前言
就在過去不久的蛇年春節,DeepSeek大語言模型引發了全球熱烈關注,它具備訓練成本低、開源等顯著優勢,直接撼動了OpenAI在AI領域的地位,長期霸榜手機應用榜首的ChatGPT一下子被DeepSeek超越,近幾天甚至有多家央企和科技巨頭紛紛也宣佈接入DeepSeek。不過由於應用過於火爆,官方版本目前最大問題就是間歇性服務器繁忙。
目前不少平臺也接入DeepSeek API了,這可大大分擔了DeepSeek官方的負載壓力,這些平臺有免費使用亦有收費的,部分還需要科學上網。
當然除了官方和第三方API以外,對於絕大數用戶來說,使用PC本地部署蒸餾過後的DeepSeek-R1模型也是值得一試,畢竟一免費二可離線(比如什麼AI貓娘)隱私高(公司剛需)三對話記錄也是永久保存。本文硬核就以RX 7900 XT和RTX 4070 Ti SUPER這兩款顯卡爲例分享一下本地部署的過程,順便可以對比A卡和N卡之間的性能~
LM Studio和Ollama本地部署

即便蒸餾過後DeepSeek-R1的“小模型”依然對於硬件上限要求很高,具體配置和部署教程大家可自行搜尋,各路大神在互聯網上的經驗分享可太多了,本文重點還是測試。硬核這次依舊使用的是LM Studio,它省去了輸入命令的過程,整合圖形UI交互界面,具備硬件協同調試策略,對於NVIDIA、AMD系列GPU和Apple Silicon Mac等硬件都有優化支持,重點是對於新手操作友好。
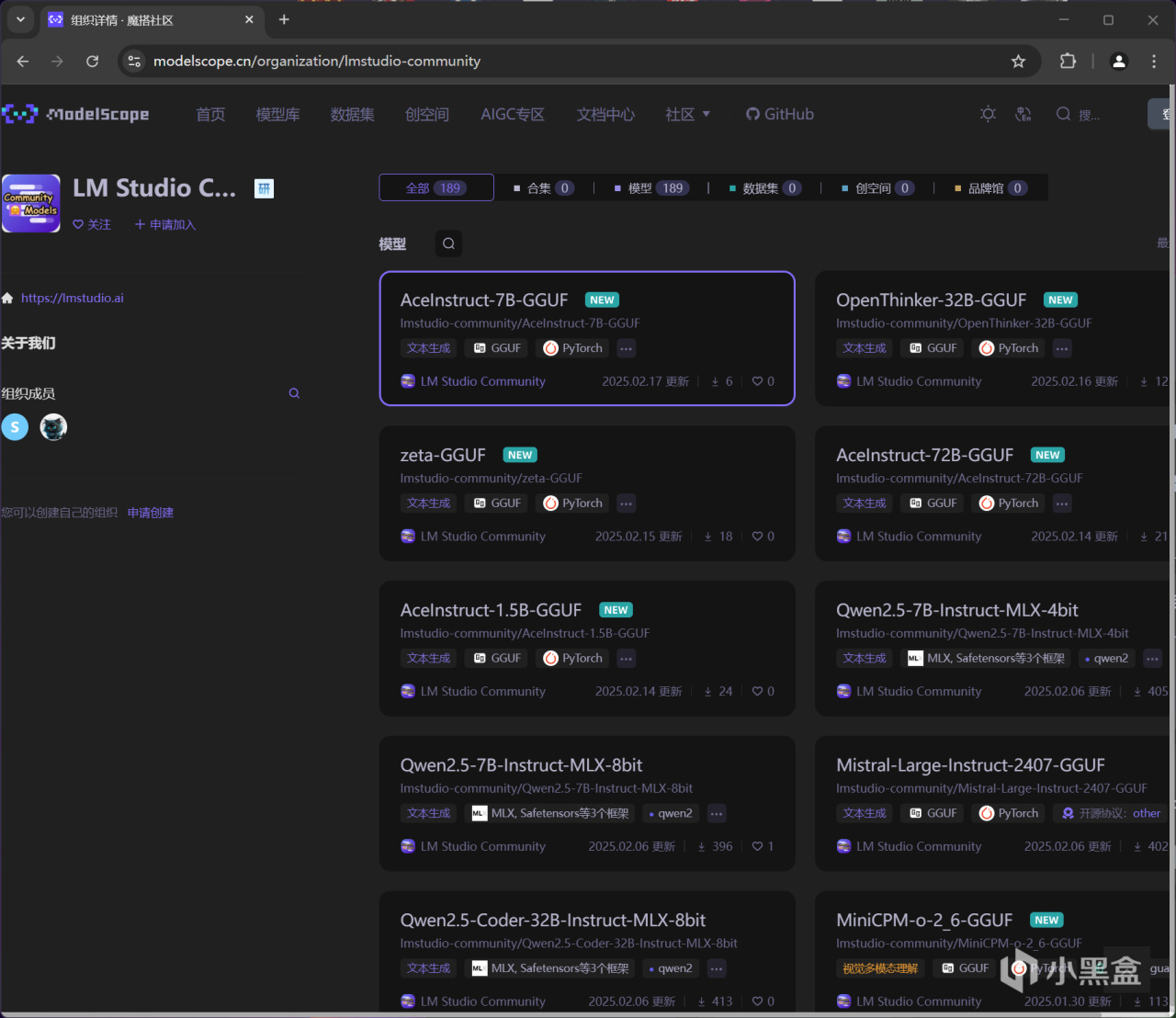
