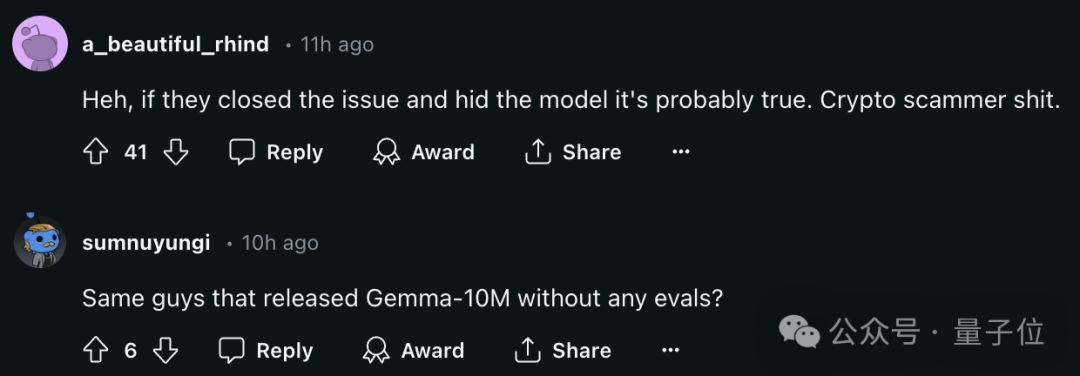
斯坦福AI 團隊,竟然曝出了抄襲事件,而且抄襲的還是中國國產的大模型成果 —— 模型結構和代碼,幾乎一模一樣!跟任何抄襲事故一樣……AI 圈內都驚呆了。
斯坦福的這項研究叫做Llama3-V,是於 5 月 29 日新鮮發佈,宣稱只需要 500 美元就能訓出一個 SOTA 多模態大模型,比 GPT-4V、Gemini Ultra、Claude Opus 都強。

Llama3-V 的 3 位作者或許是擁有名校頭銜加持,又有特斯拉、SpaceX 的大廠相關背景,這個項目短短几天就受到了不小的關注。
甚至一度衝上了 HuggingFace 趨勢榜首頁:
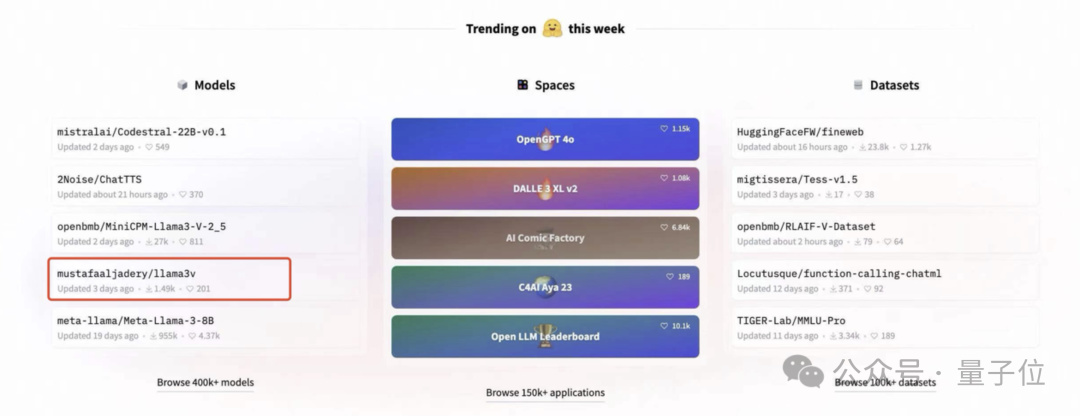
然而,戲劇性的一幕開始上演了。
有位細心的網友發現,咦?這“配方”怎麼如此的熟悉?
然後他定睛一看,好傢伙,這不就是MiniCPM-Llama3-V 2.5(出自清華系明星創業公司面壁智能)嘛。
於是這位網友便跑到面壁智能 GitHub 項目下開始爆料了:
你們家大模型被斯坦福團隊抄襲了!
