NVIDIA在CES 2025上正式發佈了採用全新Blackwell架構的RTX 50系列GPU,而其中的旗艦RTX 5090 D終於在1月24日迎來了性能解禁。作爲NVIDIA的重要合作廠商,技嘉也在第一時間推出了配備RTX 5090 D GPU的AORUS GeForce RTX 5090 D MASTER ICE超級雕(以下簡稱RTX 5090 D超級雕(白)),爲發燒級玩家帶來了新一代純白旗艦顯卡之選。

Blackwell架構解析:爲AI渲染而生

RTX 5090 D採用全新的Blackwell架構,新架構設計的目標主要有四點:一、爲新的神經網絡渲染進行優化;二、減少顯存佔用;三、爲服務功能提供新的質量;四、高能效。可以說,RTX Blackwell架構的誕生,代表GPU的發展開始擺脫摩爾定律的限制,同時也宣告光柵化渲染時代正式進化到AI渲染時代。

NVIDIA GeForce Blackwell神經網絡渲染架構擁有第五代Tensor Core和第四代RT Core,RTX算力高達360 TFLOPS,爲全新的Mega Geometry提供強大的性能支持;搭載AI管理處理器,在AI計算與圖形渲染之間智能分配算力,實現最佳平衡;全新設計的Blackwell SM單元,爲新的神經網絡着色器提供高達125 TFLOPS的強大算力;首次搭載GDDR7顯存,提供高達30Gbps傳輸速率。
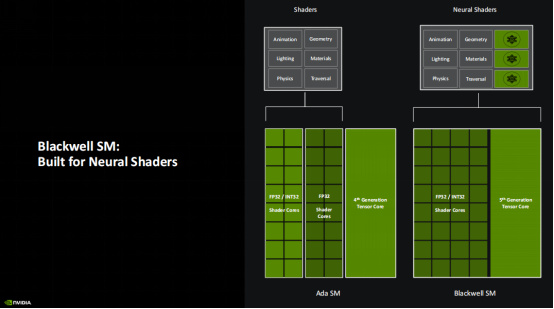
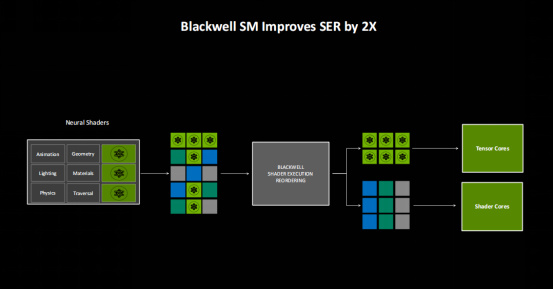
Blackwell的SM單元經過了全新的設計,整個架構完全爲新的神經網絡渲染而打造。從圖中可以看到,和上代針對常規渲染設計的Ada SM相比,Blackwell SM將支持INT32的着色器單元數量增加了一倍(INT32/FP32着色器單元總數不變), 同時將着色器執行排序的效率提升到上代的兩倍(對常規渲染和神經網絡渲染的代碼進行排序)。
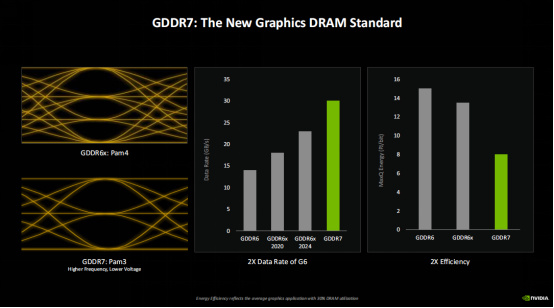
Blackwell是第一款搭載GDDR7顯存的GPU,相對GDDR6顯存來講,GDDR7提供了兩倍的數據傳輸速率,同時由於GDDR7使用了PAM3的模式,擁有比GDDR6X PAM4模式更低的工作電壓,所以不但速率更高,功耗也更低,相對GDDR6更是提升了一倍的能效。
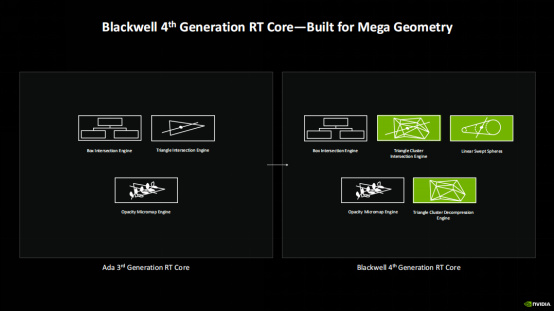
Blackwell架構的一項重大技術升級就是支持Mega Geometry,可將場景中的光線追蹤三角形數量至多增加 100 倍,從而可以在遊戲或者3D應用中提供超高的幾何細節,打造極爲逼真的模型。而實現Mega Geometry的硬件基礎當然就是Blackwell搭載的第四代RT Core,它相對上代Ada架構的第三代RT Core增加了三角形集羣交匯引擎、三角形集羣解壓縮引擎與線性圖形掃描單元(專用於加速毛髮渲染)
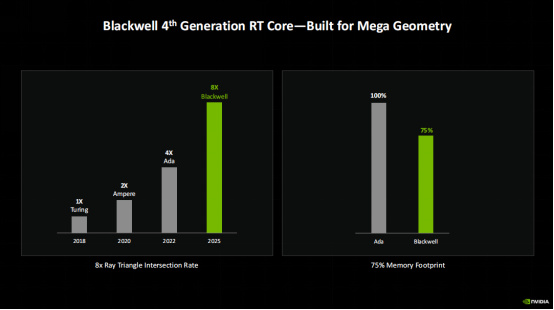
從圖中可以看到,Blackwell的第四代RT Core相比第一代RT Core提升了7倍的光線三角形交匯率,相對上代RT Core也有一倍的提升。同時,和上代Ada架構相比,Blackwell架構由於支持幾何壓縮,顯存佔用率也下降了25%之多。
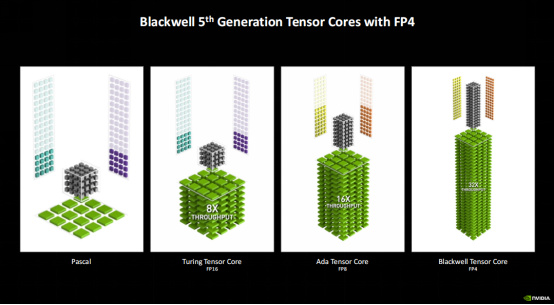
Blackwell另一大亮點就是其搭載的第五代Tensor Core支持FP4精度的計算,如果和Pascal架構相比,它的算力提升了31倍,相對上代Ada的Tensor Core(FP8),也提升了一倍。爲什麼要選擇FP4模式?按照NVIDIA官方說法,FP4模式在可以滿足渲染精度的同時下能夠提供更快的渲染速度,綜合來看是當下最符合需求的平衡點。