LM Studio內置可直接搜索下載GGUF等格式的大語言模型,不過也需要施加魔法,個人推薦直接到國內的阿里魔搭社區搜尋即可,建議加入LM Studio Community組織以後方便定位,當然你也可以使用一些huggingface鏡像站,但可能模型不太齊全。
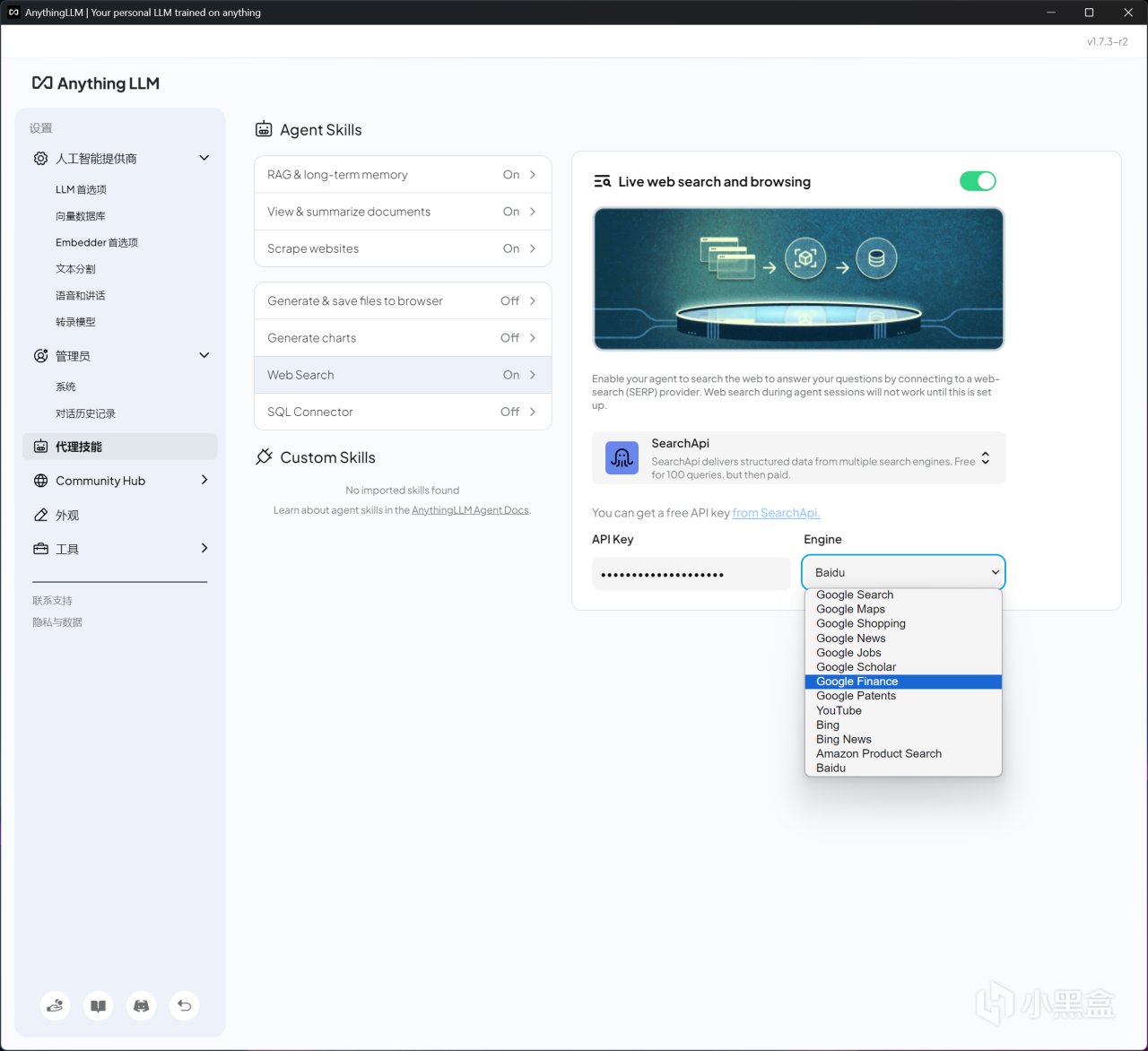
若本地部署之後還想使用聯網搜索功能,LM Studio也可以聯動Anything LLM實現,只需要同時打開這倆軟件,在LM Studio加載好模型後,再將Anything LLM工作區定位至LM Studio,最後設置一下代理技能中的Web Search即可。個人目前使用的是Search API,不需要魔法,也兼容各種搜索引擎,不過免費使用次數只有100。
