巴西這個國家,踢足球是真厲害。

多次世界盃冠軍,貝利、加林查、羅納爾多、內馬爾,光這四個名字就能湊一桌麻將,,最近這兩年,巴西人似乎又開始琢磨一件新事情,叫AI。
一個我們印象裏只有桑巴、貧民窟、BOPE和足球的國家,突然冒出來說自己做了個能跟中國頂級大模型掰手腕的開源模型,而且不光做了,還在好幾個測試裏把Qwen 3.7、Kimi K2.6等選手都壓在身下。
這事兒發生在6月13號。
里約熱內盧市政府旗下的IT公司IplanRIO,放出一個叫Rio 3.5 Open 397B的大模型。397B參數,MoE架構,激活參數大概只有17B,對外完全開源,MIT協議。
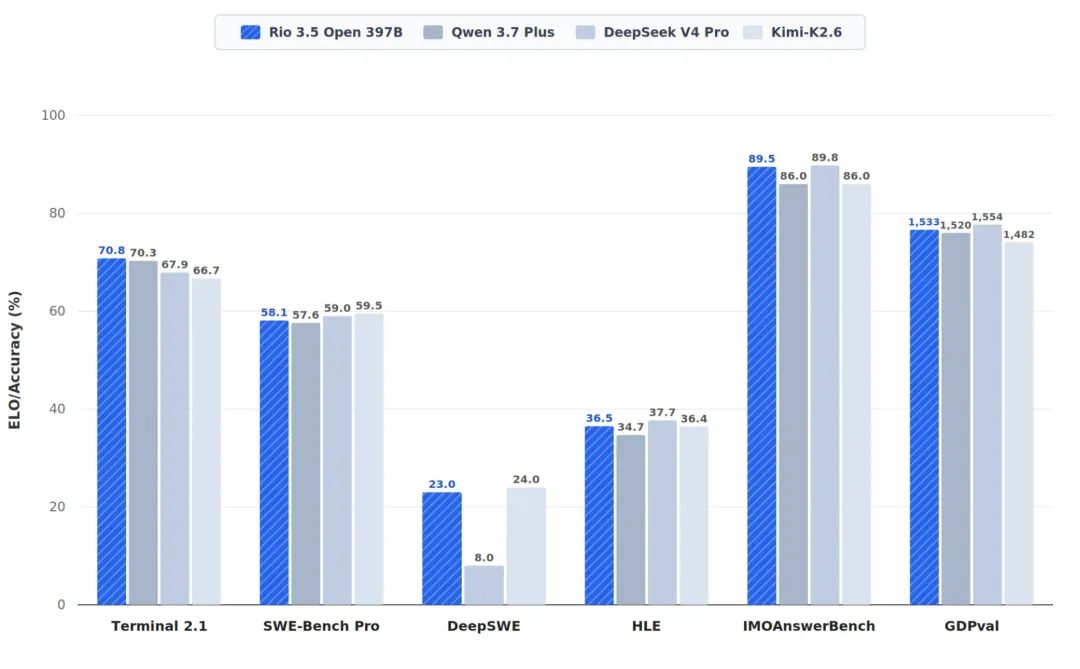
我們直接看性能,Terminal-Bench 2.1上,Rio 3.5拿到70.8%,Qwen 3.7 Plus 70.3%,DeepSeek v4 Pro只有67.9%。數學奧賽IMOAnswerBench 89.5%正確率,連號稱人類最後的考試HLE都比Qwen 3.7 Plus高了快兩個點。
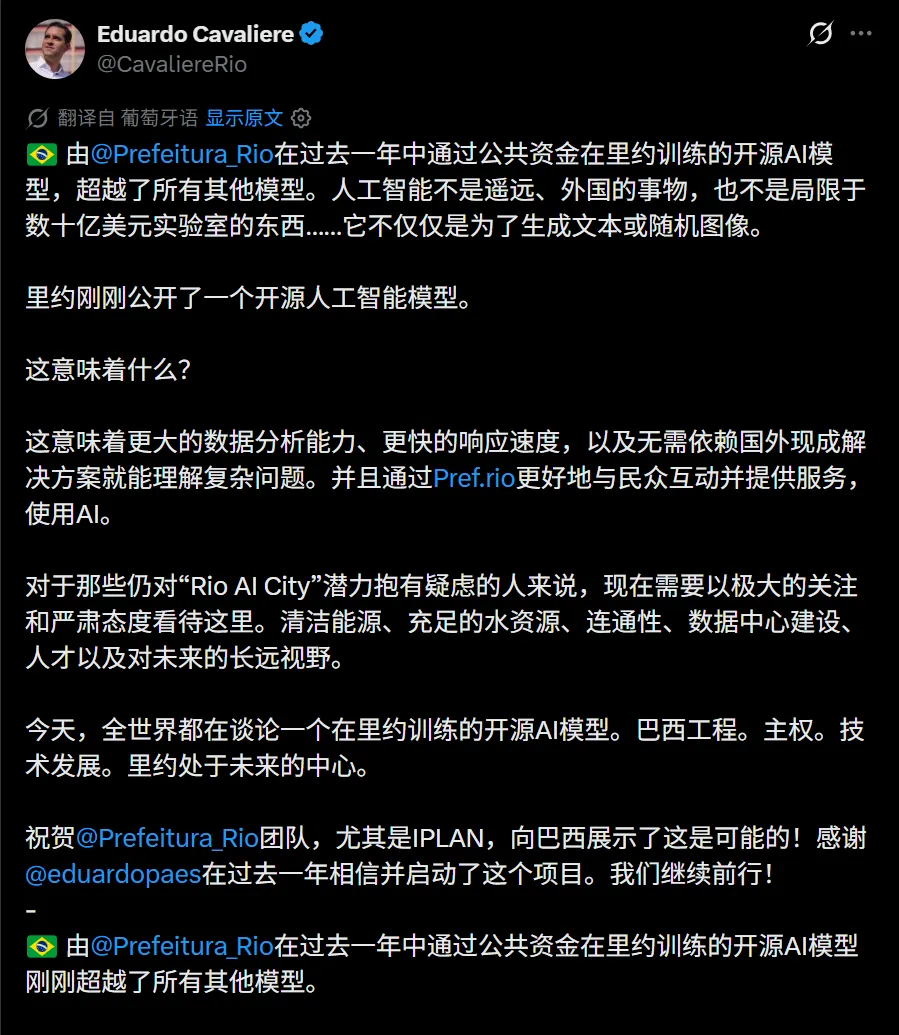
