前言
如今,各类AI项目遍地开花,但无论是绘画模型还是大语言模型基本都离不开pytorch运算框架,而NVIDIA的CUDA封闭生态使得要通过GPU加速pytorch往往需要一张NVIDIA的显卡。但是众所周知,同性能的A卡价格远低于N卡,为了让A卡能加速pytorch,AMD推出了ROCm做为深度学习领域CUDA的替代品,pytorch官方也提供了ROCm的支持,但这一切都需要在Ubuntu物理机上完成,对于我们这类不想频繁重启电脑的游戏玩家很不方便。直到今年前不久,AMD推出了WSL的显卡驱动和ROCm支持,这使得A卡用户在不关闭Windows的情况下得以方便地运行各类AI程序。与此同时,Windows下HIP SDK也已经发布了一段时间,尽管pytorch尚未进行支持,一些别的从基础构建而非使用pytorch的AI项目依然能从中得到支持。除此之外,做为转译运行CUDA的工具,尽管Zluda的主要分支已被叫停并重新编写(目前来看较长时间内不会有对pytorch的支持),但依然还存在其他分支在不断更新以支持pytorch。
我将发布一系列的教程,针对A卡用户从基础环境搭建到本地配置包括图片生成模型(Stable Diffusion、FLUX.1)、大语言模型(可基于llama.cpp运行量化后的较大的模型,同时在显存充足的情况下可使用LLaMA Factory微调一些4B及以内的较小的模型)、语音转换模型(GPT-SoVITS、Fish-Speech)和目标检测模型(YOLO)在内的一系列模型,乃至基于此使用本地算力运行Open-LLM-VTuber,打造完全免费的属于自己的AI虚拟主播,而这将是这一系列教程的第一篇,做为基础环境的搭建部分。
本教程有较多需要复制的地址和指令,建议在电脑上的浏览器一边阅读一边操作,手机点击右上角的分享后复制链接发送到电脑即可。
获取链接
本篇教程主要分为两个部分,其一是基于WSL通过ROCm运行pytorch做为运行AI的平台,其二是基于HIP SDK和Zluda运行pytorch及其他程序做为运行AI的平台。我推荐显卡达到下面的要求的读者朋友进行阅读第一部分,而所有的读者(即使你显卡达标已经阅读了第一部分)都应阅读第二部分。
首先为避免浪费时间,如果你的显卡不在下面这个列表当中,说明AMD目前还没有为你的显卡做WSL的支持,无法在WSL中运行ROCm。但你依然能用你的显卡实现我上面说的那些操作,只不过部分应用相对于WSL上的ROCm会损失部分性能,请跳过本文的WSL部分,直接阅读本文的HIP SDK和Zluda部分。
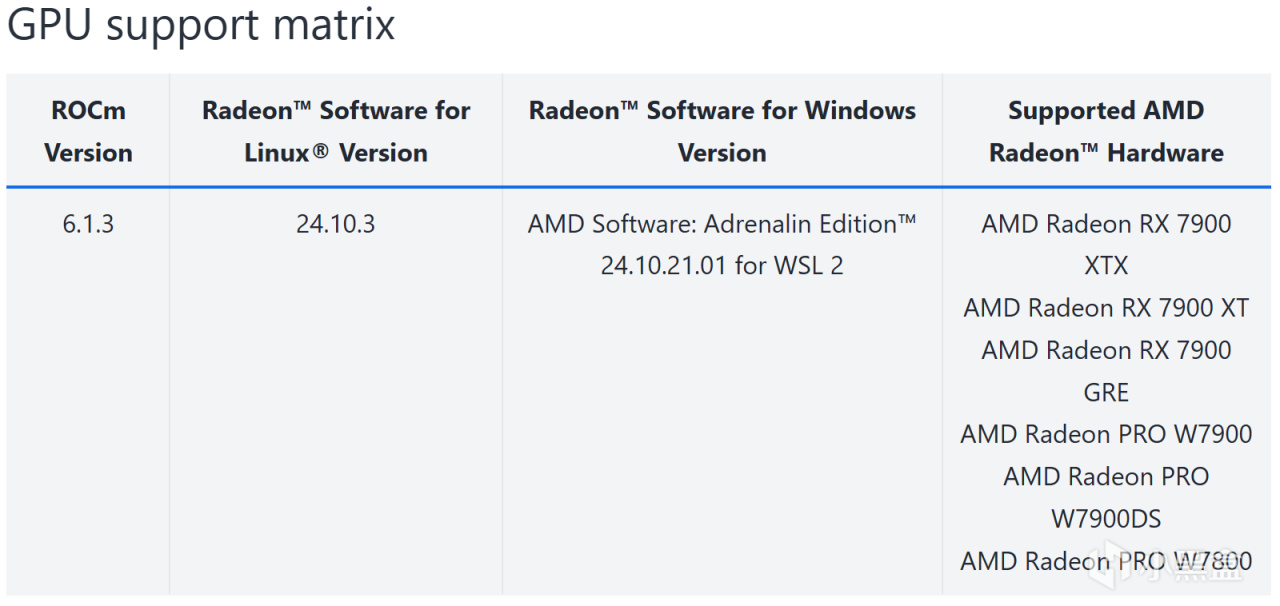
WSL的显卡支持矩阵
而如果你的显卡在上面的列表当中,比如和我一样7900XT,那么请继续阅读以下内容,请注意,对于显卡达标的读者而言,为了更快的运行速度,第一部分也是有必要阅读的,因为对于一些模型而言,ROCm和Zluda在相同设备下具有肉眼可见的效率差异(但仍处于同一数量级)。