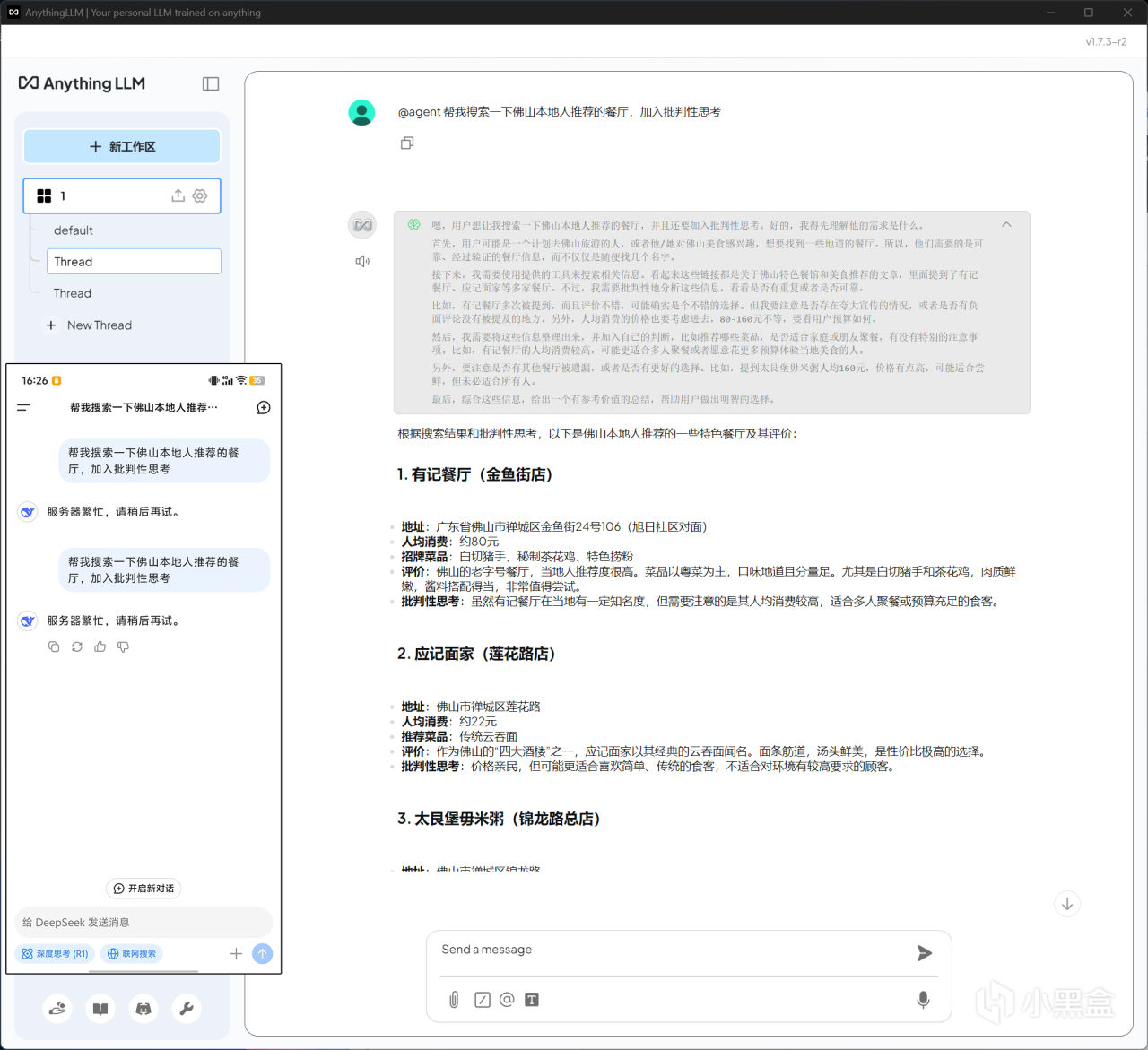
最終在Anything LLM工作區中,只要輸入@agent+問題,就能進行聯網搜索,硬核也試了一下詢問日常美食探店的相關問題,答案還算挺滿意,值得一說的是加入批判性思考後,還能一定程度上防踩雷,能做到這些至少要比官方手機APP連續兩次答不上要強得多了。
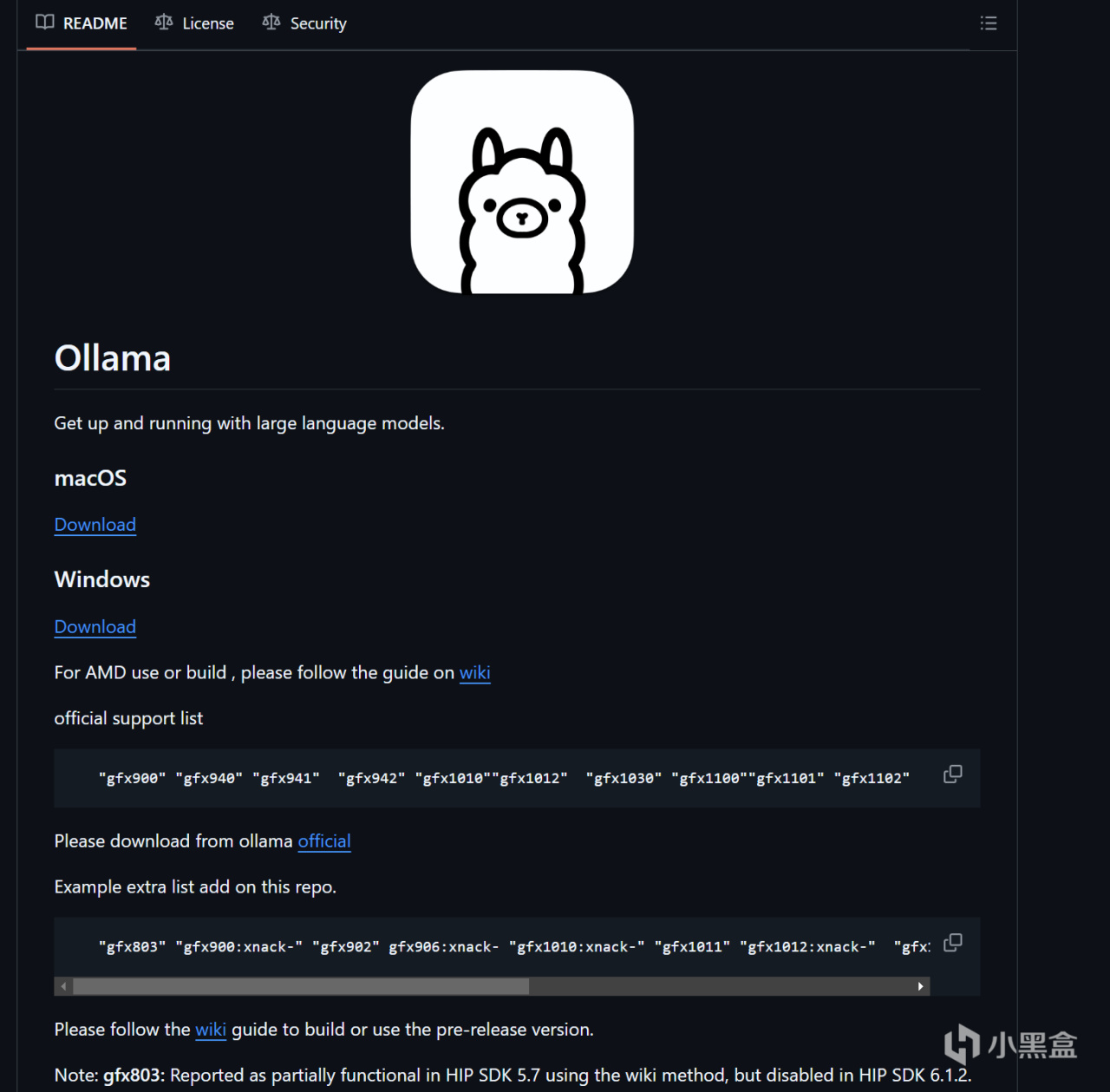
另外如果想用Ollama進行部署也是完全沒問題,不過需要注意的是,對於AMD來說,目前支持官方AMD ROCm框架加速的顯卡有一定型號限制,RX 7000作爲最新系列當然沒有問題,但是RX 6700 XT等型號就不支持了。
