在2025年3月19日举办的NVIDIA GTC 2025大会上,英伟达(NVIDIA)宣布,其搭载Blackwell GPU的DGX系统成功创造了满血DeepSeek-R1模型AI推理性能的世界纪录。这一突破不仅刷新了AI推理速度的天花板,更向全球展示了英伟达在AI硬件与软件协同优化上的惊人实力。究竟是什么让这台“AI怪兽”如此强悍?让我们一探究竟!

Blackwell DGX
▶︎单机8卡狂飙:每秒3万token的吞吐量
英伟达透露,在一台配备8块Blackwell GPU的DGX B200系统上,运行6710亿参数的DeepSeek-R1模型时,每位用户可获得超过250 token/秒的响应速度,而整机最高吞吐量突破了惊人的3万 token/秒。这一性能得益于Blackwell架构的第二代Transformer Engine、FP4 Tensor Core以及第五代NVLink高速互联技术的加持。

8块Blackwell GPU
相比之下,基于Hopper架构的DGX H200(同样8卡配置)虽然表现出色,但在相同测试条件下吞吐量明显逊色。英伟达表示,自2025年1月以来,通过硬件升级和TensorRT-LLM软件优化,DeepSeek-R1的吞吐量提升了约36倍,成本效率更是跃升32倍。这种飞跃式进步无疑将为AI开发者带来更高效的推理体验。
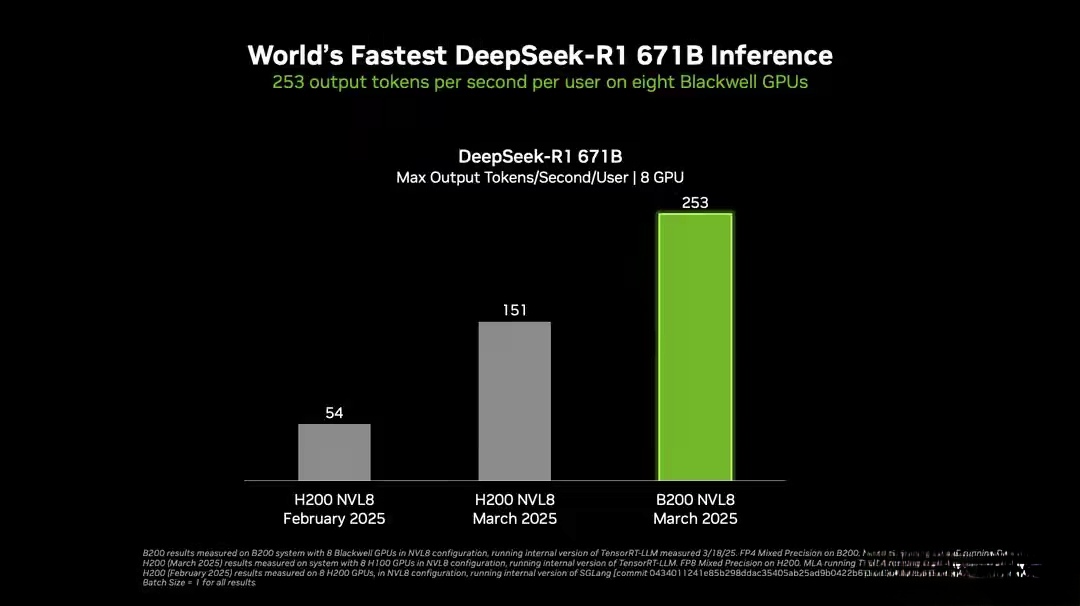
DeepSeek R1的推理性能飞跃
▶︎测试细节曝光:FP4精度下的极致优化
本次测试采用了TensorRT-LLM内部版本,输入长度为1024 token,输出长度为2048 token,相比此前1月和2月的测试(输入/输出均为1024 token),任务复杂度显著增加。计算精度方面,DGX B200使用FP4精度,而DGX H200和H100则采用FP8精度。即便在更低的FP4精度下,Blackwell依然展现了无与伦比的性能优势。
英伟达还对比了多节点配置的表现:单台DGX B200(8卡)、单台DGX H200(8卡)以及双台DGX H100(共16卡)。结果显示,Blackwell架构配合TensorRT软件,在推理吞吐量上比Hopper架构高出数倍。例如,在运行DeepSeek-R1、Llama 3.1 405B和Llama 3.3 70B等大模型时,DGX B200的FP4推理吞吐量是DGX H200的三倍以上。