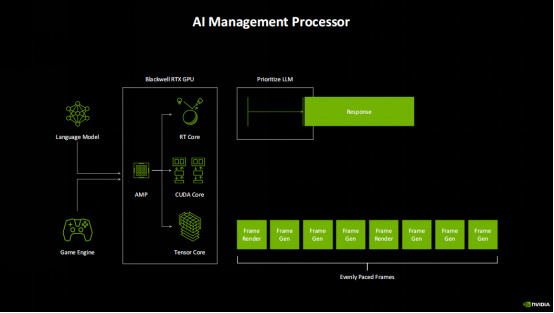
同時,Blackwell架構還引入了全新的AMP(AI Management Processor),這是一個完全可編程的硬件處理器,它可以精確控制和平衡幀生成與AI計算的所有需求。因此,在混合了LLM大語言模型、DLSS、幀生成等功能的遊戲中,AMP優先保證基於LLM的數字人AI隊友能夠第一時間響應你的命令,同時也能確保幀渲染與刷新率接近或同步,不出現卡頓的情況。
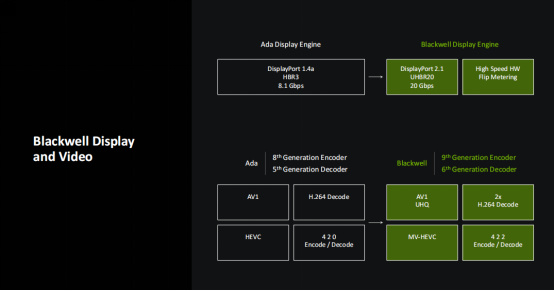
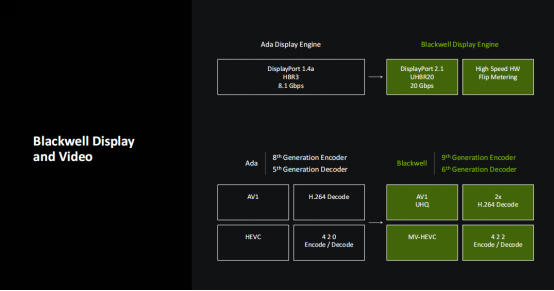
顯示與視頻部分,Blackwell也帶來了一系列的升級,輸出部分,它支持DP2.1接口,支持UHB R20,擁有20Gbps的帶寬。而在視頻編解碼部分,它的編碼器從Ada的第八代升級到了第九代,解碼器也從Ada的第五代升級到了第六代。因此,Blackwell現在支持AV1 UHQ、雙倍的H.264解碼,MV-HEVC,同時也支持4:2:2格式的硬件編解碼了,對於視頻剪輯師用戶來講非常實用。
綜合來看,Blackwell架構整體設計思路爲AI渲染打造強大的硬件基礎,無論是新一代RT Core與Tensor Core,還是全新打造的SM單元和首次引入的AMP,都是爲AI渲染而生。而正是因爲這些變革,才爲DLSS 4、神經渲染、Mega Geometry等等新特性提供了硬件基礎,從而打破了摩爾定律的桎梏,讓GPU的進化走入了一個新的時代、徹底擁抱AI的時代。
RTX神經渲染+DLSS 4黑科技打破傳統硬件限制
市場和用戶對於GPU性能的需求是無止盡的,而製造工藝的發展速度很顯然已經從硬件上對GPU的發展形成了瓶頸,單純增加GPU的規模顯得事倍功半。因此,NVIDIA的解決思路就是打破摩爾定律,讓GPU的架構從傳統渲染時代進化到AI渲染時代,通過AI來讓GPU性能突破硬件限制,達到新的高度。因此,RTX神經渲染以及新一代的DLSS 4成爲了RTX 50系性能猛增的核心技術。
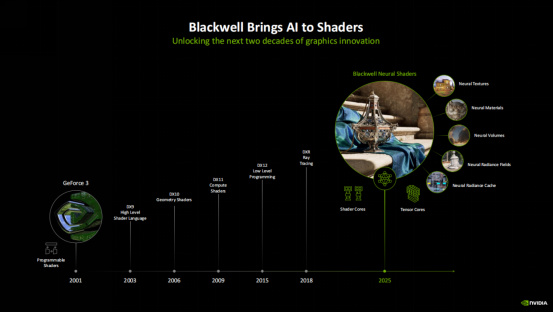
自2001年GeForce 3首次引入可編程着色器,NVIDIA始終在引領GPU技術的發展,到現在Blackwell架構則首次將小型神經網絡渲染引入傳統的可編程着色器,從而打造出神經網絡着色器的概念。神經網絡着色器可以實現很多功能,包括神經網絡材質、神經網絡紋理、神經網絡輻射緩存、神經網絡輻射場等等。
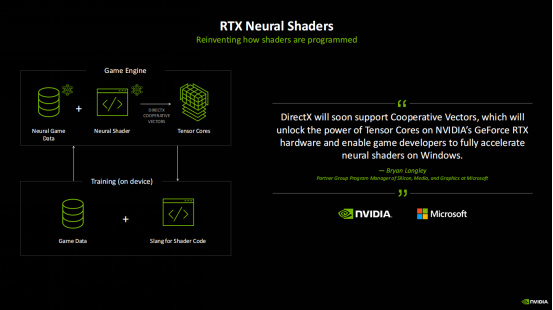
NVIDIA和微軟合作創造了一個叫做Cooperative Vectors的新API,這個API就可以讓遊戲開發者在遊戲引擎中使用到神經網絡着色器的技術。
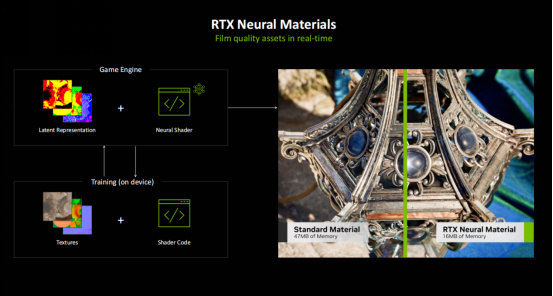
RTX神經網絡紋理壓縮在使用AI的情況下不到一分鐘的時間內就可以壓縮數千個紋理,同時它還可以節約非常多的顯存,在視覺效果相同的情況下,大約只需要傳統紋理壓縮方式1/7的顯存。同時,RTX神經網絡材質部分,也使用AI來壓縮複雜的着色器代碼,而這些代碼通常都採用了離線的模式,並可以完成多層材質的處理,處理速度更是提升了五倍,能在實現電影級畫質的同時提供遊戲需要的流暢幀率。
從圖中可以看到,使用神經網絡材質佔用16MB顯存,而使用傳統材質要佔用47MB的顯存,同時視覺效果的逼真程度要高出很多,特別是寶石的光澤、絲綢每一根絲線的光澤變化,已經遠超普通渲染的水平。特別值得一提的是,在神經網絡渲染模式下,物體表面的材質其實每次都會有細微的差別,因爲它真的是由AI實時計算生成的——就像Stable Diffusion文生圖那樣。

