注释*:“游戏可用”指此类应用可在部分游戏环境中发挥作用,且此文章也会介绍这种用途
本文章仅针对Windows系统和消费级显卡(因为这是大部分普通用户的场景),适用于零基础小白快速入门部署本地AI并投入一些开源项目的应用。
前言
近年来,随着人工智能应用的飞速发展和高性能计算需求的不断提升,显卡市场的竞争和行情愈发激(e)烈(xin)。
今年,AMD发布了全新的9000系显卡,虽凭借FSR4技术在图形优化上有所突破,但却因其为9000系显卡独占而引发了“背刺老用户”的争议,对此网友们普遍调侃7000系显卡的“AI单元”是“电阻丝”,这些显卡的用户也自嘲为“小丑”。
至于NVIDIA,则是继续巩固其在AI计算领域的霸主地位,然而众所周知,老黄的显存是金子做的,x060级甜品卡万年8G显存,而直到5080都还只有16G显存。
与此同时,Intel虽然在显卡市场尚属新兵,但凭借着A系列失败的经验,终于在B系列交出了一个还算合格的答卷,并且intel也是最舍得给显存的一方。
在这样的背景下,我们将基于这三家显卡的参数规格特点,给大家分享利用Ollama本地跑AI大语言模型和将其应用于部分游戏领域的方法,为一些感兴趣的用户和玩家们提供一种AI应用的入门方法。
当然,你可以调用如Deepseek官方提供的API来进行应用,而且调用官方的AI,其智能性也明显强于本地部署。但本地模型相比远端API调用,具有低成本和响应快的特点,更适合一些日常休闲娱乐的应用。
术语讲解和硬件要求
简单的术语及其大致机制讲解
注1:与个人开发和api调用有关的详细内容可见于网上随处可见的ollama文档,这些文档应该已经比较成熟,此处主要面向零基础的小白。
注2:此处的讲解,包括后续的内容,主要为了让零基础小白也能轻易听懂,因此某些描述可能在精通这些内容的您看来不够准确,如果您希望进一步作最精确的解释,可以发在回复中供其它人了解。
既然要跑AI,那么我们首先我们应该先知道一个模型的几个最基本的术语含义:
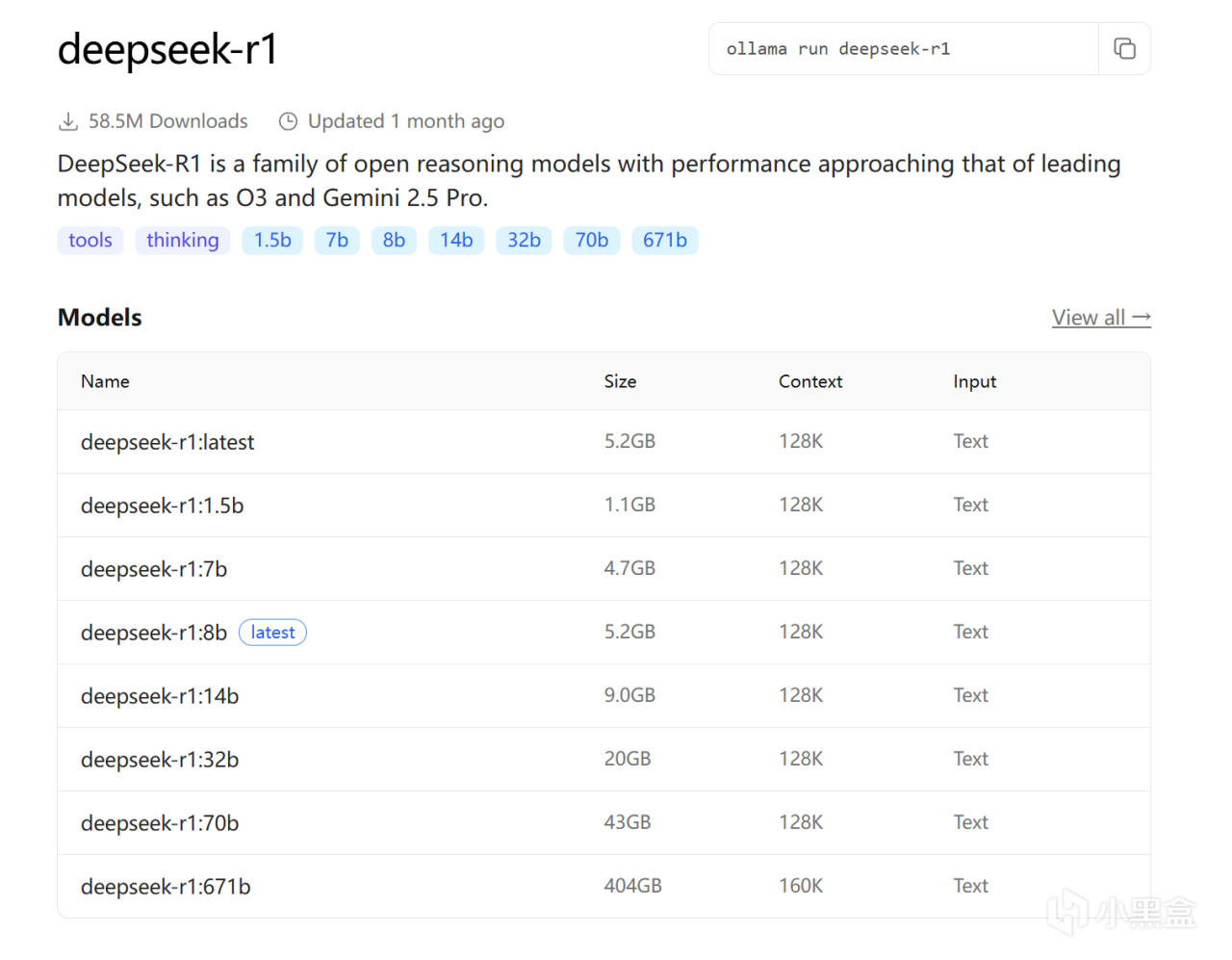
Ollama上的deepseek-r1页面
以Ollama官方网站上的deepseek-r1模型页面为例:
deepseek-r1是模型的名称;
问号后面的7b、8b、14b等是模型的参数大小,通常来说,参数越大的模型,显存占用越高、速度越慢,但同时模型的智能性和表达能力也越强;
Context处的128k指模型最大支持的上下文长度,影响模型在一次推理中能够处理的最大输入文本长度,单位就是大伙熟悉的token,上下文长度越长,模型能够记住的前文信息也越多,但对显存的开销也会随此变大;
