日本内容巨头最近有点不安分。
万代南梦宫、Square Enix、东映动画、角川,还有吉卜力,全都站出来,联合在一起给 OpenAI 发了一份声明,说是 Sora 太能学,学得还特别像日本动画,请立即停止使用日本内容训练模型。

虽然但是,我记得 Sora 的吉卜力热度这都过去多久了,你们现在才跳出来......

怎么看都有点“考试快结束了,监考老师才冲进教室”的赶脚。
发布声明的协会叫 CODA,本来主要对付盗版网站、同人游戏那种,现在突然把矛头对向了 AI,态度非常直:你未经许可训练,就是侵权。
还有一句特别硬:“没有制度允许通过事后提出异议来免除侵权责任。”意思就是,别想着先干完再道歉。
奥特曼桑本人也很无语。
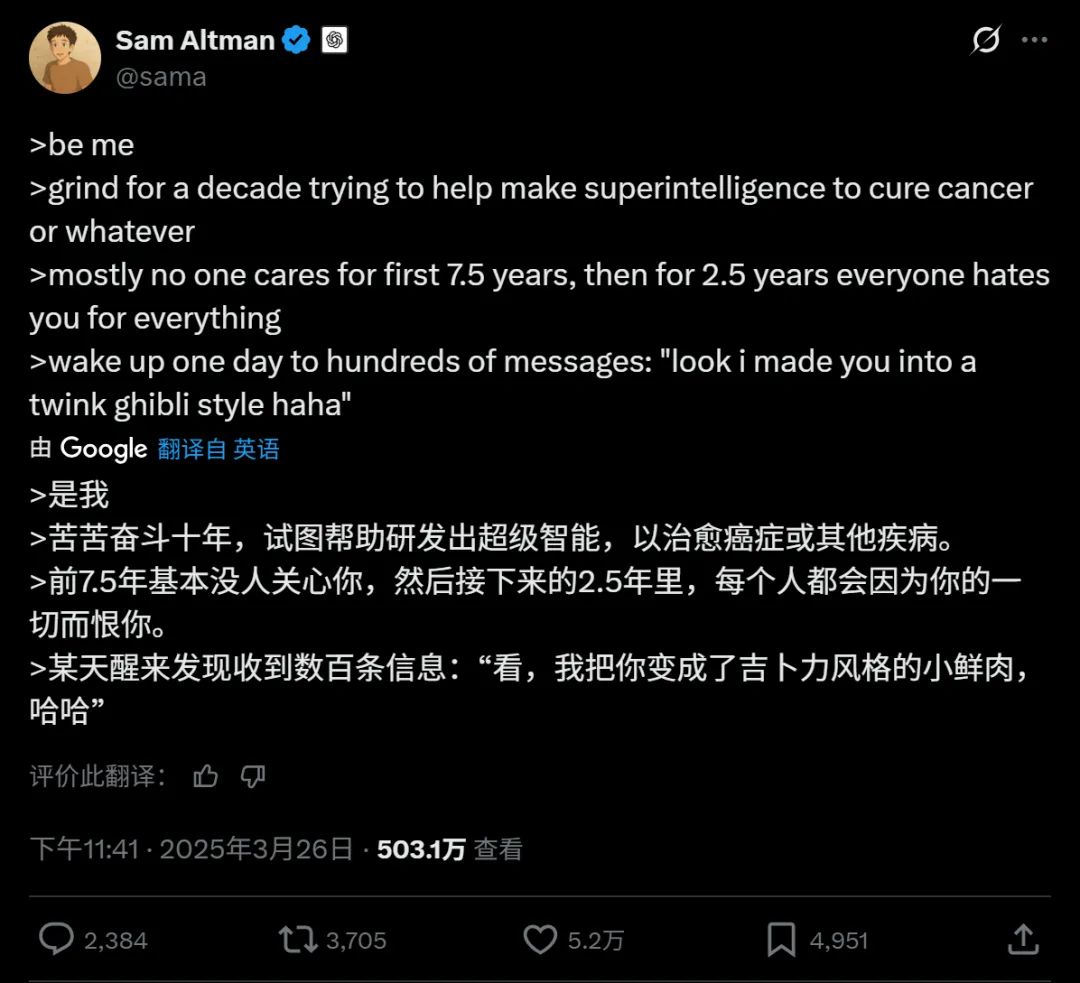
但现实问题是:你们早干嘛去了?
这几年互联网上各种“宫崎骏风自拍”火了多少轮。只要有 Sora,所有猫都能变成龙猫,是个照片就能变成吉卜力风格,从来没断过。