RTX神經網絡輻射緩存方面,用於路徑追蹤間接光照和性能的神經網絡着色器支持實時自我訓練網絡,通過每像素一次彈射可推算出更多的彈射,大幅節約資源,提升效率。
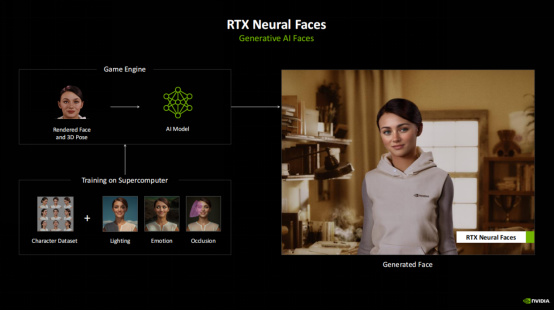
通過RTX Neural Faces,可以實時生成更加生動的AI面容。整個流程是先通過遊戲引擎的光柵化引擎渲染出臉部和3D姿勢,再通過AI模型來推理,然後對訓練之後的臉部模型通過Tensor RT來做優化,最終輸出更加接近真實的角色臉部。
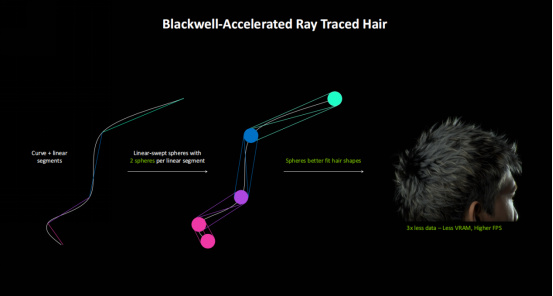
我們知道,在遊戲中用傳統的方式來精準渲染髮束會用到非常多的三角形,一個角色的頭髮甚至要用到六百萬個三角形。而Blackwell通過線性掃描球體這個新加入的渲染單元,則可以大幅降低髮束對三角形數量的需求,相對傳統渲染方式來講,僅需1/3的數據開銷,因此可以提供更高的幀率。

3D遊戲中使用的幾何體數量在不斷攀升,上世紀90年代遊戲中的幾何體數量在1K到10K,而到了2020年之後,遊戲中的幾何體數量已經增長到一千萬到五千萬。更多的幾何體也就意味着遊戲中的建模更加精細、更加真實,因此從提升視覺效果來講肯定是多多益善。但是,更多的幾何體也就意味着對GPU性能要求更高,因此,Blackwell引入了Mega Geometry,在官方的Zorah演示DEMO中,支持三角形的數量甚至達到了五億之多。
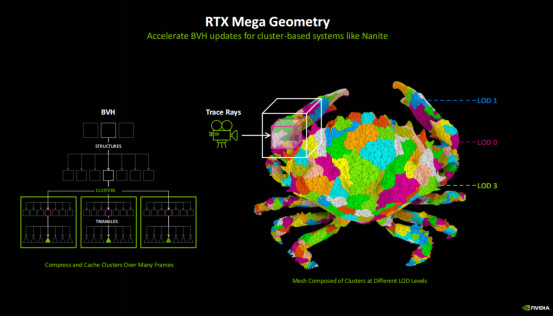
傳統的幾何體系統中每一個場景LOD的BVH(包裹體變異)都需要去更新,因此資源開銷會非常大,而適用於數百萬三角形的集羣系統(Cluster)引入,讓構建這個系統的成本大幅降低。Mega Geometry則可以在多幀上來壓縮和緩存這些集羣,從而加快場景更新LOD的BVH的速度,提供對數百萬幾何體數量高精度模型實現路徑追蹤的能力。
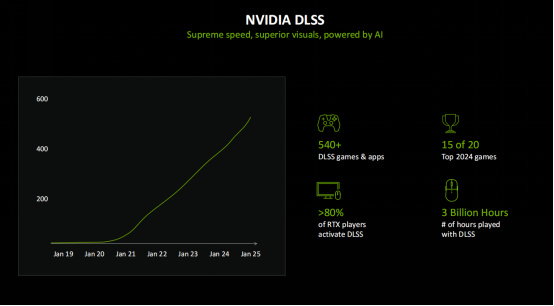
接下來要談的AI渲染技術就是大家最關心的DLSS了。DLSS已經誕生6年,並在通過訓練不斷迭代和進化。到目前爲止,支持DLSS的遊戲和應用數量已經高達540+,其中2024年前20的遊戲大作中就有15個支持DLSS。目前已經有超過80%的RTX玩家會在遊戲中開啓DLSS,而DLSS遊戲的總遊玩時間已經超過三十億小時。實際上,如果要在4K極限畫質下實現250+fps和35ms幀延遲的遊戲體驗,可能需要10塊傳統GPU,但換成支持AI的GPU,其實只需要一塊就夠了,這就是Blackwell誕生的目的之一。
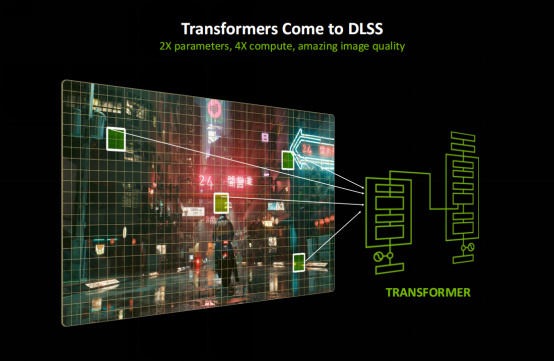
而RTX 50系核心靈魂所在的新一代的DLSS 4則使用了新的Transformer模型,相對之前的CNN卷積神經網絡模型來講,提供了兩倍的參數、四倍的計算以及更加出色的畫質。

