聖何塞McEnery會議中心的GTC 2026開幕式上,已經進行了2小時直播的黃仁勳依然經歷旺盛,快步走向被受矚目的GTC 2026 Keynote主舞臺,開啓了長達2個半小時的開幕演講。此刻NVIDIA關於AI的訂單量,已經從2025年的5000億美元,來到了現在的萬億級美元,近乎翻倍的增長也預示了未來一段時間,這家專注生產AI工具的公司,將如何構建未來AI市場的走向。

現在不妨讓我們花點篇幅,一起聊聊在將近2個半小時的GTC 2026開場Keynote中,黃仁勳說了什麼。
Token就是一切
當“I AM AI”主題變成Token,行業對AI的最終需求變得簡單直接。黃仁勳表示,在過去2年中,AI經歷了三次範式轉移,導致計算需求呈指數級爆發。即:
2023年前後的ChatGPT時刻。AI從"感知理解"升級到"翻譯生成",能夠創造獨特內容;
2023年到2024年的OpenAI o1時刻。推理AI誕生,AI學會"反思、思考、自我對話、規劃",將問題分解爲可理解的步驟,基於研究事實進行 grounded truth 推理;
最後是當下的Claude Code時刻。AI Agent智能體出現,AI能夠閱讀文件、編寫代碼、編譯測試、評估迭代,完成實際的工程任務。
三個關鍵範式轉移,導致所有的算力數字井噴爆發。推理和代理任務使單任務計算需求增加約 1萬倍,AI應用增長超過100倍,過去兩年總計算需求增加約100萬倍。數據中心也因此由傳統的數據存儲倉庫,變成AI工廠。
黃仁勳將AI工廠稱爲Token工廠(Token Factory),未來每一家企業實際上運營的一個由Token驅動的數據工廠。每個AI工廠由於受限於物理電力,會把Token打包成不同的商品,按照質量、速度分層進行定價。例如免費的Token用低速提供基礎問答,高階的Token服務可以完成極速推理和複雜研究。

這時候AI工廠收入將會從兩個緯度進行平衡,即使吞吐量(Throughput),每瓦特電力產生的Token數量;智能度(Intelligence),指Token生成速度。這裏黃仁勳引用Grace Blackwell作爲參考,相比Hopper架構,Blackwell在免費層提升吞吐量35倍,對於高價值的編碼、工程推理,性能則可以提升35倍以上。
NVIDIA將2025年稱爲推理之年,推理是AI計算的終極難點,它將直接決定公司的收入。而推理與訓練是由本質區別的。訓練是一次性大規模計算,追求峯值算力。推理是持續性、低延遲、高併發服務,追求每美元Token成本和每瓦特Token產出。
爲實現極致推理效率,NVIDIA開發了Dynamo AI工廠操作系統,能夠輕鬆在Vera Rubin和Groq之間智能調度任務,支持萬億參數模型的KV Cache管理和多層級服務品質(QoS)的混合部署。
有意思的是,Token也延伸出新的經濟學和企業預算科目,未來每家企業都同時是Token消費者和Token製造商,這意味着企業即自己消耗Token,同時也通過Token對外提供服務。
Token也帶來了計算範式的根本轉變,舊範式的檢索式計算本質上是存儲已有信息,按需調用,通過數據庫查詢、文件系統、網頁瀏覽來實現。AI新範式則是直接生成答案而非檢索,每次查詢都涉及實時推理、合成、創造,這解釋了爲何計算需求呈百萬倍增長,AI不是在查找信息,而是在思考答案。