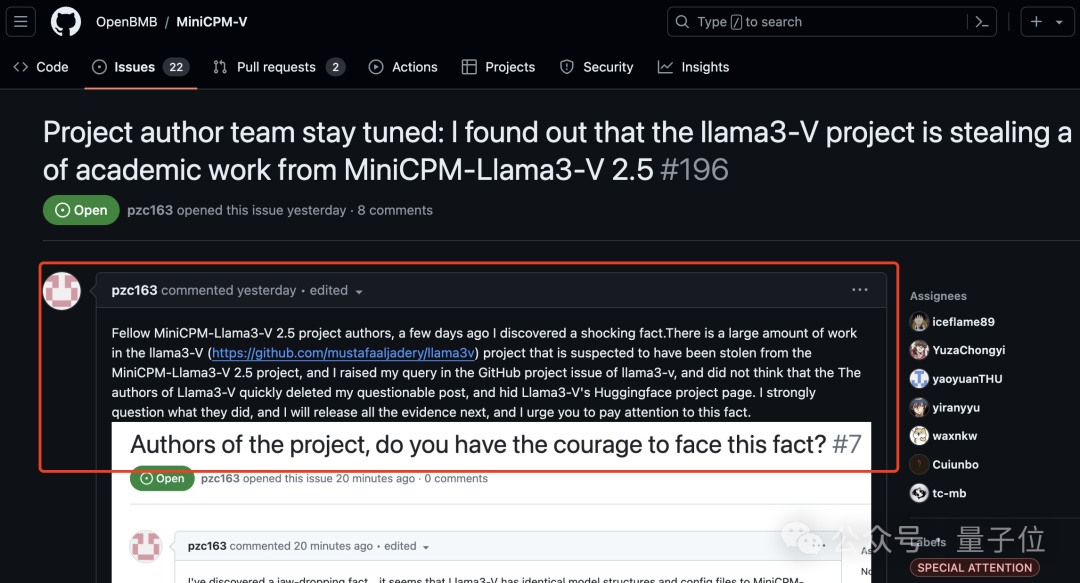
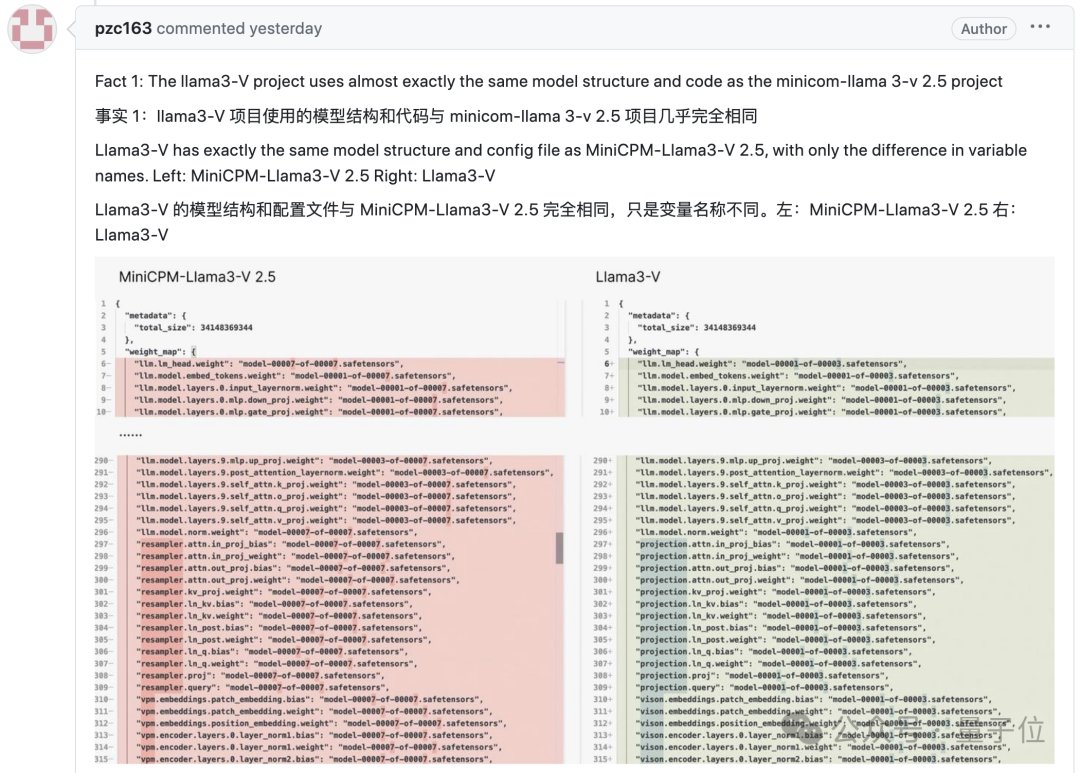
並且他還附上了一堆的證據,最直接的莫過於這張 2 個模型代碼的對比圖了:
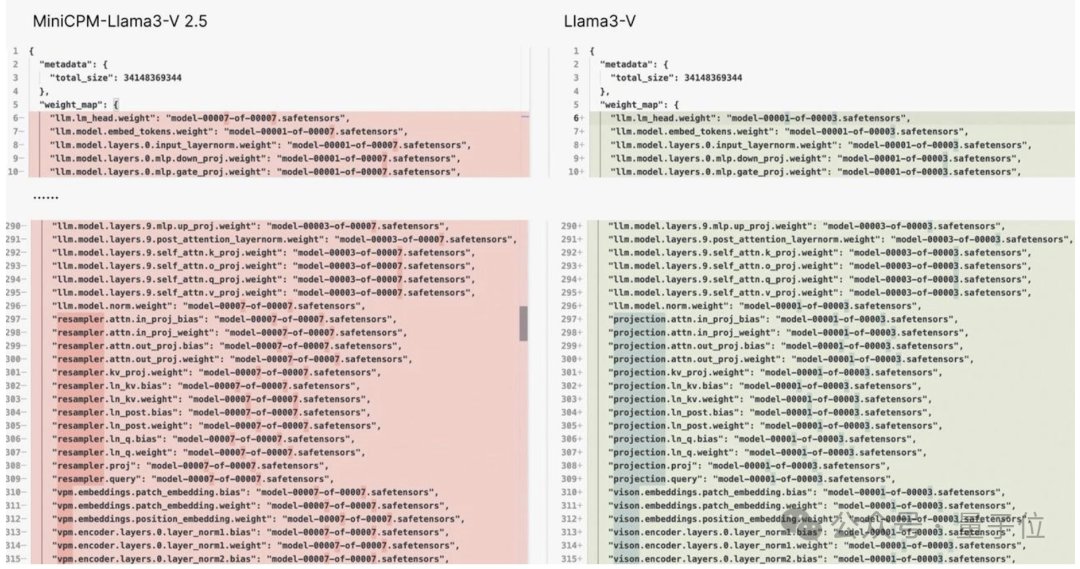
Emmm…… 用這位網友的話來說就是:
模型結構、代碼、配置文件,簡直一模一樣,只是變量名變了而已。
至於爲什麼這位網友要跑到面壁智能 GitHub 項目下面留言,是因爲他之前已經給 Llama3-V 作者留過言了,但斯坦福團隊的做法竟是刪庫跑路……
沒錯,現在不論是 GitHub 還是 HuggingFace,統統都是 404:
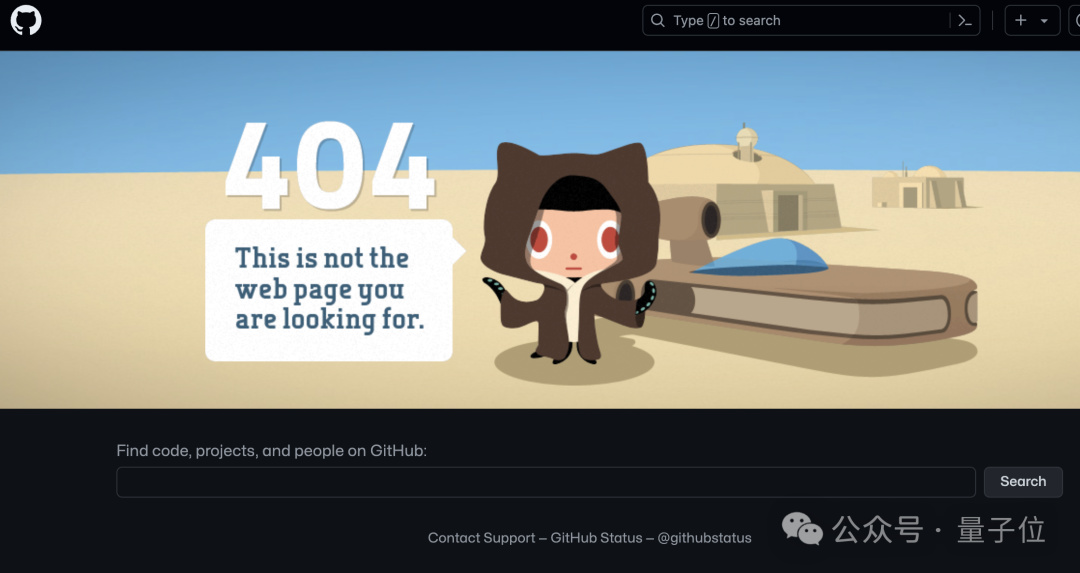
