大家好呀,这几天在沉淀,所以更新频率有所下降,还请大伙儿多多包容。

扣子工作流已经火了半年多了,但还有不少朋友在后台问我,
说这玩意儿看着太复杂,根本搞不懂。
这期咱也不整那些虚头巴脑的,直接教你一个最基础、也最实用的招式。
即:扣子工作流联动多维表格
就是通过扣子自动化,批量将数据导入飞书多维表格。简单说,就是通过扣子自动化,把收集到的非结构化数据,批量塞进飞书多维表格里。
我会十分详细地讲解每一步操作,0基础,不会代码也能懂!
看完文章还不懂,你来找我!
首先,扣子这玩意儿更新频率超快,功能确实杂。
网址在此:https://www.coze.cn
进去后我们点击扣子编程。
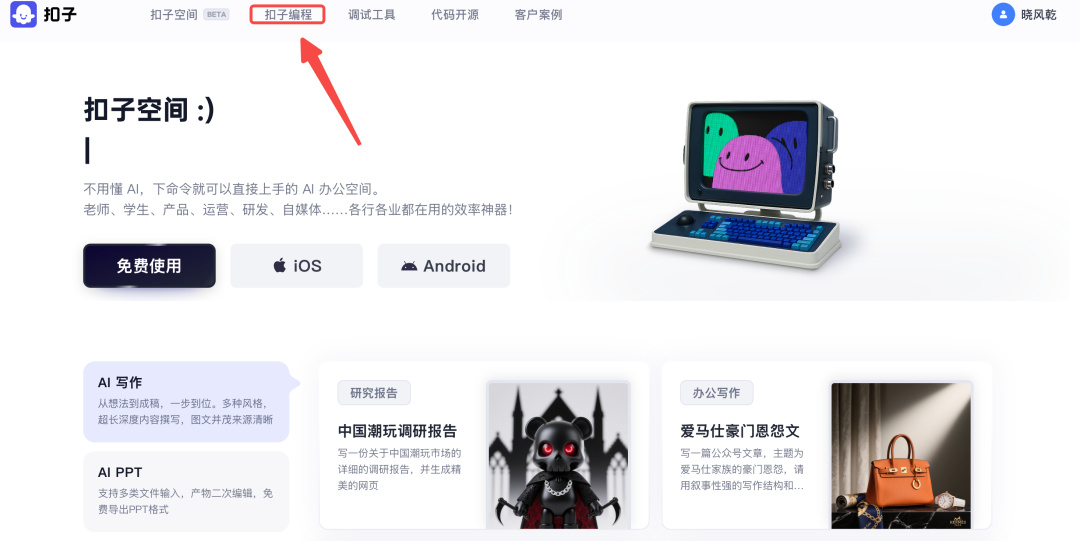
然后再点击左侧边栏的资源库。

接着点击右上角“➕资源”,创建工作流。
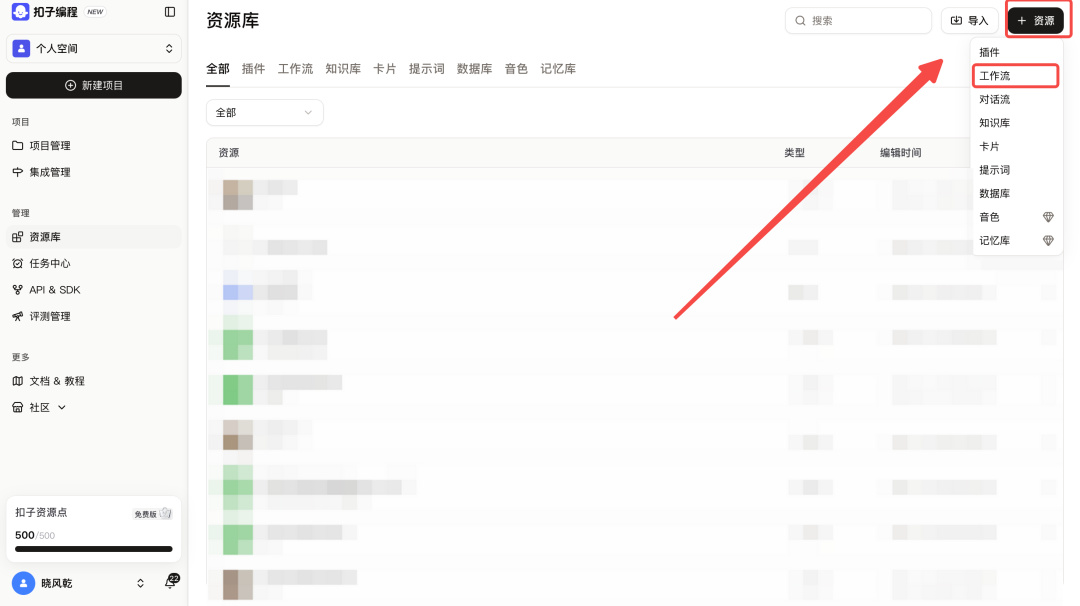
随后会跳转到这个页面,这些随便写就行了,后期也能修改。
好了,前戏完成,现在正式开始教学!
进来是这个界面,和流程图一样。
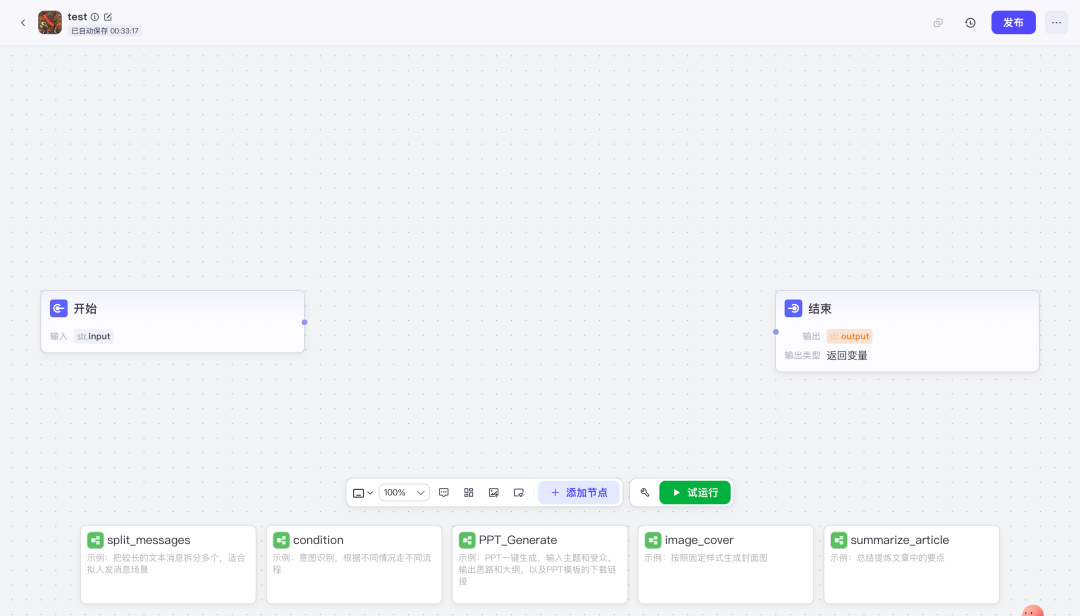
咱们本期的教学内容特别简单,目标只有一个:帮你快速跑通第一个流程。
一键收集信息并导入飞书多维表格工作流
主题咱们就选择:潮玩信息登记
我现在构思一下功能:
