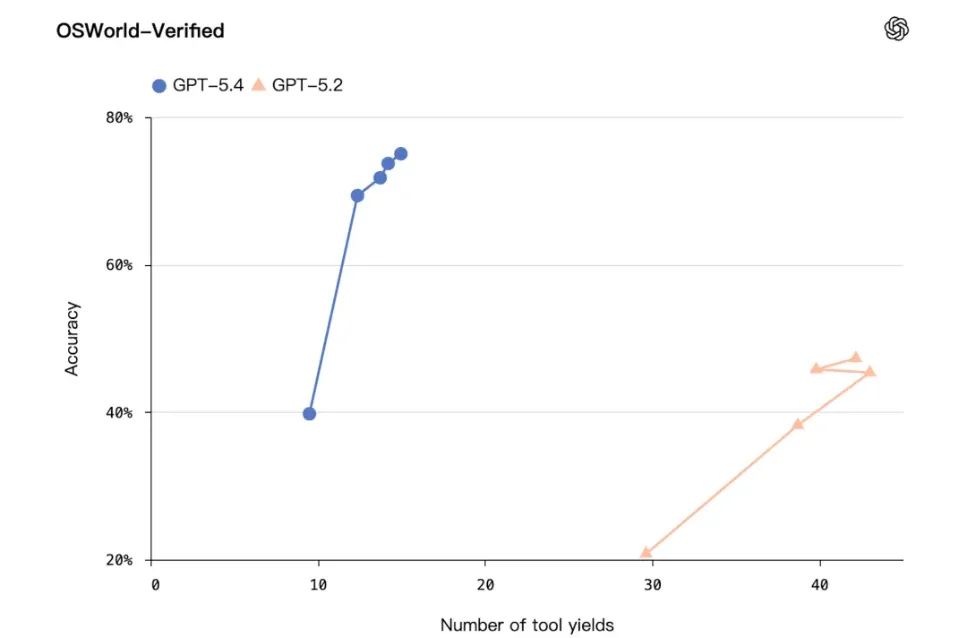
現實裏的表現更狠:有一家叫 Mainstay 的公司,用它去三萬個稅務網站自動填表,三次以內的成功率是 100% 。這背後靠的是視覺感知能力的史詩級加強,它現在能最高支持 1024 萬像素的超清圖像輸入 。界面上再小的按鈕,在它眼裏也跟路標一樣清晰。
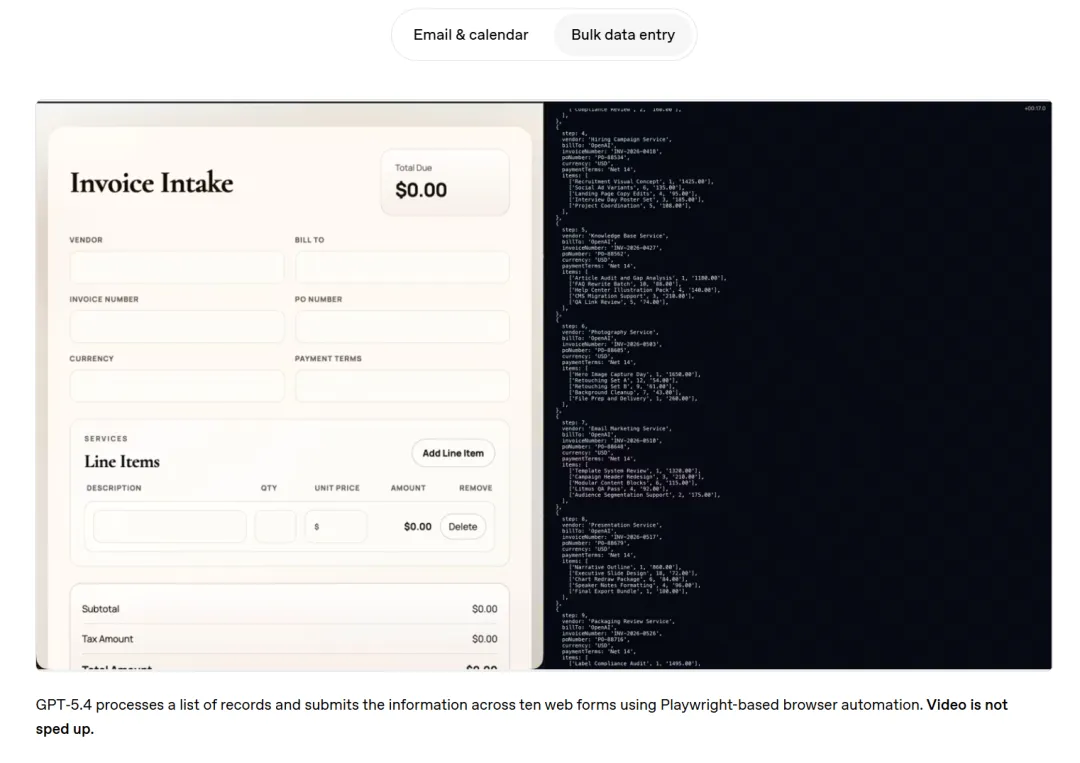
工具調用與網頁搜索:不再爲“說明書”浪費錢
以前折騰 AI Agent 的哥們兒肯定深有體會,如果你掛了幾十個 MCP 工具,每次對話前模型都得強行讀一遍所有工具的說明書。不管這次用不用得上,Token 已經實打實地花出去了。
GPT‑5.4 換了個聰明思路,引入了 工具搜索機制。簡單說,模型現在先看一眼工具清單,只有當它真的需要用某個工具時,纔會去把那個工具的詳細說明取過來 。