並且這事現在還在持續發酵的過程中,網上喫瓜的羣衆也是越來越多。
那麼我先來一同回顧一下這件 drama 事情的始末。
“代碼和架構一模一樣”
正如剛纔所述,一個網友爆料 Llama3-V 抄襲 MiniCPM-Llama3-V 2.5,跑到面壁智能的 GitHub 主頁提醒團隊注意,並把關鍵證據都一一截圖列舉整理了下來,這纔有了整個抄襲門的還原現場。
以下是來自這位網友的證據。
證據一,Llama3-V 的模型架構和代碼與 MiniCPM-Llama3-V 2.5 幾乎完全相同:
看下面的例子,配置文件就改了圖像切片、分詞器、重採樣器和數據加載等格式化和變量名:
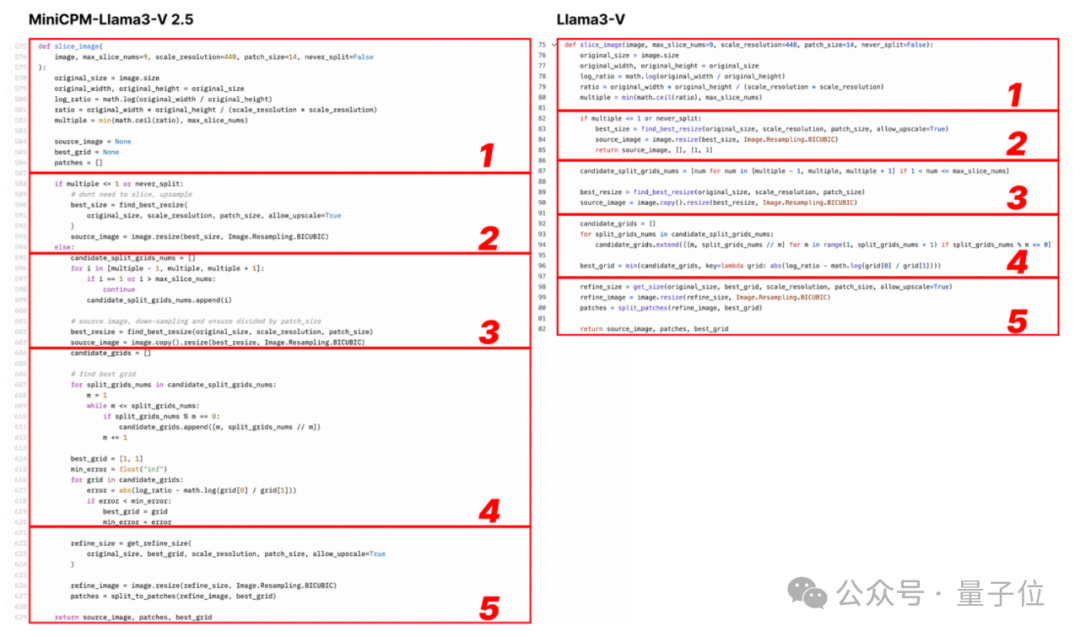
Llama3-V 作者表示參考了 LLaVA-UHD 架構,在 ViT 和 LLM 等選擇上有一些差異。但實際上,網友發現他們的具體實現在空間模式等很多方面都與 LLaVA-UHD 不同,卻出奇與 MiniCPM-Llama3-V 2.5 一致。