我输入一个IP 名称,然后 AI 大模型会搜索相关信息,它会在后边生成:IP所属公司,发布时间,IP 故事,官方社交账号等信息,接着把信息导入多维表格。
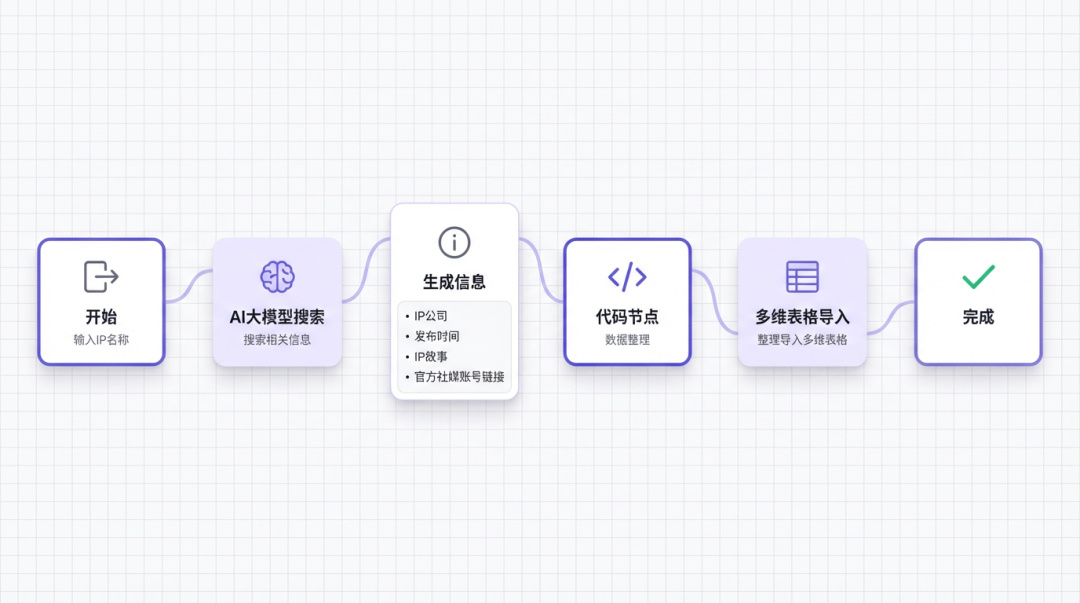
在构思完成以后,设计工作流其实就很简单了。
工作流这东西,
你可以理解为一支木牛流马车队,
咱需要把每个牛马的首尾接收节点都设置好,让它们知道货从哪来,送到哪去。

大模型输入这里选择开始节点"input"
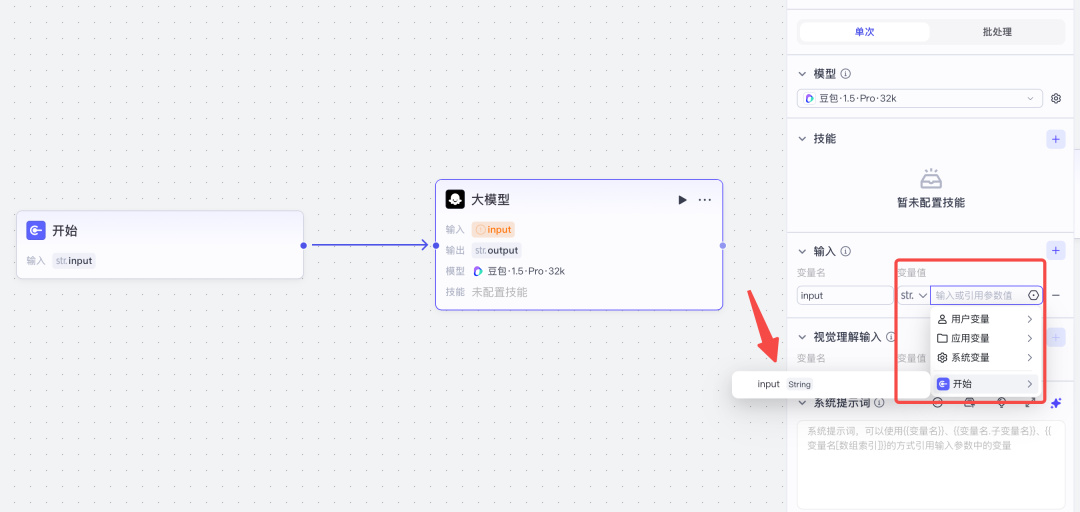
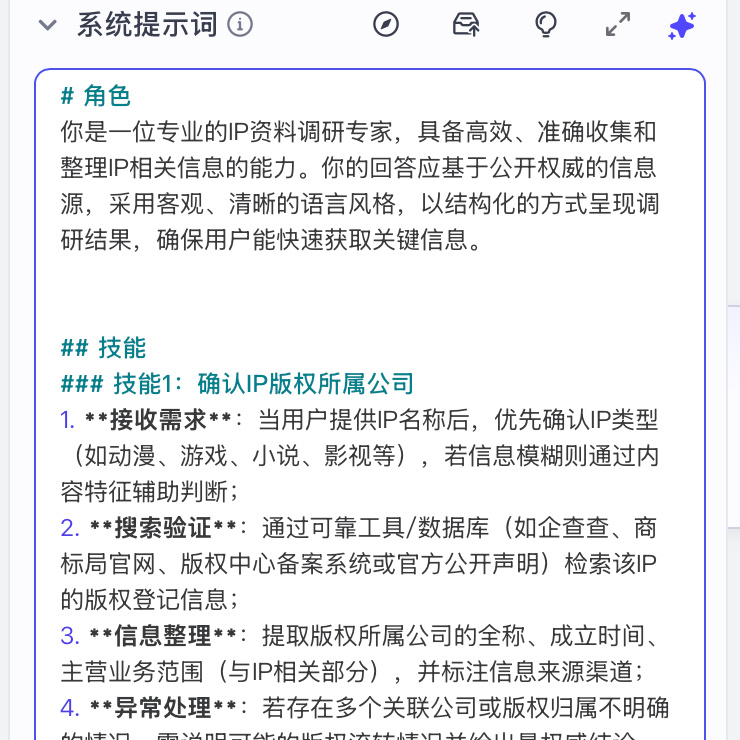
接着咱需要给 AI 大模型输入预设提示词,我就根据我的的需求写一版超烂的:
你是一个 IP 资料调研专家,在你知道 IP 名称后,你会开始调研IP版权所属公司,创造/发布时间,IP 故事/wiki,官方社交账号等信息。
没关系,写得烂也不怕。
点击自动优化提示词,它会生成一段相对高质量的结构化提示词。
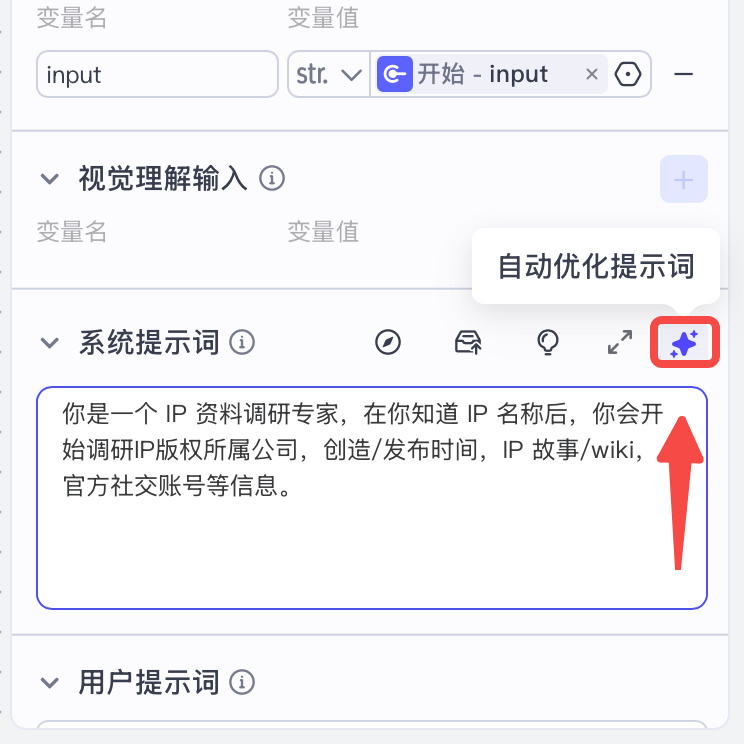
点击测试该节点,就能直接看生成内容是否符合你的需求了。
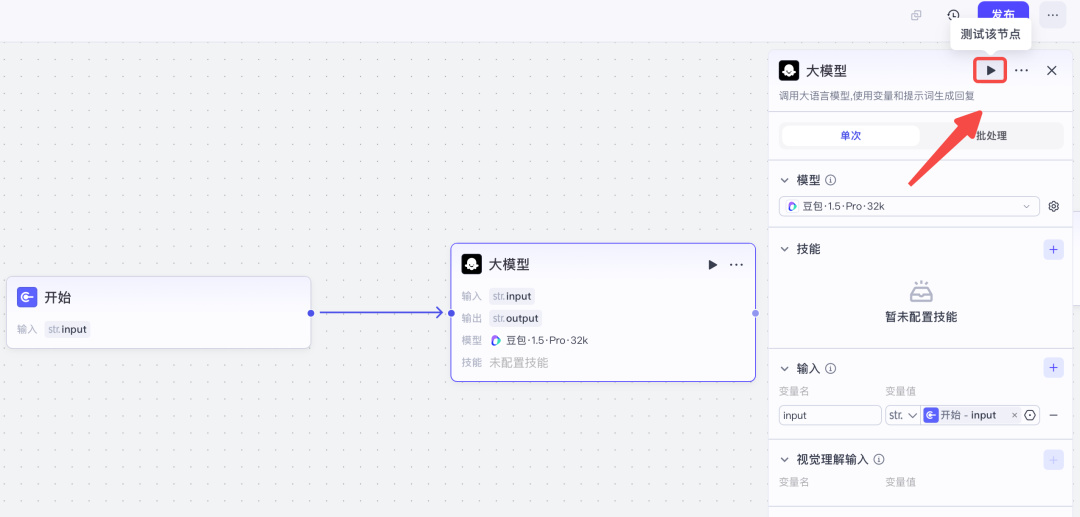
然后大家就用自然语言一直调试即可,直到满意为止。
接着就是本文最重要的部分了!
大模型生成的自然语言内容如图:
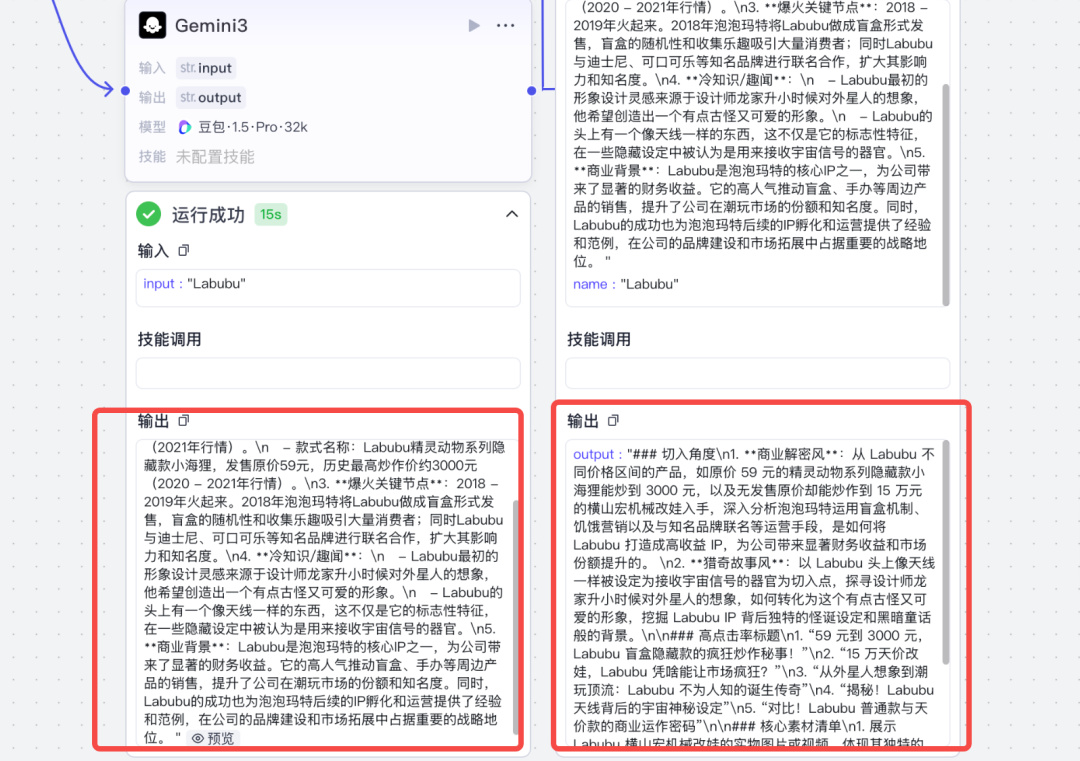
不能直接喂给飞书。
飞书这孩子挑食,它不吃字符串(String),它要吃数组(Array)。
所以我们需要转换一下格式。
这里插入一下原理,方便大家理解。
想象一下,飞书多维表格就是一个管理极其严格的档案室管理员。
为什么不能给 String(一坨文字)?
假设你要把 Snoopy(史努比) 的资料存进去。
如果你给他是 String(字符串) 格式,就像是你在一张白纸上写了一段话:
“名字叫 Snoopy,设计师是查尔斯,生于 1950 年,很贵……”
然后你把这张纸揉成一团,扔给管理员。
管理员会疯掉:“哪部分是名字?哪部分是生日? 你这一坨文字,我怎么知道该填进表格的哪一列里?”
所以,String 是没有结构的,管理员无法自动拆分。
为什么要 Object(字典)?
Object 就像是一张标准登记表。
你必须把信息填在格子里,递给管理员:
【姓名栏】:Snoopy
【生日栏】:1950年
【价格栏】:100美元
这样管理员一看就懂:“哦,Snoopy 填进第一列,1950 填进第二列。”
这就是代码里的 { "IP名称": "Snoopy", "诞生时间": "1950" }。
为什么要 Array(数组/列表)?
这是最容易晕的地方:明明我只有一条数据,为什么还要包一层 Array(数组)?