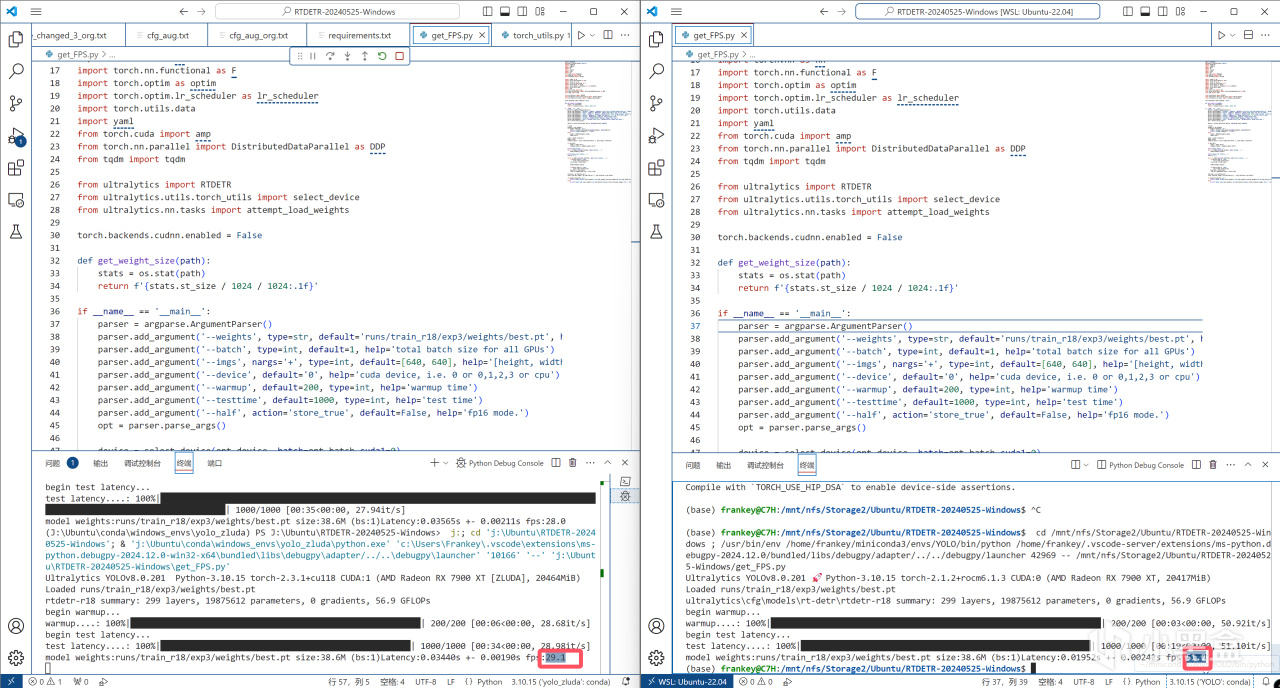
ROCm和Zluda的FPS差异
基于WSL通过ROCm运行pytorch
此部分内容的主要方面基于AMD的官方文档,若具有一定的英文能力和基础的朋友可自行阅读:
https://rocm.docs.amd.com/projects/radeon/en/latest/docs/install/wsl/install-radeon.html
https://rocm.docs.amd.com/projects/radeon/en/latest/docs/install/wsl/install-pytorch.html
首先搜索并打开“启用或关闭Windows功能”,勾选上“适用于Linux的Windows子系统”和"Hyper-V"
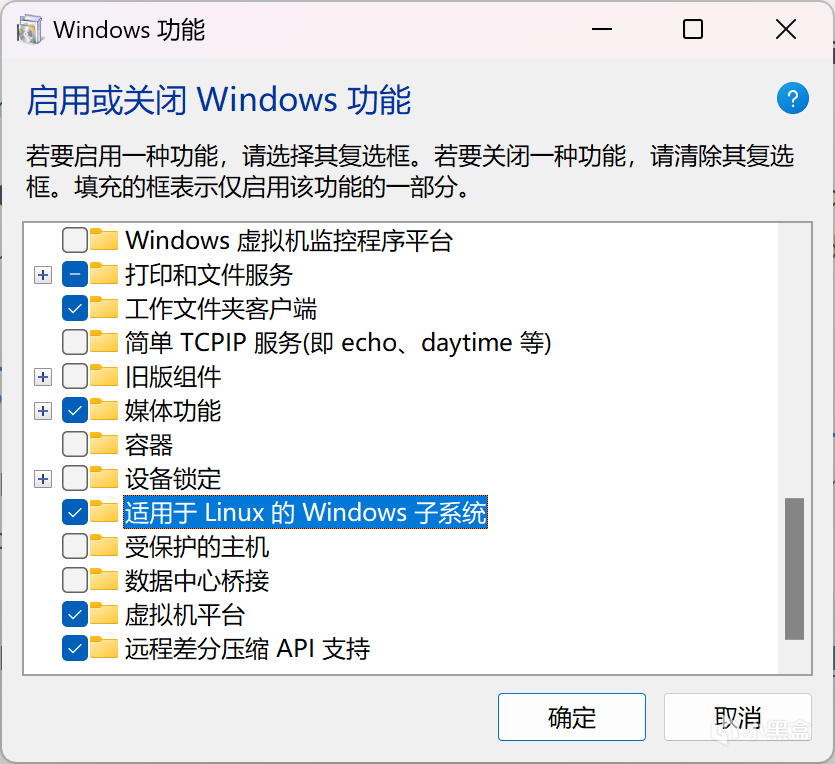
勾选“适用于Linux的Windows子系统”
勾选"Hyper-V"
需要注意的是,Hyper-V仅用于重新压缩虚拟硬盘文件的大小,可以不启用,但之后若在WSL中下载了大量文件再删除后,删除后空出的那部分空间依旧会占用虚拟硬盘文件的大小。
勾选完成后点击确定并重启电脑,之后进入微软商店安装Ubuntu 22.04,注意,一定要有22.04的版本号,不能是其他版本,也不能仅有一个"Ubuntu"但是没有版本号,目前只有22.04是受AMD支持的WSL版本,其他版本无法正常安装GPU驱动和ROCm。
安装Ubuntu 22.04
安装完成后,在PowerShell中输入指令:
wsl
进入子系统。
之后运行如下命令下载驱动安装脚本:
sudo apt update
wget https://repo.radeon.com/amdgpu-install/6.1.3/ubuntu/jammy/amdgpu-install_6.1.60103-1_all.deb
sudo apt install ./amdgpu-install_6.1.60103-1_all.deb
完成后运行如下命令正式安装驱动:
amdgpu-install -y --usecase=wsl,rocm --no-dkms
驱动安装需要一定时间,请耐心等待。
安装完毕后输入rocminfo,应打印出类似的信息:
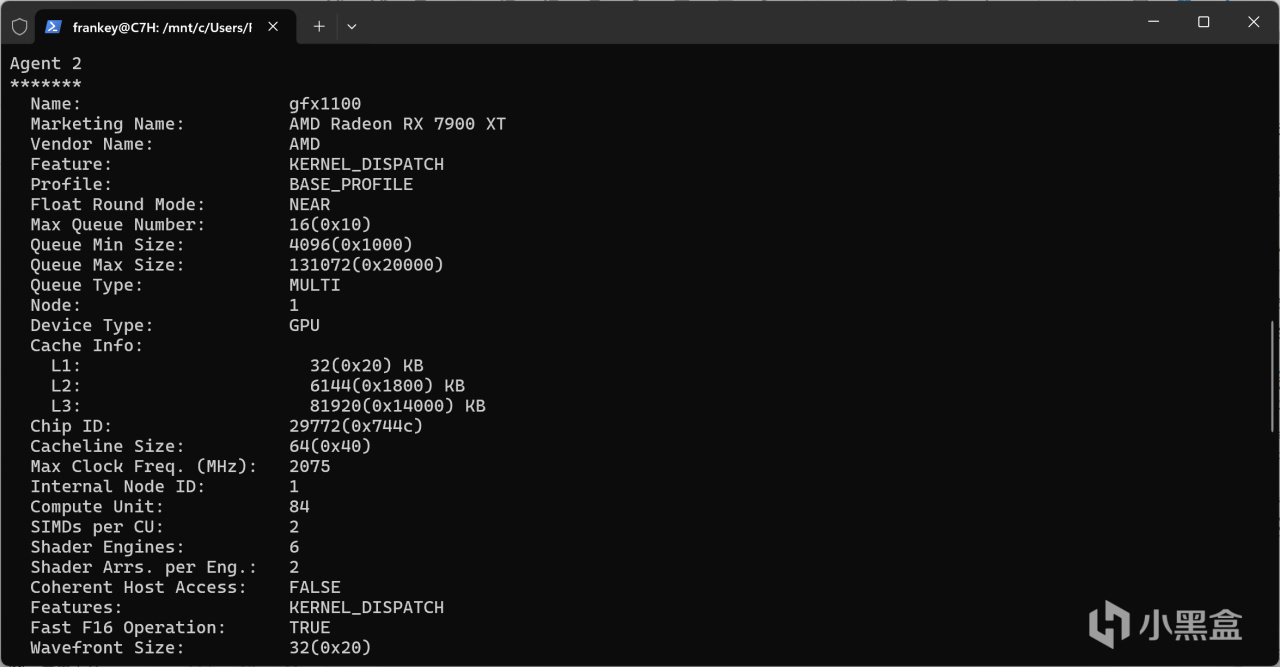
设备信息
此时驱动的安装已经完成,接下来需要安装pytorch。
这里有两种方法,一种是通过全局的python,一种是通过Anaconda的虚拟环境,我这里推荐Anaconda的方法,因为不同的程序会需要不同的环境,如果全部使用同一个环境的话会导致包的管理非常混乱。
首先是全局的python:
sudo apt install python3-pip -y
pip3 install --upgrade pip wheel