面對萬億美元級別的AI基礎設施投資,黃仁勳強調NVIDIA架構的核心優勢在於,NVIDIA是唯一支持AI全生命週期(訓練、後訓練、推理)的平臺,同時NVIDIA也是唯一同時支持語言、生物學、計算機圖形、物理仿真、機器人等多模態AI的架構的公司。
Vera Rubin架構:下一代AI基礎設施
接下來就是黃仁勳的帶貨環節。Vera Rubin並非簡單的芯片升級,而是針對Agentic AI工作負載的端到端系統重構。黃仁勳強調,傳統數據中心架構已無法滿足AI代理的需求,Agentic AI的三大系統壓力,包括思考計算(Thinking)、內存牆(Memory Wall)和工具(Tool)的使用問題。
新生的AI應用帶來了大語言模型規模持續膨脹,進而需要生成更多Token,這對算力有很高的要求。KV Cache、結構化數據(cuDF)、非結構化數據(cuVS)對存儲系統則是對內存牆產生了絕大的壓力。與此同時,AI需要以極快速度訪問工具,包括瀏覽器、虛擬PC、數據庫等等,合適的工具也同等重要。
Vera Rubin厲害的地方在於,將計算、內存、網絡、冷卻、供電整合爲單一巨型系統,通過端到端協同優化實現物理極限性能,以解決傳統數據中心架構無法滿足Agentic AI系統範式所帶來的壓力。
目前Agentic AI的系統壓力可以分成三個:
思考計算(Thinking):大語言模型規模持續膨脹,需要生成更多Token且速度更快;
內存牆(Memory Wall):KV Cache、結構化數據cuDF、非結構化數據cuVS對存儲系統造成了成噸的壓力;
工具使用(Tool Use):AI需要以極快速度訪問工具,包括瀏覽器、虛擬PC、數據庫等場景。AI應用場景中,工具越快的被調用,體驗就越好。
順帶一提,Agentic AI雖然也可以翻譯成智能體AI或者代理式AI,但與PC端的AI智能體小龍蝦不同,前者爲AI系統架構,後者爲具體的落地應用。
Vera Rubin單一巨型系統,即第六代NVLink 72使用了100%的45℃溫水液冷設計,通過冷卻液直接將熱量帶走,無需複雜的空調系統設計。同時由於省略的銅纜設計,通過預配置連接,服務器的安裝時間從2天壓縮到了2小時。
與之前Grace Hopper一樣,Vera爲專用CPU的代號,這是NVIDIA首次推出專爲AI優化的數據中心CPU,也是全球唯一使用LPDDR5內存的數據中心CPU,在低功耗表現上會亮眼很多。通過提升CPU單線程性能,AI工具也能獲得更快的響應速度,配合超高I/O帶寬,處理AI Agent智能體的頻繁數據訪問請求也更爲輕鬆。
當然搭配72個 Vera Rubin,並非NVLink 72的極限。通過Spectrum-X共封裝光學(CPO)交換機設計,將光學器件直接封裝在交換機芯片上,電子信號直接轉換成光信號,無需外部光模塊,同時也可以將NVLink擴展至576個GPU,即NVLink 576。
一旦涉及海量GPU部署,一套合適的機架就顯得相當重要了。相對於標準的Vera Rubin只需要傳統的水平劃入式機架,雙GPU組合的Vera Rubin Ultra需要Kyber機架支持,GPU會垂直插入,最多支持144個GPU,從而實現單域NVLink 144。
再多的Rubin GPU,這套AI超算還是有物理極限的。特別是當AI服務需要超高頻Token生成完成實時編碼、高頻交易或者交互式AI的時候,GPU架構本身並不能完成低延遲解碼,這是大規模並行架構本身缺陷決定的。這時候就需要專門優化單線程Token生成速度作爲確定性數據流架構彌補空缺,Groq應運而生。