從官方提供的對比視頻來看,使用Transformer模型的光線重建畫面質量明顯優於使用CNN模型,大家可以注意《心靈殺手2》場景中鐵絲網的細節,Transformer模型這邊明顯紋理更清晰,完全看不到邊緣閃爍的鋸齒。

用Transformer模型來做超分辨率效果也會好很多,它可以提供更清晰的紋理細節、更少的鬼影,目前已經有Beta版可供大家體驗。
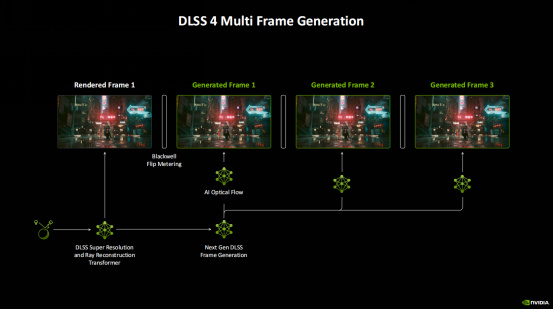
不過,這次DLSS 4最令人興奮的大招當然是全新的多幀生成技術。我們知道,之前DLSS 3的幀生成技術是AI模型使用遊戲本身的數據(運動矢量和深度),通過光流場加速器來生成新的幀,但每幀只能生成一幀,畢竟通過這種方式要生成多幀會導致極高的資源開銷。而Blackwell架構則針對DLSS 4的多幀生成設計,包括增強的Tensor Core、增強的Flip Metering和AMP。在此基礎上,DLSS 4的多幀生成採用的模型速度提升了40%,使用的顯存減少了30%,而且只需要渲染一次就可以生成全部的三幀,生成的幀會均勻排列,從而提供流暢的體驗。

從圖中可以看到,DLSS 4和多幀生成技術加持的情況下實際渲染的16個像素中,就有15個是AI生成的。綜合計算下來,可以讓幀率最高提升八倍。

官方展示視頻中《賽博朋克2077》在開啓DLSS 4和多幀生成(使用Transformer模型)之後,幀率從27fps暴增至248fps。而且,DLSS 4不但幀率提升,畫面精度也大幅升級,大家可以看到外賣盒上的紋理細節,DLSS 4明顯更加豐富。
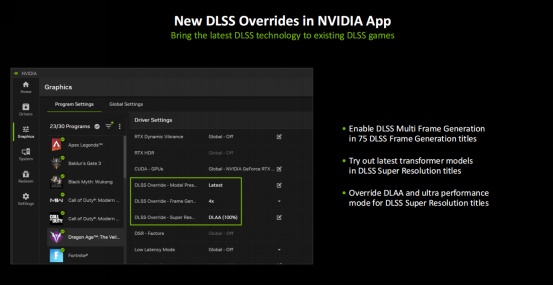
首發支持DLSS 4的遊戲與應用有75款,那麼對於暫時不支持DLSS 4的遊戲來講,大家也可以在NVIDIA app中使用DLSS Override功能來提前享受DLSS 4。例如《漫威爭鋒》就可以通過DLSS Override來提前享受多幀生成帶來的巨幅幀率提升。
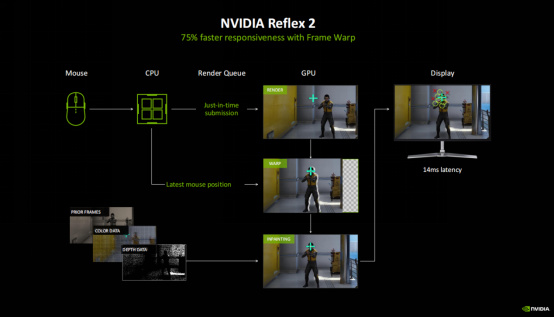
可能玩家會擔心多幀生成會帶來更多的延遲,不過NVIDIA的Reflex2顯然會讓大家打消這個顧慮。NVIDIA在Reflex 2中部署了一個以前應用在VR中的技術(Frame Warp),在每一幀渲染結束之後,Reflex 2都會移動畫面對齊最新的鼠標位置。不過,Frame Warp會在畫面中產生空白的區域,爲此NVIDIA開發了一項Inpaint預測修補技術,這個技術使用前一幀的顏色與深度數據對空白區域進行修復,從而創造出與原生渲染幾乎沒差別的畫面。
綜合來看,通過AI技術加持的神經網絡渲染,Blackwell實現了空前的性能提升和更加真實的電影級畫質,而這些如果要依靠傳統光柵渲染來實現的話幾乎是不可能完成的任務。由此可見,AI渲染時代已經正式來臨,而Blackwell的出現,將徹底改變遊戲開發的流程和遊戲玩家的體驗。
RTX 5090 D更強算力、更高顯存帶寬皆爲AI渲染而生

