在高科技领域,中国与世界最高水平仍有较大差距的两大核心领域,一是光刻机,二是 GPU 芯片 —— 二者正是全球 AI 竞争的关键基石。
5 年时间,摩尔线程基于自研全功能 GPU,构建起软硬兼备的全栈产品体系,覆盖几乎所有 GPU 相关领域:从消费级游戏显卡(S80/S70)到专业视觉加速显卡(X300/S50)、数字办公显卡(S30/S10);从 AI 算力本(AIBOOK)到台式机(智娱摩方);从算力加速卡(S5000/S4000)到服务器(MCCX D800 X1/X2)、智算中心(夸娥集群);从基础软件、AI 套件到云原生软件、图形与多媒体软件;从 AI 模型(MUSAChat)到 AI 应用(魔笔马良 / 魔笔天书),摩尔线程在传统与新兴领域均表现亮眼。所以,摩尔线程是时候做一次总体汇报,也是时候展望一下未来了!
第一届MUSA开发者大会,恐怕超出了每一位与会者的意料与期待! 这场大会的干货密度,远超所有与会者的期待:新架构 ×1、新芯片 ×3、新整机 ×2、新集群 ×1,外加众多开发工具与生态升级,尽显 5 岁摩尔线程的全面爆发!

我们先来总结剖析以上这些数据包含了什么:
架构层面
:花港架构是核心护城河,全精度支持 + 高能效 + 高扩展性,为全系产品打下基础;
芯片层面
:华山主攻智算、庐山聚焦图形、长江发力端侧,三条赛道精准覆盖不同需求;
生态层面
:从个人算力本到十万卡集群,实现 “芯 - 边 - 端 - 云” 全场景覆盖,开发者友好属性拉满。
接下来让我们看看这些芯片的详细信息。

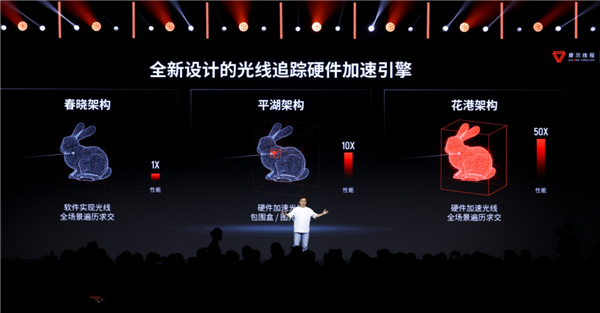
新一代 GPU 架构:花港
自 2022 年起,摩尔线程 MUSA GPU 架构保持每年一代的迭代速度,先后推出 “苏堤”“春晓”“曲院”“平湖”(架构代号均源自 “西湖十景”),此次发布的新一代架构,代号 “花港”。
核心性能突破
“花港” 架构采用新一代指令集,在相同工艺条件下,算力密度提升 50%,能效更是实现 10 倍飞跃。支持 FP4 到 FP64 的全精度端到端加速计算,新增 MTFP6、MTFP4 支持,优化 FP8、FP6、FP4 低精度计算,通过混合计算模式提升能效。
内置第一代 AI 生成式渲染架构(AGR),以 AI 重构传统渲染流水线,搭配第二代光追硬件加速引擎,生成速度较上代提升 5-6 倍,完美支持 DX12 Ultimate 全功能。同时,新一代异步编程技术优化任务调度与并行机制,结合自研 MTLink 高速互联技术,可支撑 10 万卡及以上超大规模智算集群扩展。
未来产品规划
基于 “花港” 架构,推出两大核心芯片:高性能 AI 训推一体的 “华山” 芯片,以及高性能图形渲染的 “庐山” 芯片,覆盖智算与消费级市场。