Groq團隊屬於谷歌TPU團隊離職後的二次創業,雖然名義上是獨立運作公司,但目前通過NVIDIA資產收購和人才收購,在2025年末實現了與NVIDIA深度綁定。

Vera Rubin成爲了首個融入Groq並實現任務解耦的平臺。Rubin負責預處理、Attention計算和KV Cache存儲任務,適合高吞吐矩陣計算和大容量HBM內存環境使用。Groq負責Decode Token生成、低延遲推理,在確定性數據流、超大SRAM和靜態編譯調度中使用。NVIDIA會通過Dynamo操作系統對兩者進行調度。
Groq的靜態編譯調度消除了GPU的動態開銷,也很好的突破了內存牆,突破萬億參數模型的物理限制,通過Groq的存儲模型權重,用SRAM完成權重的快速訪問。這樣的收益是非常明顯的,相比純Rubin GPU計算,Groq加入之後可以獲得35倍的性能提升。通過專用的以太網絡,兩者的協同延遲可以降低50%。
在部署策略上,黃仁勳建議AI工廠可以考慮75%爲Vera Rubin用來處理高吞吐工作負載,剩下的25%爲Groq,用來處理高價值、低延遲任務。Groq加入是NVIDIA從訓練、吞吐轉向全Spectrum推理的關鍵一步,無論是經濟、技術還是系統層面,都是非常重要的。目前Groq LP30由三星代工打造,在2026Q3就會大規模出貨。與此同時,Groq LP40也已經在NVIDIA參與下開發,下一代Feynman架構將由GPU、Groq LP40、Rosa CPU、Blue Field DPU和CX10存儲平臺實現,並同時支持銅纜擴展和共封裝光學擴展,從而實現NVLink 144和NVLink 576大規模GPU集羣擴展。

黃仁勳表示,目前NVIDIA已經能夠支持萬億美元級基礎設施的供應鏈,每週可生產數千個機架系統,相當於每月可以生產出數個GigaWatts級別功耗的AI工廠,GB300機架還能與Vera Rubin機架並行生產,可根據供需調整,相互之間不會因此影響產能。
從數字到物理世界
黃仁勳明確講AI智能體(AI Agent)分成了兩種形態,一種是數字智能體(Digital Agents),在數字世界中感知、推理和行動,比如編寫代碼、處理數據;另一種是物理智能體(Physical Agents),也就是機器人在物理世界中感知、推理和行動。
後者的物理AI(Physical AI)需要理解物理定律,比如重力、摩擦力、材料特性等等。因此物理AI需要處理真實世界的海量多樣性、不可預測性和邊緣情況,這是在虛擬世界不存在的不確定因素。海量的物理特性不可能僅依靠真實數據訓練,必須依賴合成數據生成和高保真仿真,這也是物理AI的核心。

目前NVIDIA已經爲機器人產業構建了完整的端到端基礎設施,包括負責訓練計算的NVIDIA DGX、Cosmos世界模型;負責合成數據生成與仿真的Isaac Lab、Omniverse;以及機器人嵌入式Jetson Thor,實現機器人內部的實時推理。
這時候自動駕駛成爲了物理AI的首個大規模落地場景。NVIDIA與Robotaxi-Ready平臺合作,在比亞迪、日產、捷豹路虎、本次、豐田、通用幫助下,現在已經具備每年生產1800萬輛Robotaxi的能力,通過與Uber合作,可以將多個城市的出租車網絡接入其中,快速構建一套適合自動駕駛物理AI的應用場景。
在現場,黃仁勳展示了通過NVIDIA Alvin解釋車輛自動駕駛過程中的決策過程,讓自動駕駛變得更有邏輯可言。在CES2026上,這套運作方式已經成功讓奔馳測試車型輕鬆穿梭在舊金山的都市街道中。