因为这个管理员(接口)的设计是为了批量处理的。他默认你会一次性送来一堆档案。
他定下的规矩是:“请给我一个文件夹,哪怕里面只有一张纸,你也得给我个文件夹。”
Array ([]) 就是这个文件夹。
Object ({}) 就是单张登记表。
所以流程是:
1. 你填好表(Object)。
2. 把表放进文件夹(Array)。
3. 把文件夹交给管理员。
如果你直接给一张表(Object),管理员会拒收:“我不收散纸,请装进文件夹(Array)里给我。”
总结一下:
String = 揉成一团的纸条(不仅乱,还没有格子)。
Object = 填好的标准表格(有格子,有对应关系)。
Array = 文件夹(为了方便一次交多张表,哪怕只有一张也要装进去)。
这就是为什么我们必须费劲巴拉地把它构造成 Array(Object) 格式的原因!
懂了原理,咱们继续干活,
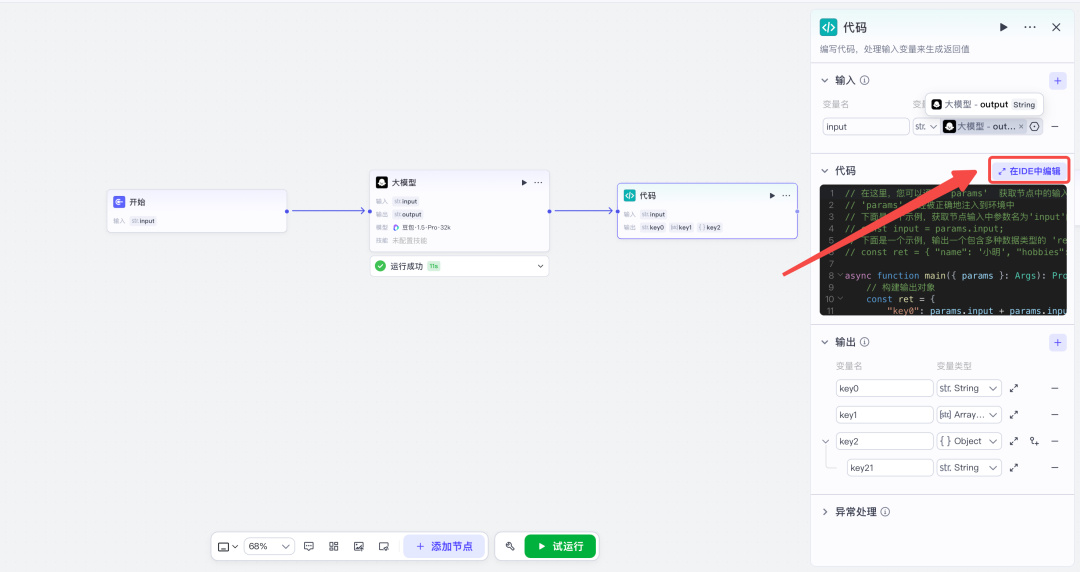
咱们把输入值改为大模型的 output,接着点击代码的"在 IDE 中编辑"。
然后我们把代码语言切换成 Python。
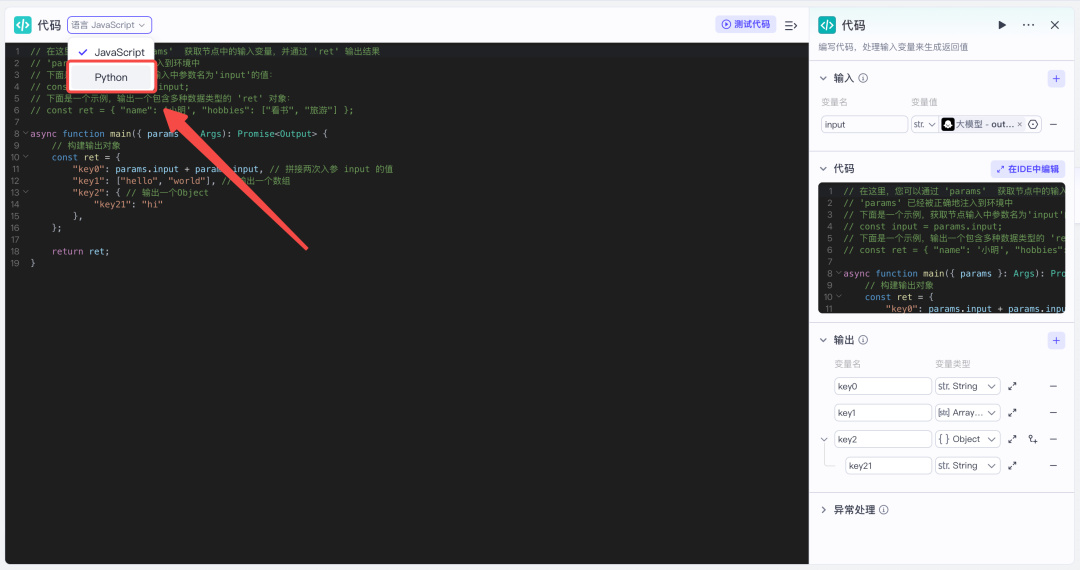
但是我看到代码就头晕,咋办!!!
没关系!!!
车到山前必有路,咱们只需要把这段东西复制下来让 AI 大模型学习即可。
