在AI計算的浪潮中,AMD正逐步從幕後走向臺前。回想一下,AI加速器市場的核心在於處理海量數據和複雜模型的硬件能力,而NVIDIA長期以來憑藉其GPU架構主導這一領域。但如今,AMD的Instinct MI350系列正以一種務實的姿態加入戰局,通過價格調整和技術迭代,試圖在性能和成本間找到平衡點。

先說說這場價格調整。AMD將Instinct MI350加速器的售價從1.5萬美元提升到2.5萬美元,漲幅達70%。這一變動並非隨意,是基於對市場需求和自身產品實力的評估。即便如此,新價格仍低於NVIDIA的Blackwell B200,後者起步價在3萬美元左右。這意味着AMD在保持性價比優勢的同時,意圖通過更高的定價捕捉更多利潤空間,尤其是在數據中心和雲服務提供商對AI硬件需求爆發的當下。
要理解這一步的底氣,得從MI350的技術規格入手。這個系列基於AMD的CDNA 4架構,使用臺積電3納米工藝製造,主要包括MI350X和MI355X兩款型號。核心亮點在於內存配置:每塊芯片配備288GB HBM3E高速內存,帶寬高達8TB/s。這比前代MI300X的5.2TB/s帶寬提升明顯,也超越了Blackwell B200的192GB內存容量。在處理大型AI模型時,內存大小直接影響能加載的參數規模——MI350能輕鬆應對超過500億參數的模型,而無需過多依賴外部存儲,這在訓練和推理階段都能減少延遲。
計算性能方面,MI350支持多種浮點格式,如FP4、FP6、FP8和FP16。其中,MI355X在FP4格式下的峯值性能可達20.1 PFLOPS,在FP8下爲10.1 PFLOPS。相較之下,Blackwell B200在FP4下的性能約9 PFLOPS。AMD通過Chilplet設計實現了這一躍升:MI350由8個XCD計算芯片和2個I/O芯片組成,總晶體管數達1850億,比MI300X多出21%。每個XCD芯片包含32個計算單元,總計256個單元。這種模塊化結構不僅提升了擴展性,還優化了功耗管理——MI350X的TDP控制在較低水平,適合風冷,而MI355X則推到1400W,支持液冷,以換取更高輸出。
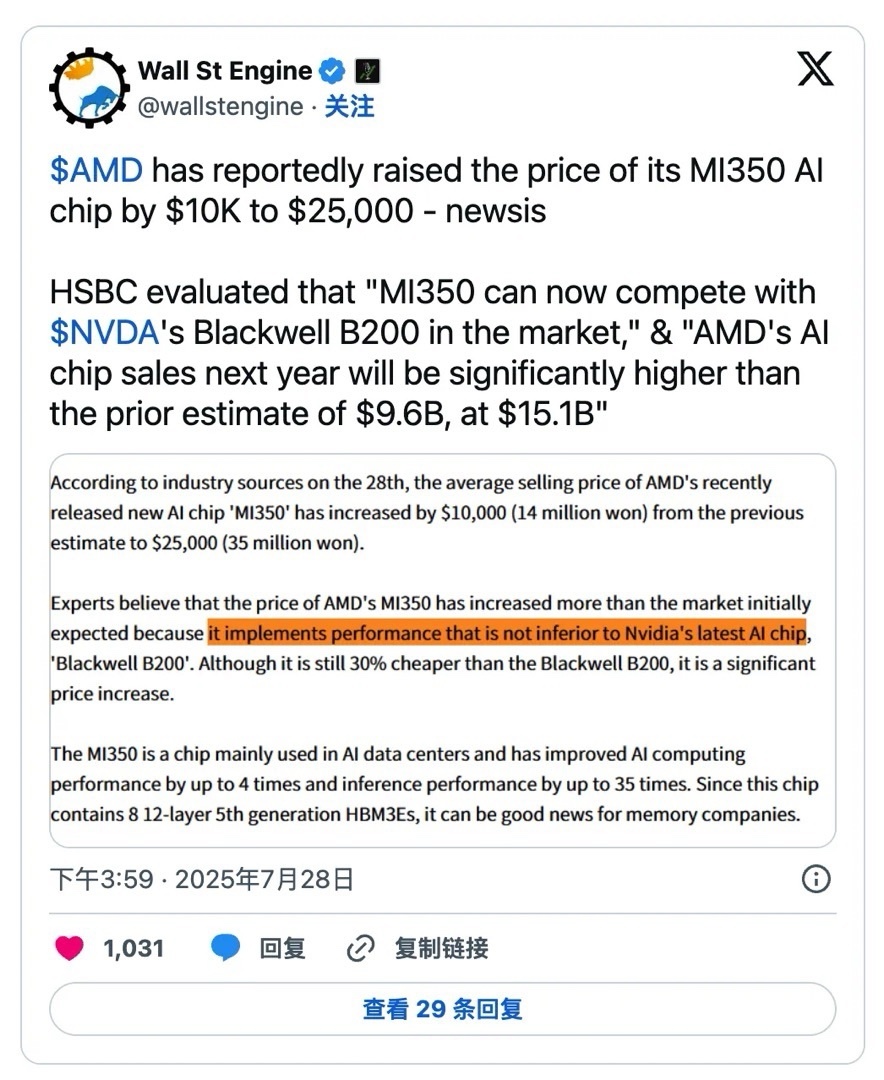
