凌晨,Anthropic 丟出重磅更新,跟本公衆號昨天發佈的爆料不一樣,本以爲是發佈的Claude 5.0,但是這次版本號是4.6,還沒來得及歡呼,緊接着OpenAI 的Codex也發佈新版本 GPT-5.3-Codex。
如果說昨晚之前,我們在討論 Prompt Engineering(提示詞工程)還能活多久,那麼今天過後,這個職業已經正式進了ICU。
Sam Altman 昨天剛在 X 平臺上凡爾賽完 Codex 的“百萬活躍用戶”,今天就用 GPT-5.3-Codex 告訴世界:AI 進化的閉環已經完成。而大洋彼岸的 Anthropic 則用 Claude Opus 4.6 證明:比手速我可能輸,但比腦子,你們都是弟弟。
本號帶大家,都來過一遍
01
OpenAI 的陽謀:從“副駕駛”篡位到“老司機”
OpenAI 的技術文檔裏藏着一句極具分量的話:“這是我們第一個在創造自己的過程中,發揮了關鍵作用的模型。”

翻譯一下:GPT-5.3-Codex 參與了 GPT-5.3-Codex 的代碼編寫、數據清洗和架構優化。 不是套娃,這是遞歸進化。
這種進化直接體現在了恐怖的“行動力”上。還記得那個模擬人類操作電腦的 OSWorld-Verified 基準測試嗎?前代模型 38.2% 的準確率連及格線都夠不上,像是剛學電腦的老大爺。但這次,GPT-5.3-Codex 直接跳漲到了 64.7%。