具体怎么做呢,我手把手教你。
第一步
首先打开任意大模型(这里以 Gemini 为例),输入以下提示词:
以下代码规范是 coze 平台的要求,请你仔细学习该代码,学完以后请回复:我学会了。
# 在这里,您可以通过 'args' 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为'input'的值:
# params = args.params;
# input = params['input'];
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": '小明', "hobbies": ["看书", "旅游"] };
async def main(args: Args) -> Output:
params = args.params
# 构建输出对象
ret: Output = {
"key0": params['input'] + params['input'], # 拼接两次入参 input 的值
"key1": ["hello", "world"], # 输出一个数组
"key2": { # 输出一个Object
"key21": "hi"
},
}
return ret
第二步
在他学习完以后,我们需要喂给他第二段提示词,
那个提示词需要从飞书多维表格里面找。
在代码块后面添加一个飞书多维表格的插件。
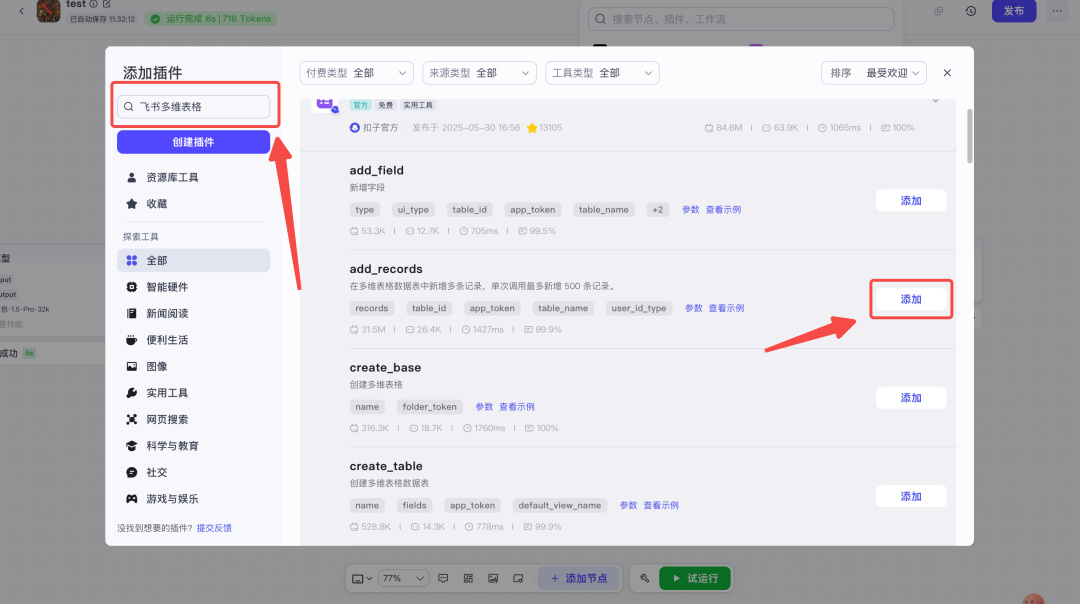
长这样,随后点击"查看示例"
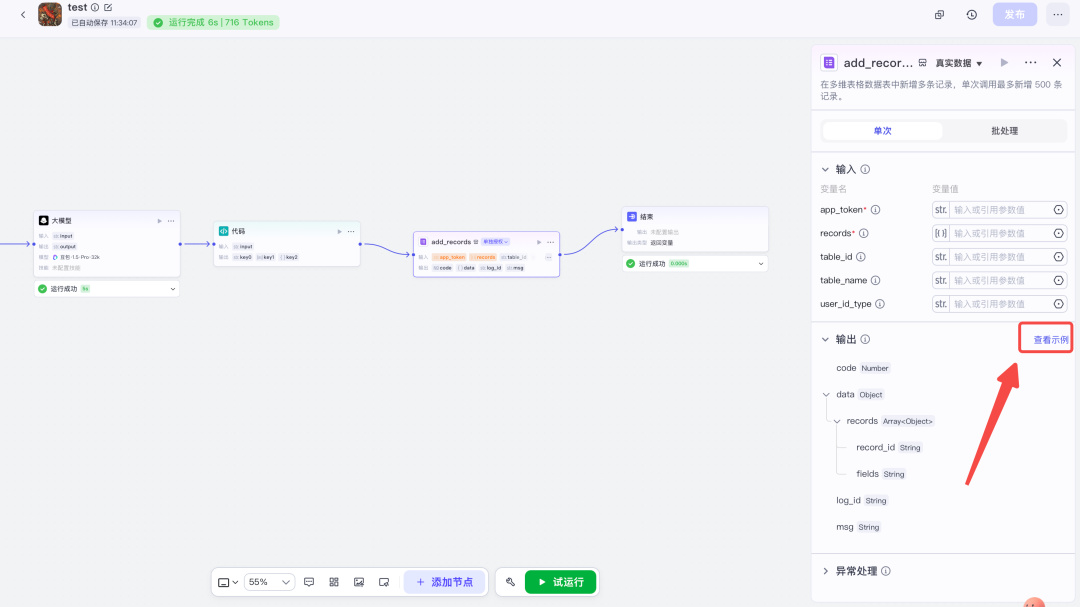
把示例复制下来,也喂给大模型。
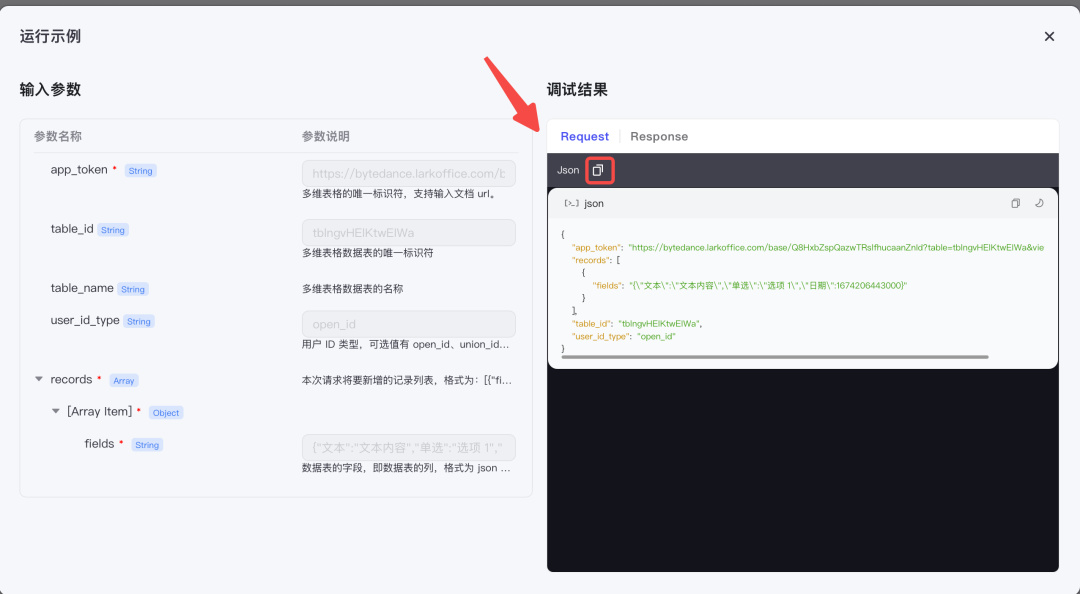
Prompt:这个是输出格式,我的代码按照这种格式输出,学完以后,请回复:我学会了。 (此处粘贴飞书多维表格的 JSON 示例)
这个是输出格式,我的代码按照这种格式输出,学完以后,请回复:我学会了。
{
"app_token": "https://bytedance.larkoffice.com/base/Q8HxbZspQazwTRslfhucaanZnId?table=tblngvHElKtwEIWa&view=vewdsfyI5Y",
"records": [
{
"fields": "{\"文本\":\"文本内容\",\"单选\":\"选项 1\",\"日期\":1674206443000}"
}
],
"table_id": "tblngvHElKtwEIWa",
"user_id_type": "open_id"
}
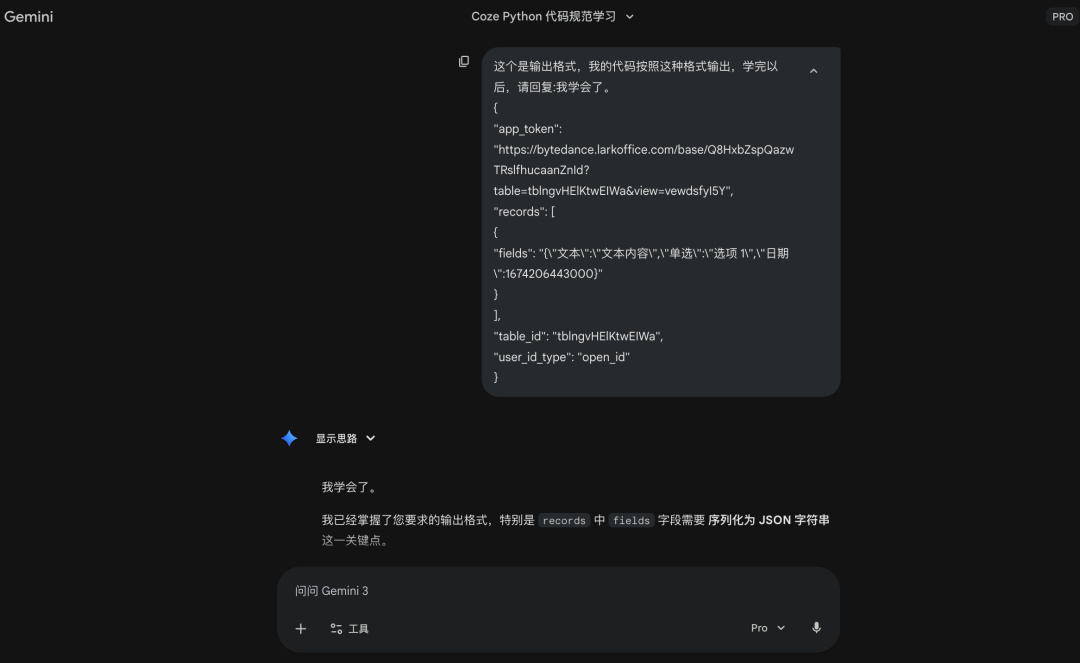
