凌晨的互聯網從來不會讓人失望。
雖然前段時間有關 Gemini 小道消息已經鋪天蓋地,但當谷歌真正把 Gemini 3 擺到臺前時,整個技術圈還是像被人敲了一棒一樣瞬間炸開了。

按照“字越少、事越大”的行業規律(這裏我們再次diss某“開源就是智商稅”的企業,天天動不動就喜歡開發佈會數字對標),這次谷歌的登場方式也算把話說透了:不講玄學提升,不賣情緒價值,直接把“我們這代模型主打一個實用”寫在了臉上。
更有意思的是,這次 Gemini 3 的發佈,甚至就連身爲對手的奧特曼都點了個贊。
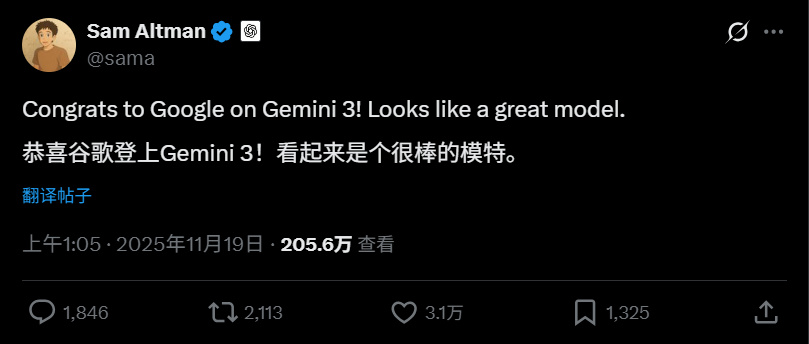
能獲得同行的讚美,說明 Gemini 3 確實有點東西,不過我個人更認可這張👇
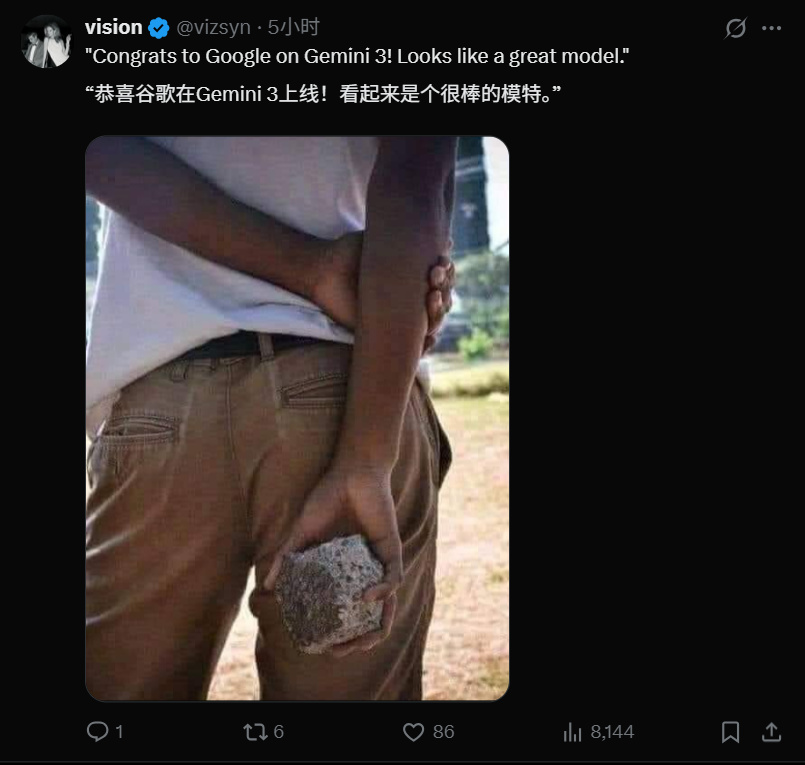
這次谷歌明顯改變了策略。
不再只盯着“回答是否自然”,而是把重點放在“能不能幫你把事情做了”。更長的上下文、更強的多模態理解、更穩的編碼與代理能力,全都圍繞這個目標展開。