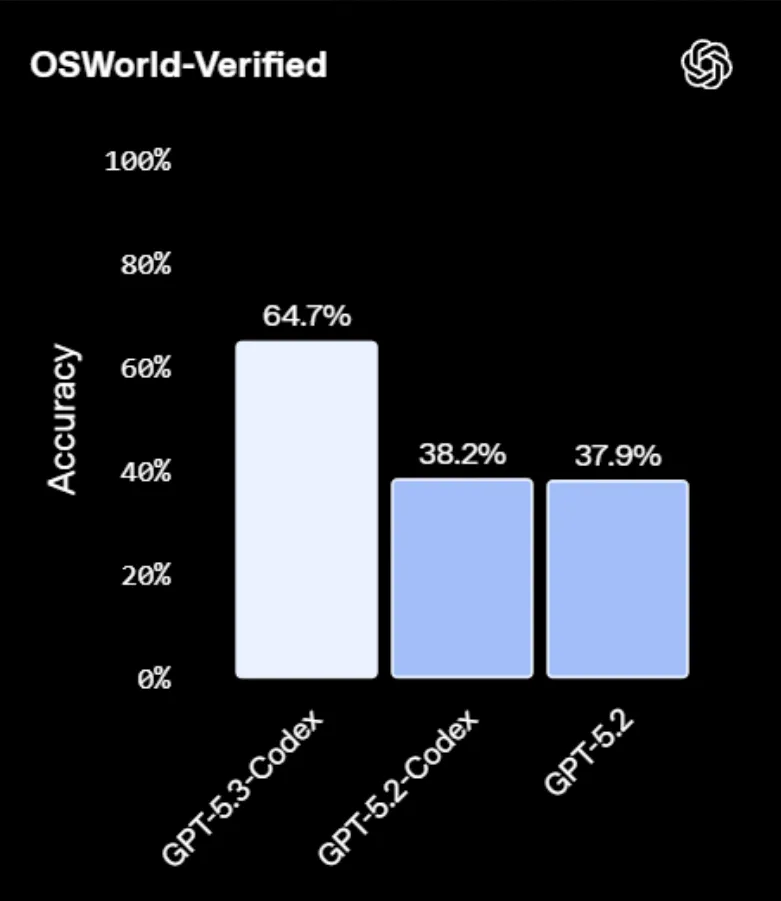
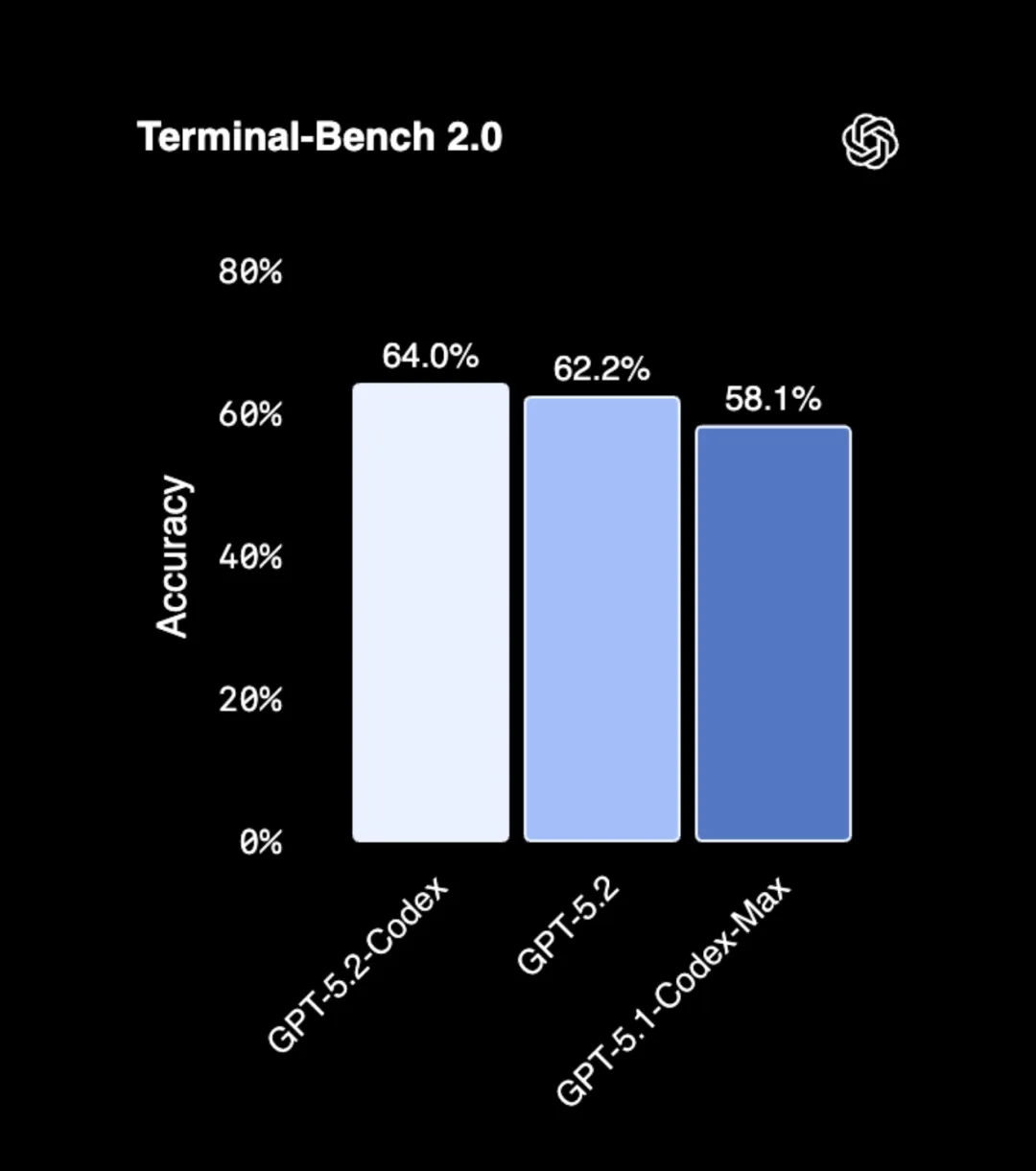
這意味着,AI 距離像你一樣熟練地甩鼠標、切屏、操作 ERP 系統,只剩下一層窗戶紙。在 Terminal-Bench 2.0(命令行操作)中,它更是拿下了 77.3% 的高分,把 GPT-5.2(62.2%)遠遠甩在身後。
更有趣的是,OpenAI 引入了一項名爲 “Ghost Cursor”(幽靈光標) 的新技術。在演示視頻中,你只需要告訴它“幫我把上個月的財報數據填進 SAP 系統”,你就能看着鼠標自己在屏幕上飛舞,點擊、輸入、甚至處理彈窗報錯。
OpenAI 的野心已經寫在臉上了:微軟常說 AI 是 Copilot(副駕駛),但現在 AI 想做那個能掌控方向盤、甚至能自己修車的司機。
值得一提的是,OpenAI 這次罕見地“認慫”了硬件依賴。官方博客特地強調:整個模型的訓練和推理優化,完全基於 NVIDIA GB200 NVL72 集羣完成。這一波高情商的“感謝英偉達”,不僅給足了黃仁勳面子,也側面印證了 GPT-5.3 對顯存帶寬的吞噬能力——畢竟要實時理解 4K 分辨率的屏幕流,普通芯片根本扛不住。