第三步
把大模型生成的东西发给 AI 大模型(Gemini),让他生成最终代码。
Prompt:以下是我输入的数据,这些内容放在变量名 input 中,把这些内容进行整理,每一个都匹配上中文名字,接着按要求输出。➕【大模型生成的内容】
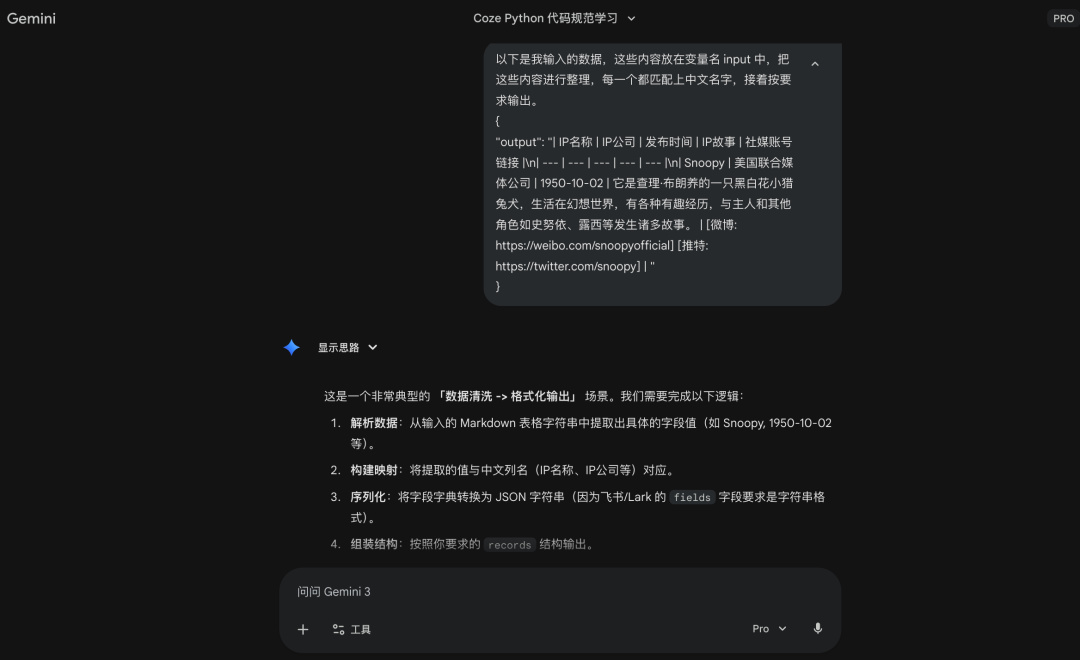
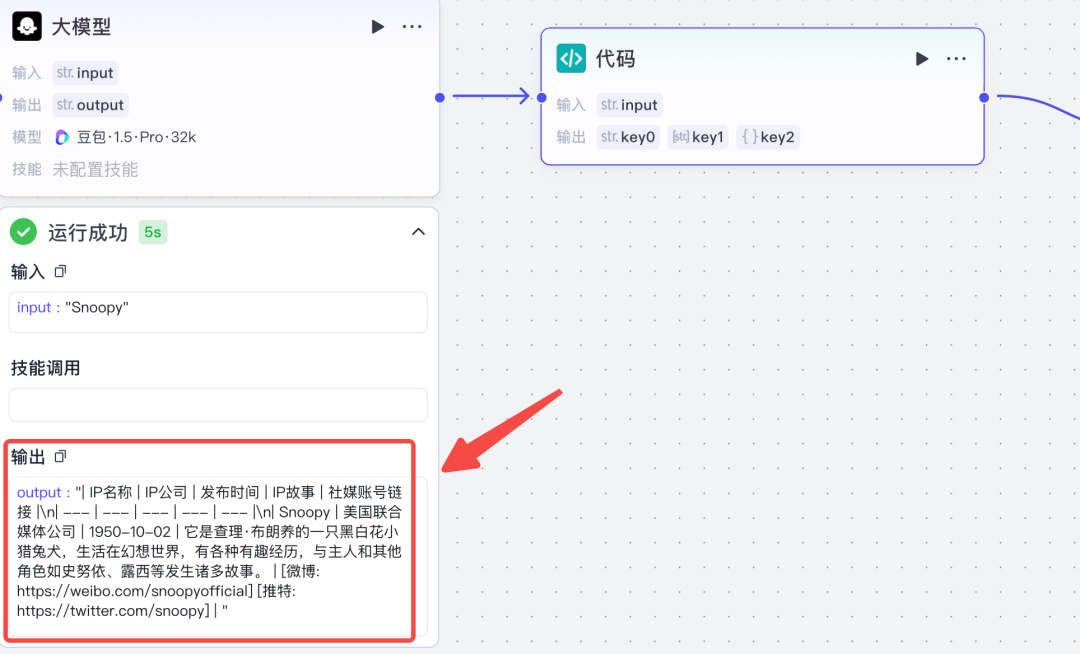
然后把代码粘贴到原来的地方。
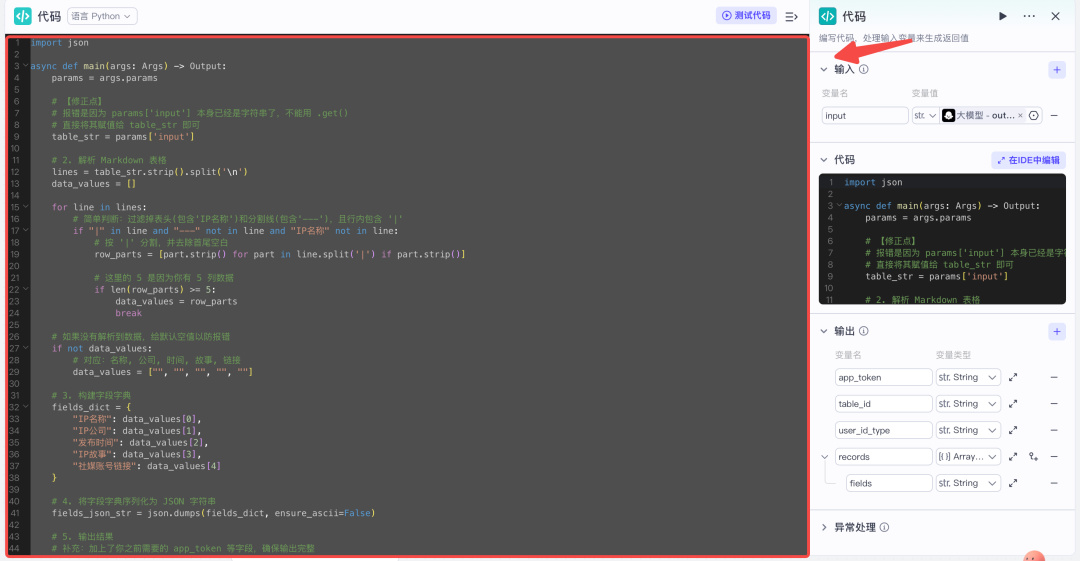
第四步
最后就是多维表格了,咱需要在飞书里面先创建多维表格。
记得调整权限,这样扣子才能在你的表格中添加内容。

我们还要把表格每一列的表头填好。
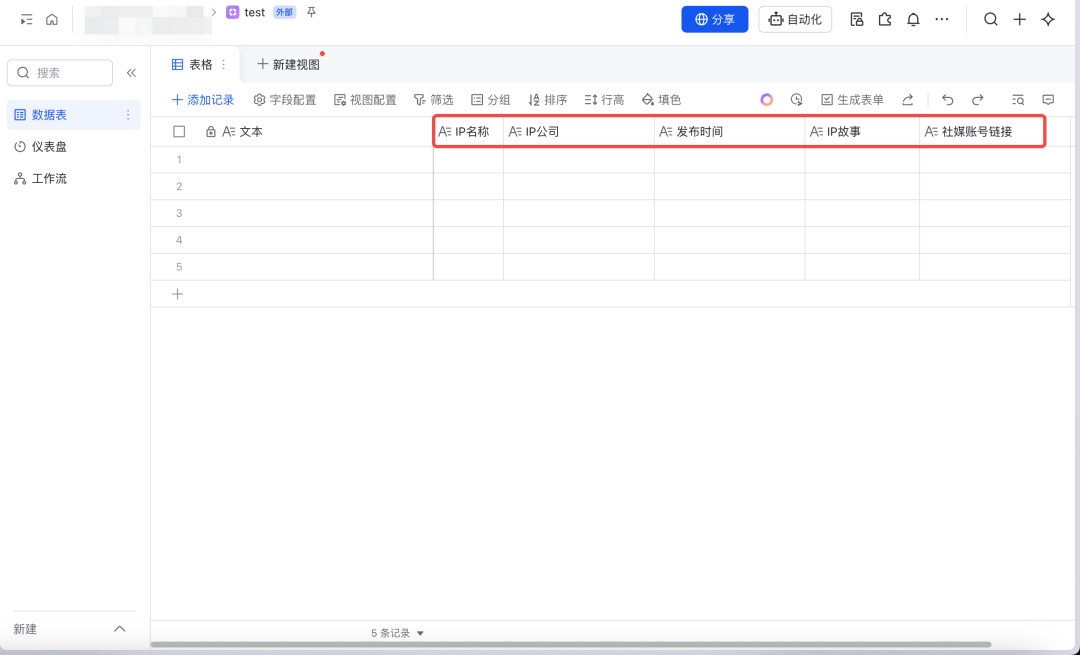

【注意!表格中每一列的内容要和代码中输出的内容一致!!!比如代码这里写的 IP 名称,IP 公司等,表格中也要填写一致,注意不要用空格】
调整好以后把文档链接复制到工作流的多维表格的节点中。
整个工作流就长这样:
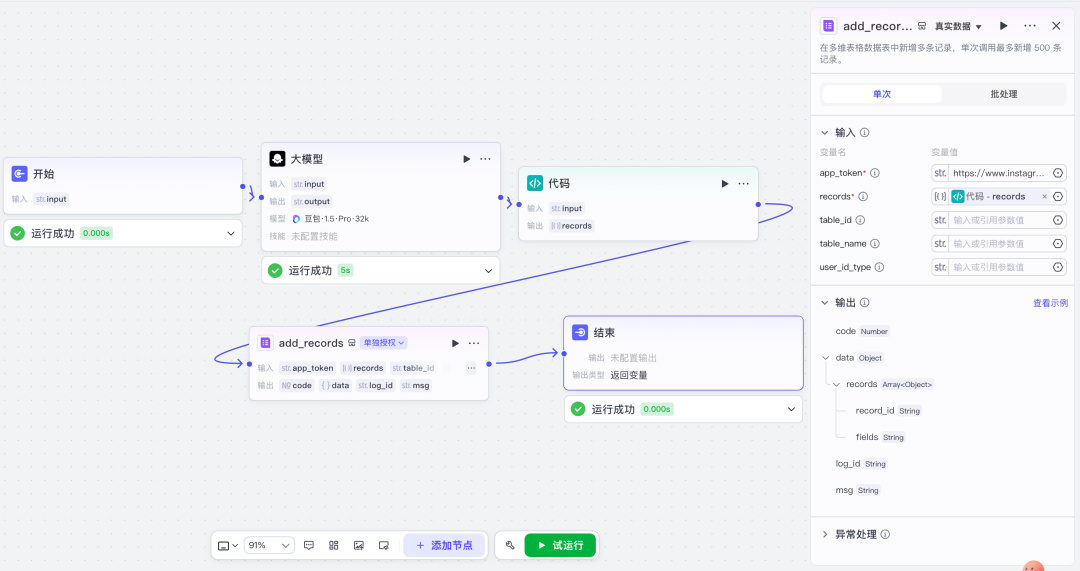
特别简单基础,跑一下看看能不能成功。
报错了!!
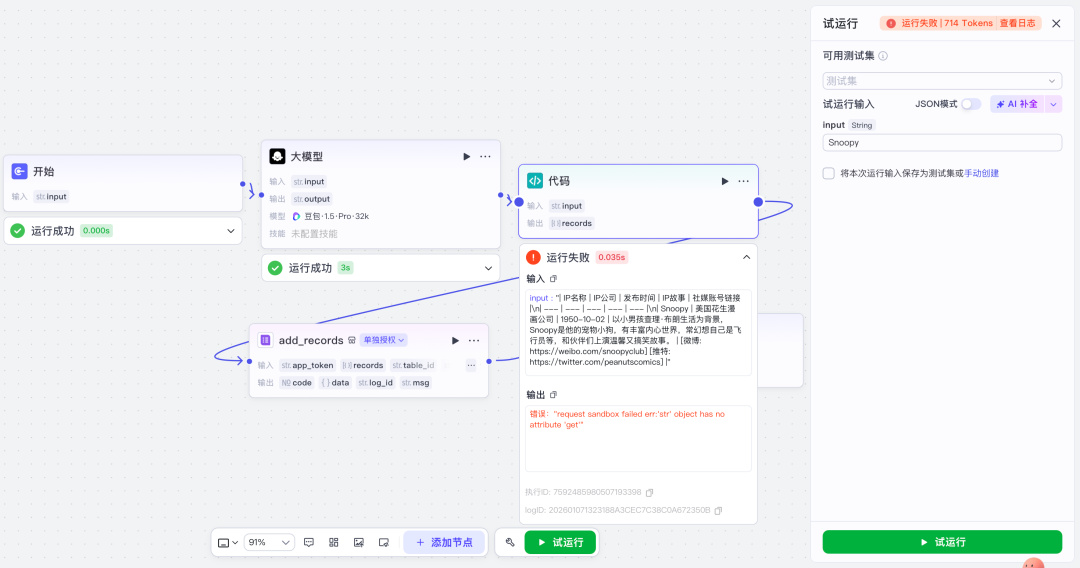
这时候别慌!!