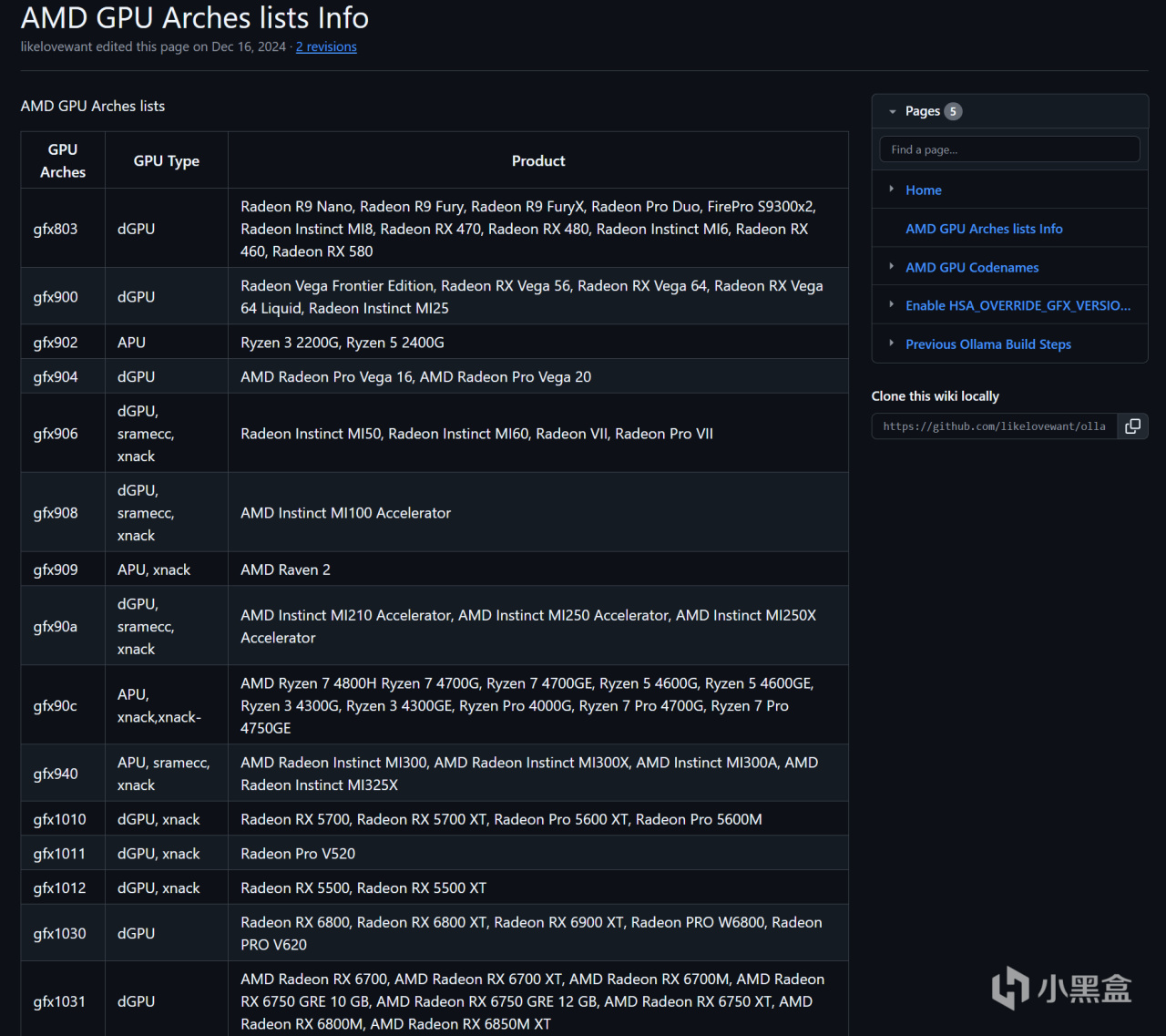
解決辦法不是沒有,就像Stable-Diffusion一樣,使用民間大神版編譯的AMD ROCm框架即可解決,各位可以在Github上搜一搜關鍵詞“Ollama for amd”就明白了,步驟相比相對來說複雜一些。
測試配置、DeepSeek-R1三種蒸餾模型以及對比全量版本效果

本次測試的A卡來自定位次旗艦的藍寶石RX 7900 XT超白金OC L,外觀採用銀灰色金屬導流罩+單側靈動島RGB燈條設計,擁有七根鍍鎳熱管、全銅底座、鋁鎂合金框架等豪華用料,是AMD高端非公版的代表之作。
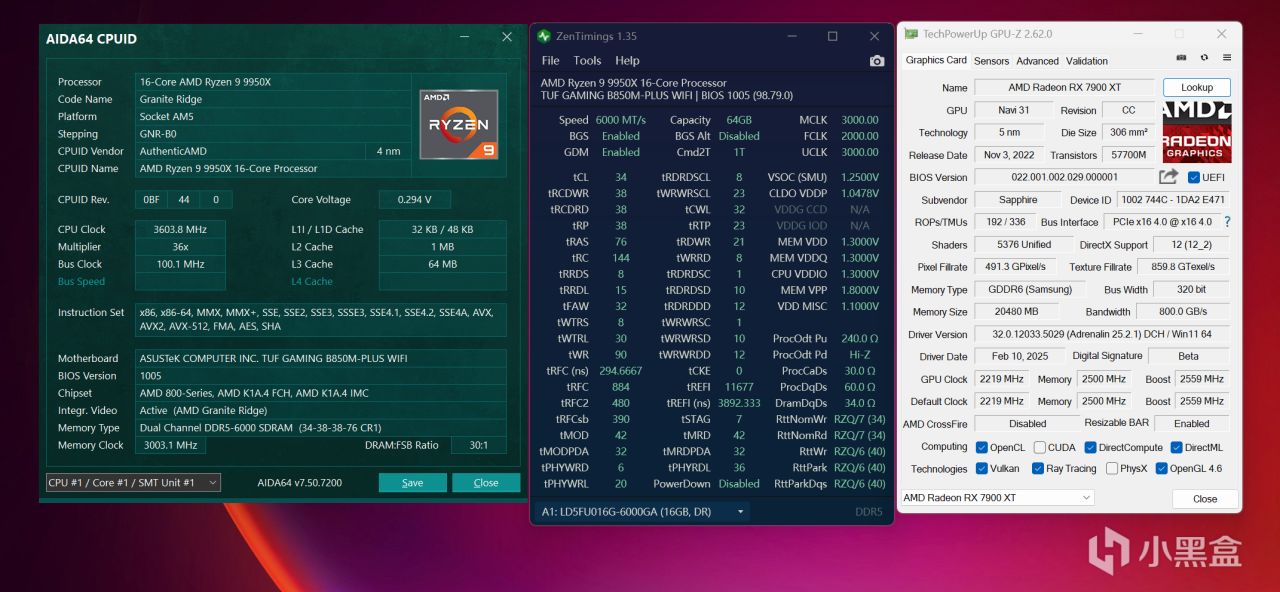