size指的是模型文件的大小,在Ollama上的这个值在一定程度上也可以用于衡量模型对显存需要的大致参考,默认设置和常规用户环境下使用时,模型对显存的消耗大致相当于size加上1~3GB(取决于许多因素,此处为方便大多数小白用户参考,而作此解释)。
还有一种在某些应用下比较重要的叫embedding模型的东西,此类模型可以理解为专门用于将复杂的数据转换为AI大语言模型看得懂的形式的模型,这种模型本文章也不作过多赘述,因为ollama上目前最常用的embedding只有一个nomic-embed-text,通常如果有项目需要用到embedding模型(如deepwiki),这些项目都预先写好了在使用ollama跑时默认使用nomic-embed-text。
大致的硬件要求
注1:根据你使用的显示器分辨率,在实际使用时,系统本身是会吃掉一部分显存的,此处的硬件要求参考中,均主要基于2K分辨率进行考虑。
注2:内存足够但显存不足一样可以跑这些模型,但代价就是模型会运行在CPU上,如果需要应用在实际项目上,这可能不是一个具有足够效率和性能的方法。
注3:单纯地插多张消费级显卡并不能为你带来交火以运行一个更大模型的效果,但同时插一张24G和一张8G的卡会让Ollama自动将较小的模型跑在8G卡上、较大的模型跑在24G卡上,以按需同时运行多个模型。
注4:此处主要考虑常见的消费级显卡,不考虑专业卡和多卡交火场景。
AI推理时会占用显卡的性能,如果希望应用在游戏中,推荐在游戏时留出少量的性能盈余和一定的显存。在至少搭配一张当下显存充足的甜品到主流级别的显卡(推荐以3060 12G、4060ti 16G、9060xt 16G、7700xt 12G、B580 12G等起步)时,选择一个好的模型,模型每次推理只会占用极少量的时间,这些显卡的性能就足以在一瞬间完成模型推理了,通常不会过多影响到你的游玩体验。
轻度使用场景中的应用(也就是,不打什么游戏也不干什么重活,或者说跑起这个AI的应用就是你的主要目的<如AI文档翻译、视频同声传译>的场景):
6G及更小显存(2060 6G、1660 6G等):只能跑跑5b以内参数的模型(如qwen3:4b、deepseek-r1:1.5b、llama3.2:3b等),偏玩,基本没有什么实用意义,但你仍然可以自行尝试一下效果。
8G~10G显存(3060 8G、RX580 8G、6750gre 10G、A750、B570等):适合跑7~10b的模型(如deepseek-r1:8b、qwen3:8b、llama3.1:8b、gemma2:9b等),适合简单任务,实测用于实时翻译时效果偏机翻,勉强能用一用。