自動駕駛僅是其中之一。在工業機器人和製造業領域,物理AI能夠涵蓋ABB、卡特彼勒這樣的種公羊,在富士康這樣的電子製造行業中,通過Isaac Lab微調GROOT模型用於產線,或者使用Isaac Lab進行訓練和數據生成,亦或者使用Isaac Lab和Cosmos生成手術室輔助機器人訓練數據,讓醫療機器人成爲可能。
物理AI甚至可以通過仿真平臺解決數據難題,因爲真實世界數據永遠無法覆蓋所有場景,AI生成數據+物理仿真到時有機會解決這一點。
因此NVIDIA構建了三項技術給物理AI提供支持,即Isaac Lab、Cosmos 世界模型和GR00T 開放機器人基礎模型。
Isaac Lab是一套開源、可擴展、GPU加速的可微分物理仿真平臺,開發者可預訓練世界基礎模型,使用互聯網規模視頻和人類演示,Isaac Lab本身也支持經典仿真和神經仿真混合使用,能夠與Cosmos世界模型和很好的融合,最終生成大規模合成數據和訓練策略。
Cosmos 世界模型則用於神經仿真(Neural Simulation),生成符合物理規律的虛擬環境,用於替代傳統基於規則的物理引擎,AI學習物理世界的內在規律。
GR00T則是開放的機器人推理與動作生成模型,類似LLM的功能,負責理解指令、規劃動作、控制執行。這是NVIDIA推出的全球首個開放式人形機器人基礎模型(Foundation Model),旨在爲通用人形機器人提供推理和控制能力,被黃仁勳稱爲"機器人領域的ChatGPT時刻"。
本質上,GR00T是一個視覺-語言-動作(VLA)模型,能夠理解自然語言指令、感知視覺環境,並生成精確的機器人動作。其架構設計靈感源自人類認知的雙系統理論,系統一爲快速動作模型,負責直覺式的反應和實時控制,系統二爲慢速推理模型,基於視覺語言模型(VLM)進行深思熟慮的決策。模型通過擴散變換器(Diffusion Transformer)頭部對連續動作進行降噪處理,將高層指令轉化爲低層機械控制信號。
在2025年3月份,NVIDIA發佈了首個版本GR00T N1,目前版本是GR00T N1.7,並計劃在今年底升級到GR00T N2。GR00T通過結合多種數據來源以解決真實機器人數據稀缺的問題,同時能夠加入陣營中的機器人數量越多自然越好。在GTC 2026現場展示了110款對應的機器人,涵蓋了全球範圍內的所有主要機器人制造商。同時也包括了人形機器人、工業機器人臂、自主移動機器人和迪士尼娛樂機器人。
迪士尼娛樂機器人自然是最令人深刻的,與之前展示R2D2不同,這一次NVIDIA展示了與與迪士尼合作的Olaf雪寶。這是一套完全在NVIDIA Omniverse中使用Newton物理求解器訓練出來的機器人,機器人通過物理仿真學習行走,然後零樣本遷移到真實世界。同時由於基於物理的仿真,Olaf能適應真實世界的物理特性。NVIDIA Omniverse雖然銷量不及預期,但從目前來看,依然是NVIDIA希望推動的重點產品之一。
構建開放模型
黃仁勳在現場闡述了NVIDIA一套獨特的雙軌制AI策略,在在垂直整合硬件基礎設施的同時,AI模型是水平開放的,各行各業都可以基於開放模型微調,構建符合本地數據隱私和文化背景的專屬AI,NVIDIA目標仍然是賣出更多的硬件,而非在AI模型上構建壁壘。
爲此,NVIDIA發佈了一系列特定的開放模型,包括通用推理與語言模型Nemotron 3,物理世界仿真Cosmos 2,生物化學與分子設計BioNIMO,以及用於氣候與天氣預測的Earth 2。