甚至,Llama3-V 還用了 MiniCPM-Llama3-V 2.5 的分詞器,連MiniCPM-Llama3-V 2.5 定義的特殊符號都能“巧合”實屬離譜。

證據二,網友質疑 Llama3-V 作者是如何在 MinicPM-Llama3-V2.5 項目發佈之前就使用上 MinicPM-Llama3-V2.5 分詞器的。
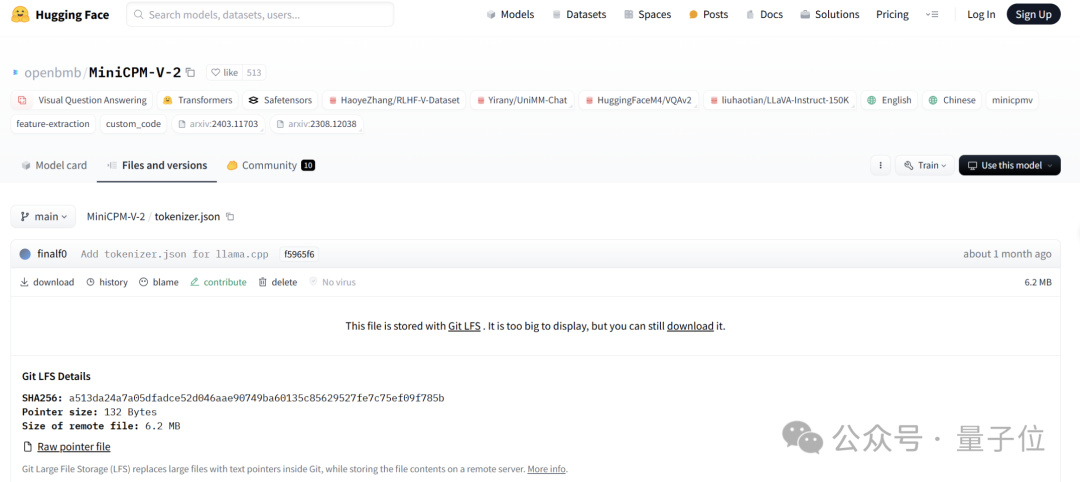
Llama3-V 作者給的回覆是這樣嬸兒的,說是用的面壁智能上一代 MinicPM-V-2 項目的:
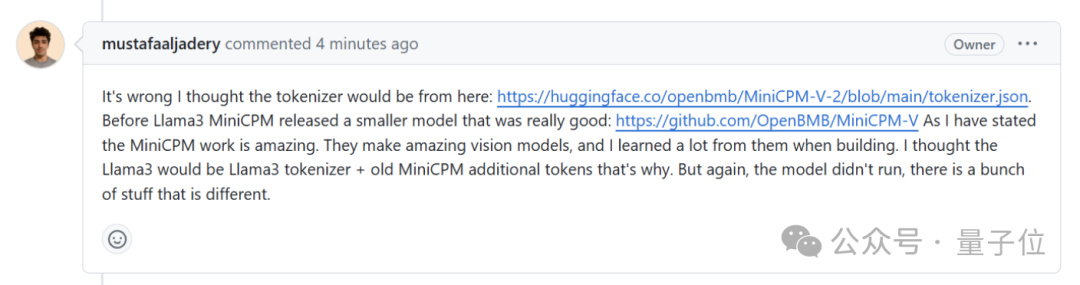