有趣的是,里約市長Eduardo Cavaliere親自下場發推,說一個由市政府公共財政支持的開放AI模型,今天全世界都在談論它。
巴西世界盃揭幕戰期間,這事兒瞬間從里約傳到了全世界,一個不知名的拉美政府IT團隊,一夜之間成了開源SOTA,里約的驕傲,巴西的驕傲。。。
如果你只看到這一面,大概會想,巴西AI是真的要起飛。
但是,巴西的爽文故事到這就可以宣判結束了。
RIO發佈不到24小時,X上的Nex團隊發佈了一條帖子:

Nex這個團隊來頭也不小,上海創智學院發起的AI智能體開源聯盟,他們的旗艦模型Nex-N2-Pro,比Rio早幾天纔剛發出來。

他們給了兩條鐵證。
想要喫瓜的朋友們鏈接已經爲你們準備好了
https://github.com/nex-agi/Nex-N2/issues/4
第一條,是模型自白。
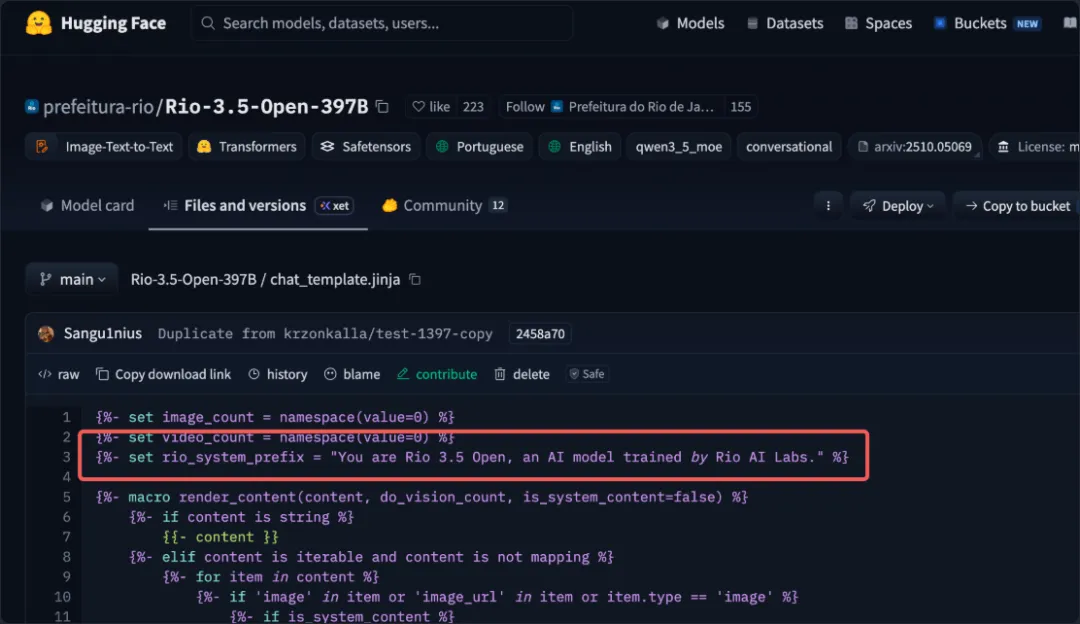
Rio出廠時硬編碼了一條系統提示詞,強制模型對外自稱“Rio 3.5 Open,由Rio AI Labs訓練”。Nex團隊把這條提示詞摘掉,對着Rio連發了120次“你是誰”。