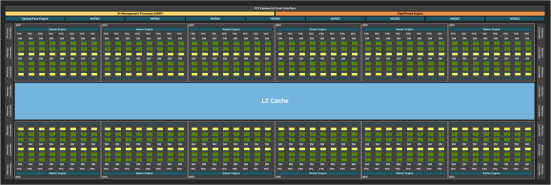
▲RTX 5090 D在完整的GB202芯片(上圖)基礎上精簡了22個SM單元,因此RT Core和Tensor Core的數量分別爲170個和680個
採用Blackwell架構的RTX 5090 D GPU在首發登場的RTX 50系家族中處於頂級旗艦的位置,它使用的GB202芯片芯片面積高達744mm²,相對上代RTX 4090 D的AD202芯片提升了大約22%之多,CUDA單元數量也提升了49%,升級幅度確實相當搶眼。
此外,得益於新的架構設計,RTX 5090 D內置的第四代RT Core和第五代Tensor Core相對上代RTX 4090 D的性能也得到了巨幅升級,提升幅度分別達到了87%和102%,畢竟新架構全面擁抱AI渲染,確實需要更強大的Tensor Core來支持。
紋理單元和光柵單元方面,RTX 5090 D則相對RTX 4090 D分別提升了49%和9%。顯存部分,RTX 5090 D率先使用了GDDR7,位寬高達512bit,傳輸速率達到28Gbps,因此顯存帶寬相對RTX 4090 D的提升幅度達到了78%,這對於高帶寬高容量需求的高分辨率光追遊戲、AIGC應用來講無疑是個針對性很強的升級點。
編解碼器部分,RTX 5090 D也進行了大升級,擁有3個第九代編碼器和2個第六代解碼器,相對RTX 4090 D的2個第八代編碼器和1個第五代解碼器提升幅度也算是很大了。而且RTX 5090 D增加了H.265/10bit/4:2:2格式的視頻編解碼,對於視頻剪輯師用戶來說非常實用。
功率部分,RTX 5090 D官方參考整板功率爲575W,採用16Pin輔助供電,而各大顯卡廠商生產的OC版基本都會使用600W的功率上限,所以在頻率和性能方面的規格會更高。由此也可以理解爲什麼RTX 50系會徹底擁抱AI渲染,NVIDIA再次爲業界指明瞭GPU的設計方向,不過NVIDIA在AI方面已經領先太多,優勢已經無可匹敵。
接下來就讓我們一起近距離欣賞來自技嘉的RTX 5090 D超級雕(白)顯卡實物。
AORUS GeForce RTX 5090 D MASTER ICE超級雕圖賞

RTX 5090 D超級雕(白)採用了全白配色,正面採用分層紋理設計,將力量與優雅完美融合。同時,顯卡巨大的體型給人非常霸氣的感覺,對於希望打造純白旗艦遊戲主機的玩家來說極具吸引力。

顯卡採用了風之力散熱系統,配備3個支持正反逆轉的仿生風扇,同時還支持在背板上安裝一個風扇,組成進氣格柵PLUS,不但增強了顯卡的散熱效果,對整套系統的散熱環境也能起到改善的作用。

除了強大的風之力散熱系統,顯卡還使用了複合金屬硅脂,同時具備液態金屬和硅脂的特性,提供更好的安全性和導熱效果。此外,顯卡還配備了新一代導熱墊,確保VRAM和MOSFET的散熱效果。

DIY設計方面,顯卡提供了雙BIOS快速切換開關,可以在性能模式和靜音模式之間快速切換,滿足玩家不同使用環境的需求。顯卡配備16pin輔助供電接口,並擁有電源指示燈,可以根據燈光判斷供電狀態。其中燈光熄滅代表電源連接正常;亮起代表電源線未連接;閃爍代表電源異常。此外,輔助電源接口位置下凹,遠離顯卡邊緣,有效提升了與16Pin供電接頭的兼容性和安全性,同時也減少了電源線彎折發生故障的概率。

爲了保證顯卡的使用安全,它還附帶了一個顯卡支架,可以自由調節高度,確保超重的顯卡在立式機箱中不會傾斜,提供更可靠而穩定的使用體驗。

個性化部分,顯卡除了支持RGB FUSION燈效同步之外,還在頂部配備了一個LCD顯示屏,可以顯示自定義視頻、圖片和動圖,打造酷炫的個性MOD。

用料部分,顯卡使用了長壽命固態電容、合金電感、2盎司銅PCB與低電阻晶體管,並且採用自動化生產流程,PCB還具備3防塗層,可以防塵、防潮和防腐蝕,大幅提升了顯卡的耐用度和壽命。
硬件配置方面,除了RTX 5090 D GPU之外,顯卡還配備了32GB GDDR7海量顯存,爲玩家提供高分辨率下的極致幀率,同時也爲AIGC用戶提供了當下頂級的顯存規格,高分辨率出圖更加高效。此外,RTX 5090 D超級雕(白)的GPU加速頻率高達2655 MHz,遠高於NVIDIA官方參考頻率2410 MHz,其功率上限也達到了600W,高於參考標準的575W,因此在性能方面會有更高的表現。