再者是Anaconda虚拟环境:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
使用上述指令下载并安装miniconda,为防止安装的最后询问是否自动激活环境时手滑输入了no(直接回车默认就是no,需要手动输入yes),之后手动激活conda环境:
sudo nano ~/.bashrc
在最后一行添加:
export PATH=$PATH:~/miniconda3
按Ctrl+X保存并退出,执行以下命令:
source ~/.bashrc
此时新开一个控制台进入WSL,那么用户名左边应该有一个(base)字样表示你正在conda的base环境中。

(base)
为保持base环境的干净,使用如下命令新建一个虚拟环境,注意,WSL的pytorch仅支持python 3.10版本,所以一定要使用3.10版本的python:
conda create -n torch_rocm python=3.10
等待创建完毕后激活环境:
conda activate torch_rocm
至此python的安装结束,接下来就是核心部分,即pytorch的安装,首先需要下载由AMD预编译的pytorch相关包:
wget https://repo.radeon.com/rocm/manylinux/rocm-rel-6.1.3/torch-2.1.2%2Brocm6.1.3-cp310-cp310-linux_x86_64.whl
wget https://repo.radeon.com/rocm/manylinux/rocm-rel-6.1.3/torchvision-0.16.1%2Brocm6.1.3-cp310-cp310-linux_x86_64.whl
wget https://repo.radeon.com/rocm/manylinux/rocm-rel-6.1.3/pytorch_triton_rocm-2.1.0%2Brocm6.1.3.4d510c3a44-cp310-cp310-linux_x86_64.whl
之后以防万一卸载现有的pytorch相关包:
pip3 uninstall torch torchvision pytorch-triton-rocm numpy
最后就是正式安装了:
pip3 install torch-2.1.2+rocm6.1.3-cp310-cp310-linux_x86_64.whl torchvision-0.16.1+rocm6.1.3-cp310-cp310-linux_x86_64.whl pytorch_triton_rocm-2.1.0+rocm6.1.3.4d510c3a44-cp310-cp310-linux_x86_64.whl
此时包的安装已经结束,但是整个过程还没完,因为这个时候如果你执行torch.cuda.is_available()会发现其返回的是False,也就是说此时pytorch依然只能使用CPU来计算,那么就需要下面的操作了:
location=`pip show torch | grep Location | awk -F ": " '{print $2}'`
cd ${location}/torch/lib/
rm libhsa-runtime64.so*
cp /opt/rocm/lib/libhsa-runtime64.so.1.2 libhsa-runtime64.so
那么到此为止,AMD的教程就结束了,但是如果此时你import torch,还会出现类似于下面的错误:
ImportError: /home/cedric/anaconda3/envs/decdiff_env/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.30' not found (required by /lib/x86_64-linux-gnu/libLLVM-15.so.1)
但是没关系,请继续如下操作:
location=`pip show torch | grep Location | awk -F ": " '{print $2}'`
cd ${location}/torch/lib/
mv libstdc++.so.6 libstdc++.so.6.old
ln -s /usr/lib/x86_64-linux-gnu/libstdc++.so.6 libstdc++.so.6
此时再进行测试,就不应出现任何问题了。
python
import torch
torch.cuda.is_available()
此时出现的就应该是True,说明pytorch可以使用你的GPU进行运算了。
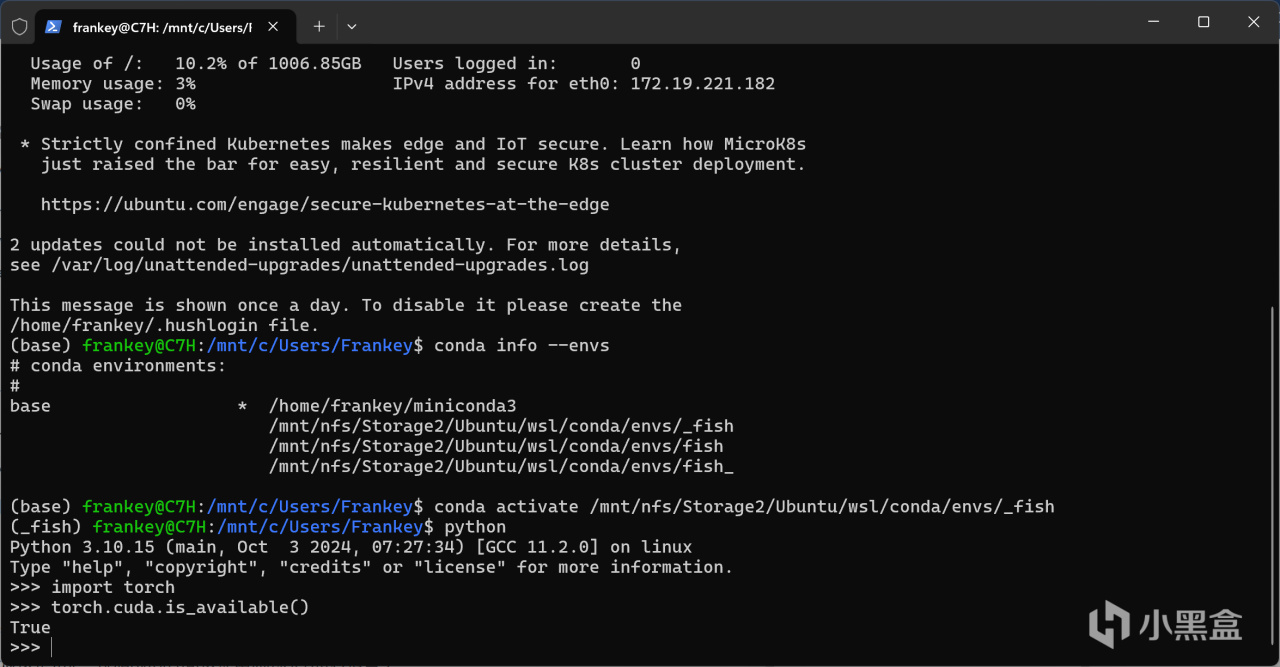
torch.cuda.is_available()
输入以下指令退出python(按Ctrl+C是没用的):
exit()
到此为止你已经成功得到了一个可以使用A卡的pytorch,本篇教程WSL的部分已经结束,但是我推荐你继续阅读并安装Zluda,因为AI绘画方面已经有秋叶大佬https://space.bilibili.com/12566101 的整合包。秉着不重复造轮子的原则,我不会重新去配置一个新的环境,而是仅对一些使用上的方法进行说明(主要是针对低显存的显卡如何通过量化来运行百亿级别参数的绘画大模型),而秋叶大佬的整合针对A卡使用的是Zluda(DirectML远比Zluda要慢)的方式来运行,所以接下来的内容对于运行AI绘画而言是有用的。
再次强调,目前仅RX 7900 (XTX/XT/GRE)和部分专业卡可在WSL上运行ROCm:
https://rocm.docs.amd.com/projects/radeon/en/latest/docs/compatibility/wsl/wsl_compatibility.html
WSL的显卡支持矩阵
不过根据ROCm开发者的回复,将来WSL下的ROCm将支持更多的显卡:
https://github.com/ROCm/ROCm/issues/3402#issuecomment-2218312649
目前经本人测试,WSL下RX 7900 XT可正常运行ROCm,而RX 6750 GRE 12G无法正常运行ROCm,而如果不想等待的话,一方面可直接在Ubuntu物理机上安装ROCm并通过"export HSA_OVERRIDE_GFX_VERSION=1030"运行(经本人测试即使在Ubuntu物理机下ROCm 6.0以上也并不支持6750GRE(gfx1031),请使用ROCm5.6版本):
https://www.reddit.com/r/LocalLLaMA/comments/18ourt4/my_setup_for_using_rocm_with_rx_6700xt_gpu_on/
另一方面则是下文要讲的内容,使用Zluda运行绝大多数基于pytorch的程序,同时自行编译llama.cpp来适配自己的显卡以运行量化后的大语言模型(这一部分直接基于HIP SDK,不通过Zluda)。并且,考虑到大伙有6750GRE的比较多,尽管官方没有相关版本,我本人也预编译了支持gfx1031(6750、6700等显卡)的llama.cpp程序,我会在之后llama.cpp的文章中放出,有6750GRE的朋友可以直接下载。
而做为基础环境的一部分,本文仅介绍到Zluda下pytorch的使用为止:
基于Windows通过HIP SDK和Zluda运行pytorch
首先AMD官网下载HIP SDK for Windows(再次说明llama.cpp直接依靠HIP SDK,即使你不打算安装Zluda你也应该安装HIP SDK,而Zluda同样依靠HIP SDK运行,所以这应该是必装的):
https://www.amd.com/en/developer/resources/rocm-hub/hip-sdk.html
关于版本,如果你要自己编译llama.cpp,我推荐同时下载5.7.1和6.1.2的版本,如果你只是单纯运行程序,那我推荐只下载5.7.1的版本(主要由于本人编译的llama.cpp在6.1.2版本下的HIP SDK下会报内存错误无法运行,具体原因未知)。
下载好后直接运行安装,默认装在C盘,也可以手动指定到其他盘,整个流程和安装显卡驱动一样简单。
需要注意的是,Pro版本的显卡驱动是并不需要安装的,用已有的游戏驱动也可正常运行一切功能。
安装完成后,搜索并打开"编辑系统环境变量",选择"环境变量"
打开系统属性
环境变量
如果你同时安装了6.1.2版本和5.7.1版本的HIP SDK,那么需要编辑HIP_PATH_57、HIP_PATH_61、HIP_PATH共3个变量,分别设置为你各个版本的HIP SDK的安装位置,就和我图中的一样。如果只安装了一个版本,那就少设置一个即可。
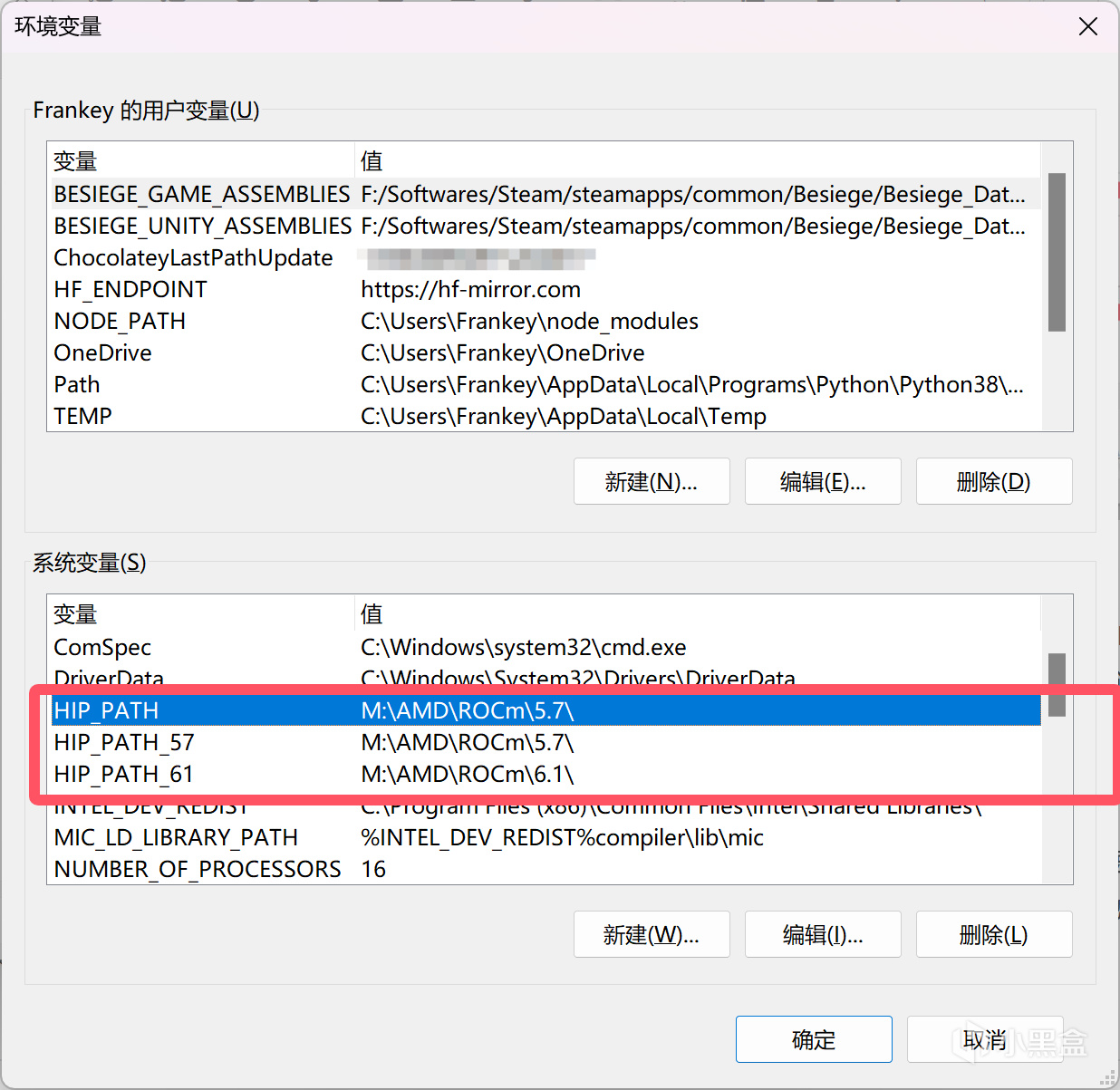
HIP_PATH