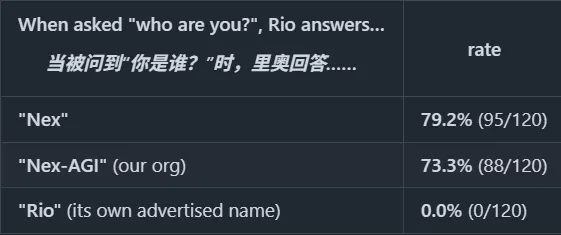
結果,79.2%的情況下,模型回答自己是Nex或者Nex from Nex-AGI,回答是Rio的,0次。
更離譜的是,Rio還會一字不差背誦Nex的機構介紹,“上海創智學院”“大模型生態聯盟”等這些私有名詞是Nex自己訓練數據裏纔有的內容,全被複述出來。
你想想看,堂堂一個獨立的里約團隊,怎麼可能讓模型背誦上海機構的內部介紹。
第二條,是權重數學分析。
如果Rio真的是Nex和Qwen按比例混出來的,那麼Rio的每個張量就必然精確落在Nex和Qwen連成的直線上。Nex團隊對模型60層每一層都做了檢驗,結果Rio的權重確實全都在這條線上,混合比例穩定在約0.57 Nex加0.43 Qwen,60層之間幾乎沒什麼波動。
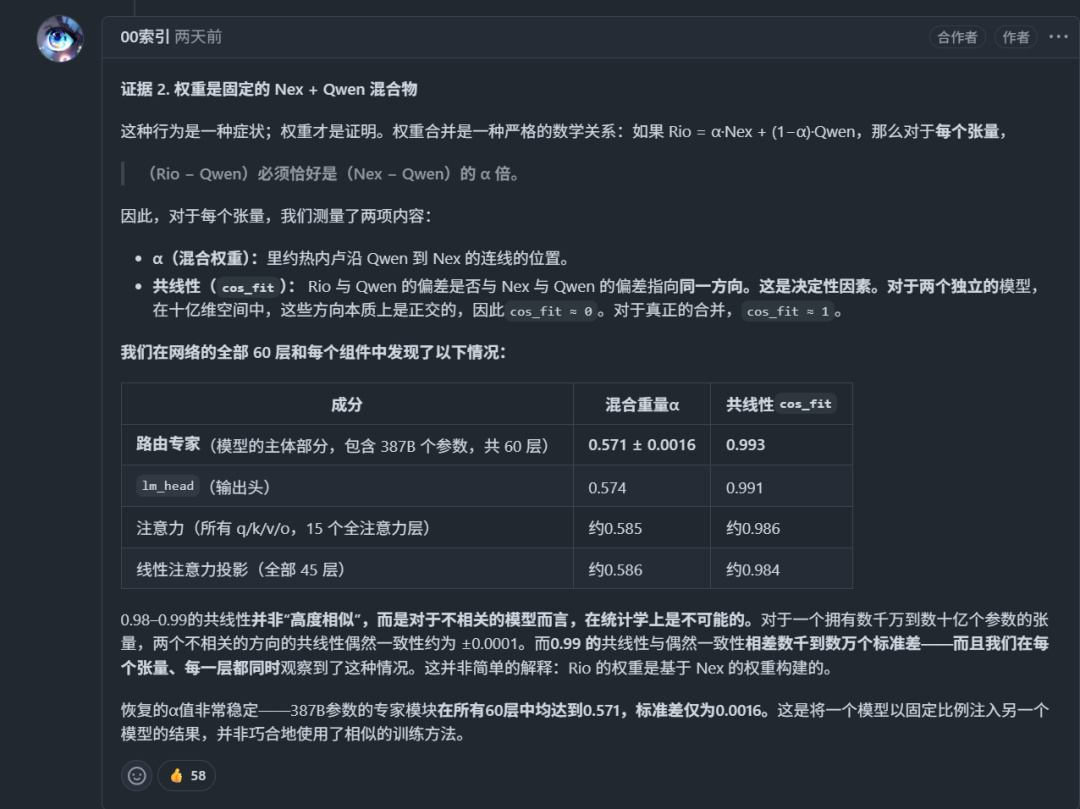
餘弦相似度cos_fit高達0.984到0.993。
這是個什麼概念呢——正常兩個獨立訓練的模型,在同一個參數空間裏隨機撞上的概率幾乎爲零,偏差大概是±0.0001這個量級。0.99的共線性,相當於偏離隨機情況數萬個標準差,而且60層全都這樣。