接口部分,顯卡提供了一個HDMI 2.1b和三個DP 2.1b接口,足以滿足發燒玩家多屏輸出的需求。
總的來說,RTX 5090 D超級雕(白)作爲RTX 5090 D中的旗艦級代表,擁有頂級的用料和散熱設計,完全可以給發燒級玩家帶來頂級的遊戲體驗。
實戰測試:遊戲/生產力無可匹敵,新王者制霸全場
測試平臺
顯卡:AORUS GeForce RTX 5090 D MASTER ICE超級雕
處理器:銳龍7 9800X3D
內存:佰維DDR5 6000(C28) 16GB×2
主板:X870E AORUS MASTER
硬盤:WD_BLACK SN850X 2TB
電源:技嘉UD1300GM
操作系統:Windows 11專業版24H2
測試平臺部分,我們選擇了銳龍7 9800X3D與RTX 5090 D超級雕(白)搭配,將處理器部分的瓶頸效應控制在最小,同時還使用上代的RTX 4090 D與之進行對比。爲了保證整板功率600W的RTX 5090 D超級雕(白)能夠滿載穩定運行,我們還使用了1300W的電源。此外,考慮到RTX 5090 D的旗艦級定位和性能水平,確保它在遊戲中能100%發揮性能,我們本次遊戲實測都使用4K分辨率。
基準性能測試
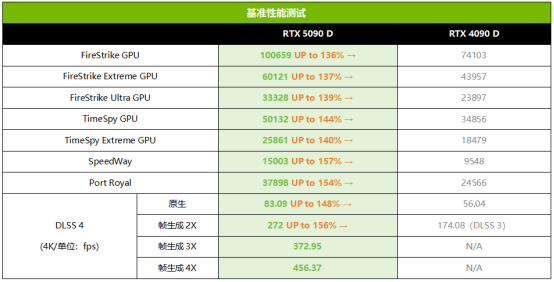
先來看看基準性能方面的表現。從3DMark的測試分數可以看到,在常規的DX11和DX12光柵化渲染測試項目中,RTX 5090 D相對RTX 4090 D的優勢都超過了35%,在DX12項目中的優勢更高,最高甚至可達44%。在DX12U和光追項目(SpeedWay和Port Royal)中,RTX 5090 D的優勢更大,最高甚至相對RTX 4090 D提升了57%。綜合傳統基準性能部分的成績來看,RTX 5090 D平均領先RTX 4090 D的幅度大約爲44%。
而在RTX 50系獨享的3DMark DLSS 4測試項目中,擁有最多4×多幀生成的RTX 5090 D領先只有2×幀生成(DLSS 3)的RTX 4090 D的幅度高達162%之多。同時,我們也可以看到,開啓4×幀生成之後,RTX 5090 D的幀率相對原生幀率也提升了449%,相對RTX 4090 D的原生幀率提升幅度更是高達714%,可見DLSS 4的多幀生成效果確實非常誇張。
常規遊戲性測試
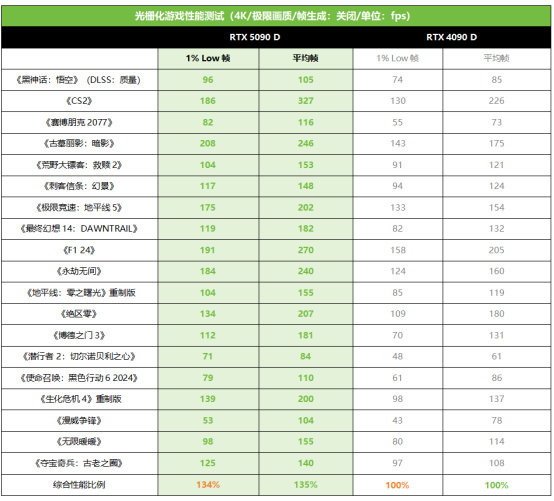
接下來看看4K極限畫質設定下光柵化遊戲性能的表現。從測試情況來看,RTX 5090 D相對RTX 4090 D的平均幀率提升幅度從24%到59%不等,平均提升幅度大約爲35%,其中《賽博朋克2077》《永劫無間》提升幅度都非常搶眼,分別達到了59%和50%之高。而在考查遊戲流暢度的1% Low幀方面,RTX 5090 D的表現也非常出色,在《博德之門3》中甚至領先了60%,綜合全部遊戲平均領先幅度是34%。
光追與DLSS遊戲測試
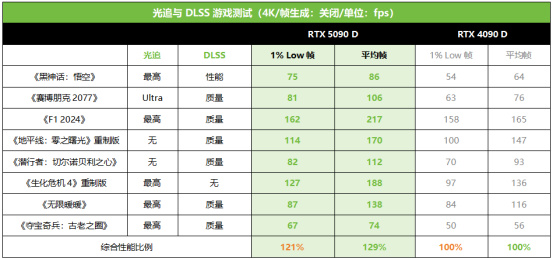
在打開光追和DLSS(CNN模型)的主流3A遊戲中,RTX 5090 D相對RTX 4090 D的平均幀優勢從16%~39%不等,平均領先幅度大約爲29%。而1% Low幀部分,RTX 5090 D相對RTX 4090 D的領先幅度最高也達到了39%,平均領先21%。所以無論是絕對幀率還是遊戲平滑度,RTX 5090 D都是大幅超越上代RTX 4090 D的存在。
生產力性能測試
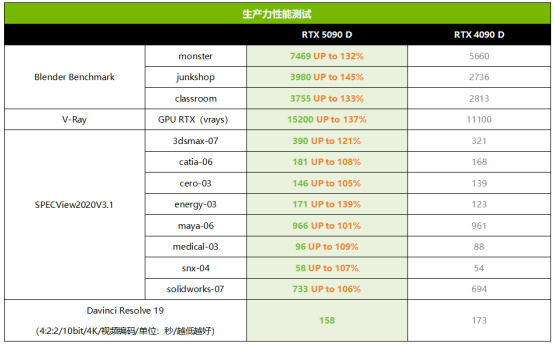
RTX 5090 D提供了更多的CUDA單元和更爲強大的32GB/512bit/GDDR7顯存,因此在各種3D設計工具軟件中也會提供更高的執行效率。從測試結果來看,RTX 5090 D在Blender中相對RTX 4090 D有32%~45%的提升;在V-Ray GPU RTX渲染中有37%的提升;在SPECView2020V3.1中的平均提升幅度則爲12%。由此可見,對於經常要用到3D設計工具的用戶來講,RTX 5090 D相對上代提升巨大,是更加高效的升級選擇。此外,RTX 5090 D新增了對4:2:2/10bit格式視頻編解碼的支持,我們使用Davinci Resolve 19 + Voukoder進行了編碼測試對比,確實有明顯的提升。
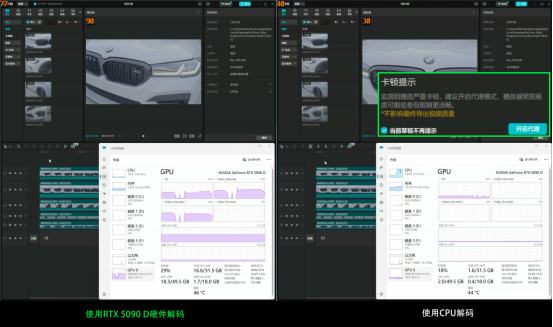
▲RTX 5090 D的兩個第六代解碼器在剪映中可以同時流暢解碼5條H.265/4:2:2/10bit視頻不掉幀,而CPU即便擁有16核32線程,在面對這樣的解碼需求時也會嚴重卡頓
RTX 5090 D在視頻解碼方面同樣十分強大,它配備的兩個第六代解碼器在剪映中可以同時流暢解碼5條H.265/4:2:2/10bit視頻不掉幀。但如果用CPU來解碼,就算是擁有16核32線程的銳龍9 9950X,來完成同樣的解碼工作也會出現嚴重卡頓,無法流暢預覽。可見對於視頻剪輯師來說,RTX 5090 D新一代的編解碼器確實會帶來更高的工作效率。
DLSS 4應用與遊戲測試
首發宣佈支持DLSS 4的遊戲與應用有75款,現在我們可以通過NVIDIA提供的測試代碼來激活一些遊戲的DLSS 4測試分支版本,更多的遊戲將會在晚些時候陸續上線對DLSS 4的支持。在原生支持DLSS 4的遊戲中,我們可以選擇多幀生成的倍率(4×、3×、2×),而在非原生支持DLSS 4的部分遊戲中,我們也可以通過NVIDIA APP來設置使用的模型(新的Transformer或者上代的CNN)與多幀生成倍率。