十万卡集群基石:AI 训推一体芯片 “华山”
“华山” 芯片基于花港架构打造,为 AI 训练与推理一体化设计,构建下一代 “AI 工厂”。其性能全面超越 NVIDIA 上一代 Hopper 架构,在访存容量上优于新一代 Blackwell 架构,访存带宽与之持平。
核心技术优势
异步编程技术:通过线程同步效应实现负载自动均衡分配,让每个计算单元持续高效运转,避免 “一核有难多核围观”。
Tensor 张量计算系统:支持从 32 位到 4 位全精度整数、浮点、张量数据格式,重点提升 FP6、FP4 张量运算性能,支持 MTFP8/6/4 混合精度计算;新增 TCE-PAIR 模式,实现两个 TCE 单元数据共享,增强内部数据重用,提升算子效率。
多元互联与高可靠性:支持自研 MTLink 4.0 互连技术及多种主流开发互联协议,兼容不同硬件生态;内置 RAS 2.0 技术,通过 SRAM 奇偶校验、ECC、强化错误检测上报与隔离等功能提升集群可靠性;新一代异步通信引擎 ACE 2.0 让通信与计算并行执行,大幅提升整体效率。
集群扩展能力
“华山” 芯片可轻松构建十万卡级别智算集群,单个节点最多支持 1024 块加速卡。


新一代游戏卡:图形渲染芯片 “庐山”
对于普通用户与游戏玩家,消费级显卡是焦点。摩尔线程 MTT S80/S70 作为目前唯一可购的国产游戏卡,硬件性能对标 RTX 3060,说实话还是有些不够看的。
性能飞跃式提升
新一代图形渲染芯片 “庐山” 同样基于花港架构,性能突破:游戏性能理论上提升 15 倍、光追性能提升 50 倍、AI 性能提升 64 倍、几何处理性能提升 16 倍、纹理填充性能提升 4 倍、原子访存性能提升 8 倍,显存容量最大可达 64GB(较上代增大 4 倍),亦可应对 CAD、CAE 等工业设计任务。
核心技术亮点
AI 生成式渲染 MTAGR:融入 AI 赋能,覆盖几何着色器、网格着色器、像素着色器等环节,集成 AI 超分、多帧生成、光流、降噪等功能,类似于DLSS/FSR,支持 DirectX、Vulkan 及自研 MUSA 多渲染后端,兼容 Windows、Linux 系统与主流 CPU 架构。
统一任务引擎架构(United Task Engine):实现 GPU 内部计算单元充分并行,避免任务分配不均,最大化核心利用率。
新一代光追技术:内置专用光追计算模块(RTU),支持硬件加速全场景遍历求交,自主设计 BVH 加速结构算法,兼顾高效生成与显存节省,完美支持微软 DXR 1.1 标准。


大一统 SoC 芯片 “长江” 与两款整机
本次发布的第三颗芯片 “长江”,是摩尔线程首款完整的 SoC 片上系统,打造异构计算核心:
CPU:8 个 Arm 架构全大核,主频最高 2.65GHz,兼顾高性能与低功耗;
GPU:自研全功能 GPU,支持高性能 3D 渲染与大模型端侧推理;
NPU:可编程双核心,专注语音、图像多模态加速处理;
VPU:支持 H.264、AV1 等格式编解码,适配 8K30、4K60 超高清需求;
DPU:支持双屏 8K60、八屏 4K60 高清多屏输出;
DSP:高性能双核设计,支持 AI 降噪、Hi-Fi 音效;
ISP:最高支持 3200 万像素摄像头,兼容 HDR;
内存:支持 32/64GB LPDDR5X,带宽超 100GB/s;
异构 AI 总算力超 50 TOPS,支持 FP64、FP32、FP16 等多精度计算。
基于 “长江” SoC,摩尔线程同步推出三款产品:AI 算力本 AIBOOK、迷你机 MTT AICube、MTT E300 AI 模组。

AI 算力本 MTT AIBOOK
专为 AI 学习与开发者设计的个人智算平台,兼顾日常使用场景,售价 9999 元,现已开放预售,2026 年 1 月 10 日正式开售。
系统兼容:默认运行 Linux 内核的 MT AIOS 操作系统,支持 Windows 虚拟机、Android 容器及主流国产操作系统;
开发环境:预置 VS Code、Jupyter Notebook、Python、PyTorch、vLLM 等全套 AI 开发工具,简化开发部署流程;
模型支持:端侧最高可运行 30B 参数大模型,预装阿里 Qwen3-8B、智源悟界 Emu 3.5 多模态模型,支持视觉指导、文本生图等功能;
智能体验:内置数字人智能体 “小麦” 与 MUSAChat-72B 大模型,支持模型 API 灵活调用,提供开箱即用的 AI 体验,“小麦” 核心能力已开放云端 API 与本地 SDK;
硬件配置:航空级铝合金一体成型设计,薄至 12.4 毫米、轻至 1.35 千克;14 寸 OLED 屏幕(91%屏占比、2.8K 分辨率、120Hz 刷新率);4 扬声器、4 麦克风阵列、1080p 摄像头;1.5 毫米键程键盘、12×7.5 毫米触摸板;1TB SSD、70Whr 电池;三个 USB-C 接口、Wi-Fi 6、蓝牙 5.2。