目前Nemotron 3已經在關鍵基準測試中達到世界頂尖水平,擅長的領域包括研究推理、語音模型、世界模型以及通用機器人和自動駕駛推理。同時Nemotron 3分成三個版本,包括基礎版的Nemotron 3,面向超大規模應用的Nemotron 3 Ultra,以及與AI Agent框架真整合的Nemotron 3 OpenClaw版。
這裏黃仁勳盛讚了OpenClaw龍蝦對計算機史帶來的里程碑的轉變,僅發佈的幾周內就達到了Linux 30年才能獲得成就,並且已經比肩HTML和Linux開源軟件成爲同等重要的基礎設施級軟件。通過簡單命令行即可下載、構建、部署AI智能體,並且可靈活添加工具、數據源和自定義能力,也可以與NVIDIA硬件和軟件棧深度優化。
針對AI工廠,NVIDIA還推出了名爲NVIDIA NeMo雲框架,這是一套融合了硬件層、庫與工具層以及生態集成層的架構,包含了Vera Rubin架構的優化部署,cuDF、cuVS加速庫,以及Dynamo推理操作系統。通過對Vera Rubin的優化,這套方式可以更好的確保Token生成效率,並支持機密計算,確保模型與數據安全。
黃仁勳認爲,Token已成爲硅谷人才競爭的核心籌碼,並且企業也將扮演Token消費者和製造者,不僅爲員工購買AI算力提升生產力,同時也產生Token對外提供服務。AI智能體將扮演企業級IT轉型,原本供人使用的工具將被特定領域的專業化智能體替代。AI智能體像雲服務API那般被租賃。
企業計算與數據平臺重構
數據類型可以分成結構化數據和非結構化數據。黃仁勳認爲這兩類企業數據資產在AI時代都將被重構。結構化數據是業務運營的基礎,傳統CPU數據處理系統已無法跟上AI智能體的訪問速度,NVIDIA cuDF(CUDA Data Frames)無疑是利用GPU加速結構化數據庫處理的理想解決方案。
同樣,非結構化數據現在已經佔據全球年生成數據的90%,但幾乎無法被有效利用,原因是缺乏索引機制,必須理解含義和目的才能查詢。NVIDIA給出的解決方案是利用NVIDIA cuVS(CUDA Vector Search)GPU加速的語義向量搜索庫,從而完成對非結構化數據的處理。簡單的說,cuDF與cuVS構建了NVIDIA對結構化數據和非結構化數據兩套GPU加速的組合拳。
其中cuDF進行的結構化數據AI加速擅長企業ERP、供應鏈、財務數據的實時分析,與IBM合作案例顯示5倍速度提升,83%成本降低。cuVS非結構化數據檢索用於PDF文檔理解、視頻內容檢索、語音轉文本分析,將非結構化數據嵌入爲高維向量,支持快速語義相似性搜索。
cuDF與cuVS目前已經在IBM、DELL、Google Cloud、亞馬遜雲、Microsoft Azure、Oracle、CoreWeave、Telstra + Dell等企業中展開應用。AI時代下,傳統的檢索式將被生成式替代,數據訪問本身是新內容的生產,並由AI智能體與人類進行交互,圍繞GPU加速構建的計算框架,成本不會收到摩爾定律影響,而是隨着加速計算得到不斷優化。
金融服務、醫療保健、零售業與安全計算很快就會率先受到影響,通過cuDF和cuVS兩大基礎庫,NVIDIA正在將傳統上由CPU主導的數據處理(佔企業IT支出的核心部分)遷移到GPU加速架構,實現結構化與非結構化數據的統一AI化訪問,標誌着企業IT從檢索式工具使用向生成式智能體的範式轉移,這不僅是技術升級,更是涉及萬億美元IT支出的產業重構。