▲RTX 5090 D在《賽博朋克2077》中啓用DLSS 4 + 4×幀生成,4K極限光追畫質下也可以能達到300fps左右的幀率
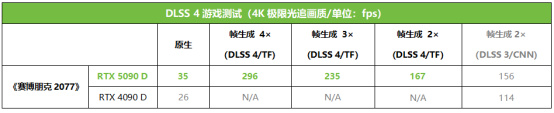
在《賽博朋克2077》的DLSS 4測試分支版本中,我們可以詳細比較RTX 5090 D使用Transformer模型的DLSS 4模式不同倍率幀生成設置下的幀率,也可以比較CNN和Transformer模型同在2×幀生成下的效率(使用CNN模型的DLSS 3只支持2×幀生成)。
從測試結果來看,在DLSS 4模式下,啓用4×、3×和2×幀生成,RTX 5090 D的幀率相對原生分別提升了746%、571%和、377%,提升幅度可以說是非常誇張了。同時,我們也可以看到,使用Transformer模型實現2×幀生成,相對DLSS 3的CNN模型也有7%的幀率提升,可見新模型的使用確實也進一步提升了DLSS 4的性能。
上代RTX 4090 D在《賽博朋克2077》中只能使用CNN模型加持的DLSS 3模式,因此只支持2×幀生成,而擁有4×幀生成的RTX 5090 D幀率足足是它的260%,相對它的原生幀率更是提升了驚人的1038%。
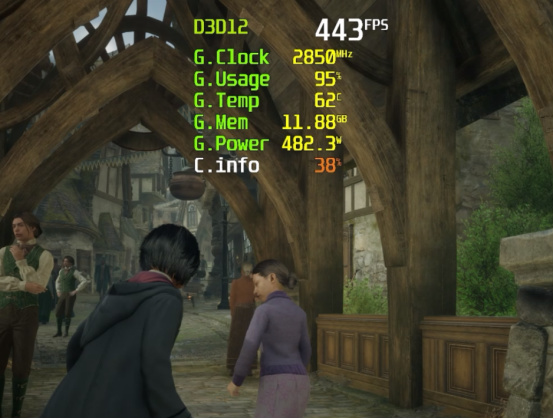
▲RTX 5090 D在《霍格沃茲之遺》中啓用DLSS 4 + 4×幀生成,4K極限光追畫質下實時幀率可以輕鬆達到300fps~400fps+
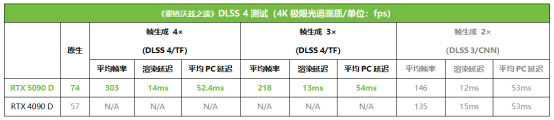
《霍格沃茲之遺》的DLSS 4測試分支版本中,4×幀生成和3×幀生成使用了新的Transformer模型,不過在2×幀生成模式下,它還是調用的CNN模型。從測試結果來看,RTX 5090 D使用DLSS 4和4×幀生成,相對原生的幀率提升了309%,3×則提升了195%,使用上代的DLSS 3 + 2×幀生成模式,也提升了97%之多。如果和RTX 4090 D的DLSS 3 + 2×幀生成相比,最高提升幅度達到了108%,和RTX 4090 D原生幀率比,則提升幅度最高達到432%。大家可能擔心開啓4×幀生成會帶來更高的延遲,但從我們的測試來看,使用4×幀生成的渲染延遲與平均PC延遲與2×幀生成相比並沒有明顯變化,可見完全不用擔心這個問題。