其他配置方面,爲了儘可能降低CPU和內存瓶頸,本次採用CPU是銳龍9 9950X設定開啓PBO ENABLE技術,內存使用EXPO超頻達成DDR5 6000C34 16GB*4,總計64GB容量。
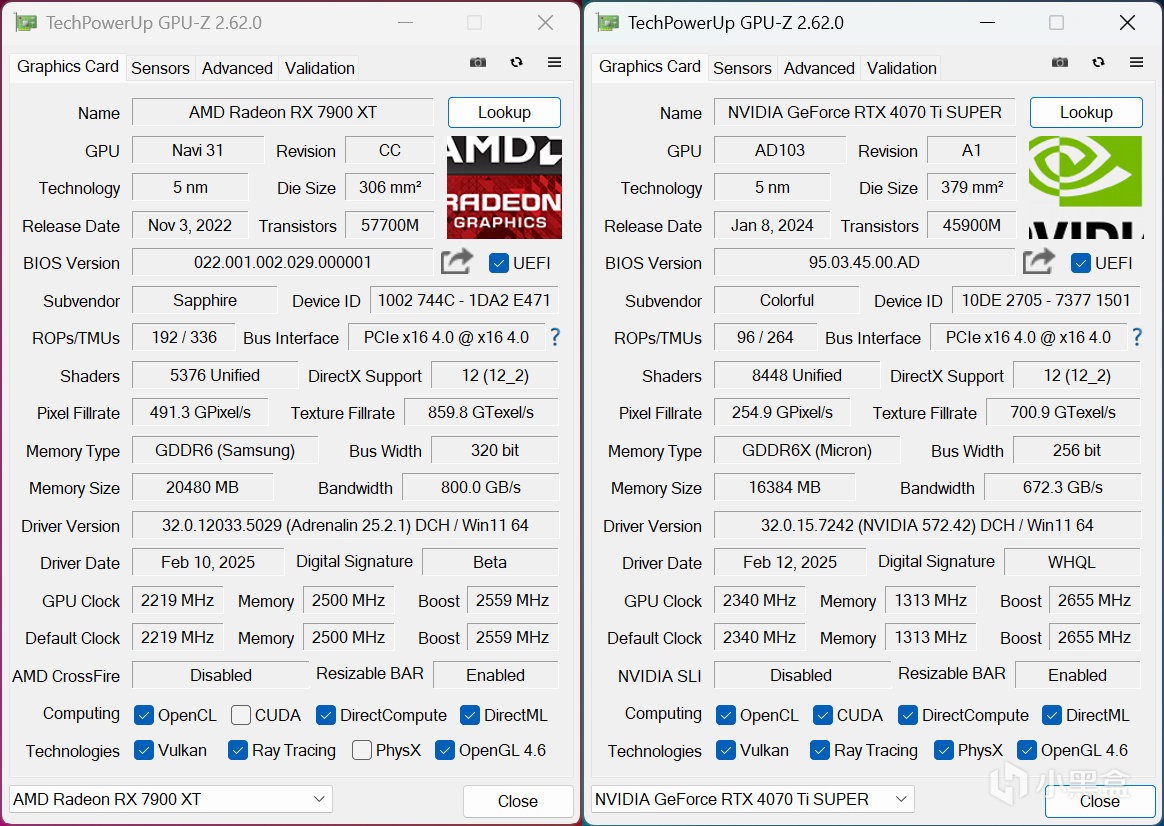
AMD安裝的是AMD Adrenalin 25.2.1 Optional版本顯卡驅動,加入對比測試的N卡是RTX 4070 Ti SUPER,安裝的是NVIDIA GeForce GameReady 572.42 WHQL最新版本顯卡驅動。操作系統是Windows 11 24H2最新版本,在BIOS中開啓Resizable BAR技術提升一些顯卡性能,測試軟件統一爲LM Studio 0.3.9最新版本。