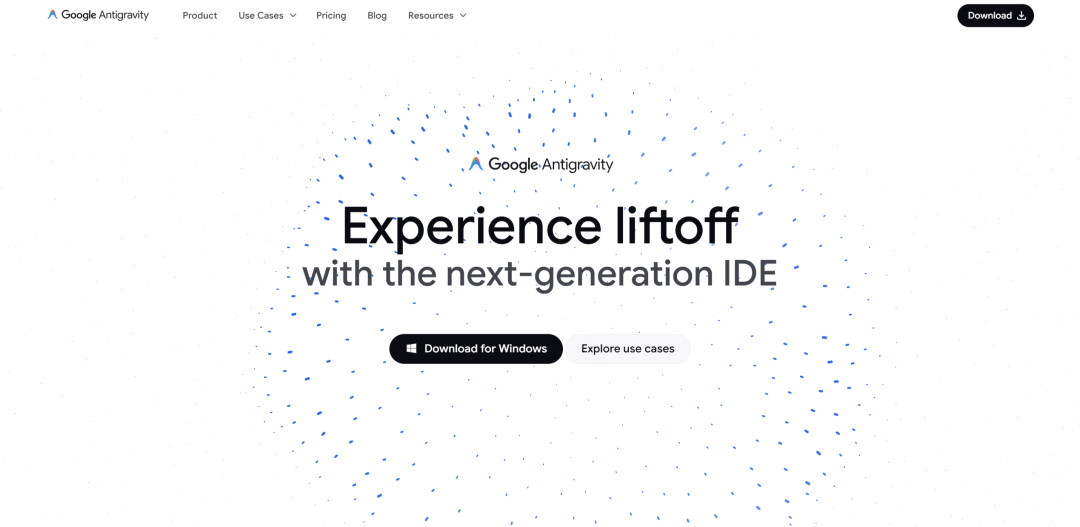
爲了讓開發者真正用起來,谷歌還配了個全新的 Antigravity 平臺,算是把“AI 和 IDE 融合”推向了一個新階段。
再看模型卡里那些細節,谷歌給得異常乾脆。
架構上採用 Sparse MoE,支持文本、圖像、音頻、視頻,最長上下文百萬級,輸出上限 64K tokens。
整體參數上乍一看其實跟現在別家的旗艦模型相比,其實沒啥亮眼的,畢竟只捲紙面參數的時代已經過去,現在講究的是實際體驗。
比如這次讓人眼睛一亮的是生成式界面(Generative UI)。
Gemini 3 給出的不再只是文字答案,而是能交互的界面。
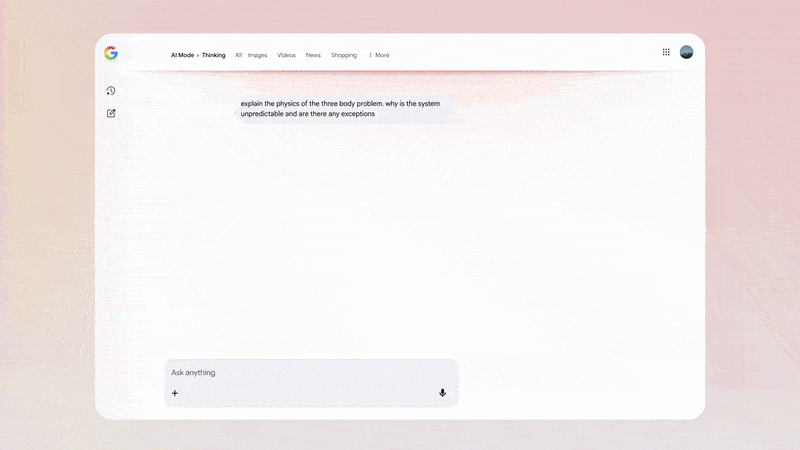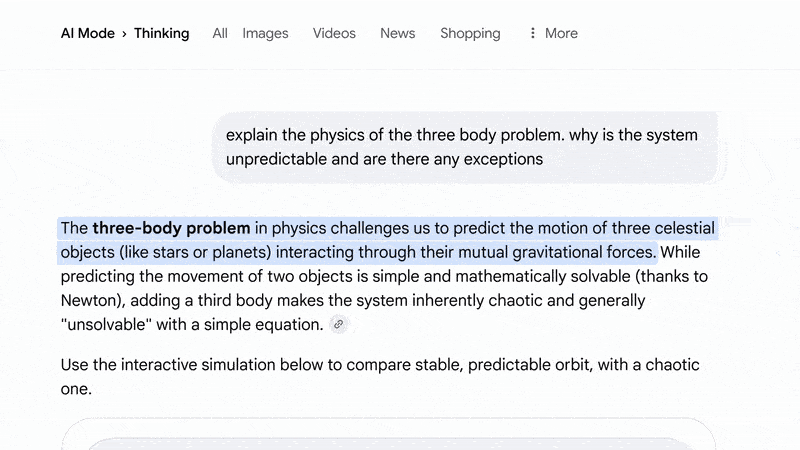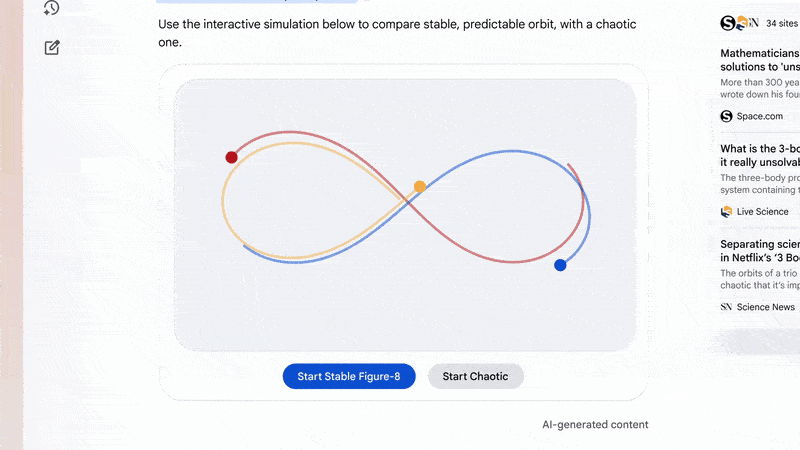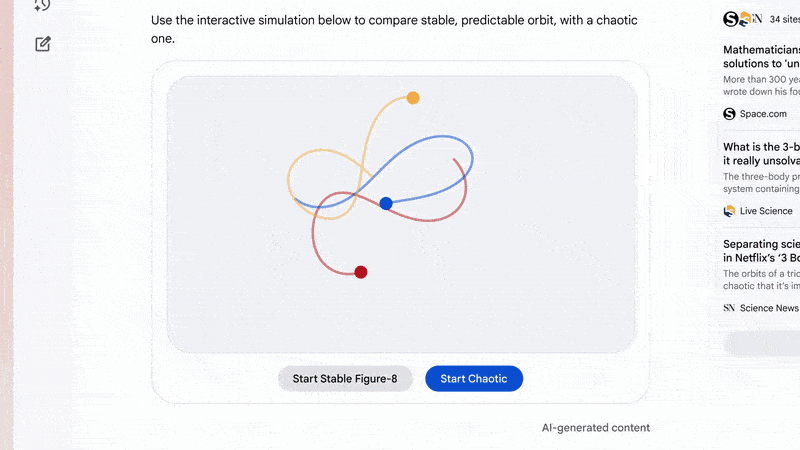