寫在最後:構建全新的生態與行業
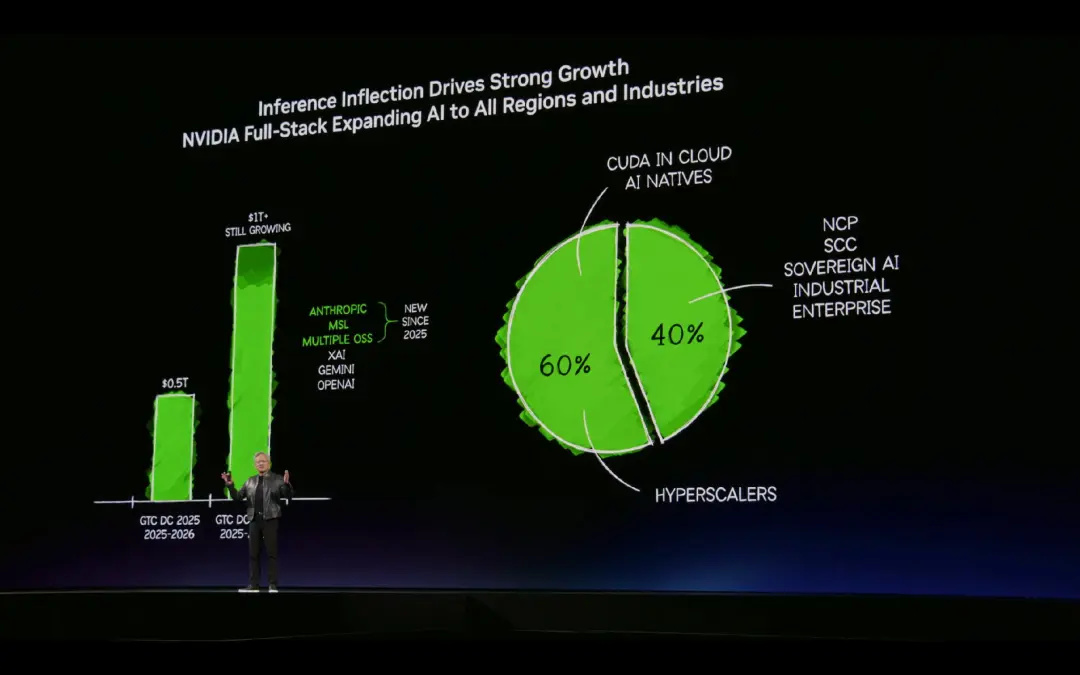
黃仁勳表示,目前NVIDIA業務已經呈現出了雙金字塔結構,其中60%來自超大規模雲服務商,推薦系統從傳統表格和協同過濾開始轉向深度學習大模型,傳統搜索則開始轉向深度學習大模型,同時基於NVIDIA生態構建出來的原生AI公司也越來越多。
另外40%來自多樣化的長尾市場,應用場景遍佈工業機器人、邊緣計算、超算、小型服務器。AI不是單一應用的技術,而是跨行業的基礎設施。
同時黃仁勳也強調了CUDA的二十年生態帶來的飛輪效應,從便於部署到算法突破,加速了整個生態系統的正向循環。基於CUDA生態的硬件幾乎應用於每個雲平臺、每個計算機公司、每個行業,軟件資產包含數十萬公開項目,數千工具、編譯器、框架和庫。從臺積電芯片製造商,到服務器OEM、再到雲服務商和AI應用公司,哪怕是擁有150年曆史的公司,在全新的AI浪潮中也創造了全新的營收紀錄,足以見得AI對行業的重要性。
隨着行業的垂直程度加深,數萬億美元的產業將會迎來重構。比如金融服務的量化交易從人工特徵工程、經典機器學習轉向超算自動發現數據模式;醫療保健通過AI完成新藥物發現、診斷代理、客戶服務,藥物分子模擬變得輕而易舉。
NVIDIA深耕十年的製造業與機器人行業,現在也正在邁向訓練、仿真、邊緣計算的體系,NVIDIA已經與幾乎全球機器人展開了合作,GTC2026現場的110個機器人就是很好的例子。在零售端,AI可以很好的完成供應鏈優化、購物系統、客服支持,NVIDIA構建了一套完整的端到端智能零售技術棧。
在電信領域,基站從單一信號傳輸轉向AI基礎設施平臺,基站將成爲機器人化無線電塔,將具備推理和自適應能力,目前NVIDIA合作伙伴諾基亞、T-Mobile已經率先展開部署。最後是媒體、娛樂和遊戲,AI已經被應用於直播翻譯、廣播支持、實時遊戲增強。RTX、Holoscan用於實時視頻處理。
基於AI的原生企業開始迎來自己的高光時刻,AI初創公司的風險投資歷史性爆發,現在已經出現了從百萬到十億級美元的投資跨度,每家公司都需要海量計算和Token,要麼自建Token工廠,要麼在現有Token上增值,類似於Google、Amazon、Meta級別的公司很可能在原生AI初創公司中誕生。
這樣的結論並非一拍腦袋得出的,黃仁勳將GTC 2025和GTC 2026訂單規模進行了對比。GTC 2026期間,NVIDIA獲得了5000億美元的訂單規模,而在當下,GTC 2026將帶來上萬億美元的訂單,增長速度翻倍。在未來,AI從訓練轉向推理,每家企業都需要AI工廠,Agentic AI將會提供7x24小時不間斷的推理服務,自動駕駛、機器人等物理世界AI均需要AI邊緣計算作爲基礎設施。
在長達兩個半小時的GTC 2026演講中,黃仁勳展示了一套萬億美元級AI經濟閉環的AI生態系統,從上游芯片供應鏈到下游行業應用,從超大規模雲到主權邊緣部署,從20年曆史的CUDA開發者社區到新興的AI原生獨角獸。NVIDIA不僅成爲AI基礎設施的提供者,更是全球AI產業生態的樞紐節點,其影響已超越單純的技術供應商,正在重塑全球計算產業的經濟結構和權力分佈。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