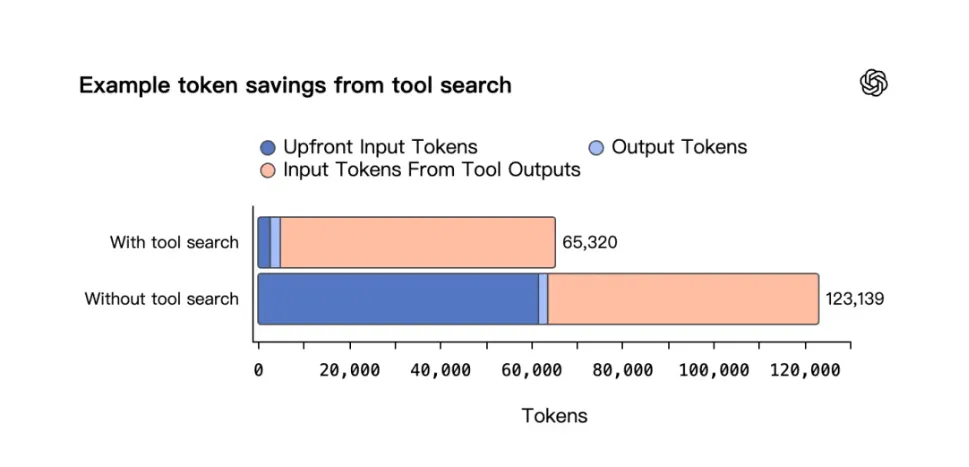
在 250 項任務的實測中,即使開啓 36 個服務器,這套機制在精度一點沒掉的前提下,把總 Token 消耗直接砍掉了 47% 。這省下來的可都是真金白銀。
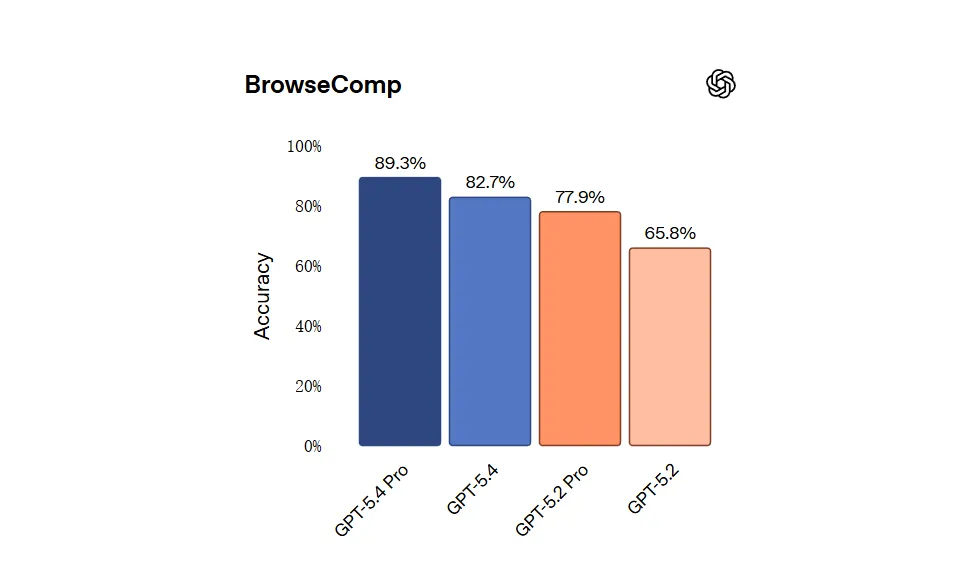
網頁搜索這一塊兒也沒落下。GPT‑5.4 在 BrowseComp 基準上拿到了 82.7% 的分數,Pro 版更是衝到了 89.3%,創下了業界最高分 。用 Zapier CEO 的話來說,這模型的持續性極強,它會在其他模型放棄的地方繼續挖下去 。
百萬上下文:是神藥也是試驗品
GPT-5.4 這次把上下文拉到了 100 萬 Token 。理論上,你能把一整個項目的文檔全塞進去對話。