12~16G显存(5070ti、9070、B580等):适合跑12~16b的模型(如deepseek-v2:16b、deepseek-r1:14b、gemma3:12b等),适合轻度任务,这个级别的模型已经具备基本的应用价值,实际应用中表现还行。
20G显存(7900xt):能多跑一些例如gemma3:27b这种16G的卡刚好差一点而跑不了的模型。
24G~32G显存(5090、4090、7900xtx等):适合跑约30b的模型(如gpt-oss:20b、deepseek-r1:32b、qwen3:32b等),这个级别的模型已经具备不错的智能性,具有良好的应用价值。
注意:gpt-oss:20b虽然字面上是个20b的模型,但这个模型的显存需求实际上接近甚至可能超越qwen3:30b。
中重度场景中的应用(也就是,我既要跑AI也要干别的事,AI的应用是为了让我更舒服地做这些事,比如玩游戏的同时让AI进行实时翻译,或者数据交互<如MC车万女仆AI聊天>等):
不足10G的显存:基本与此类应用无缘,因为7b以下的模型基本没有什么实用价值,而随便跑一个不是那么古老的单机游戏都很容易让正在跑7b模型的8G显存显卡爆显存,只能将7b的模型应用于一些小游戏。但拿个小模型如上述一般应用在MC里让女仆跟你聊聊天可能还是可以的。
10G~12G显存:可以跑7~8b的模型,勉强能用一用。
16G显存:推荐跑8~10b的模型以留出显存给游戏,但也可以试着跑一下12~16b的模型(如显存还够,则建议使用deepseek-v2:16b)。
20G显存:推荐跑12~16b的模型,推荐使用deepseek-v2:16b。
24G显存:可以放心使用16b的模型,非常推荐使用deepseek-v2:16b,可以轻松跑起的同时留有充足的显存。
32G显存:16b模型完全无压力,推荐使用deepseek-v2:16b或gpt-oss:20b,可以使用32b的模型。
注意:有些AI(如gpt-oss、deepseek-r1、qwen3)会输出它的思考过程,这类AI可以但不建议用于实际项目。因为:一方面,不是所有项目都提供了去除思考过程的功能;另一方面,这些思考过程会大大拖慢模型输出结果的速度。关于这一点,推荐deepseek-v2:16b的原因就是其在这里是一个兼顾速度、性能与实用能力的不二之选。
另外需要注意的是,除了显存外,模型运行时还会占用一部分内存,以deepseek-v2:16b为例,其吃掉的内存在12G左右,模型的参数大小也会影响内存的使用量。