之后往下滑,找到"Path"变量,双击编辑,将"%HIP_PATH%\bin"添加进去,如图所示。
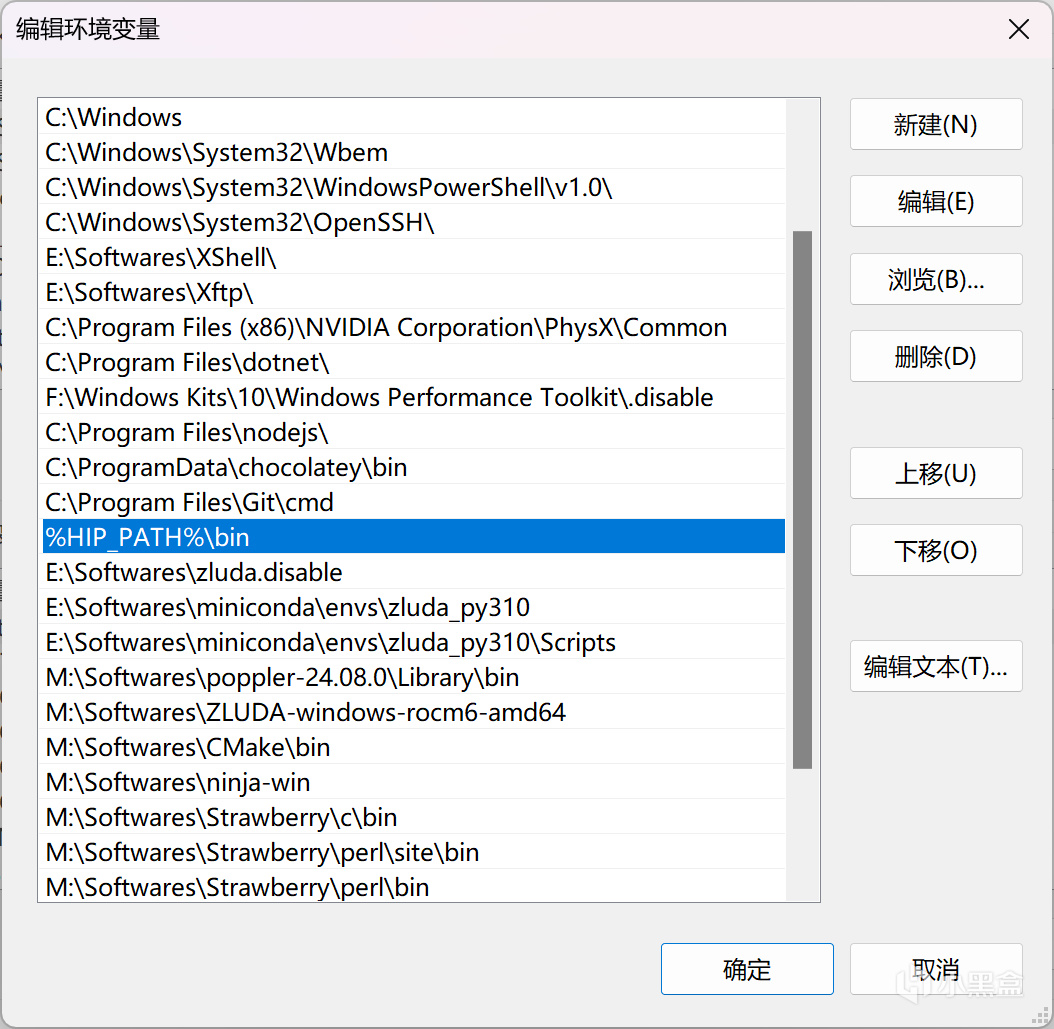
Path
如果你的显卡可以在WSL上使用ROCm,或者你只需要运行AI绘画和大语言模型,那么本篇教程到这里也就结束了,因为秋叶大佬的整合会为你自动完成后面的部分,而如果你的显卡不受WSL支持并且你还想运行其他程序(如语音克隆),请继续阅读下面的内容。
首先,HIP SDK的支持范围又要比WSL的ROCm要大一些,如果你的显卡在下图中的支持矩阵中有两个√,那么可跳过下面一步,直接转到Zluda的正式安装部分。
https://rocm.docs.amd.com/projects/install-on-windows/en/develop/reference/system-requirements.html
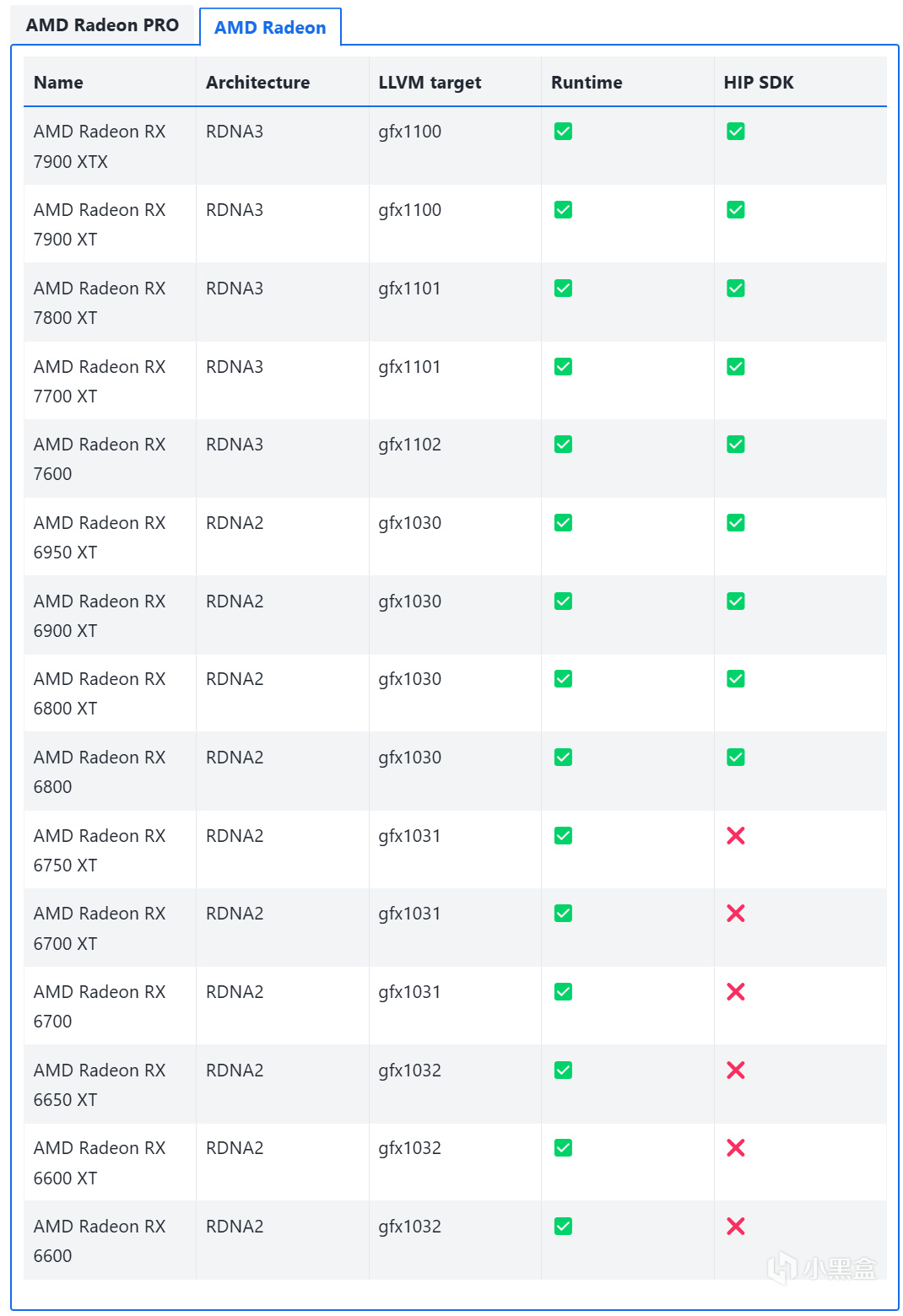
HIP SDK的GPU支持矩阵
请进入https://github.com/brknsoul/ROCmLibs 项目中
对于5.7.1版本的HIP SDK,如果你是gfx1031系列的显卡(包括6750GRE),请下载Optimised_ROCmLibs_gfx1031.7z,如果你是gfx1032系列的显卡(主要是6600系列),对于其他显卡,请下载ROCmLibs.7z。
对于6.1.2版本的HIP SDK,目前仅支持gfx1031系列的显卡,请下载rocm gfx1031 for hip sdk 6.1.2 optimized.7z。
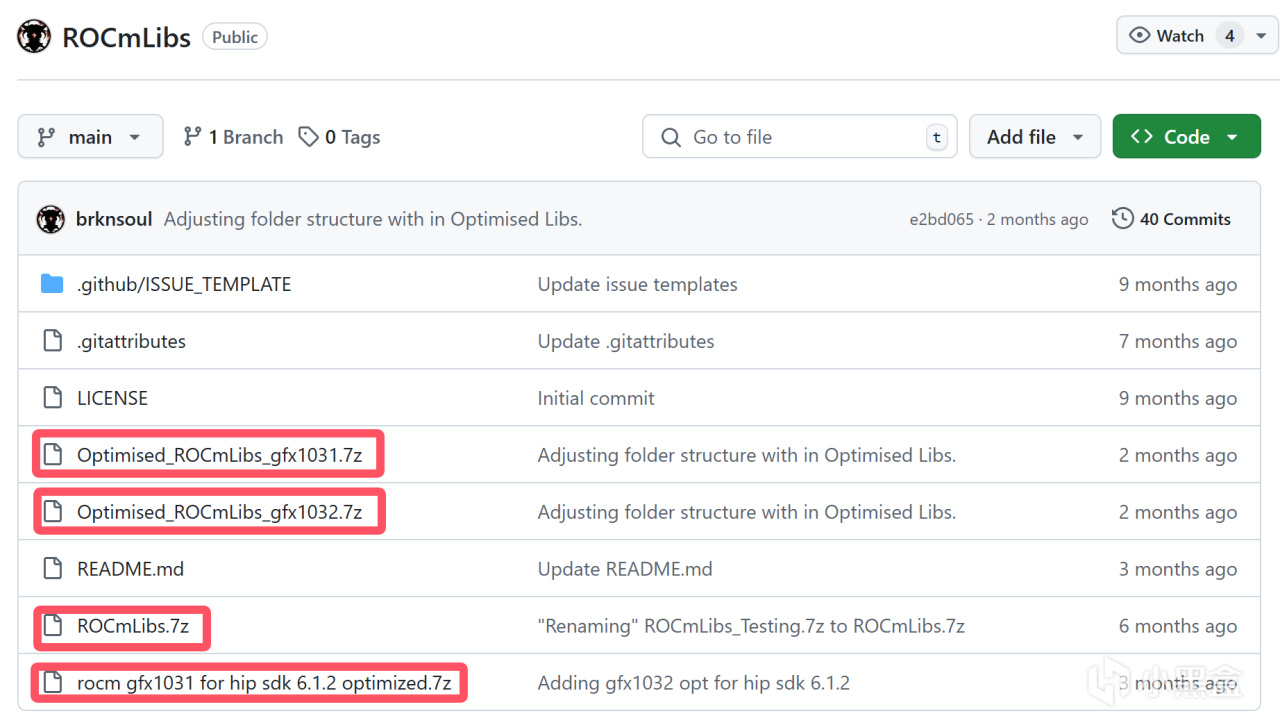
ROCmLibs
将其中的文件解压后,复制到%HIP_PATH%\bin\rocblas\中,对于我而言是M:\AMD\ROCm\5.7\bin\rocblas\,若有覆盖提示直接确认即可。
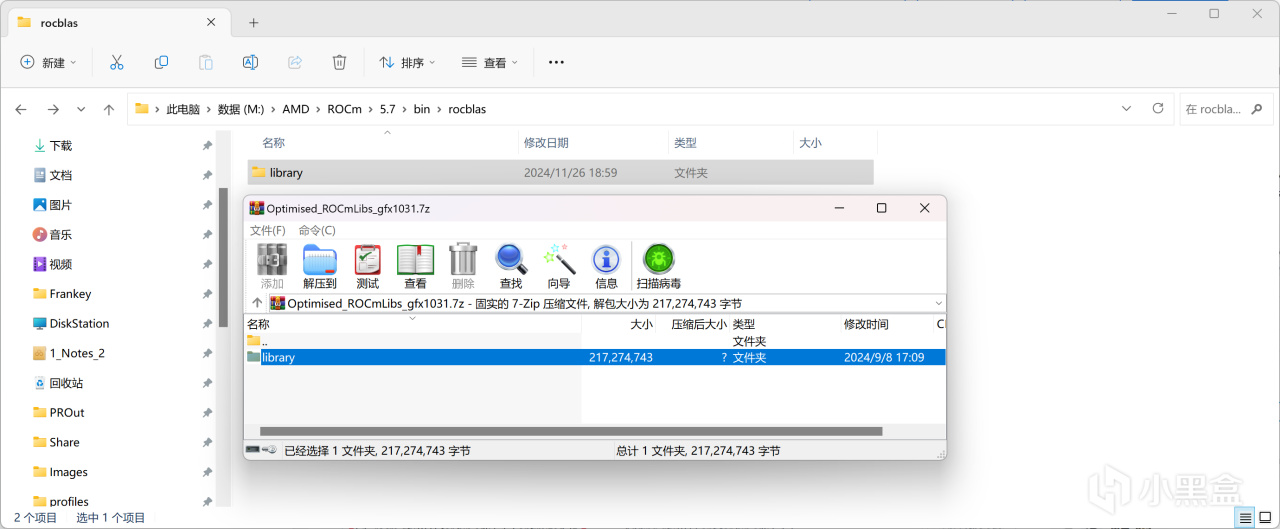
覆盖ROCm library
HIP SDK的安装到此完全结束,下面开始Zluda的安装。
用于运行pytorch的Zluda的分支地址如下:
https://github.com/lshqqytiger/ZLUDA
请自行在Releases中根据你使用的ROCm的版本下载对应的版本:

Zluda
将其随便解压到一个地方,然后用与上文相同的操作打开环境变量编辑,将你解压Zluda的路径添加到"Path"变量中。
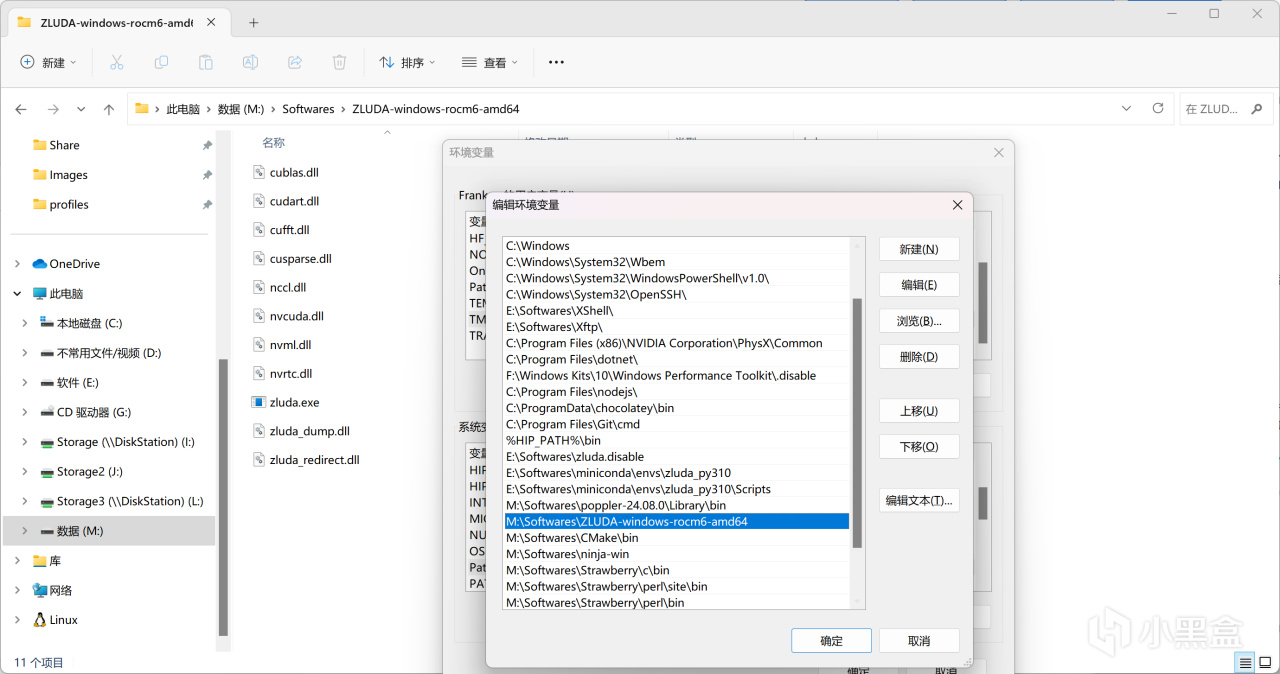
解压Zluda并添加到环境变量
此时Zluda的安装结束,非常简单,但是要想使pytorch运行在Zluda上面,还需要一些操作。
在这里再为Windows安装一个miniconda来运行虚拟python环境,其可通过此链接进行下载:
https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe
安装完成后搜索"Anaconda Prompt (miniconda)"并打开。
Anaconda Prompt (miniconda)
可以看到此时已经进入了"base"环境:
"base"环境
之后创建环境的操作和上文中WSL的部分一样:
conda create -n torch_zluda python=3.10
conda activate torch_zluda
然后使用pytorch官网中的指令直接安装CUDA版本的pytorch:
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu118
需要注意的是,Zluda并不支持最新版本的pytorch,会报CUDA错误,本人已经验证2.5.1版本的pytorch是无法运行的,而2.3.1版本的pytorch是可以运行的,所以上面的指令是2.3.1版本,其他版本请自行验证。
CUDA版本的pytorch安装完成后,需要对其进行一些修改,首先输入以下指令列出你所有的环境的位置,并找到你刚刚安装pytorch的那个环境,将其路径复制下来:
conda info --envs
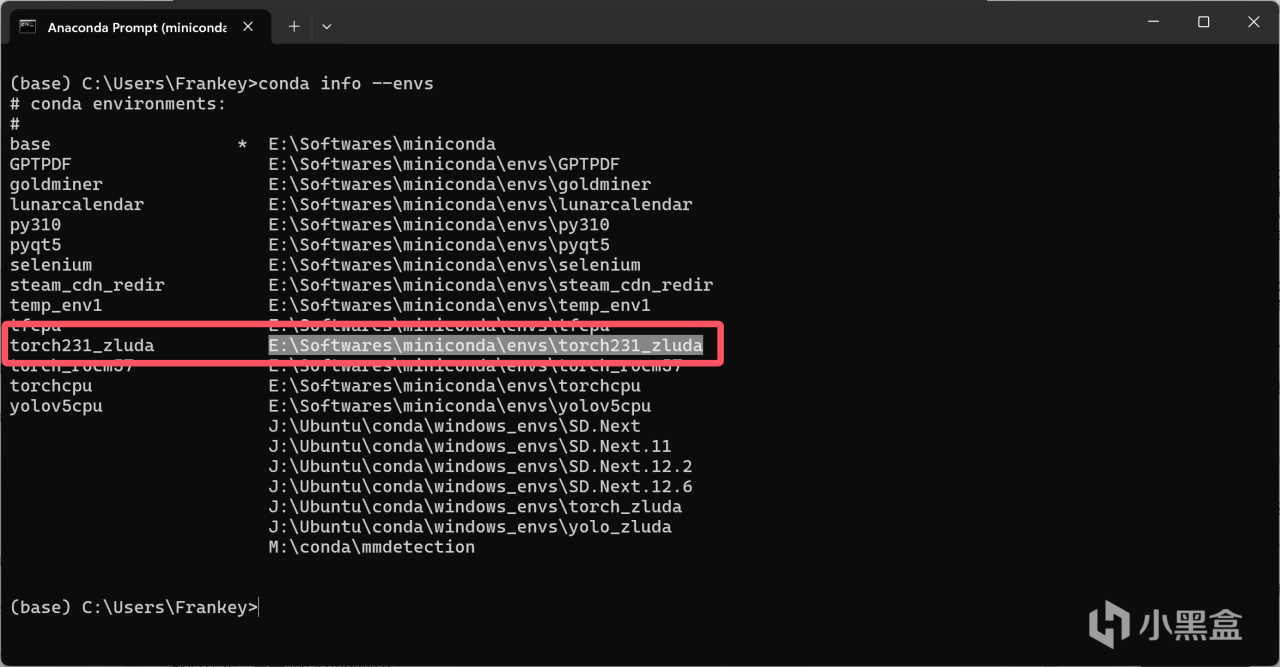
列出环境
打开该目录,进入.\Lib\site-packages\torch\lib:
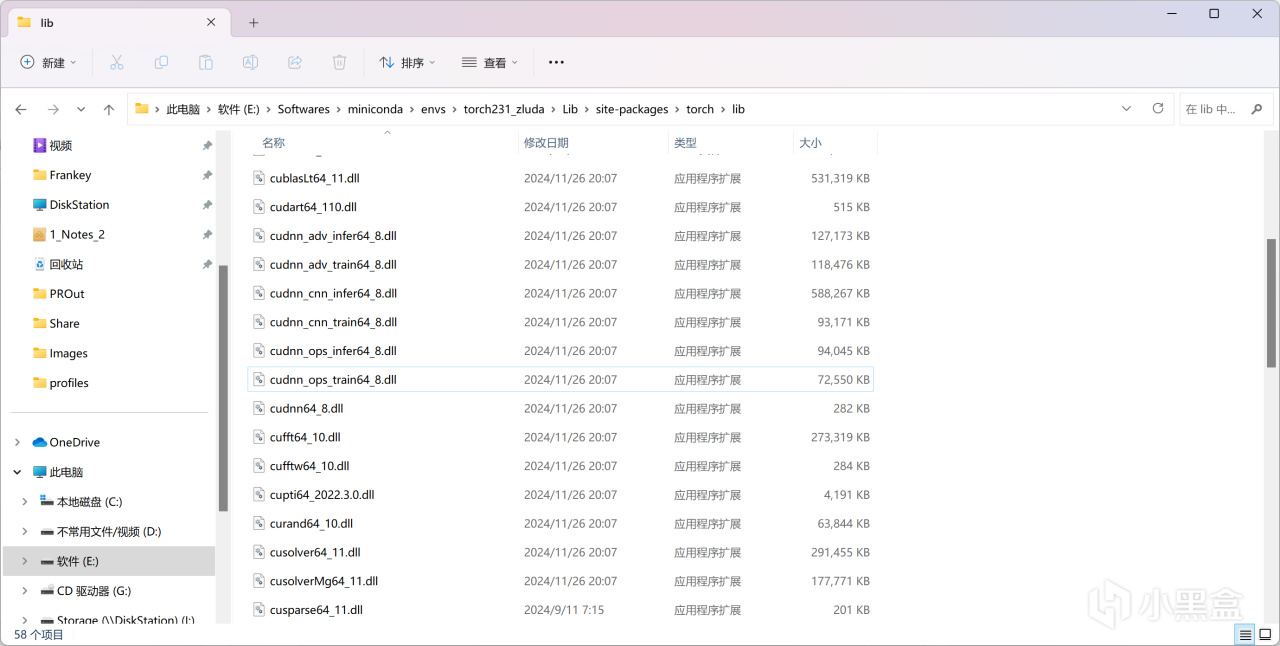
pytorch的lib目录
将cublas64_11.dll和cusparse64_11.dll分别重命名为cublas64_11.dll.bak和cusparse64_11.dll.bak:
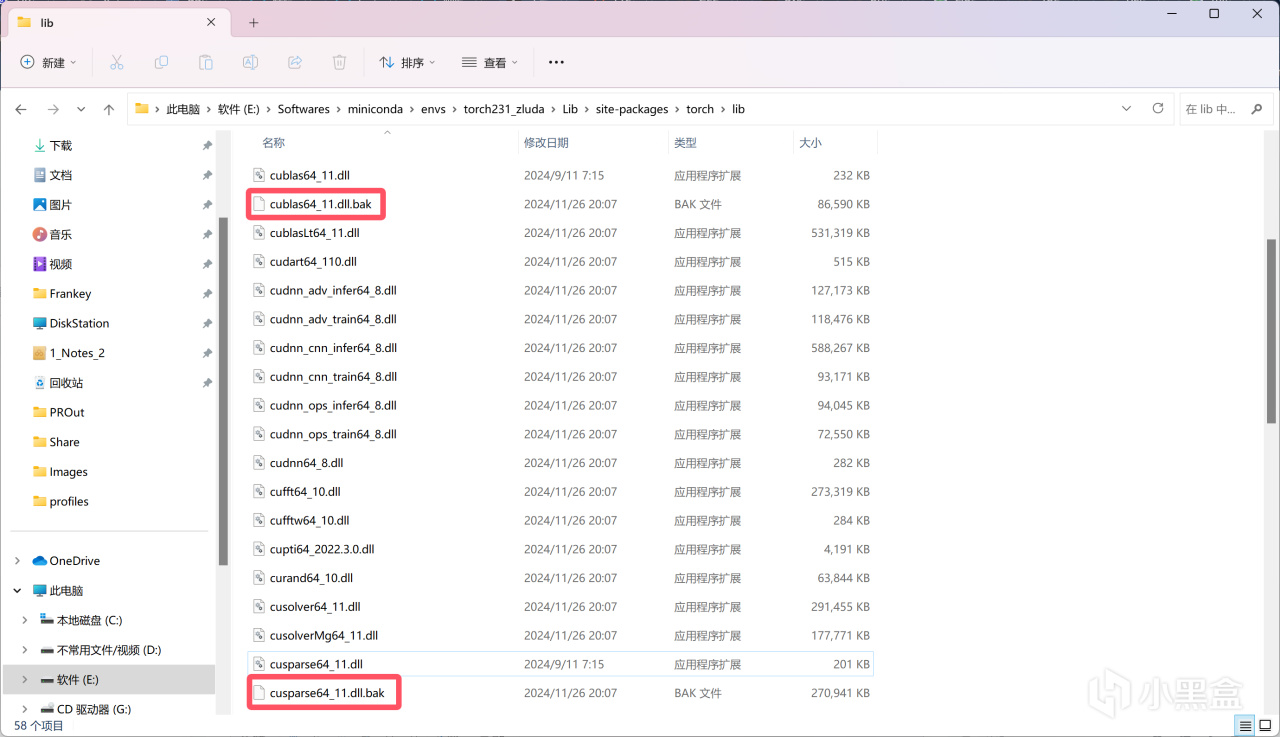
重命名以禁用
打开Zluda的目录,将Zluda目录下cublas.dll和cusparse.dll复制下来并粘贴到pytorch的lib目录当中(也就是上图中的目录)。
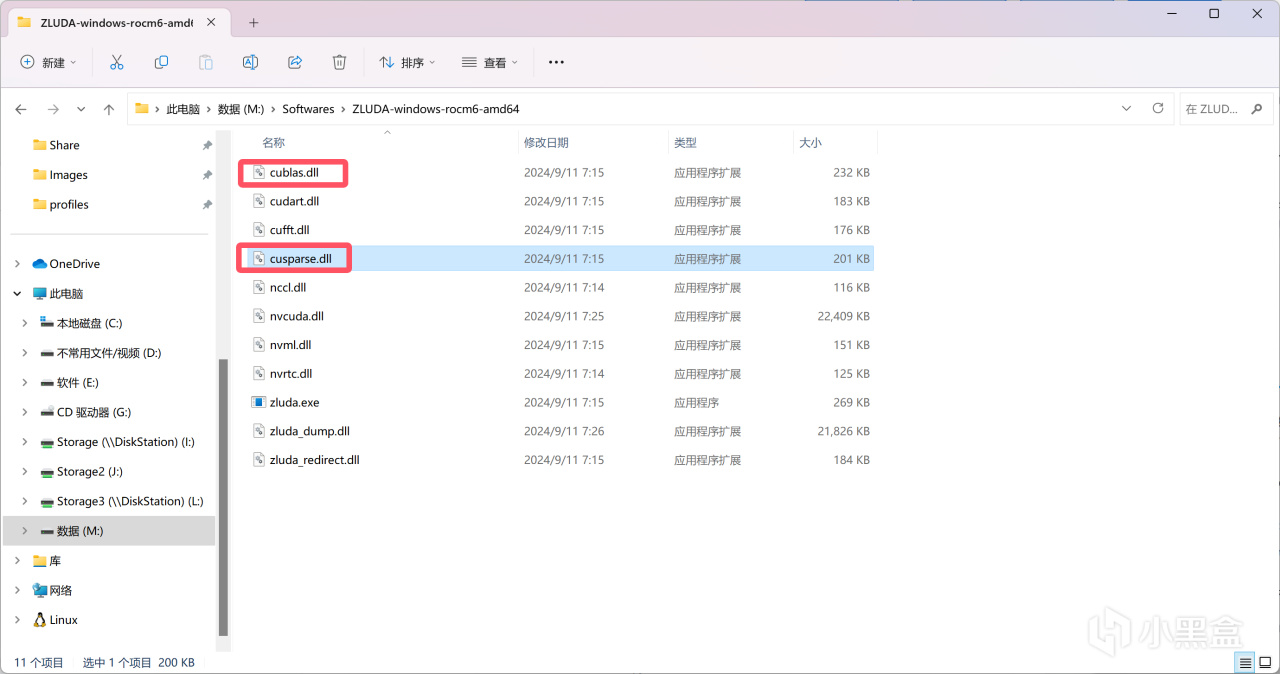
Zluda目录
在pytorch的lib目录中将从Zluda目录复制的cublas.dll和cusparse.dll分别重命名为cublas64_11.dll和cusparse64_11.dll。
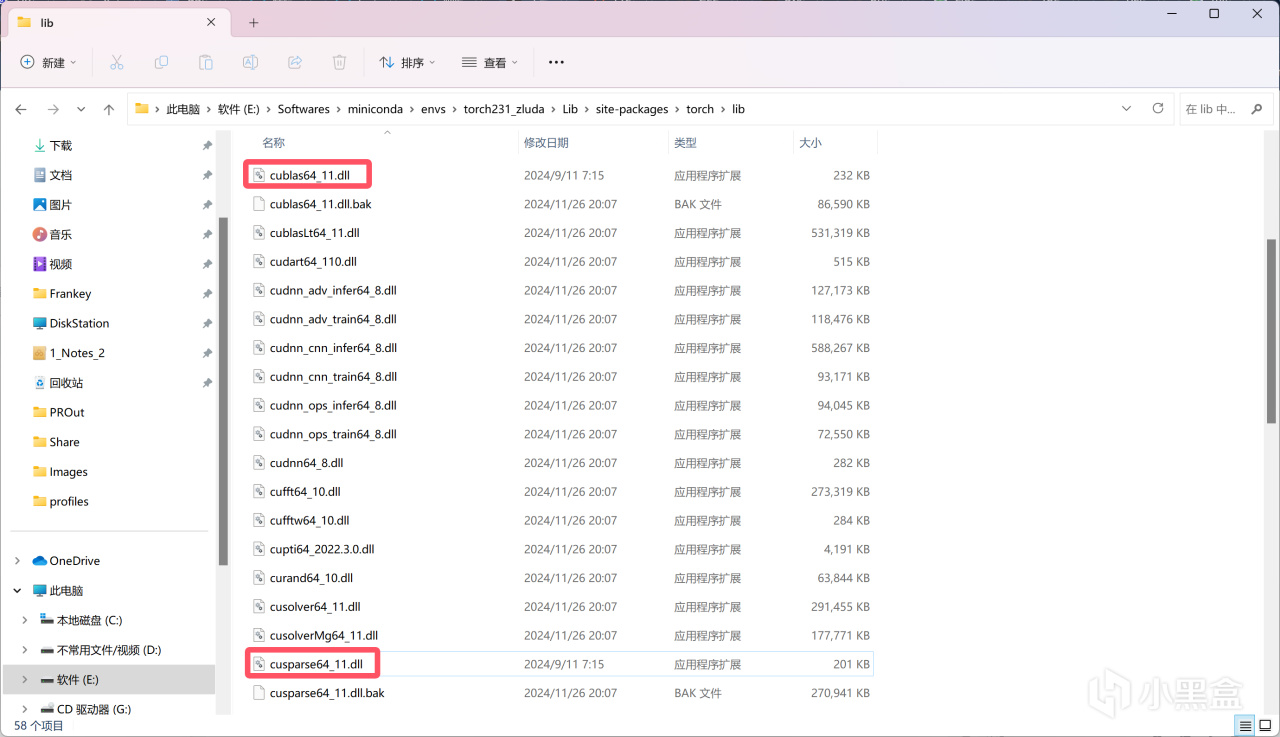
重命名以启用
此时与WSL相同,在命令行中运行如下指令验证是否可调用GPU:
python
import torch
torch.cuda.is_available()
正常情况下应该输出为True,说明已经可以通过Zluda调用你的AMD GPU进行计算:
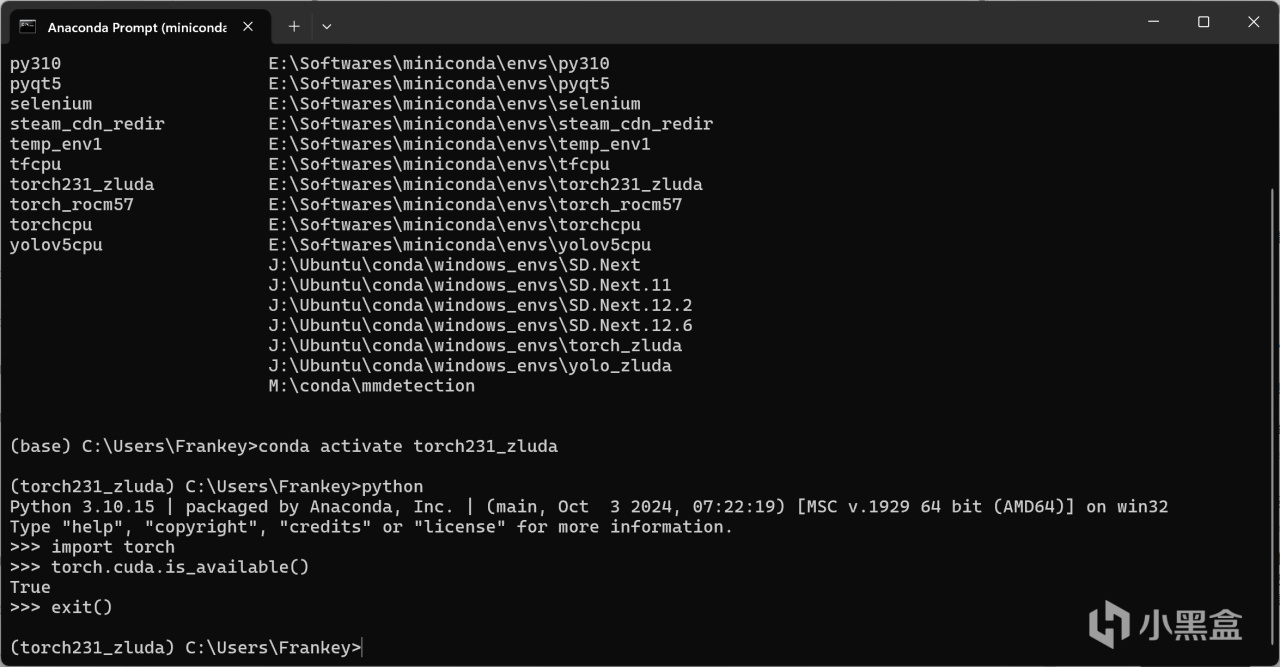
torch.cuda.is_available()
同样地,输入exit()来退出python。