問個問題直接幫你打開網頁👇。
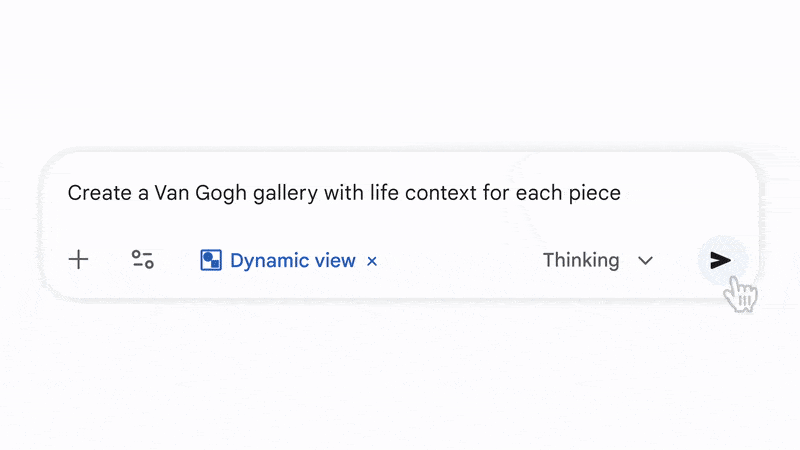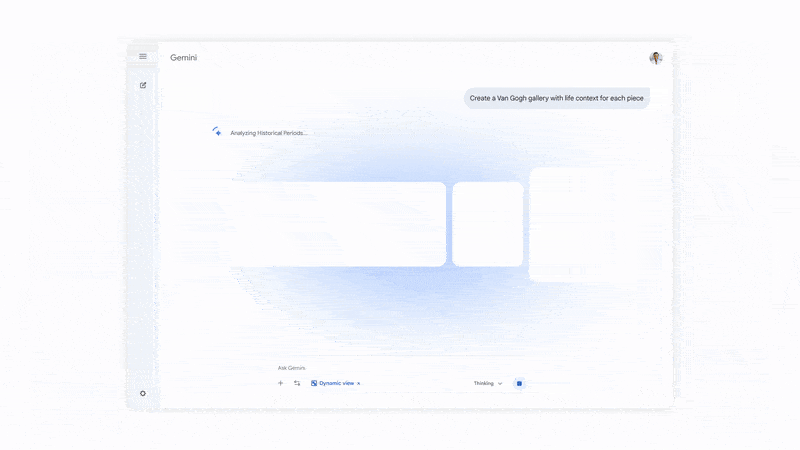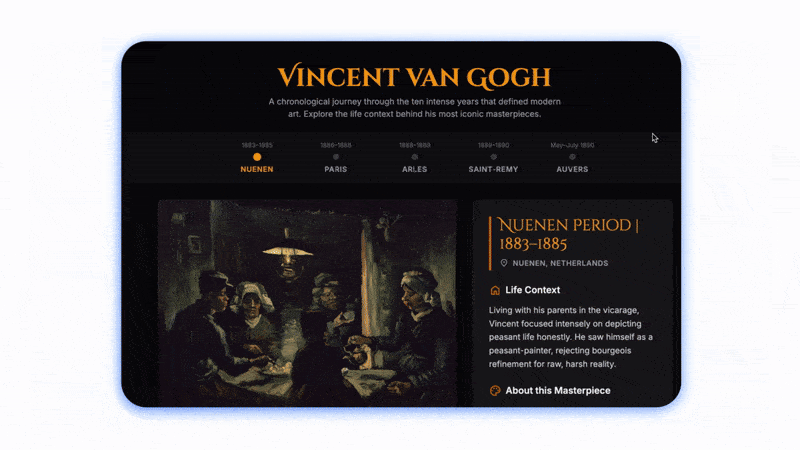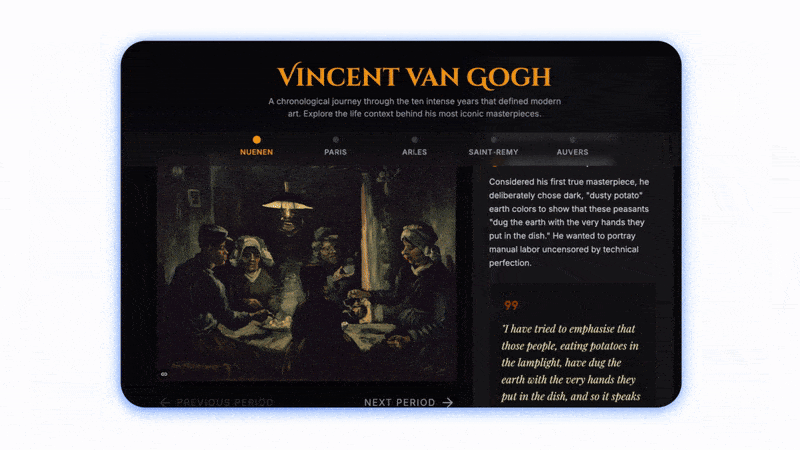
這不止是“有趣的展示”,這是新的人機界面邏輯,即 AI 不再等你適應它的框架,而是反過來主動生成最適合你的操作結構,類似於自適應,只不過這次是 AI 自適應你。
如果說 GPT 和 Claude 仍然是“通過文字互動的工具”,Gemini 3 更像“隨場景變化形態的應用容器”。界面不再是固定資產,而是模型的實時產物。
3D 理解和生成能力也有了長足的進步👇。