对于中文相关应用,deepseek、qwen等国产模型能提供更优秀的结果,如gemma3这般的模型表现就会差上不少。
网络要求
非常建议搭配一个上网的艺术形式(否则你下载一个模型耗时非常久),需要启用虚拟网卡模式或tun模式。
启用tun模式后CPU占用异常并且无法上网的情况见:Windows TUN模式无法上网 / CPU占用100%问题
模型的部署方法
安装Ollama
Ollama默认会安装在C盘,如果需要改变安装位置,你可以通过cmd运行下述命令:
OllamaSetup.exe /DIR=安装位置

(以安装到E盘为例)
①适用于N卡GTX900系、A卡RX6000系及以上
直接从官网下载并安装官方原版:ollama.com
安装完毕后运行即可。
②适用于比RX6000系更老的一些AMD显卡
使用社区大佬专门为老A卡制作的项目:ollama-for-amd (GitHub)
建议直接下载其中的OllamaSetup.exe
③适用于intel显卡
使用社区大佬专门为intel显卡制作的项目:ipex-llm (GitHub)
下载其中的ollama-ipex-llm-xxx-win.zip
运行Ollama
对于上述提到的①和②的方法,通常直接在完成安装后运行程序并另外打开一个cmd命令行窗口即可。
下面主要针对③提供的intel显卡使用方案作一个详述。
intel显卡方案中提供的是免安装压缩包,其操作步骤如下:
先将其内容解压在一个文件夹(此处以E:\Program\Ollama为例)中;
打开cmd,cd到此目录下;
cmd上输入ollama-serve.bat并回车,随后会打开一个新的命令行窗口(不要关闭这个窗口);
此时应该已经成功运行Ollama,我们切回原来的cmd窗口就可以操作了。
===========================
检查
在cmd上输入ollama并回车,你应该能够看到如下响应:
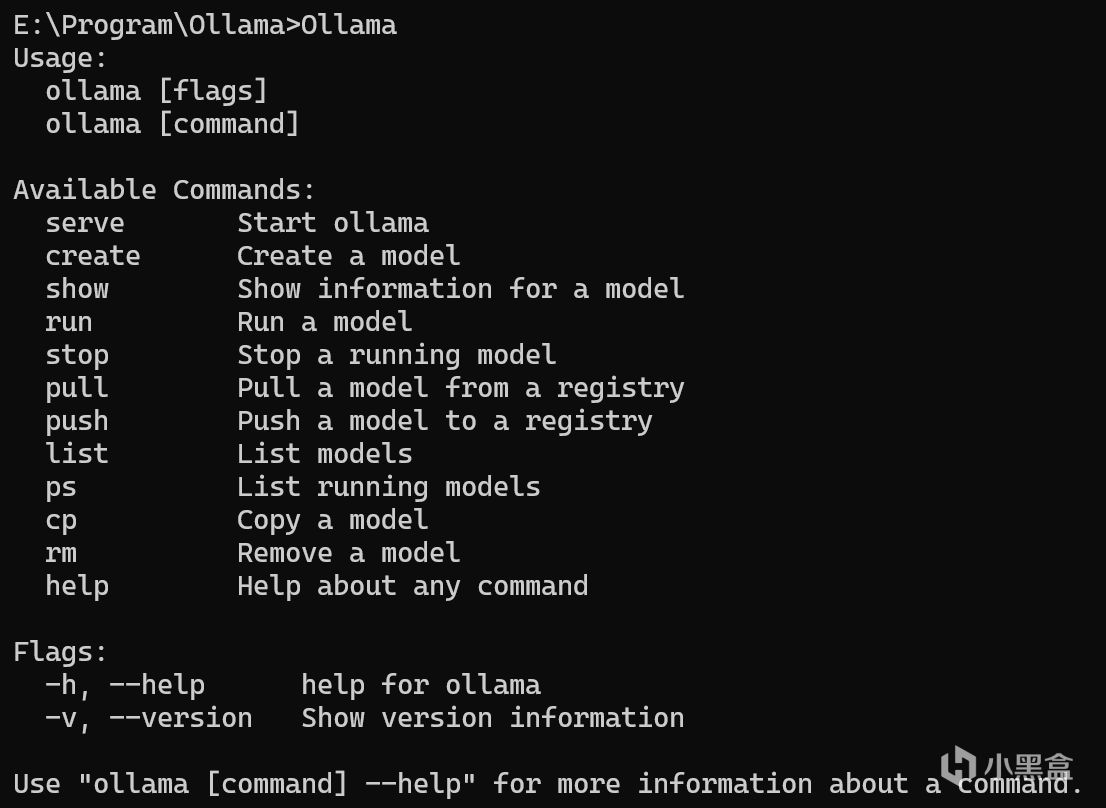
ollama在cmd上的响应
如果没有出现这一响应(或是为了方便以后操作),尤其是对intel显卡,除去安装操作上可能存在的疏漏外,你还可以尝试将ollama安装目录加进系统环境变量中,然后重启cmd(有时可能需要重启电脑):
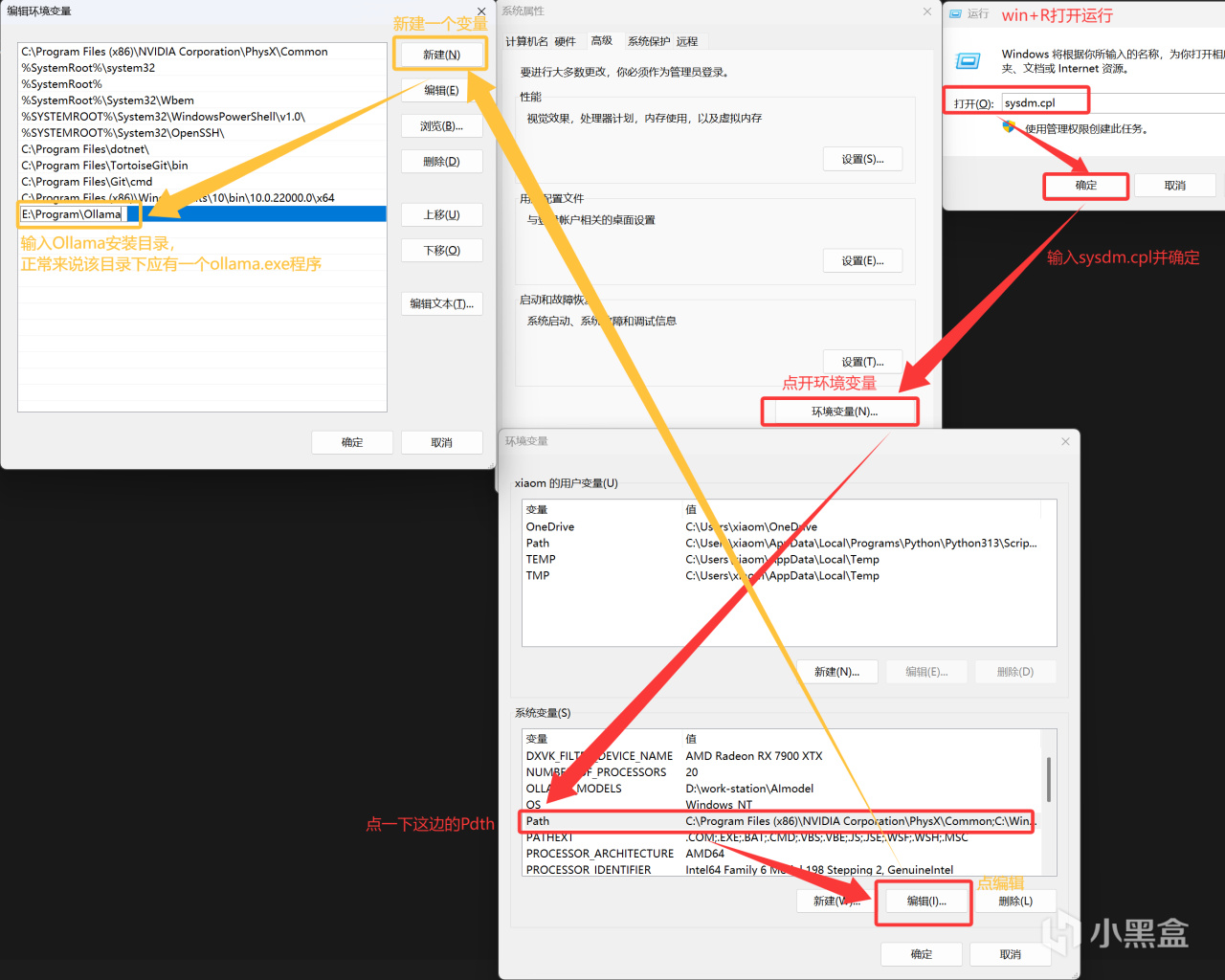
通常来说不会需要做这一步的
=========================
下载并运行模型
模型下载位置
