重要的放前面:
軟件功能如題,這裏是我自己用Pyinstaller打包的exe,文末附有python腳本代碼。
exe啓動的時候有詳細的使用說明,你可以直接把EPUB文件或者裝有EPUB文件的文件夾拖進去,然後它就會在文件所在的位置生成帶有“_簡中”後綴的新文件,不會替換舊文件,放心使用。
-------------------------------------------
通過百度網盤分享的文件:繁體改簡體.exe
鏈接:https://pan.baidu.com/s/17-_HQC9fkFRFVY-92RG1xQ?pwd=od69
提取碼:od69
-----------------------------------------
當然還是遇到了一些無法解決的問題,不同軟件對EPUB的讀取方式不太一樣,處理之後的文件,用微信讀書打開的時候會丟失扉頁,用WPS打開時,WPS無法自動添加首行縮進。另外還有例如“着”的繁體字是“著”,而“著”本身也是個簡體字,所以它沒被替換。
正文是一些,嗯……,我也不知道該算啥,看代碼可以直接看最後面,問題展示也在正文部分。說起來我一直不會小黑盒的排版,亂的讓人難受。
以下是正文
近期看到網友分享讓deepseek角色扮演的角色定義指令,塵封多年的赫蘿一下就把我腦子佔滿了,再三嘗試,定義出來的赫蘿終究不如動漫中的動人心絃,也許我想看的是赫蘿和羅倫斯的故事,而不是把我當成羅倫斯的赫蘿,或者,失去羅倫斯許久的赫蘿……於是我準備N刷,然後我驚喜的發現狼與香辛料2024年翻新了,而且新的製作組準備把小說出完,我的天吶,我們狼與香辛料粉絲喫的實在是太好了,懷着忐忑的心情,看完新作,和08版比起來有很多可圈可點的地方,新的製作組真的懂現在的大夥兒喜歡看什麼,赫蘿非常可愛,不過比起舊版少了一些氛圍感,小清水亞美的配音也和以前有寫不一樣了(沒辦法,16年了啊),還把赫蘿畫的跟個二哈一樣,有些緊張的情節看到二哈就緊張不起來了。

24版赫蘿狼形態
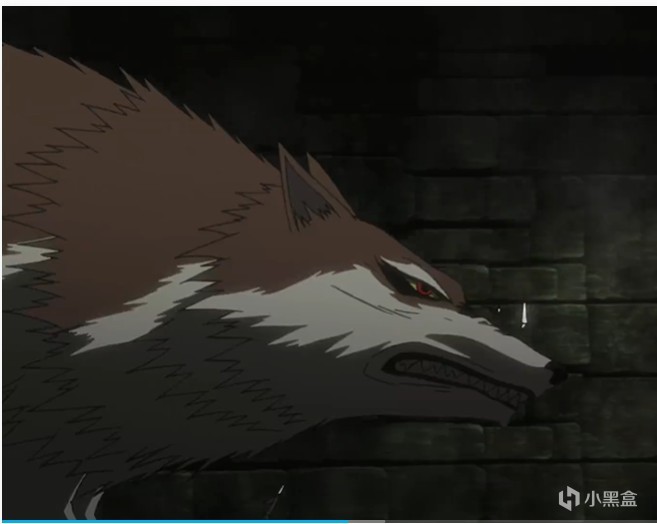
08版赫蘿狼形態
然後二刷完的我就去看小說了,結果下載了一堆打開發現是繁體,可能因爲我在國外的原因,於是我就寫了個腳本用來把繁體轉爲簡體:
問題展示:
用WPS打開時,WPS無法自動添加首行縮進。

原版WPS打開時加上了段首縮進
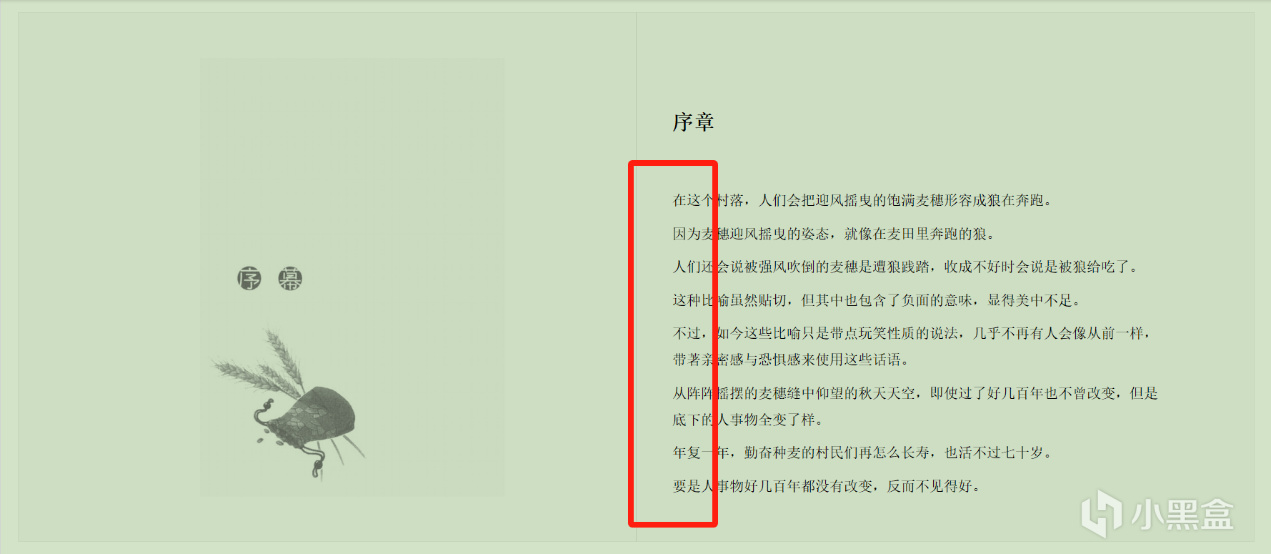
修改後WPS打開時沒有段首縮進
微信讀書丟失扉頁:

扉頁
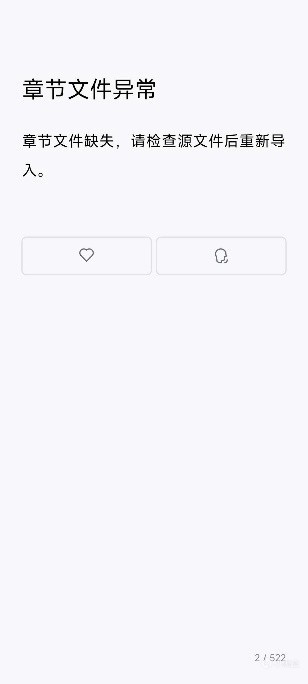
丟失的扉頁
最後是代碼部分
程序簡介:
os: 處理文件和目錄路徑
lxml.etree: 解析XML/HTML內容(雖然代碼中未直接使用,但ebooklib依賴)
ebooklib: 讀寫EPUB文件的核心庫
ITEM_DOCUMENT: 標識EPUB中的文本內容項
OpenCC: 中文簡繁轉換庫
處理流程:字節流 → UTF-8解碼 → 簡繁轉換 → UTF-8編碼
解析EPUB文件結構→遍歷所有內容項→只處理HTML/XHTML文檔(跳過圖片/CSS等)→逐文件進行簡繁轉換→保存新EPUB文件
代碼如下:
顯然小黑盒把我排好的版都弄亂了,所以你粘貼走肯定是用不了的……我去CSDN再發一下吧。
import os
import lxml.etree
from ebooklib import epub, ITEM_DOCUMENT
from opencc import OpenCC
cc = OpenCC('t2s')
def convert_text_traditional_to_simplified(text_bytes):
try:
text_str = text_bytes.decode('utf-8')
converted_str = cc.convert(text_str)
return converted_str.encode('utf-8')
except Exception as e:
print(f"文本轉換錯誤: {e}")
return text_bytes
def convert_epub_traditional_to_simplified(epub_path, output_path):
try:
book = epub.read_epub(epub_path)
for item in book.get_items():
if item.get_type() == ITEM_DOCUMENT:
original_content = item.get_content()
converted_content = convert_text_traditional_to_simplified(original_content)
item.set_content(converted_content)
epub.write_epub(output_path, book)
print(f"轉換完成: {output_path}")
except Exception as e:
print(f"處理文件 {epub_path} 時出錯: {e}")
def process_input(input_path):
try:
input_path = input_path.strip('"') # 去除拖放路徑中的引號
if os.path.isdir(input_path):
print(f"正在處理文件夾: {input_path}")
for filename in os.listdir(input_path):
if filename.lower().endswith('.epub'):
input_file = os.path.join(input_path, filename)
name, ext = os.path.splitext(filename)
output_filename = f"{name}_簡中{ext}"
output_path = os.path.join(input_path, output_filename)
convert_epub_traditional_to_simplified(input_file, output_path)
elif os.path.isfile(input_path) and input_path.lower().endswith('.epub'):
print(f"正在處理文件: {input_path}")
name, ext = os.path.splitext(input_path)
output_path = f"{name}_簡中{ext}"
convert_epub_traditional_to_simplified(input_path, output_path)
else:
print("錯誤: 輸入的路徑不是文件夾或EPUB文件")
except Exception as e:
print(f"程序運行出錯: {e}")
def main():
print("這是一個繁體轉簡中軟件,目前只支持EPUB文件格式")
print("輸入文件夾路徑或者文件路徑,按下ENTER以開始程序")
print("你可以直接將你的文件夾或者文件拖到這個窗口")
input_path = input("請輸入路徑: ")
process_input(input_path)
input("按ENTER鍵退出...") # 防止窗口立即關閉
if __name__ == "__main__":
try:
main()
except Exception as e:
print(f"程序發生意外錯誤: {e}")
input("按ENTER鍵退出...")
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