迷你机 MTT AICube
支持多系统兼容与端云大模型部署,定位类似 AMD 395、NVIDIA DGX Spark 的个人开发迷你机。

MTT E300 AI 模组
提供高性能、低延迟、高可靠的国产边缘 AI 解决方案,适用于工业、能源、教育、交通、医疗等行业场景。
十万卡级智算重器:夸娥智算集群
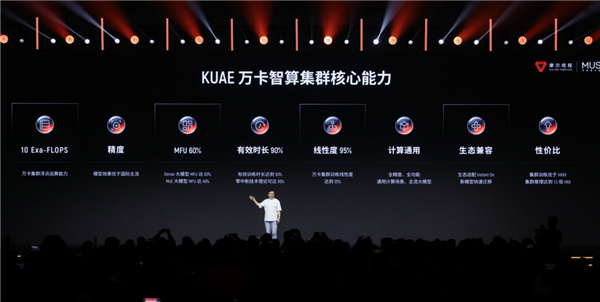
“夸娥” 万卡智算集群(KUAE 2.0)是本次大会的重点,作为国家 AI 算力核心基础设施,支撑着海量 AI 服务的后台运行。摩尔线程从千卡集群起步,现已实现万卡规模。

核心性能指标
该集群浮点运算能力达 10 Exa-Flops,成功攻克万卡级硬件筛选、高速互联、系统级容错等工程难题,可支撑万亿参数大模型训练与部署。
软件与生态优化
集群守护系统:KUAE RAS System Daemon 可在不影响客户系统运行的情况下,快速定位并替换故障节点、慢节点、SDC 节点。
推理性能突破:联合硅基流动完成全栈优化,基于 MTT S5000 AI 加速卡运行 DeepSeek R1 671B 全量模型,单卡 Prefill 吞吐突破 4000 tokens/s,Decode 吞吐突破 1000 tokens/s,支持高并发、低延迟大模型服务。
未来规划:推出 MTT C256 超级节点产品,通过一层 scale-up 网络实现两台机柜 256 块加速卡全互联,规避多层网络带来的带宽损失与延迟,提升智算集群 GPU 部署密度。