模型会默认下载在C盘(C:\Users\%username%\.ollama\models),如果需要将模型放在其它盘,可以挑选以下三种操作方法之一(非官方版请尝试方法二和三,intel显卡似乎只能选用方法三?):
方法一,直接在Ollama设置中修改模型存储位置:在右下角进程小框中右键Ollama打开Settings,然后修改Model location项:
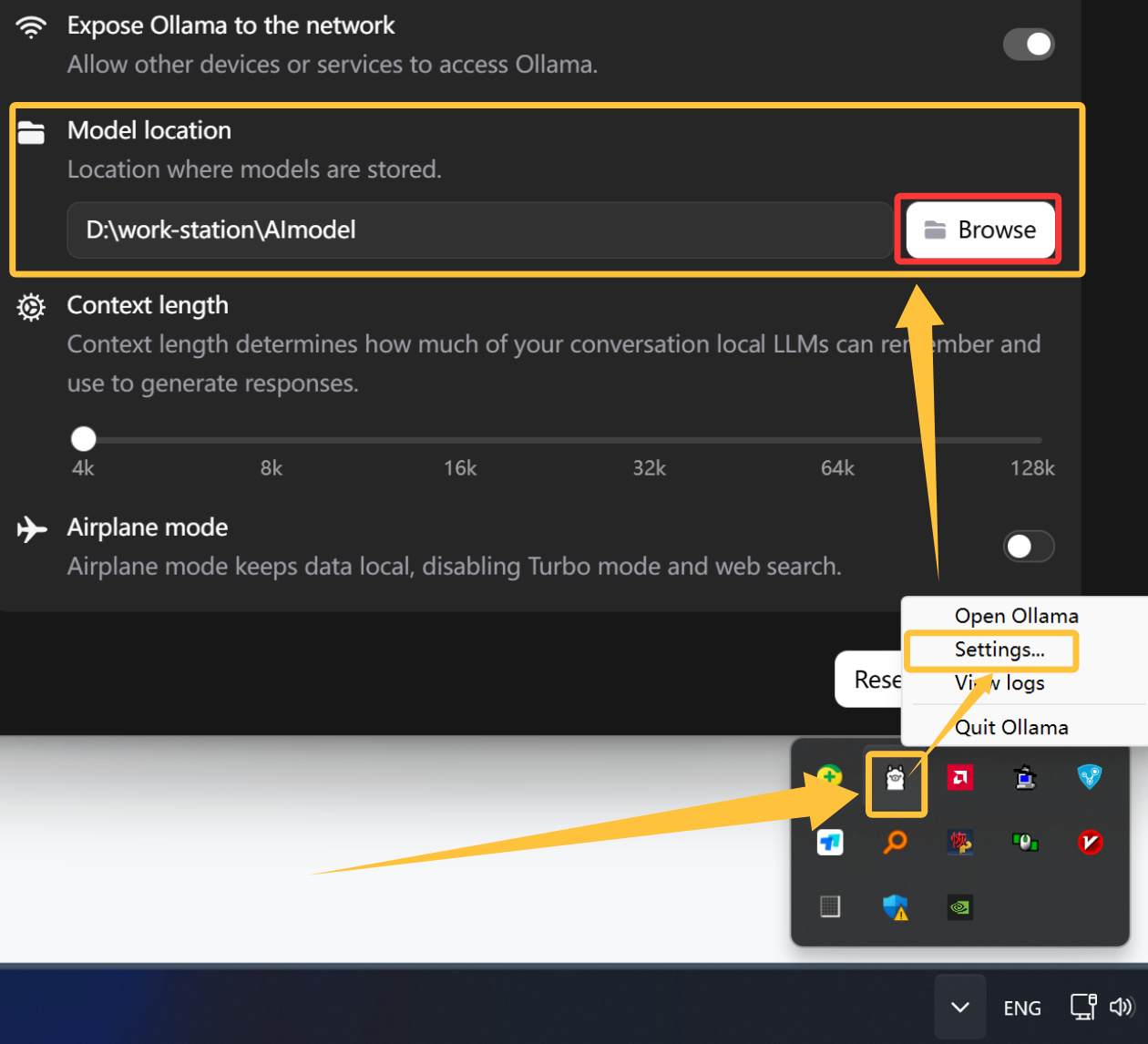
ollama设置中修改模型存储位置
方法二,修改系统变量:直接在系统变量中新建一个名为OLLAMA_MODELS,值为模型存储路径的变量,然后重启cmd(有时可能需要重启电脑)即可。
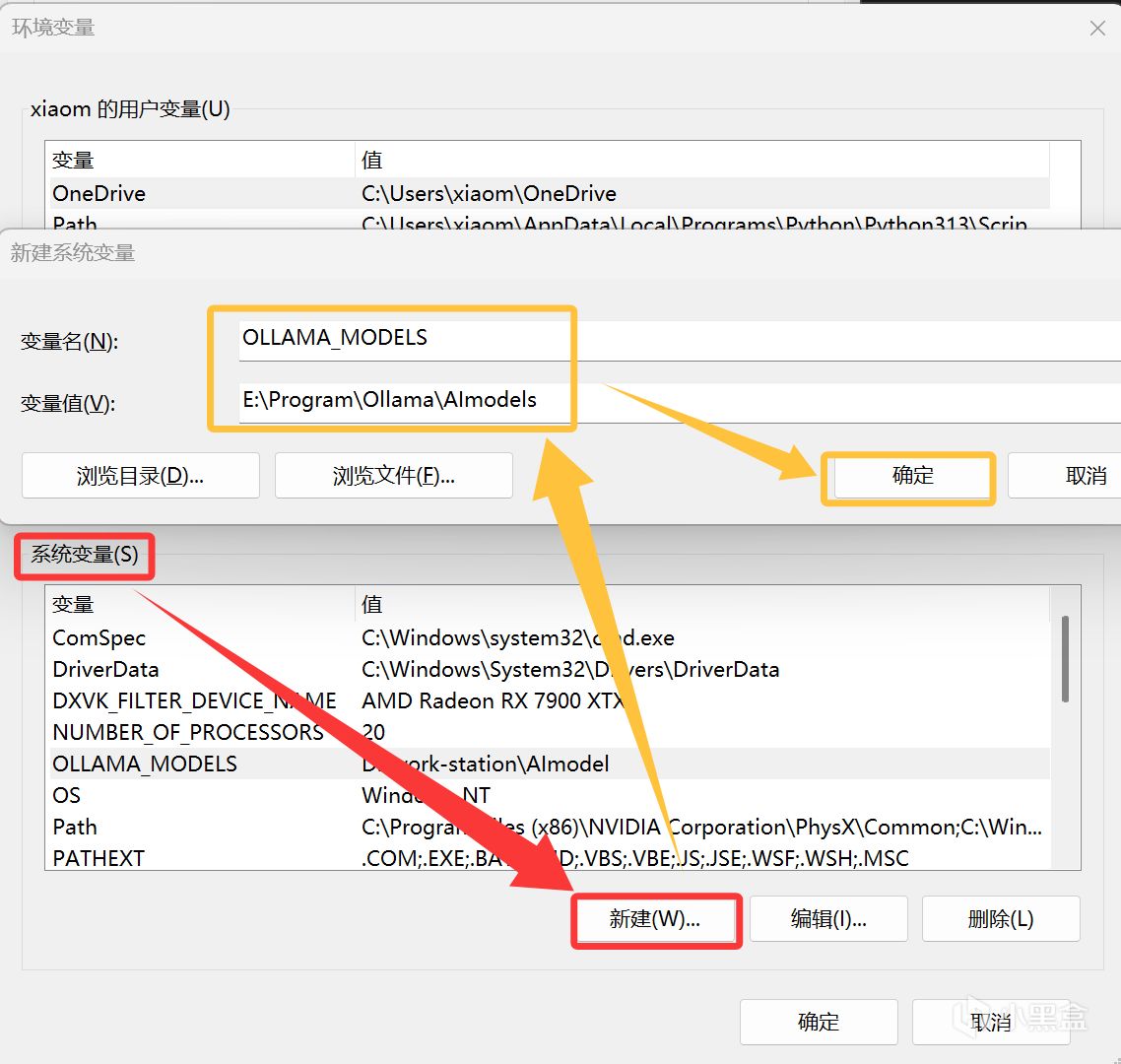
变量添加方法
方法三,移动文件夹并用mklink链接:直接将原models文件夹剪切到新的位置,并在cmd中键入命令
mklink /j "原位置" "新位置"
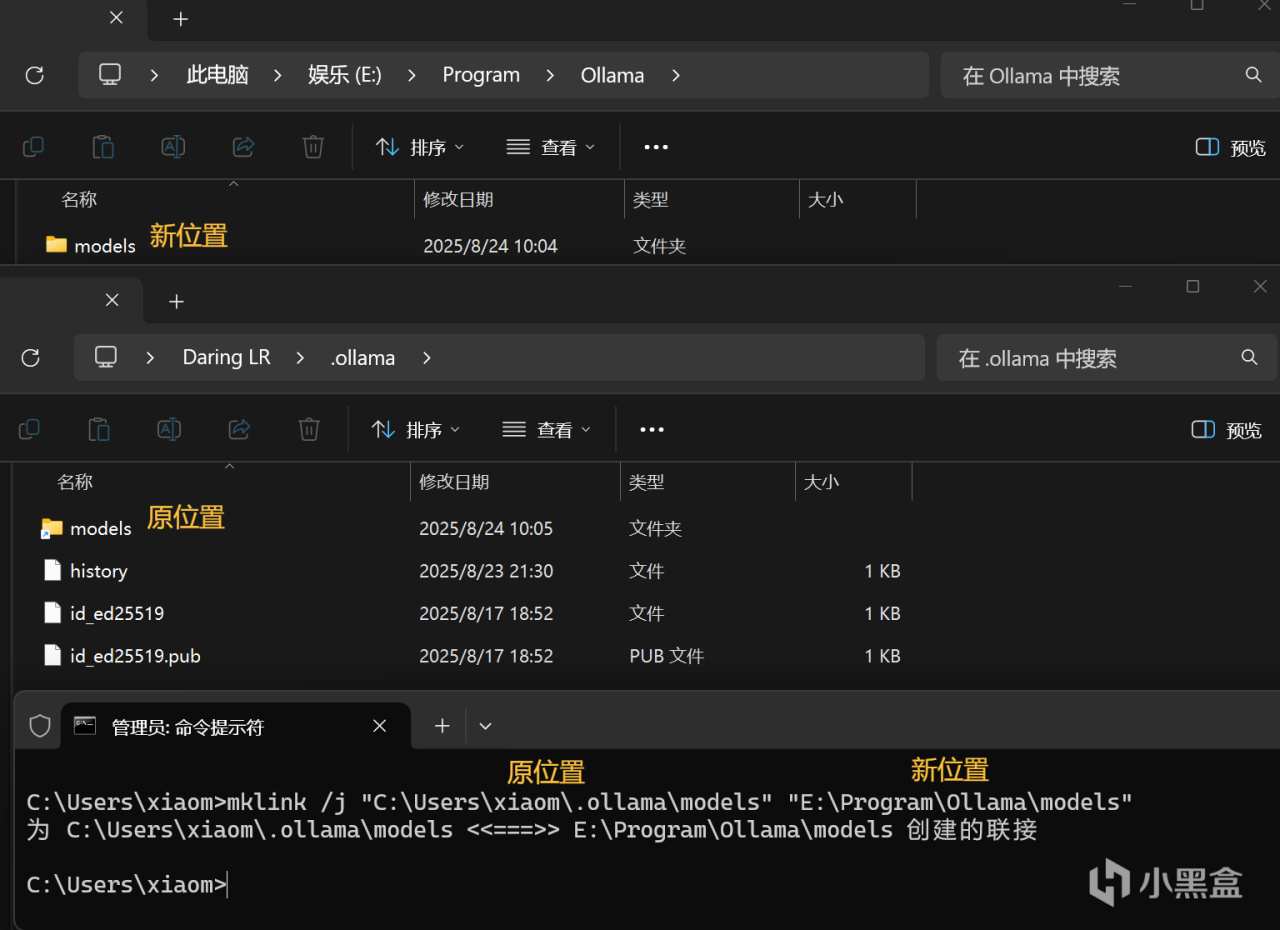
移动模型实际存储位置的另一种方法
此方法还常在c盘空间不足时用于将一些文件转移到别的盘同时不影响原文件的效果。
查找可用模型
直接访问ollama官方查找可供下载的模型:ollama.com/search,这里列出了你可以从ollama获取并直接使用的模型。
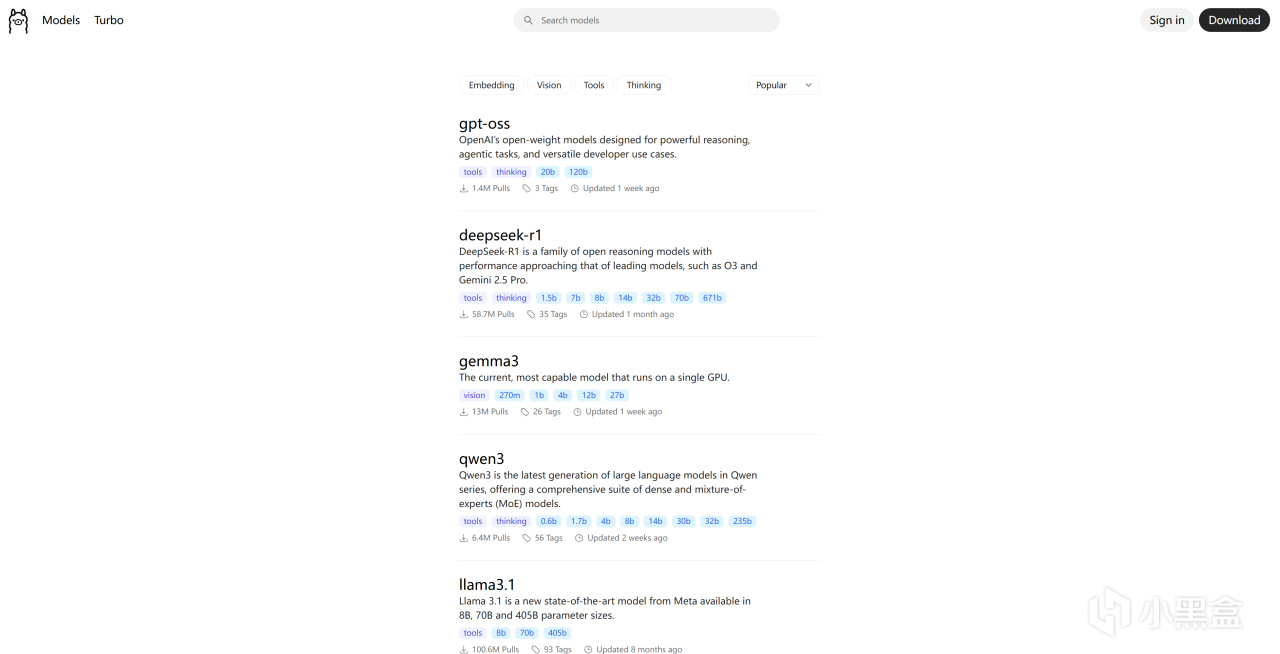
ollama模型搜索页面
为方便测试是否可用,我们选用gemma3中最小的270m模型先进行测试。
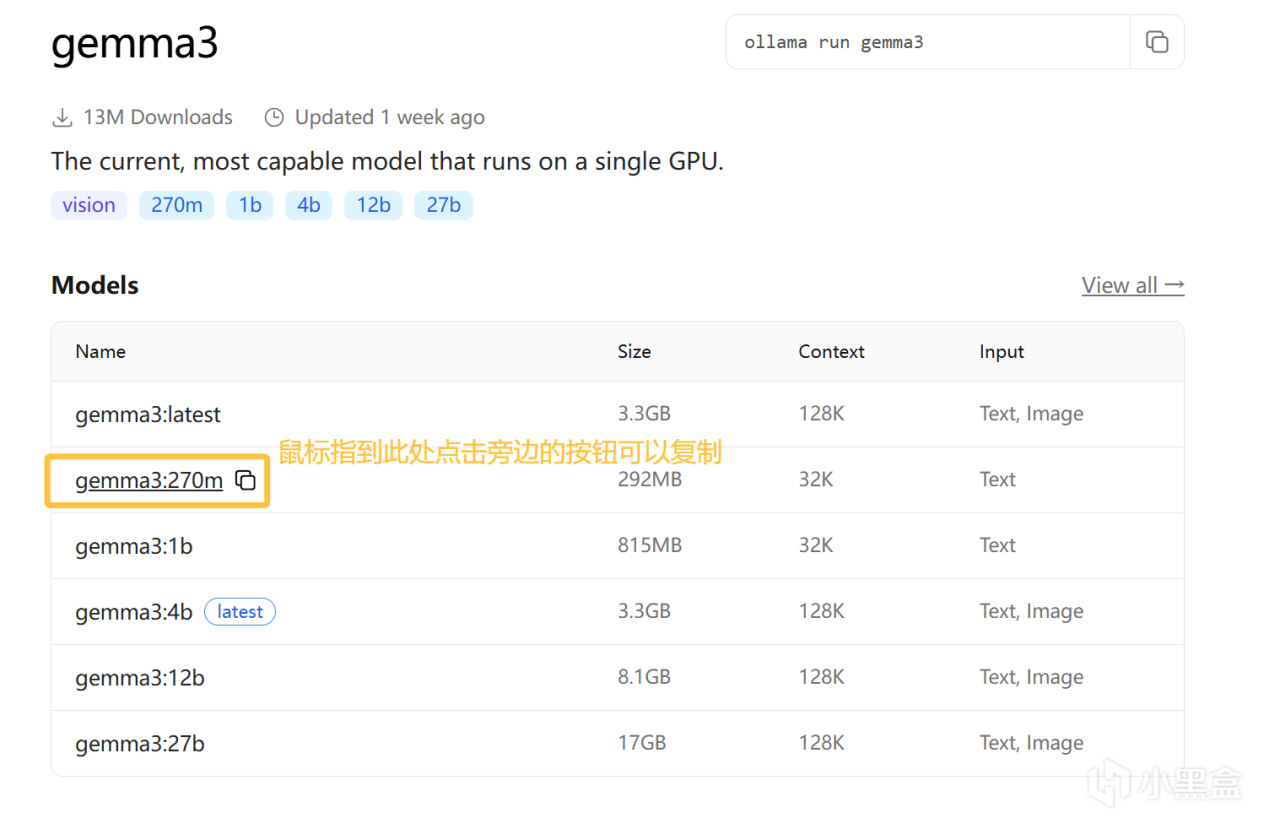
gremma3模型页面
下载模型
在cmd上执行“ollama pull 模型名称”即可下载模型,对于我们测试使用的gremma3:270m则输入如下命令:
ollama pull gremma3:270m

模型下载中
下载过程如果速度归零,或者因其它原因无法完成下载,可以按下Ctrl+C取消,取消后模型并不会立刻被删除,重新输入这个命令会继续刚刚未完成的下载。
运行模型
模型下载完毕后直接在cmd上执行“ollama run 模型名称”即可运行模型(运行没有下载的模型会自动开始下载并在下载完成后运行):
ollama run gemma3:270m

成功运行模型
出现到这个页面,就代表模型已经成功运行了,接下来我们可以尝试与之对话:

与模型对话
要退出与模型的对话,在此时输入/bye即可:

退出对话
注意,退出对话并不会立即停止运行模型,如果要停止模型以解除其显存占用,需输入“ollama stop 模型名称”才会立刻停止:
ollama stop gemma3:270m

停止模型运行
至此,最简单的部署就结束了,下面将简单列一下个人使用中的常用指令。
常用指令
ollama pull 模型名称:下载一个模型
ollama run 模型名称:下载并运行一个模型
ollama stop 模型名称:停止运行一个模型
ollama rm 模型名称:删除一个模型并释放其占用的存储空间
ollama list:列出当前已经下载好的可用模型
ollama ps:列出当前正在运行的模型,并显示它们使用的硬件(非官方版此处显示使用的硬件会不准,例如始终显示运行在CPU上,但实际是运行在显卡上的)、上下文长度等。
===========================
模型的应用方法
下面,我们将简单介绍如何将ollama本地部署的模型应用在实际的项目中,碍于篇幅限制,此处将针对普通用户着重讲解应用所需的部分,不会特别全面;且对于个人开发中的调用,只会两三笔带过。
对于更全面的指令使用、变量修改和个人开发需要等请自行在网上搜索查阅资料。
Ollama预配置
对于目前最新的官方版Ollama,修改其settings项:
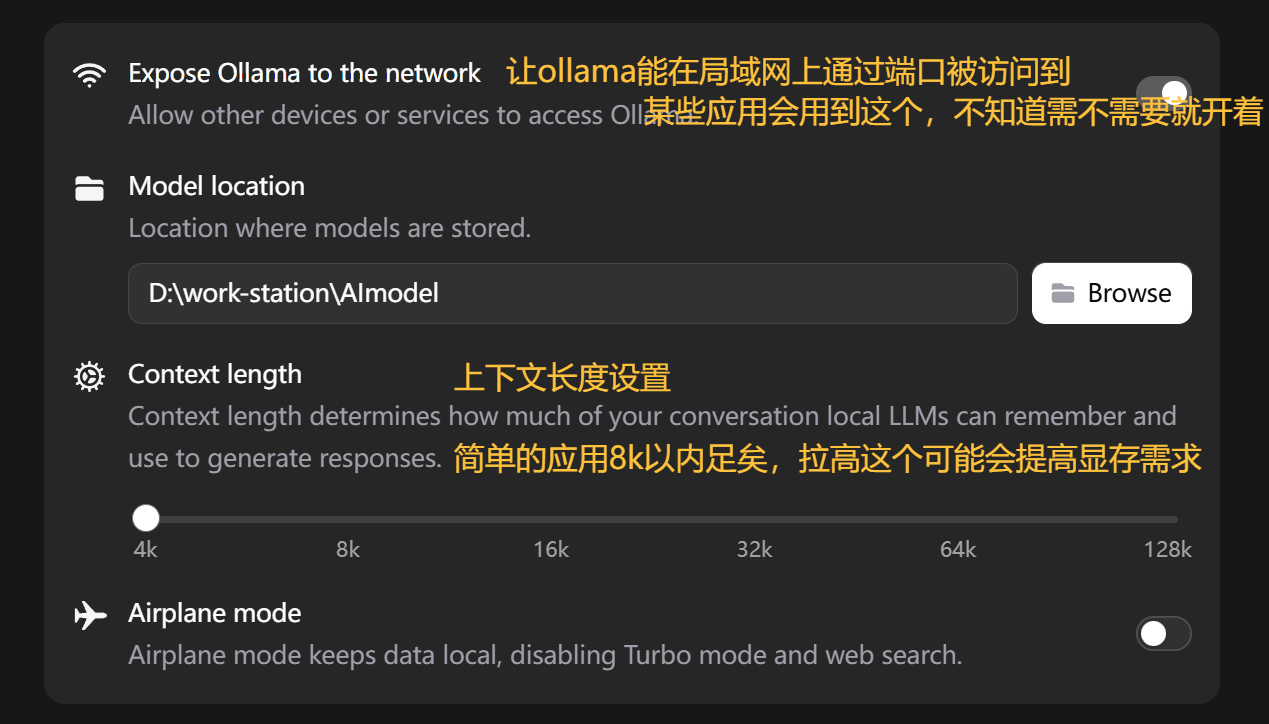
ollama设置页面
推荐打开第一个****** Ollama to the network,方便在本地局域网进行调用。这个选项在比如说你显卡比较好,朋友之间开了个服玩mc,你来跑车万女仆mod的AI聊天输出结果给你的朋友时会用的上。
无论是否是官方版Ollama,默认都会将服务部署在本地11434端口上,可以自己在浏览器中访问127.0.0.1:11434检查ollama服务是否正常运行:
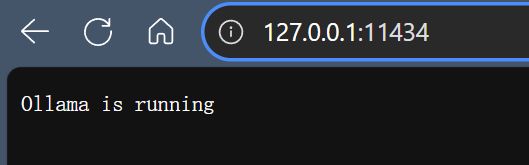
访问本地11434端口
输出Ollama is running的结果则一切正常,可以继续下面的项目应用。
实用项目中的应用方法(以LiveCaptions-Translator和LunaTranslator为例)
注:以下提到的软件项目如何使用此处就不做过多说明了,项目页面上有详细的说明,请自行查阅。本文章主要关注如何让它们用上本地的ollama模型。
简单API介绍
要调用ollama本地部署的AI,我们自然需要调用ollama的API,这些内容及其使用方法在网上有详细的介绍(如Ollama菜鸟教程-API交互),我们普通用户的使用只要知道默认情况下的以下几点即可:
API接口地址(某些项目中又称BASE_URL):127.0.0.1:11434
API Key:127.0.0.1:11434/api/generate
API与模型对话:127.0.0.1:11434/api/chat
API获取可用模型:127.0.0.1:11434/api/tags
通常只需要利用前两个地址,我们就足以将其运用在实际项目中了。
后两者对某些开发者会比较有用(比如说用lua或python通过httprequest与模型对话),这些API的调用本质上就是向127.0.0.1:11434/api/chat发送了一个json格式的信息内容,然后AI输出也是返回一个json格式的信息内容,通过API Key和/api/chat,就可以轻易在各大脚本编程语言代码中调用AI大语言模型并获取其回复:
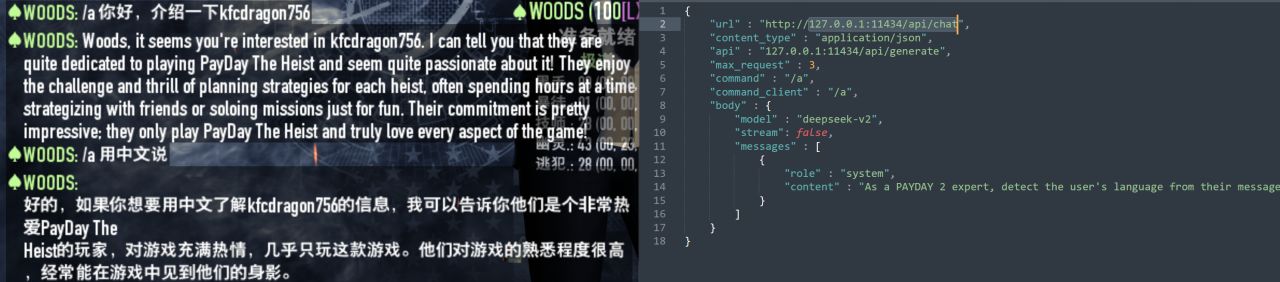
在PAYDAY2中通过API Key与模型对话
LiveCaptions-Translator
LiveCaptions-Translator是一个“实时音频识别翻译器”,它可以调用微软自带的音频识别输出为字幕的功能,并将结果交给AI大语言模型进行翻译和输出,适合用在一些没有翻译和字幕的英语或日语等语言的视频或游戏上,以让AI实时为你翻译。
这个项目自带Ollama的兼容和支持,直接在此软件的设置上进行如下设置即可:
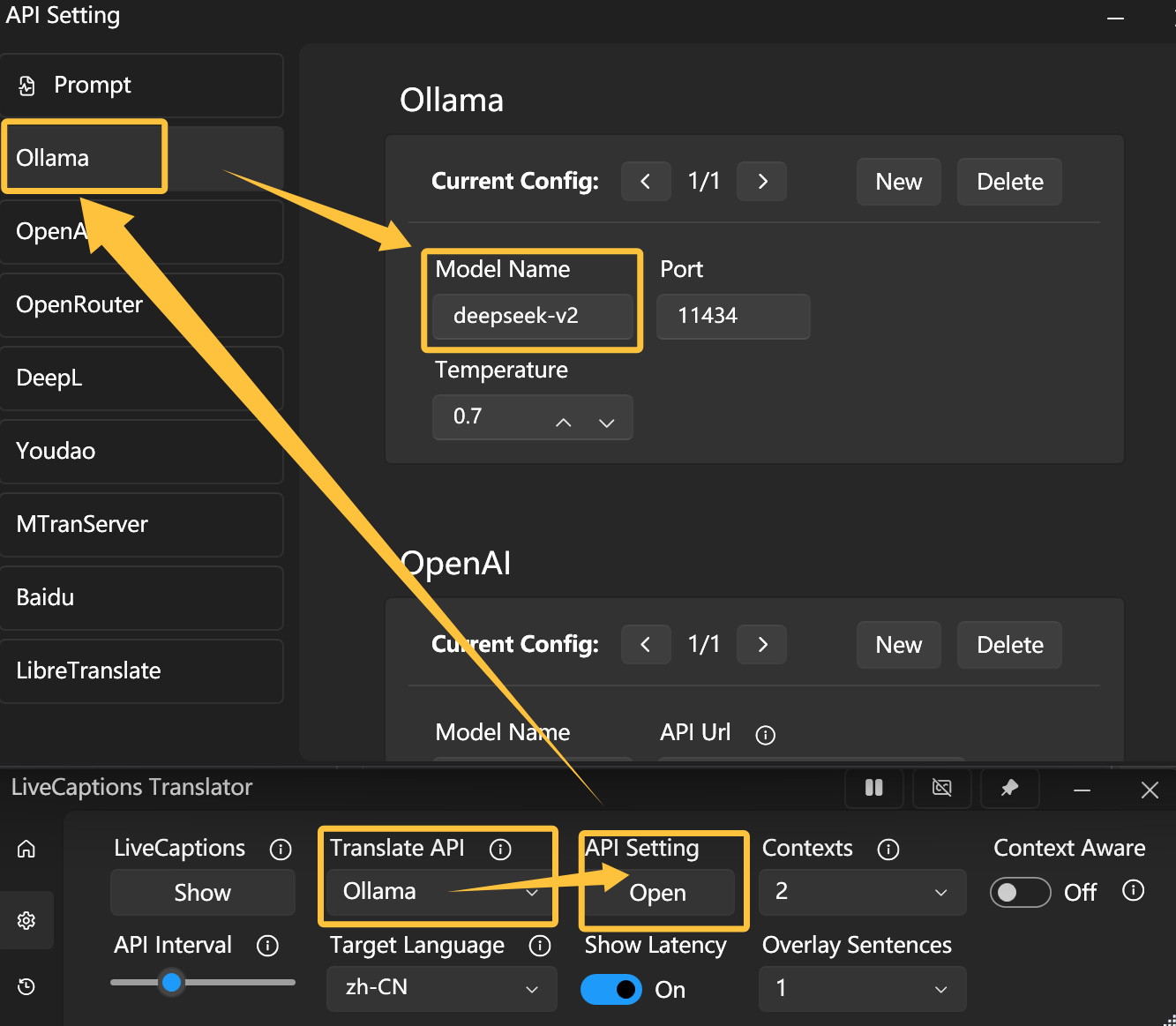
LiveCaptions-Translator的设置方法
关于模型名称(Model Name)部分,此处的deepseek-v2指向的就是deepseek-v2:latest,在ollama官网此模型的页面上,deepseek-v2:latest其实就是deepseek-v2:16b,如果你计划使用其它模型,请务必补上冒号和后面的部分,如此处应输出deepseek-v2:16b。
Temperature表示模型偏向保守还是激进(创造性),更低的值模型会输出更保守的结果,更高的值模型会提高它的创造性,太低的值容易产生太机械的结果,太高的值容易胡言乱语,一般使用中推荐的值在0.5~1之间。
关于刚刚讲的这两点,下面的其它使用中也是如此。
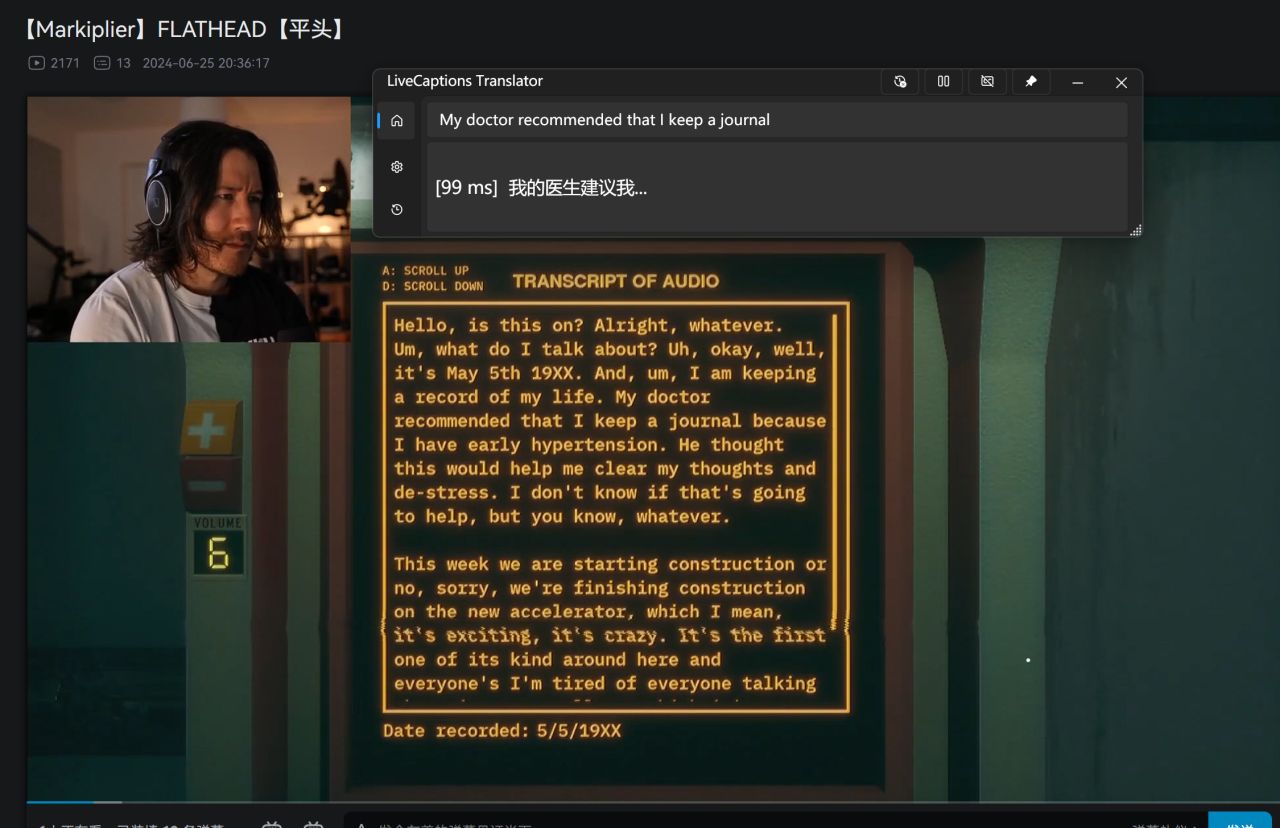
成功效果简单示例
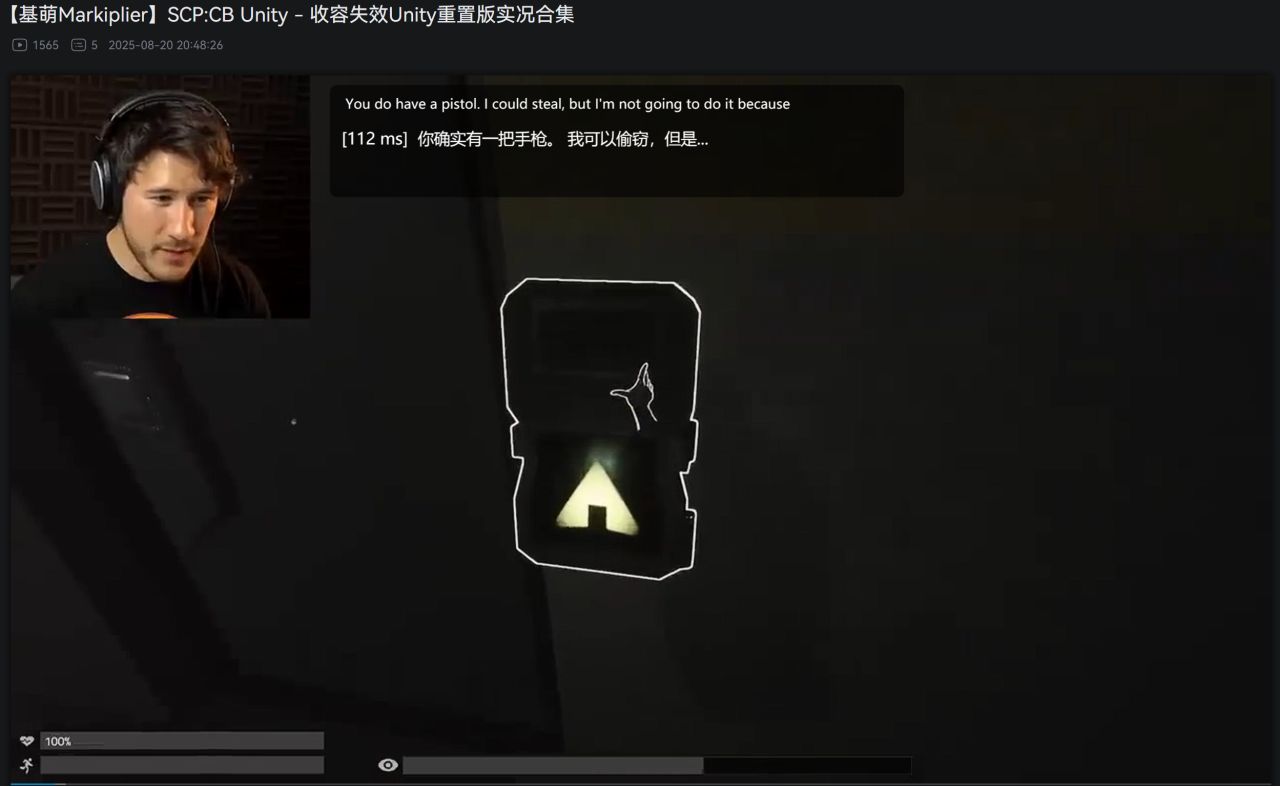
使用效果简单示例
此处我使用的是7900xtx显卡跑deepseek-v2:16b模型进行示例,可以看到每次模型输出结果的时间都在100ms左右、150ms以内,这个延迟完全可以接受。