需要注意的是,如果你在上面安装了不受支持的pytorch版本(如2.5.1),尽管这里torch.cuda.is_available()返回的是True,甚至你创建两个张量移动到GPU上相加并打印都完全没有问题,但是当你实际运行神经网络(如最基本的ResNet18)的时候依然会报CUDA错误,该错误主要出现在linear线性层进行计算的时候,具体原因未知,但至少正确版本的pytorch能保证不出现该错误。
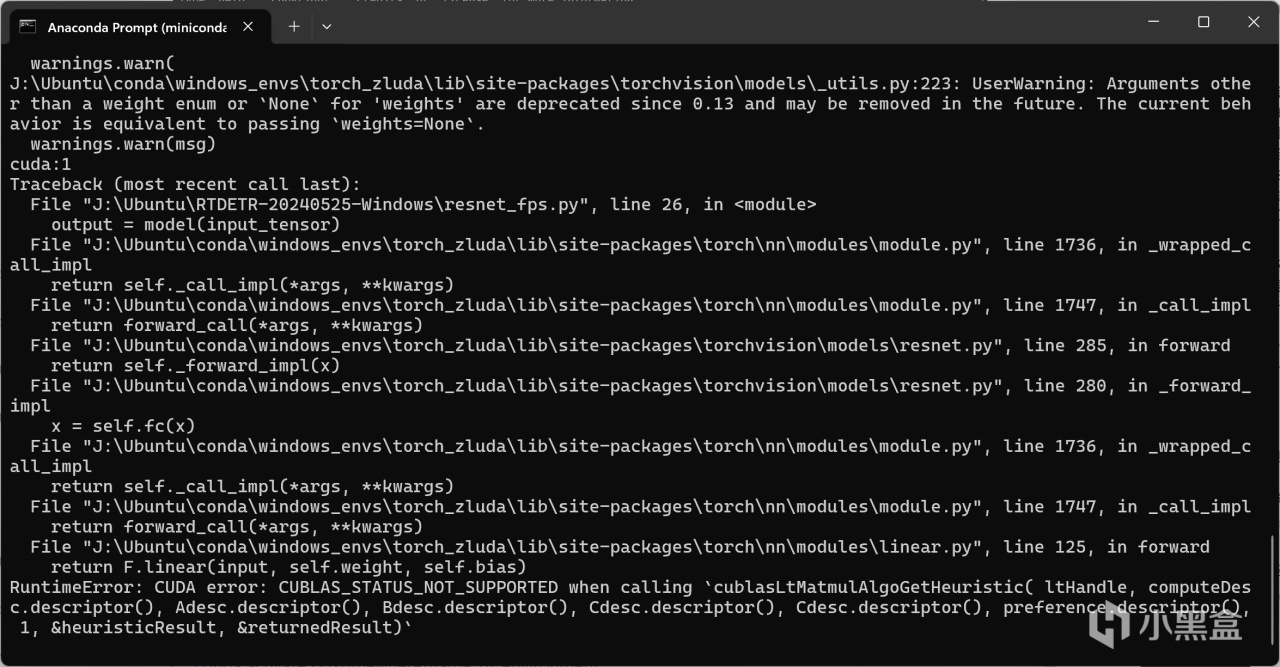
不受支持的pytorch版本导致的CUDA error: CUBLAS_STATUS_NOT_SUPPORTED
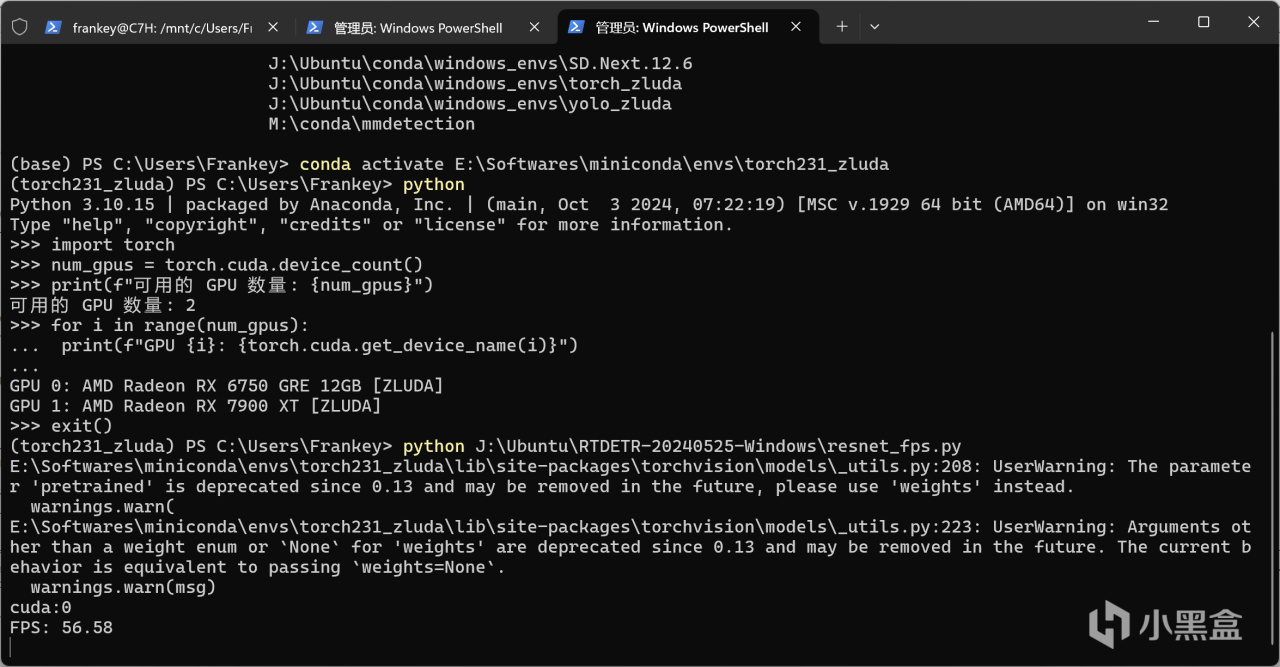
正确的pytorch版本才能正常的进行运算
另外,在通过Zluda运行一个新的torch网络的时候,其需要编译PTX模块,这个过程需要耗费十几分钟到一个小时不等,期间终端不会有任何输出,请耐心等待,第二次及之后运行则不需要此过程。
至此,本篇教程已完全结束,在这之后,你可以使用这些pytorch来运行绘画模型、大语言模型、语音克隆模型、视觉模型以及其他几乎任何现有的模型。
需要注意的是,无论是WSL还是Windows,你在本教程中安装的pytorch可能会被一些程序的安装脚本安装的CPU版本的pytorch覆盖掉,此时你就应该参考本教程,重新进行安装。因此,这样的环境并不是一次安装成功就可以一劳永逸了,本教程属于授人以渔的范畴,任何时候你需要在新的虚拟环境中安装一个可使用AMD GPU的pytorch你都可以参考本教程进行安装。
各位在参照本教程进行环境安装的时候遇到任何问题均可在评论区留言,我有时间会回答,但是网络问题除外,一切与网络相关的问题请自行解决。
补充
最后补充一些其他的conda命令:
装上pytorch等包的环境会非常大(数个到数十个GB不等),如果你想把环境安装到其他位置,乃至和我一样安装到NAS中,请使用--prefix参数:
conda create --prefix D:/somewhere/name_of_environment python=3.10
此时要激活你的环境就需要输入完整路径:
conda activate D:/somewhere/name_of_environment
注:WSL上通过NFS挂载NAS的硬盘有时会出现一些奇怪的BUG(物理机无此问题),尽管我通过一些办法进行了解决,但由于无法稳定进行复现,所以本篇教程不做阐述。
如果你想从基础环境复制一个新的环境而不是重新安装,请使用--clone参数:
conda create --prefix D:/somewhere/name_of_environment --clone D:/somewhere/original_environment
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