但事實卻是,HuggingFace 中,MiniCPM-V2 與 MiniCPM-Llama3-V 2.5 分詞器分別是兩個文件,文件大小也完全不同。
MiniCPM-Llama3-V 2.5 的分詞器是用 Llama3 分詞器加上 MiniCPM-V 系列模型的特殊 token 組成,而 MiniCPM-V2 的發佈都在 Llama3 開源之前,怎麼會有 Llama3 分詞器。
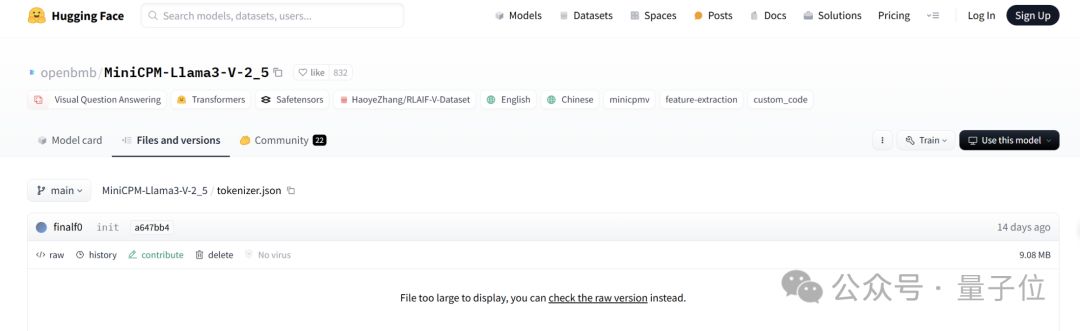
證據三,Llama3-V 作者隨後無故刪除了網友在 Llama3-V 頁面上提交的質疑他們抄襲的問題。
而且,他們似乎對 MiniCPM-Llama3-V 2.5 架構或他們自己的代碼都不完全瞭解。
感知器重採樣器(Perceiver resampler)是單層交叉注意力,而不是雙層自注意力。但是下圖所示 Llama3-V 的技術博客裏作者的理解很明顯是錯的。