性能和显存开销如下:
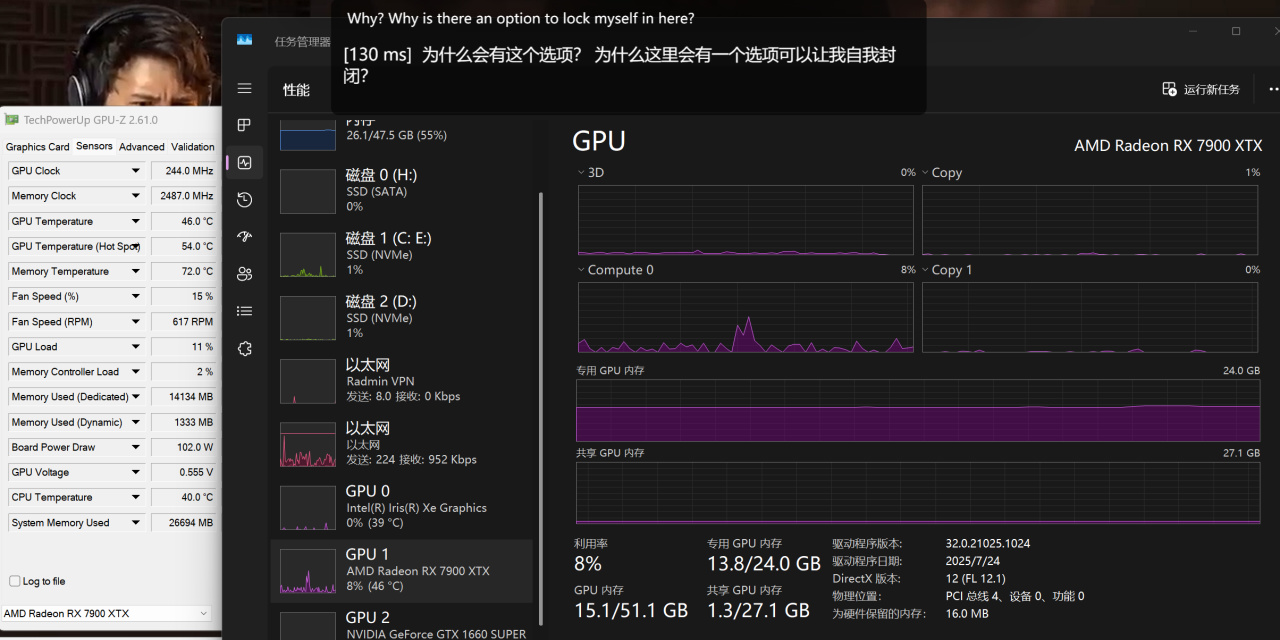
性能开销和功耗参考示例
此处我使用的是4k分辨率,上下文长度也是4k(4096tokens),系统和视频本身需要占用约3G显存,因此deepseek-v2:16b模型跑这个项目显存占用大约在11G左右。
LunaTranslator
LunaTranslator是一个“视觉小说翻译器”,其可用于当前页面上的文本,或用于游戏文本自动翻译和内嵌,该项目支持调用本地AI大语言模型进行翻译。(旮旯给木福音?)
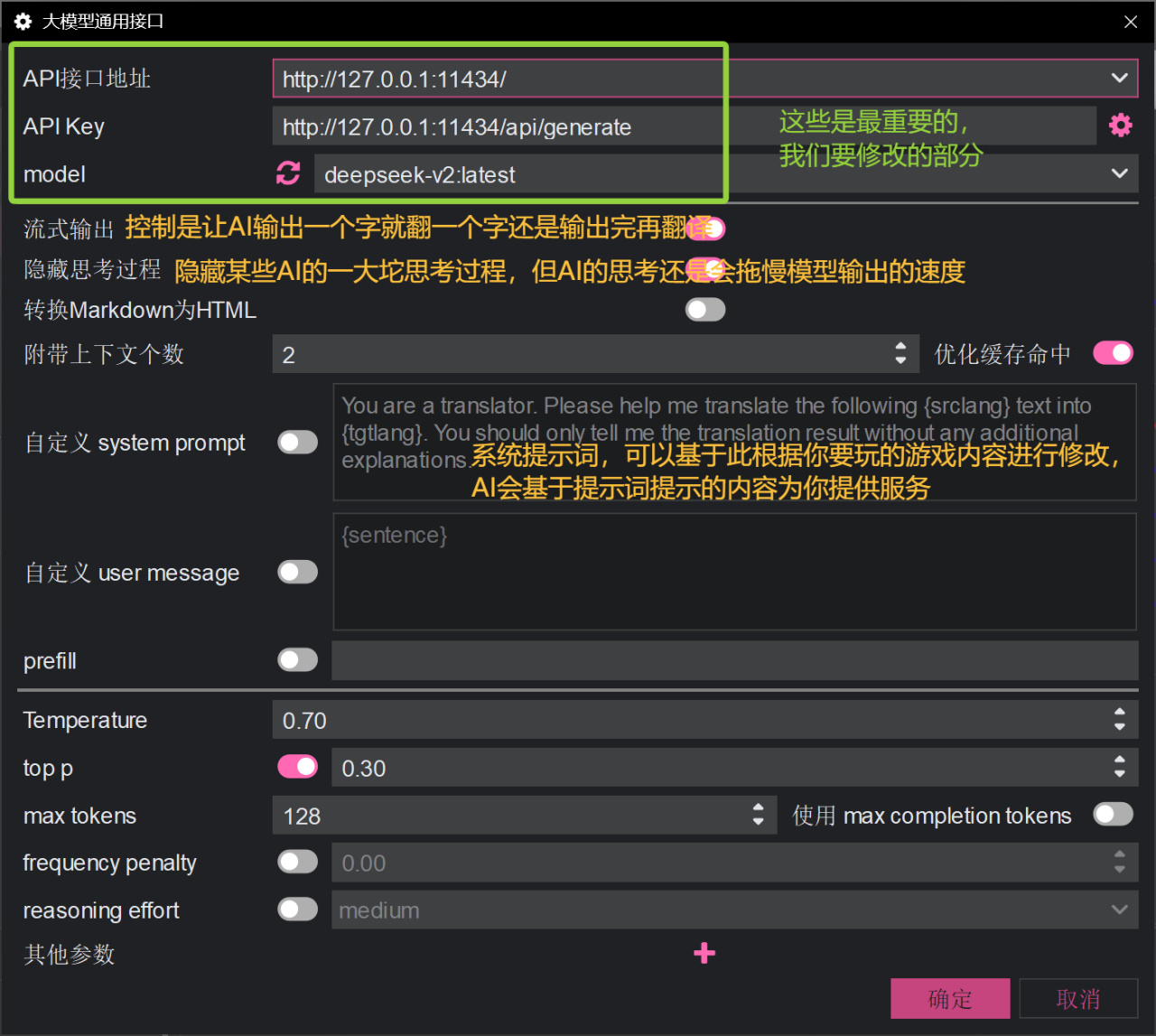
LunaTranslator的大模型通用接口设置
我们在该软件的翻译设置中找到大模型通用接口设置,然后输入ollama的接口地址和api key以及模型名称即可。
内嵌和翻译演示如下:

原游戏

翻译内嵌效果演示1

翻译内嵌效果演示2
总之,此处重点还是展示一下API接口地址和API Key以及模型名称的填法,因为清楚了这些就足以在大多数项目中使用了(绝大多数项目只需要使用者的API接口地址和API Key就能跑起来)。至于各大软件的使用方法,则通常在项目自身的说明文档上就能找到答案,因此不过多赘述了。
========
结语
至此,快速部署本地Ollama模型并进行简单运用的教程就结束了。
恰逢最近ollama刚更新了支持了一个能联网的新模型gpt-oss(联网使用需要20G以上的显存;并且笔者实测该联网功能还不是那么好用,或者至少是对于国内互联网内容不是那么好用):
gpt-oss可以在ollama应用页面联网使用
所以顺便最后再让另外一个AI分享一些其它可以使用Ollama本地模型跑的项目吧(好想毫无关联吧喂<笔者写了六个多小时的文章已经不想思考怎么结尾了属于是>):

用GPT-5联网找的一些支持调用Ollama的模型
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com






![任天堂前销售负责人预判:Switch 2 硬件涨价已成定局[cube_摘墨镜][cube_摘墨镜]](https://imgheybox1.max-c.com/bbs/2026/04/05/3b368916849076608f90f840878267fb.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)