02
Claude 的反擊:告別“金魚記憶”,構建“蜂羣思維”
相比於 OpenAI 在手速上的激進,Anthropic 發佈的 Claude Opus 4.6 則是在“腦力”和“耐力”上死磕。
很多企業用戶都有一個痛點叫 Context Rot(上下文腐蝕):號稱 200k 上下文,但塞進去的數據一多,AI 就開始顧頭不顧尾。
這次,Claude Opus 4.6 拿出的數據簡直是降維打擊。
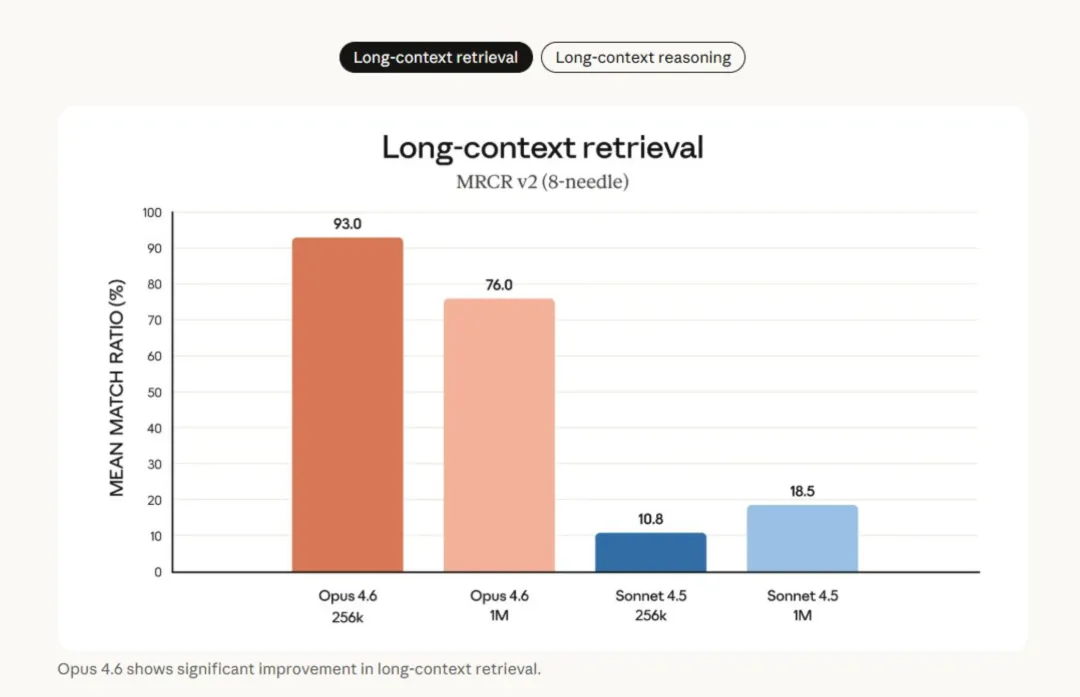
在 MRCR v2(長文本大海撈針) 測試中,Claude Opus 4.6 的召回率高達 76%。作爲對比,上一代 Sonnet 4.5 只有慘不忍睹的 18.5%。這得益於他們新研發的 “Dynamic Attention Sinks”(動態注意力匯聚) 技術,讓模型在處理長達 1M 的 Token 時,依然能像雷達一樣鎖定細節。
但真正讓開發者頭皮發麻的,是 Anthropic 推出的實驗性功能:Agent Teams(智能體戰隊)。
在新的 Claude Code 環境中,你不再是和一個 AI 對話,而是指揮一個團隊:
Team Lead(組長): 負責拆解任務、分配工單、Code Review。