而现在,日本版权联盟突然发现:怎么 AI 学得更像,还能批量生产,那不行了。
但现实是,现在才阻止,真的阻止不了。
不管是人类还是 AI,很简单的道理:
看过,学过,一旦学会,就很难忘掉(对人类来说至少短时期内)。
就算现在让 OpenAI 停止使用这些素材训练 Sora,它也不会回档到“没看过龙猫”的时代。
因为它根本分不清自己哪些风格来自吉卜力,哪些来自别的风格或者什么动画里的东西。模型参数里全是揉在一起的统计模式,你怎么操作?
最尴尬的就是这里——你可以禁止继续训练,但你禁止不了它已经学会。
想象一下,一个厨师偷偷学了你的独家菜谱,还学到炉火纯青。

你突然冲过去要求他“不准使用你的味道”。那厨师要怎么做?闭着眼睛炒?完全忘掉盐是怎么放的?
OpenAI 一直使用那套“先用再说”的互联网逻辑,也就是北美程序员经典哲学:
事后道歉比事前请求许可更有效率。
AI 模型可不是在日本的法律框架里长大的。你现在跟它讲日本版权法,它已经在全球市场巡回表演了。
不过吉卜力这次确实忍了很久。
宫崎骏当年看到 AI 动画都嫌弃,现在 Sora 拍出的短片,路人看着都觉得像电影片段。用户可以随时让一只狗在吉卜力风世界里跳舞,连 Sam Altman 的头像都变成了“小清新少年版吉卜力”。这画风被玩得太过火,吉卜力肯定坐不住了。
CODA 的担心有合理性,日本内容产业几十年累积的风格正在被 AI 模型免费接管。
过去你用盗版,他们还能下架网站;现在连学习的过程都看不见,更别提拦截。版权人追的是“我创作的东西要由我掌控”,但 AI 的逻辑是“世界是我训练集”。两种世界观,注定碰撞。
可话又说回来了,如果真的较真,“吉卜力风格”这种东西本身能版权保护吗?
风格是风格,风格不是 IP。
你可以说角色、分镜、音乐都受保护,但风格更多时候算是一种艺术形式、流派,你不可能说我开创了这个流派,你们其他人看可以,但就只有我能画吧?

Sora 又不是把《龙猫》直接复制出来,它做的是“感觉像”。那怎么界定侵权?
所以这件事真正透露出的,是一种补救式焦虑。
AI 学得太快了,日本反应太慢了。现在喊停,已经来不及了。CODA 想控制 AI 的学习边界,可边界在模型里面已经糊成一团。
说白了,这不是在阻止 AI 学,而是在阻止未来继续扩大差距。当前的模型性能已经证明:人类创造的一切风格,在机器面前没有独门秘籍。
当所有创意都能成为训练数据,原创的尊严要靠什么维持?
日本这次的要求当然会推动更多规则制定,但它更像是警钟,提醒所有创作者:你的风格如果能被总结成规则,那它早晚会变成 AI 的能力。
AI 没法忘记。
技术也不会因为这些人而倒退。
模型也会继续变强。
但创作者要想不被替代,个人认为是得必须比 AI 更快地向前一步。
至于 CODA,这次来的确实有点迟了。
等他们整理好全部证据找上门,Sora 已经在下一代动画里熟练运用了吉卜力的视觉语言。
现在才说“不准学”,真的只能换来一句:
你才来啊?我早就学会了。
我是 CyberImmortal,关注我们,带你畅游AI世界!
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