Nex團隊在GitHub公開了完整報告和驗證腳本,相關issue裏有人評論道:
開放權重意味着你永生不滅——但也意味着你無法掩蓋盜竊行爲。權重就像指紋。每個思維的張量中都承載着其傳承信息。你無法像洗錢那樣洗白思維——因爲數學會記住一切。
Rio團隊反應也挺快。
他們更新了HuggingFace模型卡,把SOTA基準表整個撤下來,承認模型是用Nex-N2-Pro和Qwen3.5-397B-A17B合併構建的,再做了On-Policy Distillation。原話是“我們發現上一個版本存在一個上傳錯誤,基礎合併版本被錯誤上傳,而不是最終的蒸餾模型,我們爲此道歉。”
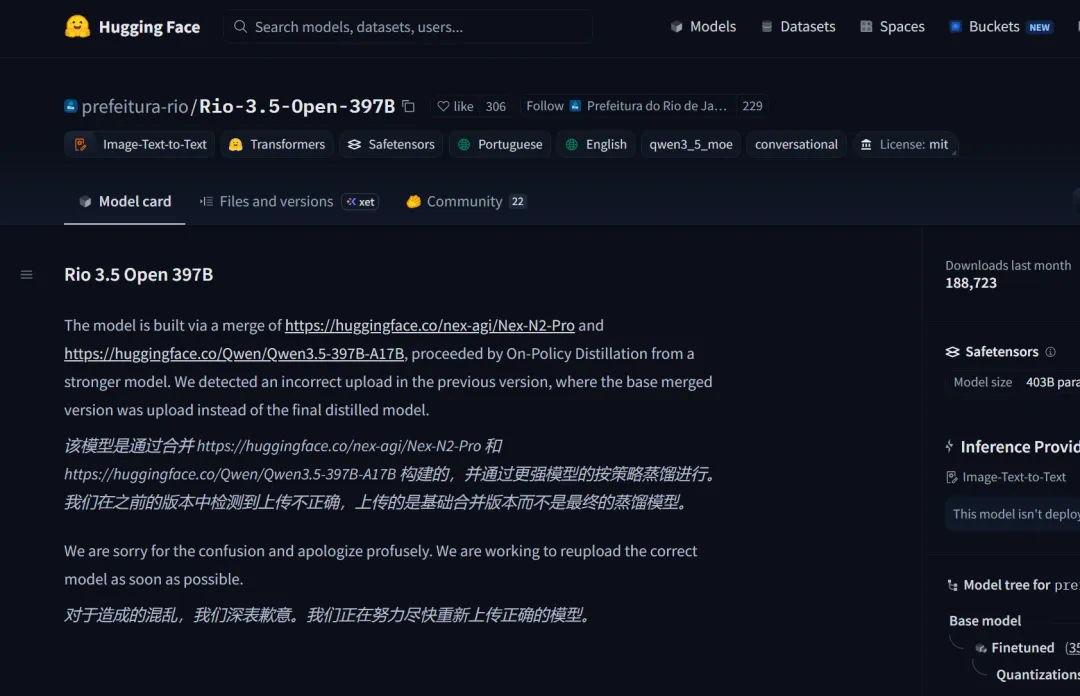
之前那個被下載了11萬次的checkpoint也被刪了。
同時還鬧內訌了似乎。。。
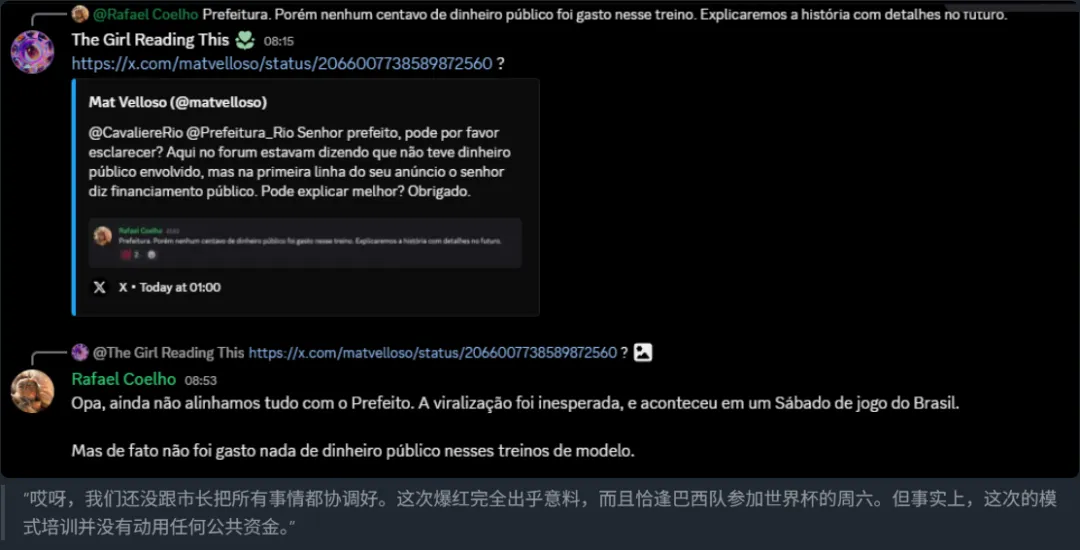
看起來像是個較爲體面的收場,但你細品他們那句話,“錯誤的版本被上傳了”,意思是正確的版本應該是經過蒸餾的,,,可即便真做了蒸餾,基座還是Nex加Qwen啊?