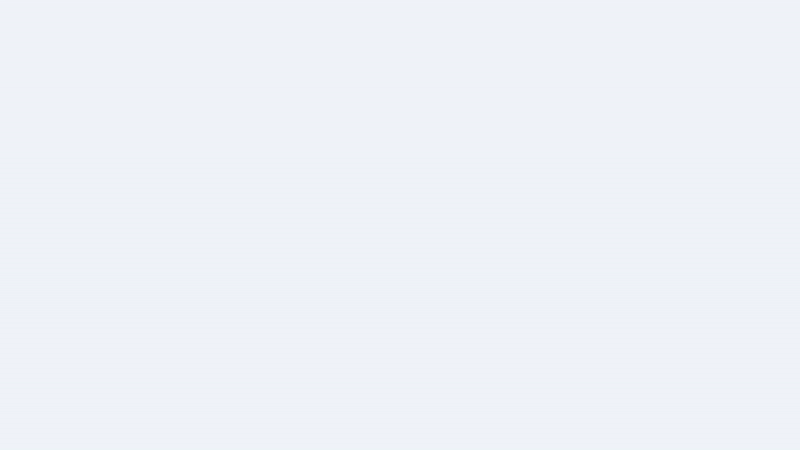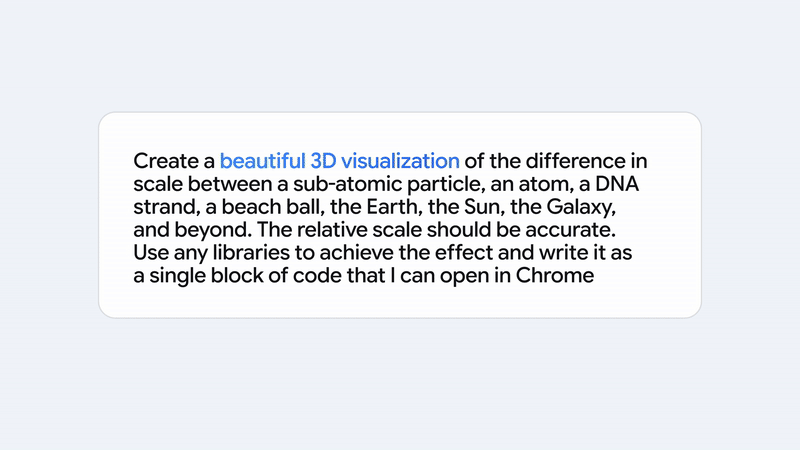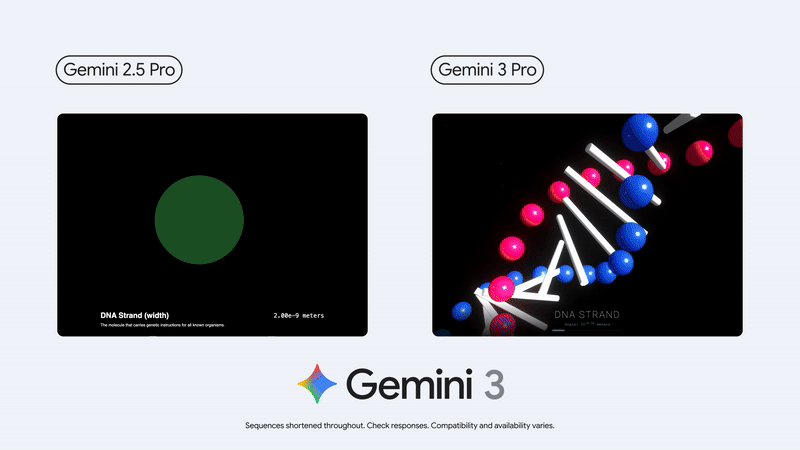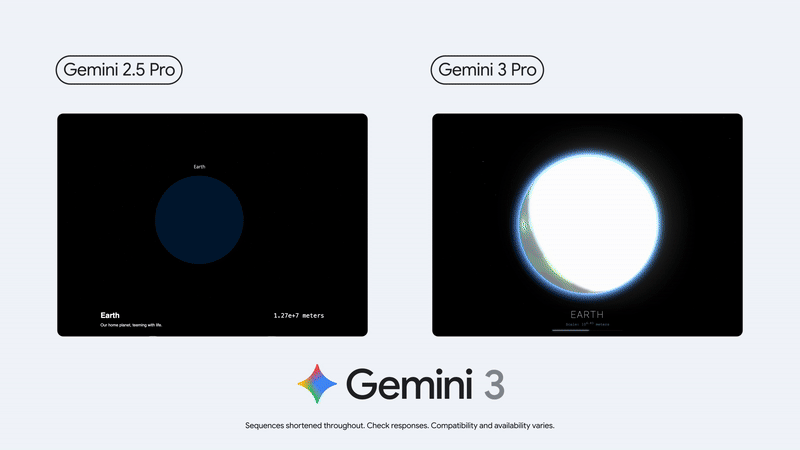
再來看跑分部分。
雖然這類數據常常被討論得太過頭,正如我們前面提到的,但趨勢是趨勢,跑分咱還是得看看。
Gemini 3 Pro 在 LMArena 的用戶投票場打到了 1500+,直接壓過前一天剛登頂的 Grok 4.1(馬斯克:請輸入文字)。多模態領域更是它的主場,Video-MMUU、MMMU-Pro、屏幕 UI 推斷這些“真實世界輸入”的任務裏,它都在最前排。

編碼能力也上來了。
TerminalBench 2.0 拿到 54.2%,LiveCodeBench Pro 刷新紀錄,跨文件重構、長會話調試這些原本容易暴露穩定性問題的場景,它表現得比以前從容。