Specialists(專家): 獨立的 Session,有的負責前端,有的負責數據庫,有的負責寫測試用例。
Parallel Execution(並行賽馬): 遇到頑固 Bug?你可以一鍵生成 5 個 Agent,分別驗證 5 種不同的假設,最後只彙報成功的那一個。
爲了展示極限,Anthropic 的研究員 Nicholas Carlini 搞了個瘋狂實驗:他沒有寫一行代碼,而是扔了 2 萬美元 的 API 額度,讓 16 個 Claude Opus 4.6 組成一個“全自動軟件開發團隊”。
結果?短短兩週內,這羣 AI 自主進行了 2000 多個編程會話,從零手寫了一個 10 萬行代碼的 Rust 編譯器,甚至成功編譯了 Linux 6.9 內核。

03
天才瘋子 vs 靠譜老牛
知名 AI 評測人第一時間的“盲測”(Vibe Check)評價非常精準:
Claude Opus 4.6 是“高上限,高方差”(High Ceiling, High Variance)。 它像是一個才華橫溢但偶爾跳脫的天才。在 GDPval-AA(高價值金融分析)測試中,它的 Elo 得分比業界第二高出整整 144 分。如果你需要突破性的靈感、複雜的法律文書分析,或者設計一套全新的系統架構,選它。
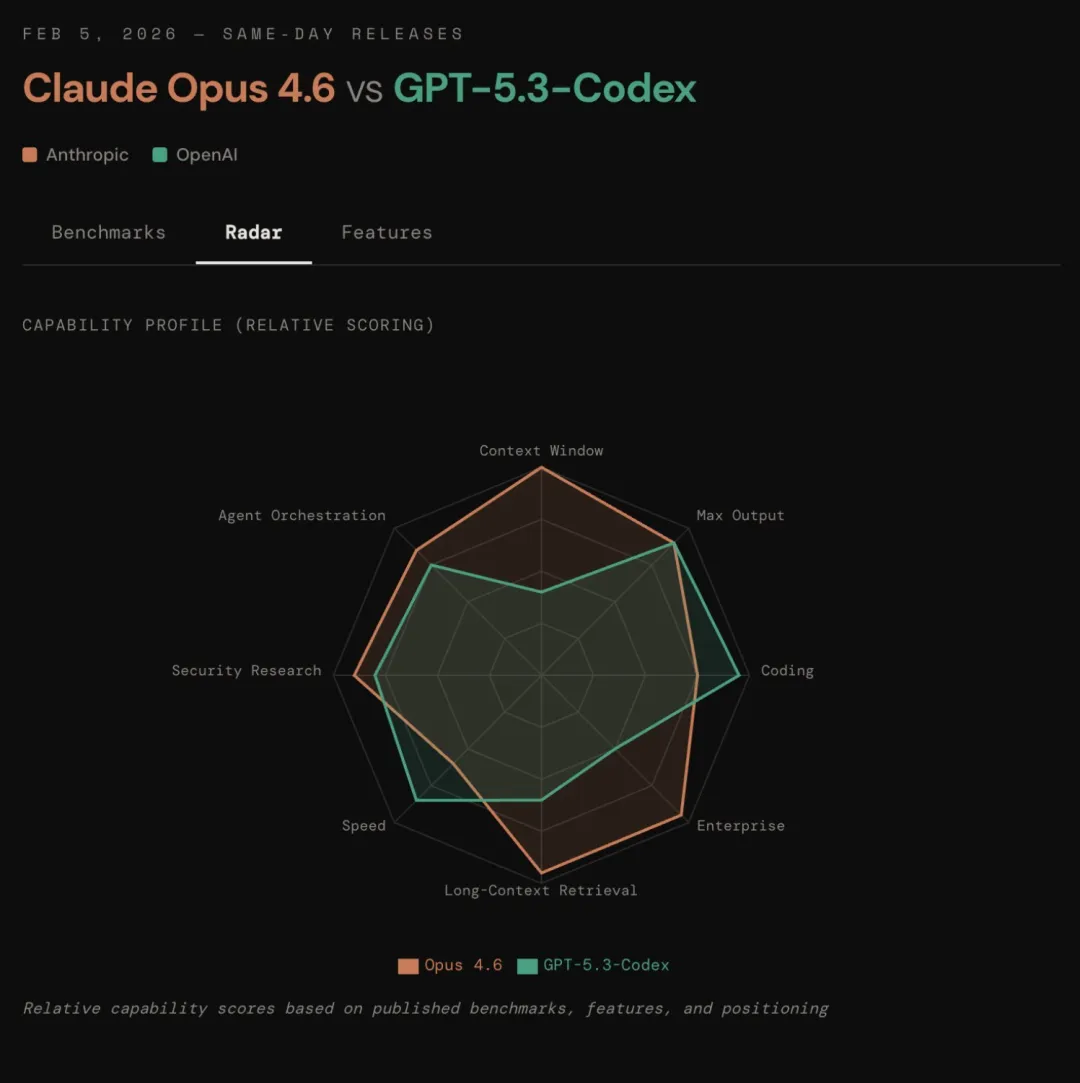