生态落地:千行百业的算力赋能
大会现场设置超 1000 平方米主题展区,充分展现摩尔线程 GPU 的广泛落地成果:
工业与边缘智能
ME10 工业级智算 BOX(天思智慧):基于 “长江” SoC,最大支持 32GB LPDDR5/5X 内存,具备宽温适应性与丰富接口,适用于智能制造、智慧城市等领域;
SD5600MX100(国仪海聚):为智能系统提供高算力核心,满足车规、工业自动化、医疗等行业需求,成本控制与 I/O 设计灵活;
柳工 CLG922E 挖掘机:基于 MindEdge L100 边缘计算平台,整合设备运行数据与音视频信息,优化故障诊断、自动驾驶等 AI 模型,解决复杂工况下的安全与能效难题;
盾构机 “盾构大脑”(雪浪云):打通七大控制系统与外部感知、运维系统,打造自适应控制中枢,解决隧道施工 “掘不快、掘不准、掘不稳” 的核心痛点。
端侧 AI 终端
B700 AI BOX(联达兴):支持 4K60Hz 超清双显,集成双千兆网口、Wi-Fi 6、蓝牙 5.3,配备专业音频接口与 DC 供电,适配智能会议、数字标牌等 AIoT 场景;
ME21 AI 迷你机:基于 “长江” SoC,专为本地大模型部署设计,适用于智能办公、边缘计算、AI 教育等场景;
后羿智盒 HOUYI-1000B/HOUYI-Pi-B(全爱科技):前者为 3.5 寸工业主板形态,无风扇散热,支持 32B 大模型端侧部署,适用于安防、交通等严苛场景;后者体积超小,可广泛应用于机器人、无人机等设备。
专业计算与仿真
紫光计算机 UltiStation 800H 工作站:旗舰级国产化单路工作站,搭载海光 C86-4G 处理器,最高支持 128GB DDR5 内存与 PCIe 5.0 存储 / 显卡,搭配摩尔线程专业显卡,适用于政府、教育等领域的图形处理、仿真与 AI 计算;
紫光计算机 100P 智算集群:基于摩尔线程 MTT S4000,构建高效集群计算能力;
微视威 eVTOL 全动飞行模拟器:全链路自主研发,1:1 封闭座舱与六自由度运动平台,搭载北京大学 ViWo 引擎视景系统,国内首个通过民航局 5 级鉴定的国产视景系统,已出口海外;基于 MTT X300 专业显卡打通全国产化视景渲染链路,适用于飞行员训练与机型工程验证。
行业解决方案
罗拉超算体 LoLR CUBE(法律版 / 财税版):搭载 MTT E300 64GB 模组,端侧全栈算力支持 300 亿大模型推理;法律版阅卷解析快至 10 秒 / 页,效率提升 100 倍,支持法律文书生成优化;财税版集成 2000 + 专业指标与 300 亿 AI 风控大模型,7X24 小时监控。
景业智能 VR 遥操作机器人系统:适配 MTT E300 模组与 MTT S80 显卡,操作人员通过 VR 眼镜远程控制特种机器人,在辐射等高风险环境完成精细任务,构建超低延迟、高可靠的操控闭环;
景业智能巡检机器狗:适配 MTT S4000 显卡,通过 Qwen 大模型部署,具备场景理解与实时推理能力,可自主完成人员识别、隐患排查、设备监测等任务;
中望软件三维 CAD 解决方案:基于 MTT X300 专业显卡,适配多款国产 CPU 与操作系统,可流畅渲染复杂三维模型;
ADAI ADXL Pro Max/AD Edit 模型:服务数十万 C 端用户与 500 多家行业客户,累计生成图像超 8000 万张,已深度适配摩尔线程 GPU;
北太天元科学计算软件:国内首款通用型科学计算与系统仿真软件,全链条自主可控,集成 MUSA 加速计算能力,成为全球首款原生集成 AI 能力的科学计算工具,可全面替代 MATLAB、Simulink;
微眸医疗眼科手术机器人:基于摩尔线程 GPU 实现手术过程本地化实时感知与智能决策,满足微米级操作精度、高安全性与隐私保护需求。
技术创新应用
物流无人机(紫光计算机):小载重四旋翼末端配送设备,支持 1 千克包裹运输,兼容 4G/5G / 专网通信,采用 RTK + 视觉融合精准降落,搭配订单 APP 与飞行管理平台,可自主完成投递任务;
数字人应用:覆盖文旅、政务、面试培训等领域,依托摩尔线程 GPU 实现高效渲染与智能交互;
MTVSR 实时视频超分技术:端侧运行,分辨率可提升 2-4 倍,多档质量可调,将以 SDK 形式支持播放器、浏览器等 App 集成。
从 “花港” 架构的全栈突破到三大核心芯片的精准布局,从端侧 AI 设备到十万卡级智算集群,从开发者生态构建到千行百业的深度落地,摩尔线程用五年时间完成了国产 GPU 的跨越式发展。这场 MUSA 开发者大会既是成果汇报,更是国产算力突围的宣言 —— 在主权 AI 的赛道上,摩尔线程正以 “芯 - 边 - 端 - 云” 全栈体系,为算力自主、算法自强、生态自立提供坚实支撑,书写国产 GPU 的全新篇章。

本文数据来来源:MUSA开发者大会 · 2025
以上是本篇文章全部内容,如果有什么缺失,欢迎评论区补充!
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com














![[6.27]夏促来袭!超多骨折!百款史低新史低这次你一定要入库!](https://imgheybox1.max-c.com/web/bbs/2026/06/26/bfb8adfbb675422149a024f4b7064470.png?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)