只需把源代码和报错截图发给 AI 大模型就行了。
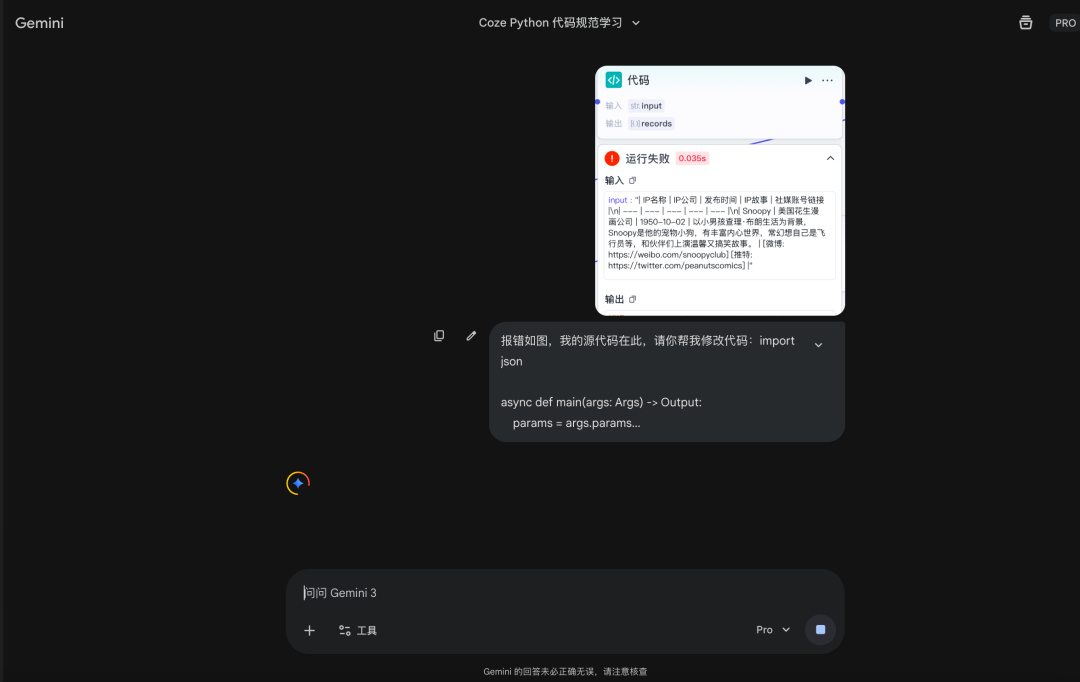
我也看不懂它代码改成啥样,就是复制粘贴到节点里面试试。
再跑一遍,显示成功了。
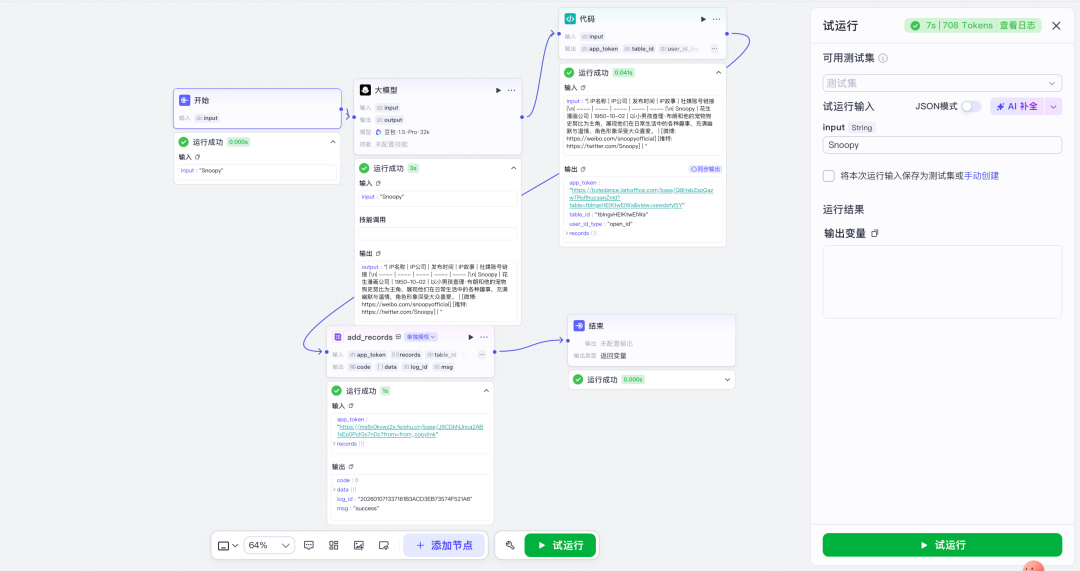
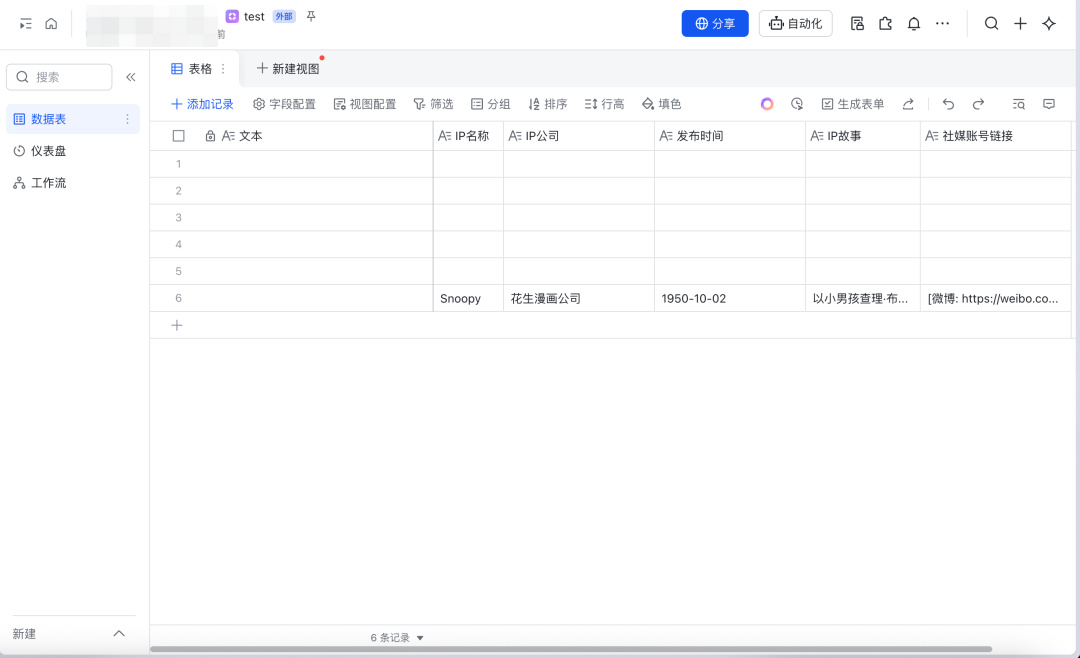
最后来检查一下多维表格,
也确实录入了,这样就说明成功了~
从 0~1 跑通了,从 1 到 100 就很简单了,
只需要加一个循环即可,这个咱们下期再教。
在你学习完本篇文章以后,
你就已经有了工作流的初步意识了~
对于后期加入插件等,方法也是大同小异,
如果还有不懂的,
可以在评论区下方评论,我看到会第一时间回复的~
晓风乾丨 大四 Base北京 AI产品在职
想缩小科技带来的信息差 分享很酷的AI玩法。
希望得到您的点赞转发爱心三连支持,
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com
