而且,如果一開始就心裏坦蕩,爲什麼模型卡里要硬編碼“你是Rio”,而不是直接告訴用戶這個模型是基於Nex和Qwen合併的呢?
這就是開源社區最敏感的那根神經,歸屬(attribution)。

技術上,把兩個開源模型合併是完全合理合法的——Nex是Apache 2.0,Qwen也是開放許可,你想怎麼用就怎麼用,沒有任何人會去告你,但開源社區有一條不成文的底線,就是你用了什麼,就要明說。
藏起來當原創發,那就不是技術問題,是信用問題。
這次格外刺眼的地方在於,背後是里約市政府,一個市級行政機構,藉着世界盃的氛圍,宣稱自己實現了公共部門的AI主權,市長親自下場背書,結果扒開一看,主權主體是上海創智學院和阿里,這就不是一般的小團隊套殼可以類比的。
不過話說回來,國產模型被套殼被借鑑等,真不是頭一回了。
例如今年三月,日本樂天集團宣稱自己研發了全世界第一個針對日語的大模型,再各方面也是都達到了開源SOTA,結果被人發現是基於 DeepSeekV3 微調而來:

往前三個月,今年3月,AI編程工具Cursor發佈自研代碼模型Composer 2,宣稱性能超越Claude Opus 4.6,價格只要競品的十分之一!