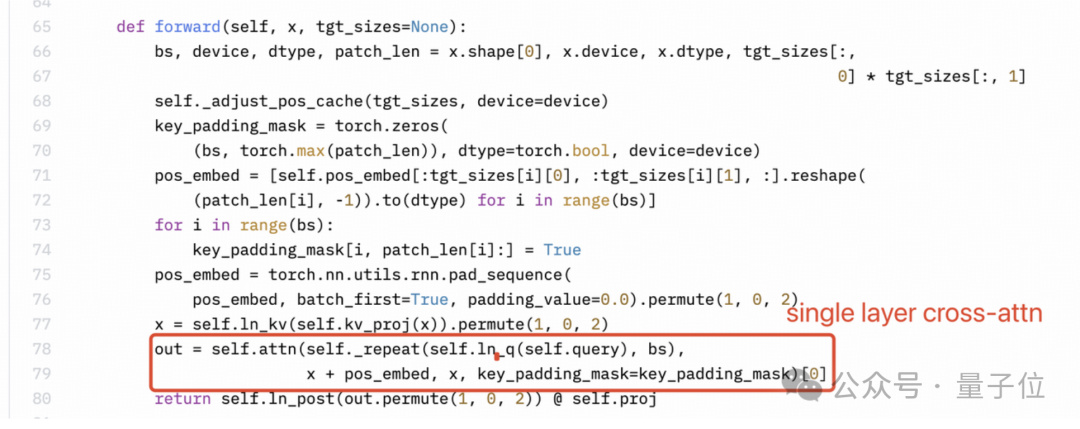
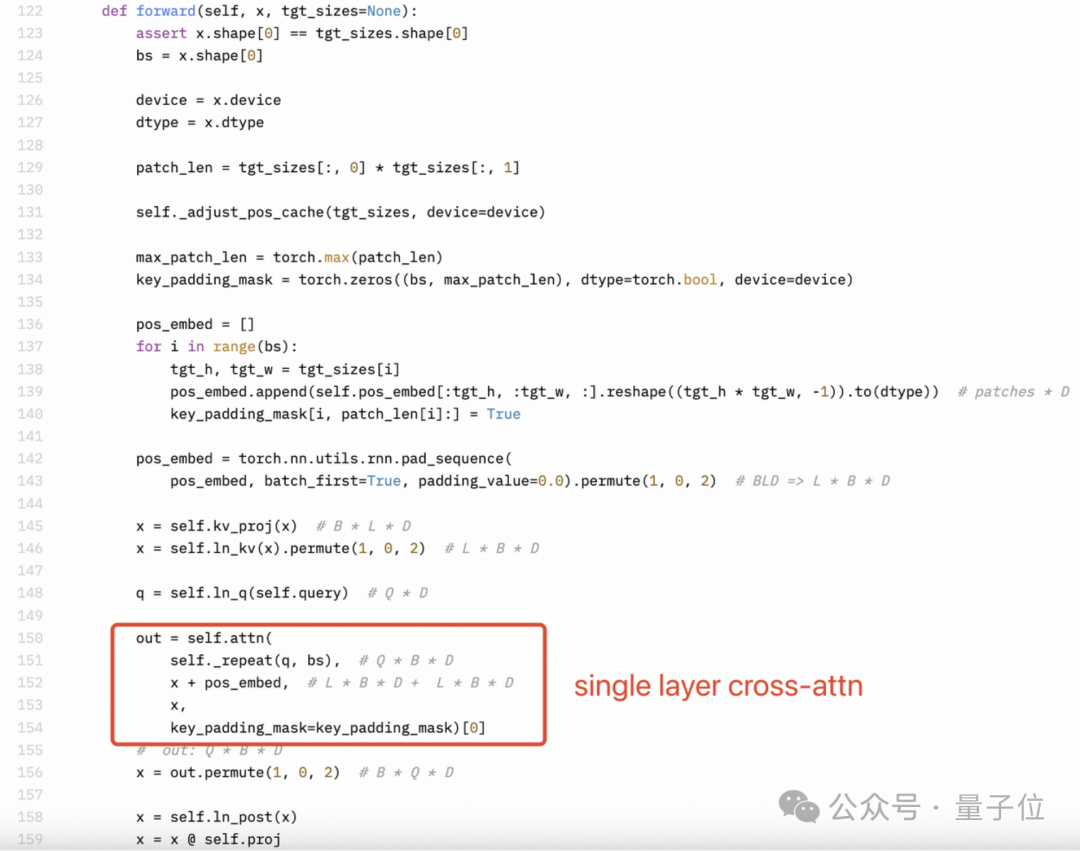
SigLIP 的 Sigmoid 激活也不用於訓練多模態大語言模型,而僅用於預訓練 SigLIP。
視覺特徵提取不需要 Sigmoid 激活:
基於以上三點事實,這位網友認爲證據足以證明 Llama3-V 項目竊取了 MiniCPM-Llama3-V 2.5 項目的學術成果。
但還沒完,他隨後又補充了兩點證據。
幾天前,當這位網友嘗試運行 Llama3-V 時,發現他們提供的代碼無法與 HuggingFace 的 checkpoint 一起使用,反饋問題沒有得到作者回復。
於是網友把從 HuggingFace 下載的 Llama3-V 模型權重中的變量名改成了 MiniCPM-Llama3-V 2.5 的,驚奇發現模型居然可以用 MiniCPM-V 代碼成功運行。
此外,如果將高斯噪聲(由單個標量參數化)添加到 MiniCPM-Llama3-V 2.5 的 checkpoint,結果就是會得到一個行爲與 Llama3-V 極其相似的模型。
收到網友的提醒後,MiniCPM-Llama3-V 2.5 團隊這邊也迅速展開了調查,他們按照網友的在 GitHub 上的說明,使用 Llama3-V 的 checkpoint 和 MiniCPM-Llama3-V 2.5 的代碼和配置文件正確獲取了推理結果。
於是,一個更爲關鍵性的證據出現了。
Llama3-V 在一些未公開的實驗性特徵上表現出與 MiniCPM-Llama3-V 2.5 高度相似的行爲,而這些特徵是根據 MiniCPM-Llama3-V 2.5 團隊內部數據訓練的。
例如,識別清華簡!