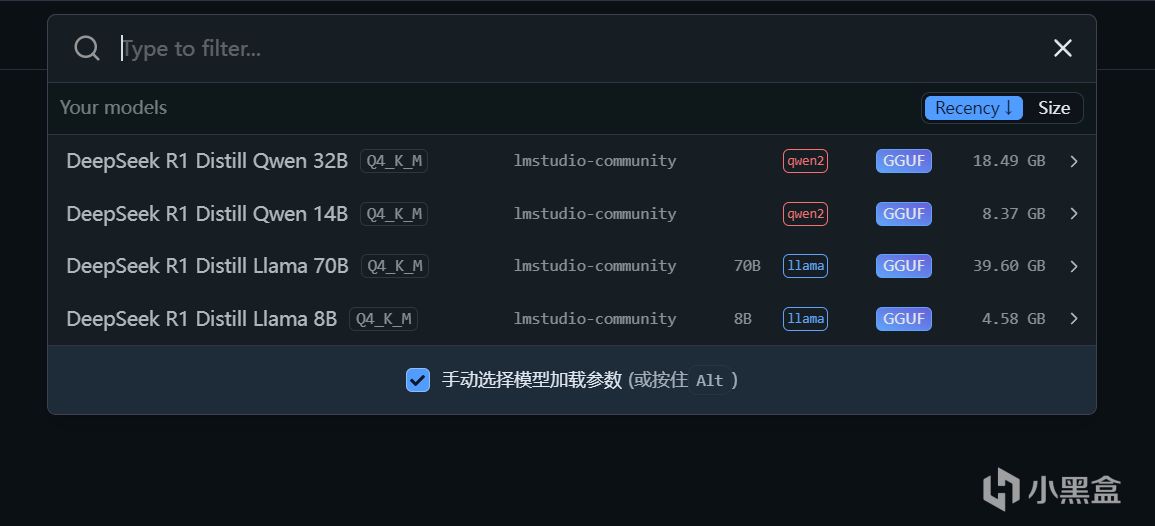
本次測試的DeepSeek-R1蒸餾大語言模型分別有以下三個:
DeepSeek-R1-Distill-Llama-8B-Q4_K_M,基於LIama蒸餾,Q4-K-M量化版本
DeepSeek-R1-Distill-Qwen-14B-Q4_K_M,基於Qwen 2蒸餾,Q4-K-M量化版本
DeepSeek-R1-Distill-Qwen-32B-Q4_K_M,基於Qwen 2蒸餾,Q4-K-M量化版本
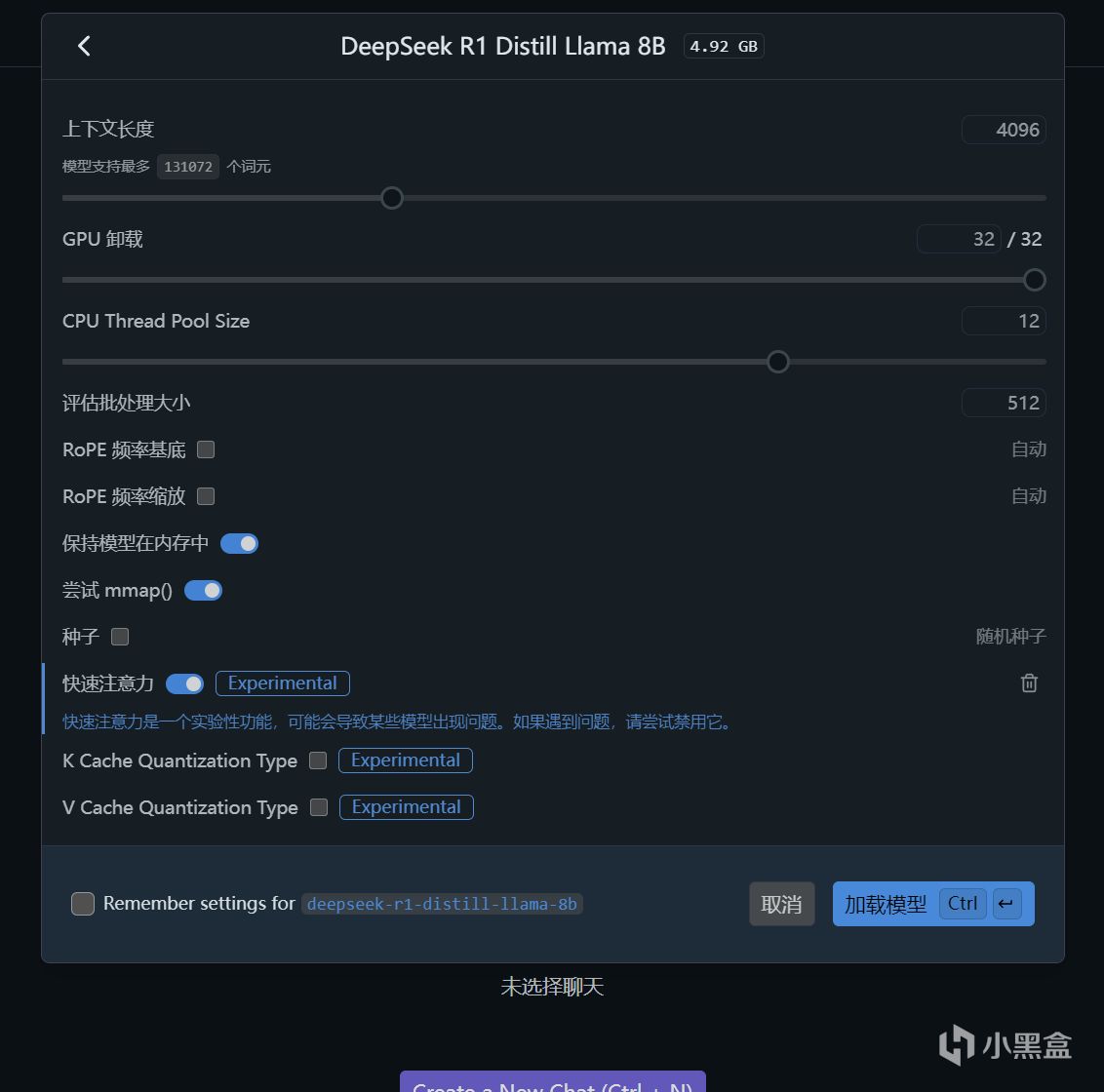
需要注意的是,加載模型時都會盡可能拉滿GPU卸載以便達到最佳效果,至於上下文長度在常規測試中保持默認值4096,在進階測試中也是儘可能拉滿,直至軟件提示報錯爲止。