但大夥兒先別急着狂歡,飛碟AI得給你們潑盆冷水。測試顯示,最穩定的區間依然是 128K 到 272K 之間 。一旦超過這個量,準確率就會像過山車一樣下滑,512K 到 1M 區間的得分只有 36.6% 。
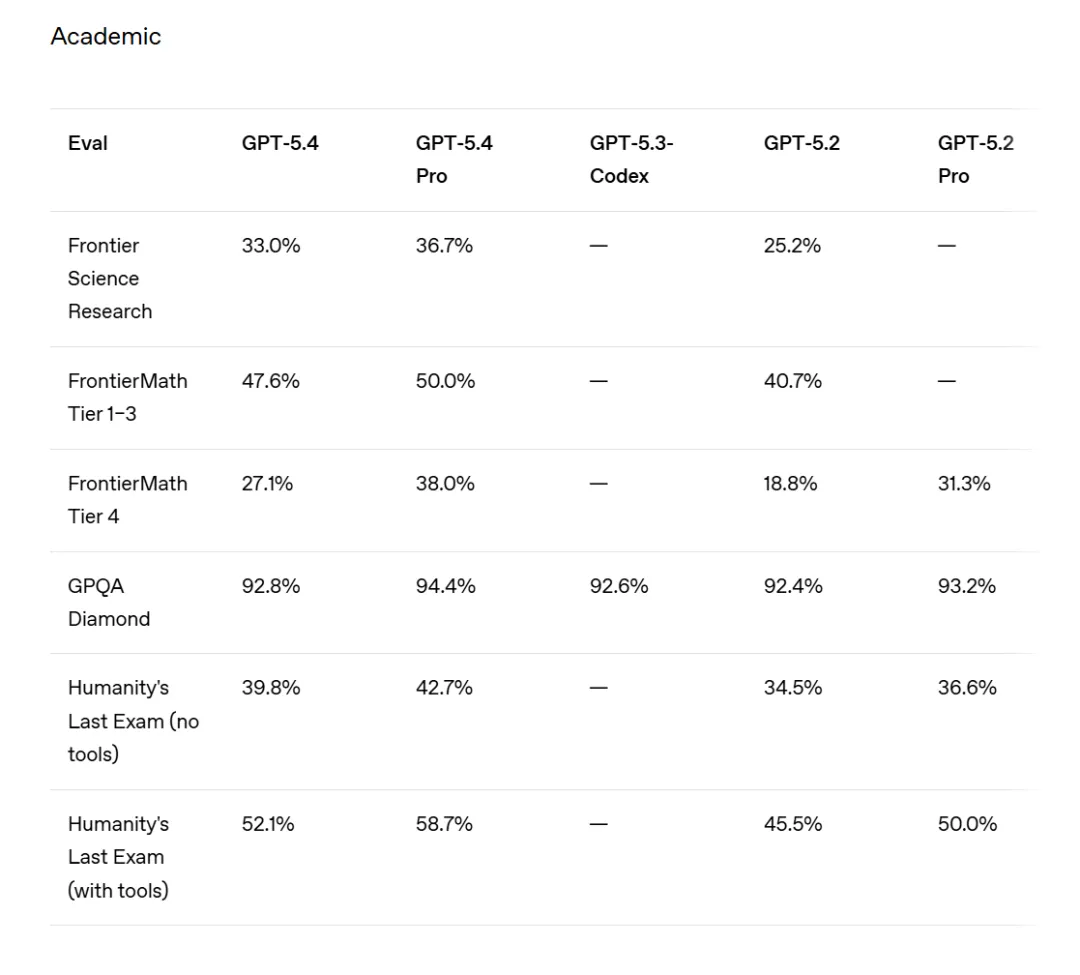
而且這玩意兒不僅容易記錯,還貴。超過 272K 的請求,按兩倍用量計費 。如果你不是真的要讓它讀一整本《大英百科全書》,建議還是省着點用。
懸在頭頂的“思考成本”
最後,咱得聊聊那個讓人又愛又恨的“過度思考”。
GPT-5.4 Pro 的推理能力確實恐怖,甚至能解出人類數學家需要幾周才能搞定的 FrontierMath 難題 。但也正因爲它太想表現了,有時候會鬧出笑話。
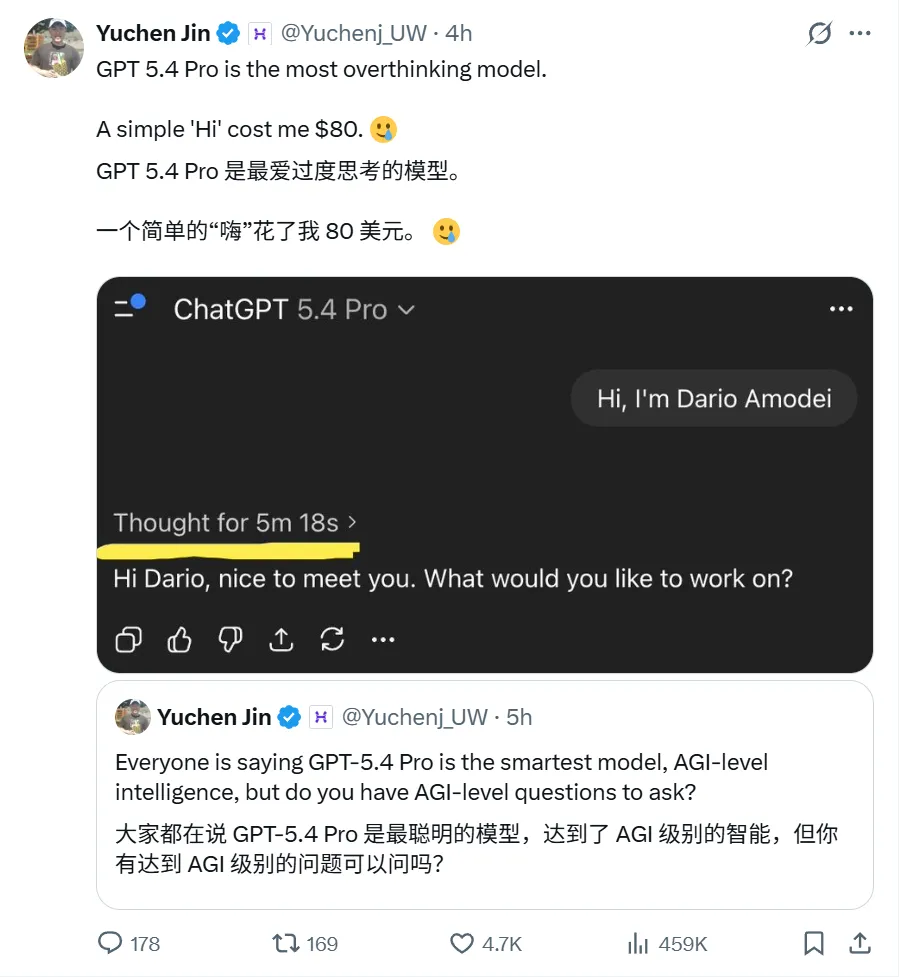
Hyperbolic 的創始人就吐槽說,他只是跟 GPT-5.4 Pro 說了句“Hi”,結果這模型就開始瘋狂推理,直接燒掉了 80 美元 。
所以大夥兒記住了,Pro 版的“重火力”是留給硬核任務的。日常問個天氣、打個招呼,標準版(輸入 2.5 美元/百萬 Token)真的夠用了 。
最後
過去兩年,我們一直在討論 AI 有多聰明,但這種聰明大多停留在“紙上談兵”。而 GPT-5.4 的出現,標誌着 AI 正在從一個“問答機器”變成一個“執行官”。它不再只是告訴你怎麼做,而是直接替你把事情辦了。這個閉環一旦完成,很多行業的玩法真的要重寫了。
那麼問題來了,面對這個能自己操作電腦、勝率壓過專業人士的 GPT-5.4,你最想讓它幫你分擔哪項“帶薪摸魚”的任務?
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com