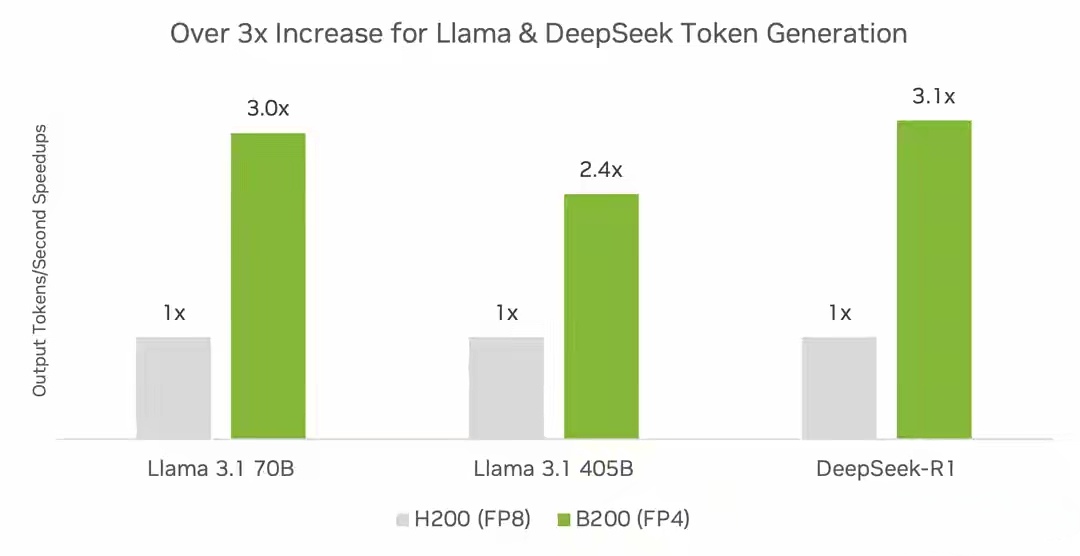
▶︎精度与性能兼得:FP4仅微损
低精度计算是提升AI推理效率的关键,但精度损失往往令人担忧。英伟达通过TensorRT Model Optimizer的FP4训练后量化(PTQ)技术,成功将精度损失降至最低。以DeepSeek-R1为例,FP8基准精度在MMLU、GSM8K等数据集上的表现分别为90.8%和96.3%,而FP4精度仅略降至90.7%和96.1%,在AIME 2024和MATH-500等数学任务上甚至几乎无差别(80.0% vs 80.0%、95.4% vs 94.2%)。这意味着开发者可以在不牺牲模型质量的情况下,享受FP4带来的性能红利。
▶︎Blackwell的秘密武器
相比Hopper架构,Blackwell为何如此强悍?答案在于硬件与软件的双重突破。Blackwell架构引入了FP4 Tensor Core,支持更高效的低精度计算,同时第五代NVLink和NVLink Switch提供了超高带宽的数据传输能力。配合开源的NVIDIA推理生态(如TensorRT-LLM),开发者可以轻松优化从DeepSeek-R1到Llama系列的各种大模型,满足从极致用户体验到最大效率的多样化需求。
英伟达技术博客指出,随着Blackwell Ultra GPU的进一步迭代,推理性能还将持续提升。未来,无论是个人开发者还是企业用户,都能借助这一平台推动AI应用的边界。
▶︎结语
英伟达在GTC 2025上用Blackwell DGX系统创下的DeepSeek-R1推理性能世界纪录,不仅是技术的胜利,更是对AI未来的大胆宣言。每秒3万token的吞吐量、36倍的性能飞跃,以及近乎无损的FP4精度优化,无不彰显英伟达在AI硬件领域的霸主地位。无论你是AI研究者还是行业从业者,这台“推理之王”都值得你关注。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















