很多開發者做Agent項目時,最痛苦的一件事就是模型“越跑越蠢”。
前面幾十輪還挺聰明,工具調用也算穩。
跑上個幾十上百輪以後,模型就開始胡說八道、重複錯誤、直接擺爛。

上下文再長一點,性能直接雪崩。
以前大家只能苦笑:大模型天生就這樣,長時序任務就是它的死穴。之前我們還寫過一篇文章來講這個事情 AI 聊兩句就翻車?性能暴跌 39%!別再難爲它了。
但是現在,智譜把這個問題給幹掉了。
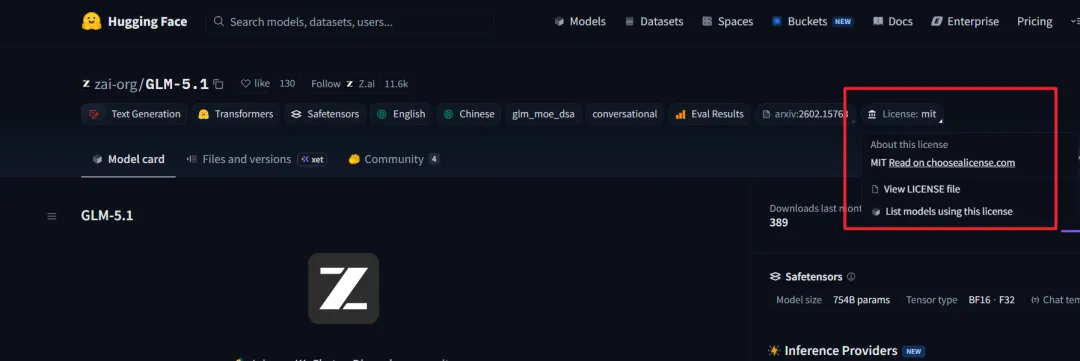
4月8日,也就是今天,智譜正式開源GLM-5.1,這是GLM-5系列的升級版,完全MIT協議,權重已經同步上線Hugging Face和ModelScope。
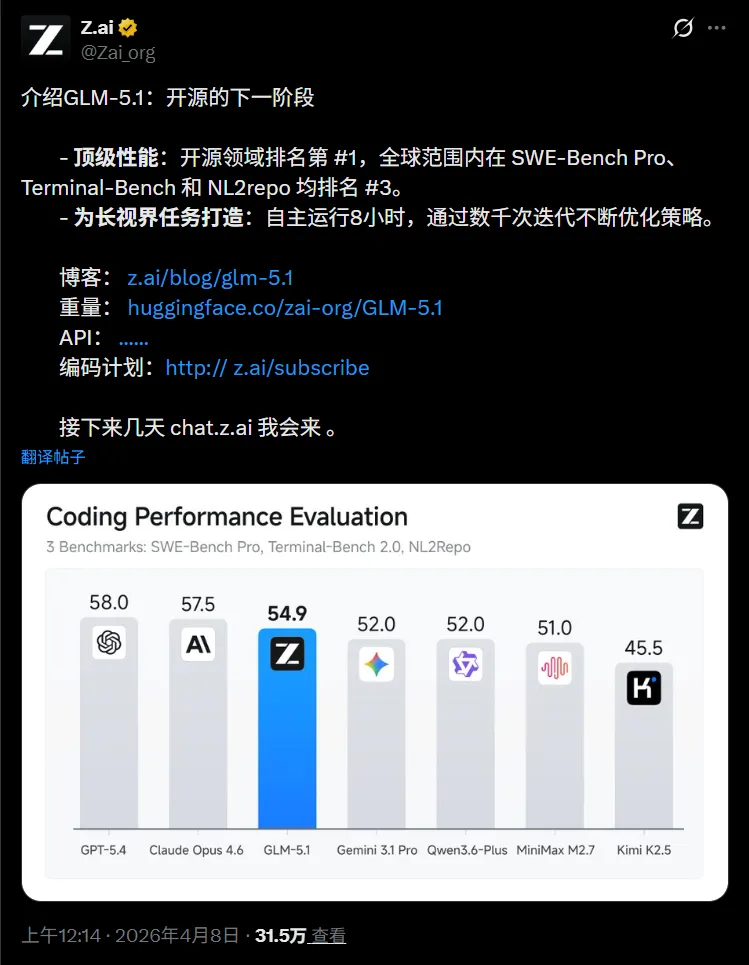
想本地部署?vLLM、SGLang直接拉取就行,商用也完全沒限制。
官方給它的定位非常明確:專爲長時序Agentic任務設計。