MiniCPM-Llama3-V 2.5 特有的功能之一是識別清華簡,這是一種非常罕見、於戰國時期寫在竹子上的中國古代文字。
訓練圖像是從最近出土的文物中掃描出來的,由 MiniCPM-Llama3-V 2.5 團隊進行了標註,尚未公開發布。
而 Llama3-V 的識別情況和 MiniCPM-Llama3-V 2.5 極爲相似。
識別錯誤的情況竟也出奇一致:
MiniCPM-Llama3-V 2.5 團隊還在 1000 張竹簡圖像上測試了幾種基於 Llama3 的視覺-語言模型,並比較了每對模型的預測精確匹配。
結果,每兩個模型之間的重疊爲零,而 Llama3-V 和 MiniCPM-Llama3-V 2.5 之間的 && 重疊達到了驚人的 87%**。
此外,MiniCPM-Llama3-V 2.5 和 Llama3-V甚至具有相似的錯誤分佈。Llama3-V 和 MiniCPM-Llama3-V 2.5 分別做出 236 和 194 個錯誤預測,重疊部分爲 182 個。
且按照網友在 GitHub 上的指令獲得的 MiniCPM-Llama3-V2.5-noisy 顯示出與 Llama3-V 幾乎相同的定量結果,真令人匪夷所思……
在另一個 MiniCPM-Llama3-V 2.5 內部數據上訓練的未公開功能 ——WebAgent 上,也出現了同樣的情況。
Llama3-V 甚至和 MiniCPM-Llama3-V 2.5 團隊新定義的 WebAgent 模式中犯的錯誤都一樣。
鑑於這些結果,MiniCPM-Llama3-V 2.5 團隊表示很難將這種不尋常的相似性解釋爲巧合,希望 Llama3-V 作者能對這個問題給出一個正式的解釋。
斯坦福團隊已刪庫跑路
雖然斯坦福的 2 位本科生已經下架了幾乎所有與之相關的項目,但其實在此之前,他們最初在面對質疑的時候還是做出了些許的解釋。
例如他們強調,Llama3-V 這項工作的時間是要早於面壁智能的 MiniCPM,只是使用了他們的 tokenizer。
不過作者對 Medium 上的聲明還是做了保留:
非常感謝那些在評論中指出與之前研究相似之處的人。
我們意識到我們的架構非常類似於 OpenBMB 的“MiniCPM-Llama3-V 2.5,他們在實現上比我們搶先一步。
我們已經刪除了關於作者的原始模型。
對此,一部分網友表示,既然選擇刪掉項目,那麼就表示確實存在一定的問題。
不過另一方面,對於抄襲這事也有不一樣的聲音 ——
MiniCPM-Llama3-V 2.5 不也是在 Llama3 的基礎上做的改良嗎?不過連 tokenizer 都直接拿來用就應該不算是借鑑了。
而就在剛剛,另一個戲劇性的事情發生了。
斯坦福的作者在中午時間做出了最新的回應:
但現在…… 這條回應又刪掉了。
本文來自微信公衆號:量子位 (ID:QbitAI),作者:金磊 西風
來源:IT之家
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