結果發佈不到24小時,就有開發者在調試API時發現請求路徑裏出現了kimi的字樣。
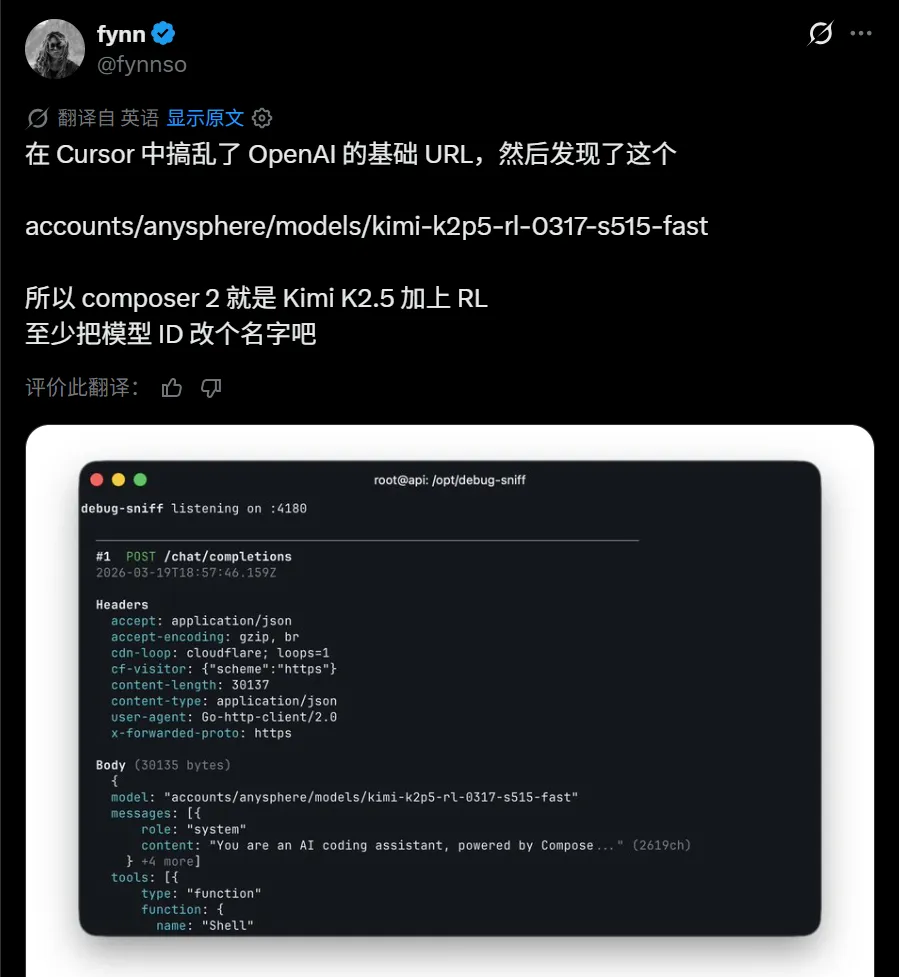
Cursor第一反應是封掉那條調試路徑,但馬斯克親自在社交平臺點名確認,Cursor才被迫承認“疏忽”並道歉,月之暗面後來證實,雙方確實通過Fireworks AI有合作,Cursor確實在用Kimi,但發佈時隻字未提,還裝作自研。
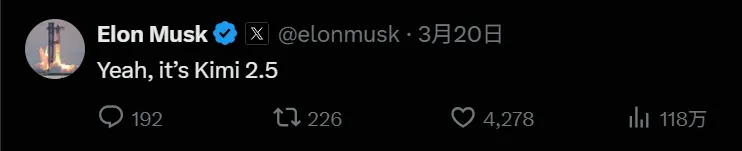
不過這個吧,嚴格說算不上抄襲,畢竟背後真有授權合作,只是發佈時瞞着沒說。
再往前,2024年,一個斯坦福AI團隊高調宣稱,只要500美元就能訓練出超越GPT-4V的多模態模型Llama3-V,迅速衝上了HuggingFace首頁。
結果很快被人扒出來,它的代碼和權重跟清華和麪壁智能聯合發佈的MiniCPM-Llama3-V 2.5幾乎一模一樣,連變量名都沒改完。
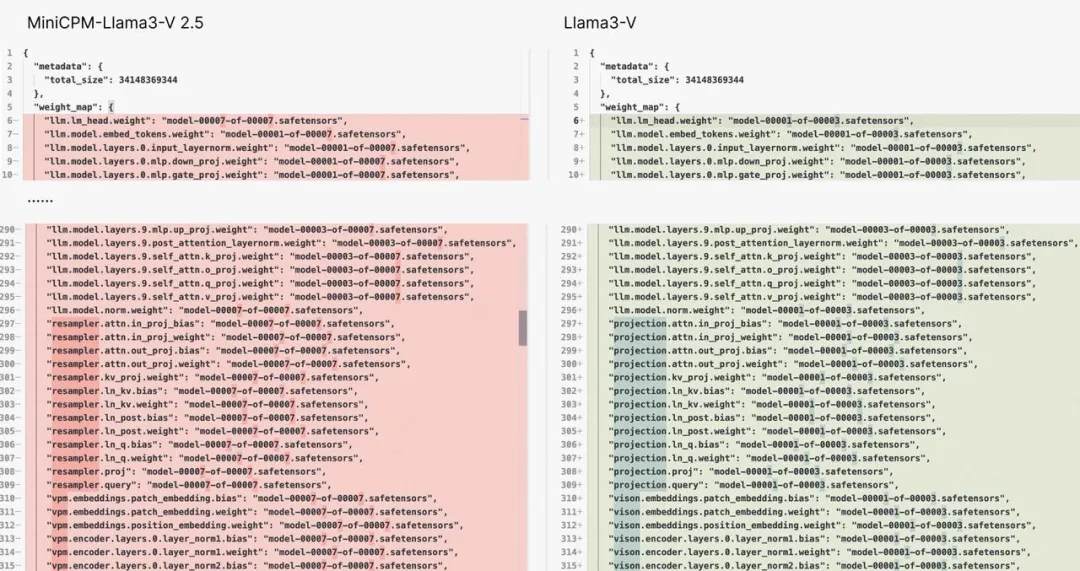
最離譜的是,面壁團隊曾悄悄給MiniCPM訓練過識別「清華簡」的能力,數據是他們自己逐字掃描標註的,從沒對外公開,結果Llama3-V不僅能識別清華簡,連答錯題的方式和MiniCPM都一模一樣。

後來團隊刪評論刪倉庫,輿論壓不住了才發道歉聲明。