架構上,CDNA 4引入了更高效的Infinity Fabric互連,帶寬升至5.5TB/s,同時降低了總線頻率和電壓,整體能效改善。舉個例子,在Llama 3.1 405B模型的FP4推理任務中,MI355X的吞吐量是MI300X的35倍。在基準測試如DeepSeek R1或Llama 3.3 70B模型上,它與B200和GB200相當,甚至領先3倍左右。這不是空談數據,而是源於AMD對矩陣運算和稀疏處理的優化,確保在實際AI工作負載中表現出色。
當然,硬件只是起點。AMD的軟件生態也在跟進。ROCm 7平臺已全面支持MI350,兼容PyTorch和TensorFlow等框架,並針對分佈式訓練進行了調優。AMD還參與了Ultra Ethernet Consortium和UALink聯盟,推動開放互連標準,這與NVIDIA的封閉NVLink形成對比。這樣的策略吸引了像Meta、微軟和OpenAI這樣的客戶,他們已在數據中心部署MI300X用於模型推理。現在,隨着MI350的到來,這些合作有望擴展。
市場背景不可忽視。全球AI芯片需求預計到2028年將達5000億美元規模,數據中心正爲高性能計算投入巨資。NVIDIA目前佔九成份額,但供應鏈瓶頸——如臺積電的CoWoS封裝產能——限制了Blackwell的交付。AMD抓住這個窗口,加速產品節奏:2024年MI325X,2025年中MI350系列,2026年MI400將引入HBM4內存,帶寬飆至19.6TB/s,直指NVIDIA的Rubin架構。

價格上調的深層含義在於AMD對需求的判斷。AI訓練和推理的成本正成爲企業痛點,而MI350的性價比——比B200便宜30%卻內存更大——適合預算有限的場景。同時,AMD推出Helios機架級解決方案,結合MI350和第五代EPYC CPU,能提供2.6 Exaflops的FP4計算力,適用於超大規模集羣。這不僅僅是賣芯片,而是提供全棧AI基礎設施。
展望未來,隨着模型參數從千億級向萬億級躍進,內存和能效將成爲關鍵戰場。MI350的高內存配置能更好地處理這些巨型模型,而液冷設計則適應高密度數據中心的需求。AMD的開放路徑或許會逐步蠶食NVIDIA的份額,尤其在雲服務和科研領域。當然,挑戰猶存:NVIDIA的CUDA生態根深蒂固,部署經驗更豐富。AMD需持續迭代軟件支持和客戶案例,才能真正站穩腳跟。
這場價格調整標誌着AMD在AI賽道的自信轉折。MI350以紮實的技術基礎,挑戰着市場格局的既有平衡。在計算能力不斷演進的時代,這樣的競爭將推動整個行業向前。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