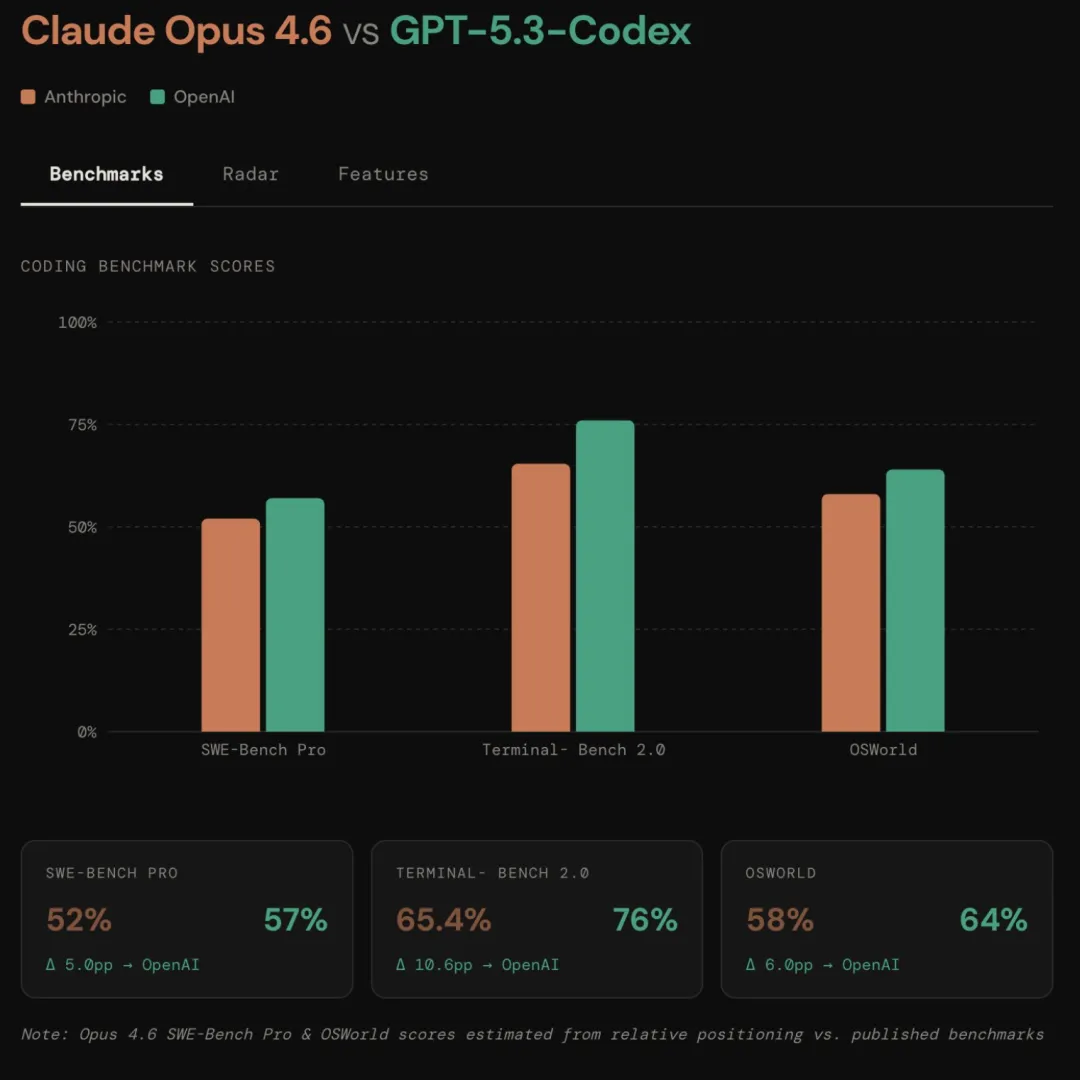
GPT-5.3-Codex 則是“高可靠,低方差”(High Reliability, Low Variance)。 它像是一個經驗豐富、絕不掉鏈子的資深工程師。在 SWE-Bench Pro(真實工程難題)中,它展現了 SOTA 水準,而且極其抗干擾。如果你需要修 Bug、寫腳本、或者讓它在半夜三點幫你把服務器重啓並恢復數據,它是最讓人安心的選擇。
03
尾聲:2026 年的新職場
OpenAI 和 Anthropic 的這次“撞車”發佈,其實是在向所有打工人傳遞同一個信號:Prompt Engineering 已死,Agent Management 當立。
當 ChatGPT 可以自主修 Bug 甚至操作你的終端,當 Claude 可以一次性吞吐海量文檔並精準定位細節時,我們不再需要像教小學生一樣,把指令拆解得碎碎念。
相反,我們需要做的,是學會如何以管理者的身份,去定義目標(OKR)、審覈結果(Code Review)、以及決定在什麼時候,把什麼任務交給哪位 AI 員工。

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com