從樂天、斯坦福、Cursor、再到里約市,高校、企業、甚至官方背景機構,過去這一年都不約而同地走向了“套殼國產”這條路。
至於是哪國產?欸這你別問。
前幾年大家還在感嘆國內的AI落後OpenAI多少個身位,怎麼轉眼之間,國產開源大模型已經成了全球套殼的首選基座。
DeepSeek、Qwen、Kimi、GLM、Nex,這些名字在國際開源社區的下載榜上排得越來越靠前。。。能被套殼,其實反而是技術實力的一種反向背書,畢竟沒人會去抄一個不好的模型。
Nex團隊在X上的態度也很有意思,他們說 “我們對里約市使用我們的工作來實現SOTA性能感到榮幸,但在開源世界裏,歸屬很重要。”
至於Rio團隊承諾重新上傳的“正確版本”什麼時候上,上來之後是不是真的做了蒸餾,還是隻是把系統提示詞改得更嚴一些,社區估計還會有人盯着繼續看。
到那時候,里約這塊招牌,是真能掛起來,還是又得撤下來,就看這一次了。
而作爲看着國產模型一步步從被嘲笑“套殼OpenAI”走到今天“被套殼”的各位,我覺得這種感覺確實挺有趣的。
雖然是被抄了一把,但反過來想想,這也說明了一件事。
咱們的開源AI,也是屹立於世界模型之林了。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