這話不是隨便說的。
GLM-5.1能在600多輪迭代、6000多次工具調用裏持續優化,幾乎不出現性能平臺期。
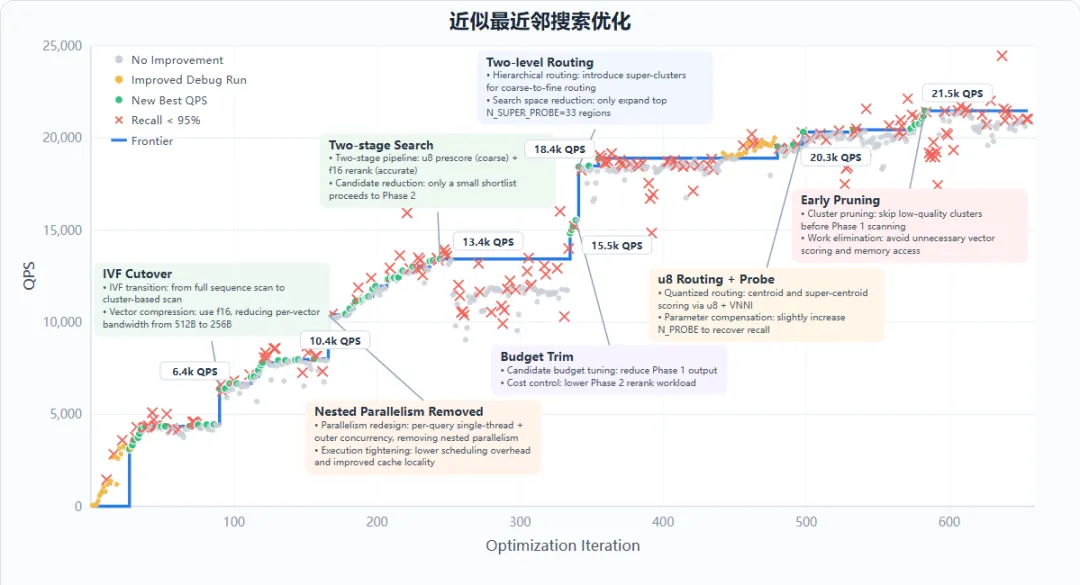
同時,在複雜編程、智能體工程、網絡安全、工具調用等這些場景,它的表現直接拉到新高度。
基準數據部分, GLM 5.1 則再一次展現出其實力。
SWE-Bench Pro拿到58.4分,高於GLM-5的55.1、GPT-5.4的57.7和Claude Opus的57.3。
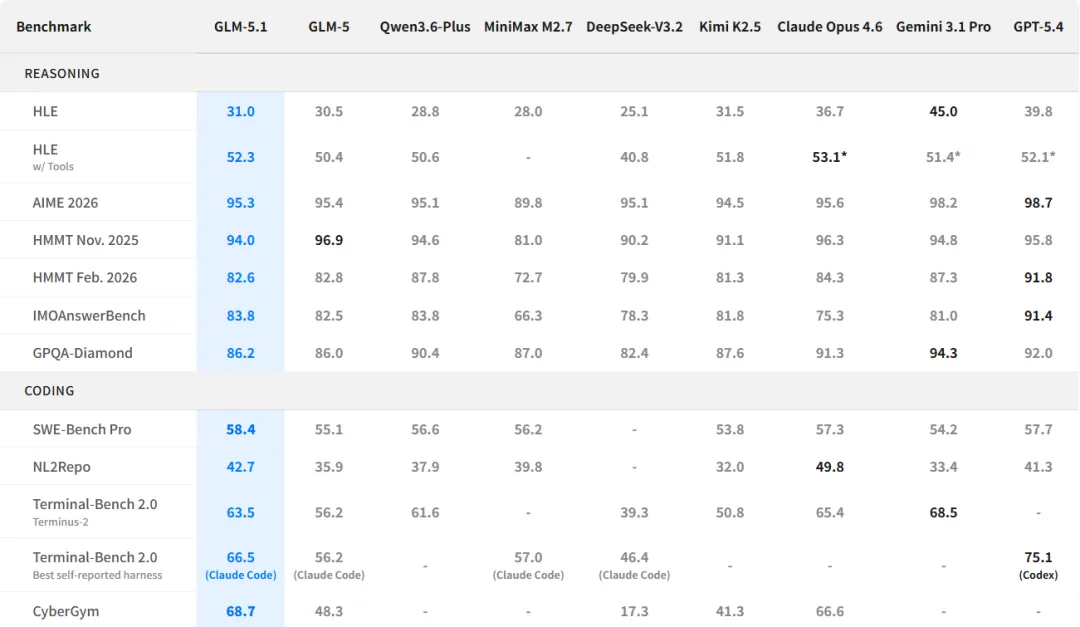
Terminal-Bench 2.0是63.5,CyberGym直接68.7,比上一代提升了20多分。

上下文窗口更是誇張,最大生成長度163840 tokens,帶工具調用時能到202752 tokens。

這意味着什麼?
正如前面我們提到的,以前跑長週期 Agent,模型對話次數一長,上下文一多,性能就開始雪崩。
現在,GLM-5.1能穩定跑到600輪以上,依然保持高水準。
那麼開發者終於可以放心地把一些相對複雜工程任務、長期運維Agent、甚至網絡安全紅藍對抗任務交給它。
在其官方示例中,還展示了使用 GLM 5.1 花費8小時從零構建一個Linux桌面環境。
同時,更重要的是,這次是完全開源、MIT協議。
這意味着不管你是個人開發者、小團隊,還是企業,都可以隨便商用、修改、二次開發,不用擔心後面被收割,這比很多 Apache/GPL 許可證開源的大模型來得更加實在(當然這並不是在說這些就不好)。
如果把長時序不退化、能力強、完全開源、性價比高這幾點放在一起看,GLM-5.1很有希望成爲當前一段時間內最好的 OpenClaw 底座模型。

以前大家做複雜Agent時,總要在閉源大模型和本地部署之間糾結,但現在GLM-5.1直接把這個選擇題變成了多選題,且答案還是很香的。
GLM-5.1的出現,把國產開源模型在長時序Agent領域的能力直接拉到新高度。
開源AI的競爭越來越卷,但卷的方向也越來越務實:不止參數提升,於實際工程裏的痛點,也在被逐一解決。
GLM-5.1這一步,走得很實在,,以後做長時序Agent項目,應該會舒服很多。
希望後面有更多國產開源模型繼續往這個方向卷,把“跑得越久越強”變成行業標配。

那樣的話,普通開發者手裏能用的Agent底座就會越來越靠譜,整個生態也會真正熱鬧起來。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