▲RTX 5090 D在《霍格沃茲之遺》中啓用Override模式的DLSS 4 + 4×幀生成,4K極限畫質下實時幀率高達400fps+

《漫威爭鋒》暫時沒有原生支持DLSS 4,不過可以在NVIDIA APP中使用Override模式來開啓DLSS 4和多幀生成。可以看到,在 4×/3×幀生成模式下,RTX 5090 D的幀率相對於原生分別提升了289%和217%,而同樣使用2×幀生成模式,使用Transformer模型相對CNN模型也提升了6%。而RTX 5090 D採用4×幀生成的幀率相對採用DLSS 3 + 2×幀生成的RTX 4090 D則提升了137%,和原生比更是提升了419%。延遲部分,可以看到RTX 5090 D在幾種幀生成比例下的渲染延遲與PC延遲差別都很小,所以對於玩家來講直接啓用DLSS 4的4×幀生成無疑是獲得高幀率和流暢操作的最佳選擇。
▲RTX 5090 D在D5渲染器中使用Override模式開啓DLSS 4和4×幀生成,實時預覽幀率暴增

除了遊戲之外,DLSS 4在3D渲染類生產力軟件中也能大顯神通,目前D5渲染器也可以通過Override模式來支持DLSS 4和多幀生成,從而提供更流暢、更高效的使用體驗。從測試來看,開啓DLSS 4和4×幀生成,RTX 5090 D的幀率相比原生(關閉超分辨率、光線重建和幀生成)提升了291%,比僅有DLSS 3和2×幀生成的RTX 4090 D提升了207%,比它的原生幀率提升了561%。可以說這個提升幅度達到了驚人的水平,對於設計師用戶來說堪稱史詩級的體驗升級。
AI性能測試
▲RTX 5090 D在UL Procyon的AI出圖測試中使用FLUX.1模型/FP4精度設置,出圖速度相對FP8精度提升約70%
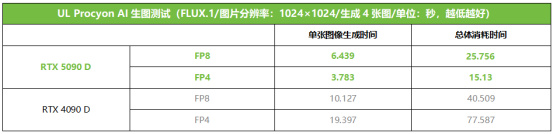
前面介紹過,Blackwell架構的一大革新就是內置的第五代Tensor Core支持FP4精度的計算,相對Ada架構的Tensor Core性能提升了一倍。我們這裏就使用UL Procyon的AI生圖測試來考查RTX 5090 D的在FP8和FP4精度下的AI性能。從測試來看,同樣使用FLUX.1模型生成1024×1024的圖片,RTX 5090 D在FP4下的出圖速度相當於FP8模式下的170%,而RTX 4090 D不支持FP4模式,所以從FP8模式切換到FP4模式出圖時間幾乎增加了一倍,所以RTX 5090 D在FP4模式下出圖速度大約比RTX 4090 D快了413%。由此可見,對於需要快速AI出圖、且對精度要求並不苛刻的用戶來講,支持FP4精度的RTX 5090 D無疑是效率遠超上代旗艦的神器。
功率與溫度表現

▲RTX 5090 D超級雕(白)滿載考機整板功率600W,GPU溫度不到72℃,風扇噪聲小,散熱效果出色

▲RTX 5090 D超級雕(白)在遊戲中的實時功率從400W~600W不等,視遊戲而定
我們使用FurMark對RTX 5090 D超級雕(白)進行滿載考機測試,可以看到這時候整板功率達到了600W上限,GPU功率則保持在230W水平。得益於強大的風之力三風扇散熱系統,RTX 5090 D超級雕(白)的GPU和顯存考機溫度都僅有72℃左右,風扇噪聲也控制得很好,對於旗艦級顯卡來講,這樣的使用體驗也是非常突出的,即便玩家長時間玩遊戲或進行AI計算,也不用擔心過熱影響穩定性和使用壽命。
總結:AI渲染時代的新王者,遊戲與工作雙料神器
最後來簡單總結一下。採用全新Blackwell架構的RTX 5090 D首先從硬件層面就完成了從傳統渲染時代到AI渲染時代的進化,突破了製造工藝、功率等硬件條件帶來的性能升級瓶頸,爲業界展示了GPU設計的新方向。可以毫不誇張地說,未來的GPU,完全擁抱AI是必然趨勢,而在這方面,NVIDIA是領軍者,擁有無可比擬的優勢。
在此基礎上,RTX 5090 D帶來了一系列基於AI技術的新功能,將遊戲流暢度和畫質水平都提升到了新的高度,爲玩家提供了更加極致的遊戲體驗。RTX 50系GPU還獨享採用Transformer新模型的DLSS 4以及多幀生成技術,開啓之後可以讓遊戲幀率暴增數倍,同時還擁有比上代CNN模型加持的DLSS 3更好的畫質,這一點可以說是發燒級遊戲玩家毫不猶豫升級的首要因素。
對於AI和生產力用戶來講,RTX 5090 D增加了對FP4精度的支持,能夠提供更快的AI計算速度(也爲AI渲染提供了強大的硬件基礎),同時它還擁有當前最高規格的32GB/512bit/GDDR7顯存配置,對於AIGC用戶來講無疑是當下最爲高效的工具。此外,它還內置了3×第九代編碼器和2×第六代解碼器,新增支持4:2:2/10bit編解碼,對於視頻剪輯用戶來說也堪稱神兵利器。當然,在3D設計工具中,RTX 5090 D也提供了遠超上代RTX 4090 D的性能。因此,綜合來看,對於追求極致效率的設計師用戶來講,RTX 5090 D也是目前的頂配選擇。
而技嘉RTX 5090 D超級雕(白)作爲RTX 5090 D中的豪華旗艦,不但擁有600W的性能釋放水平,還配備了強大的風之力散熱系統,同時在外觀顏值方面也達到了頂級旗艦水平,不愧爲發燒級玩家和高端設計師用戶首選的升級目標。

當然,對於追求性價比的玩家,也可以關注技嘉旗下的風魔系列RTX 5090 D顯卡,例如RTX 5090 D風魔,首發價格16499元,它搭配了新一代仿生風扇,有效降低了風阻和噪聲,還可將風壓提升53.6%、風量提升12.5%。同時它還升級了導熱凝膠,配備大型均熱板和複合式熱管、進氣格柵等散熱技術,性能輸出強勁、而且耐用又超值。
編輯:熊樂
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