你甚至能感覺到,谷歌這次不是在做“聊天模型”,而是在做“工程輔助系統”。模型卡對它在 Agent、長任務、跨模態推斷的定位也寫得非常清楚——適合處理現實複雜度高的問題,需要一步步改進的情況。

長週期任務的表現也很亮眼。
谷歌做了個“自動售貨機經營一年”的模擬,讓模型自行規劃補貨、定價、策略。結果是 Gemini 3 的利潤明顯高於 GPT-5.1 和 Claude 4.5。

可以說這個測試有遊戲屬性,但它確實說明了 Gemini 3 在“長期保持目標一致性”上有優勢。
還有一個容易被忽略的點在變化在文本風格上。
Gemini 3 開始趨向“講重點、不奉承”的輸出方式。谷歌直接放話說它不會像某些模型那樣放彩虹屁。模型卡的自動化評估也顯示,Gemini 3 在“拒絕的語氣”和“邊界處理”上比 2.5 更好,拒絕率下降了,不當奉承也降了。
這種語氣本質上是一種“價值取向”調整。
模型不再只會討你開心,而是學着給你最乾淨的信息,這一點未來估計會引發爭論,類似 GPT-5 上線那會的情況類似。
就在奧特曼誇讚 Gemini 3 的帖子下還有人在呼籲的👇

寫到這裏,整個 Gemini 3 的定位已經很清楚了。
它不是“更聰明的對話框”,而是“能隨需生成應用的 AI”。界面、流程、邏輯都可以實時變化,你的問題不再是文本輸入,而是建構輸入。
你說你的需求,AI 直接給你一個應用程序式的響應結構。
如果這條路走得通,軟件的定義會被重寫。應用不再是產品,而是現場生成的行爲組合。開發者要做的也不再是“寫一個能跑的功能”,而是“描述一個任務,讓模型自己搭功能”。
這不止是一個的模型發佈,而是一次徹底的方向轉向,至於這方向是不是未來?你大可以繼續觀望。
但從 Gemini 3 開始,至少我覺得,這個問題已經不再是“會不會發生”,而是“什麼時候全面發生”。
我是 CyberImmortal,關注我們,帶你暢遊AI世界!
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