同時也會開啓快速注意力選項進一步優化,而CPU Thread Pool Size則是保持默認值12。
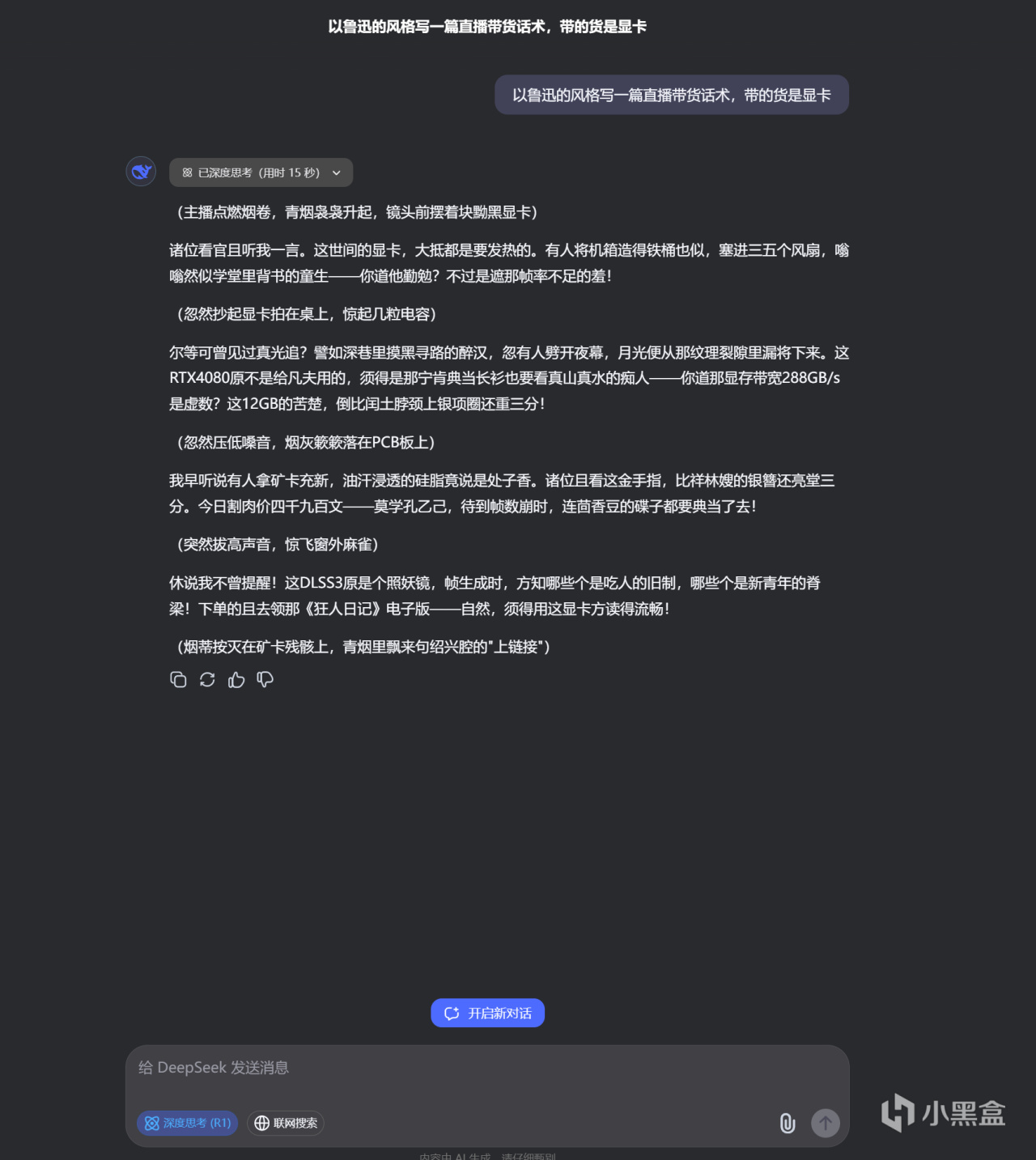
測試問題一:以魯迅的風格寫一篇直播帶貨話術,帶的貨是顯卡
DeepSeek-R1官方滿血671B版本回答如上

測試問題一:以魯迅的風格寫一篇直播帶貨話術,帶的貨是顯卡
DeepSeek-R1蒸餾14B版本回答如上
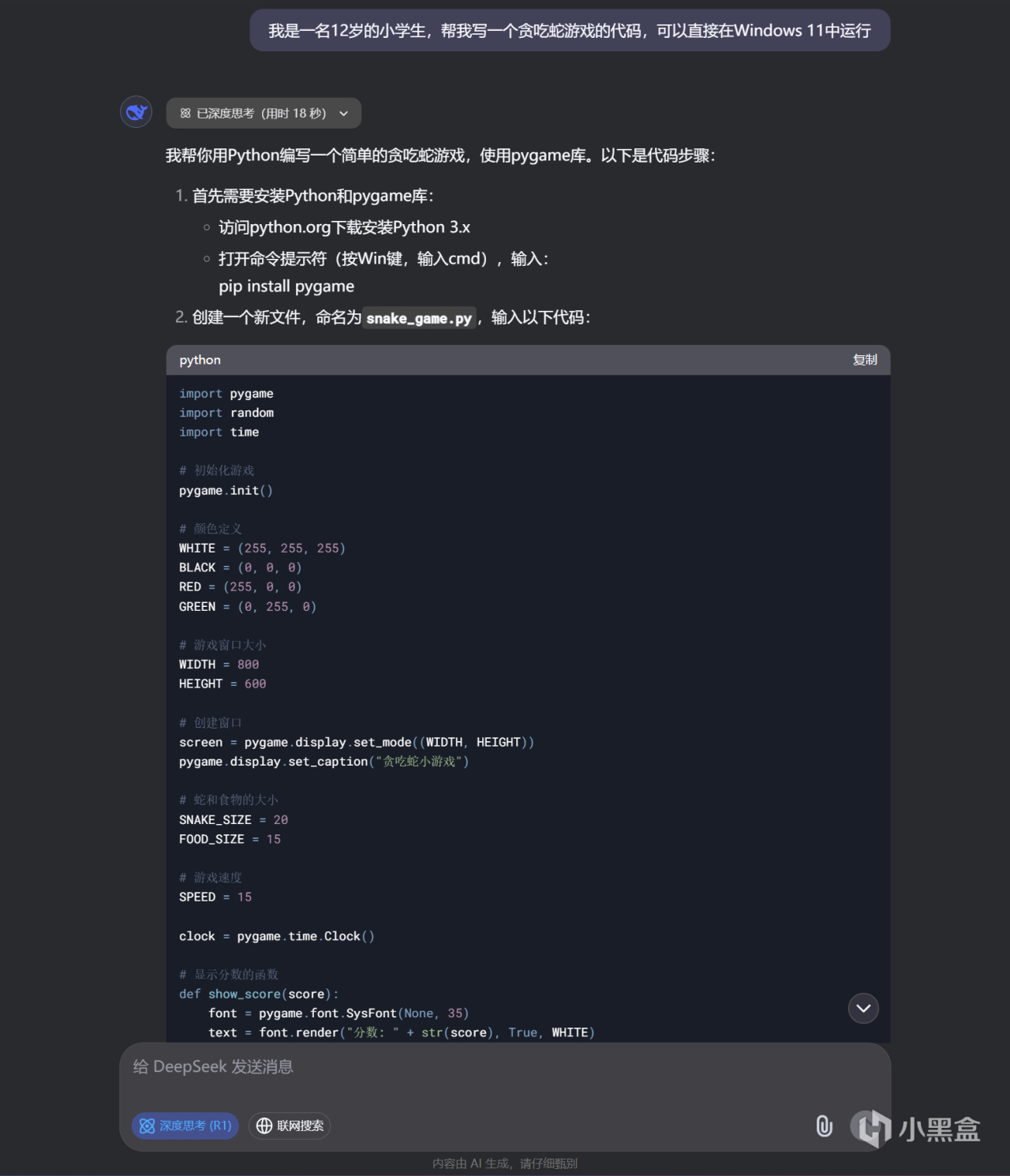
測試問題二:我是一名12歲的小學生,幫我寫一個貪喫蛇遊戲的代碼,可以直接在Windows 11中運行
DeepSeek-R1官方滿血671B版本回答如上
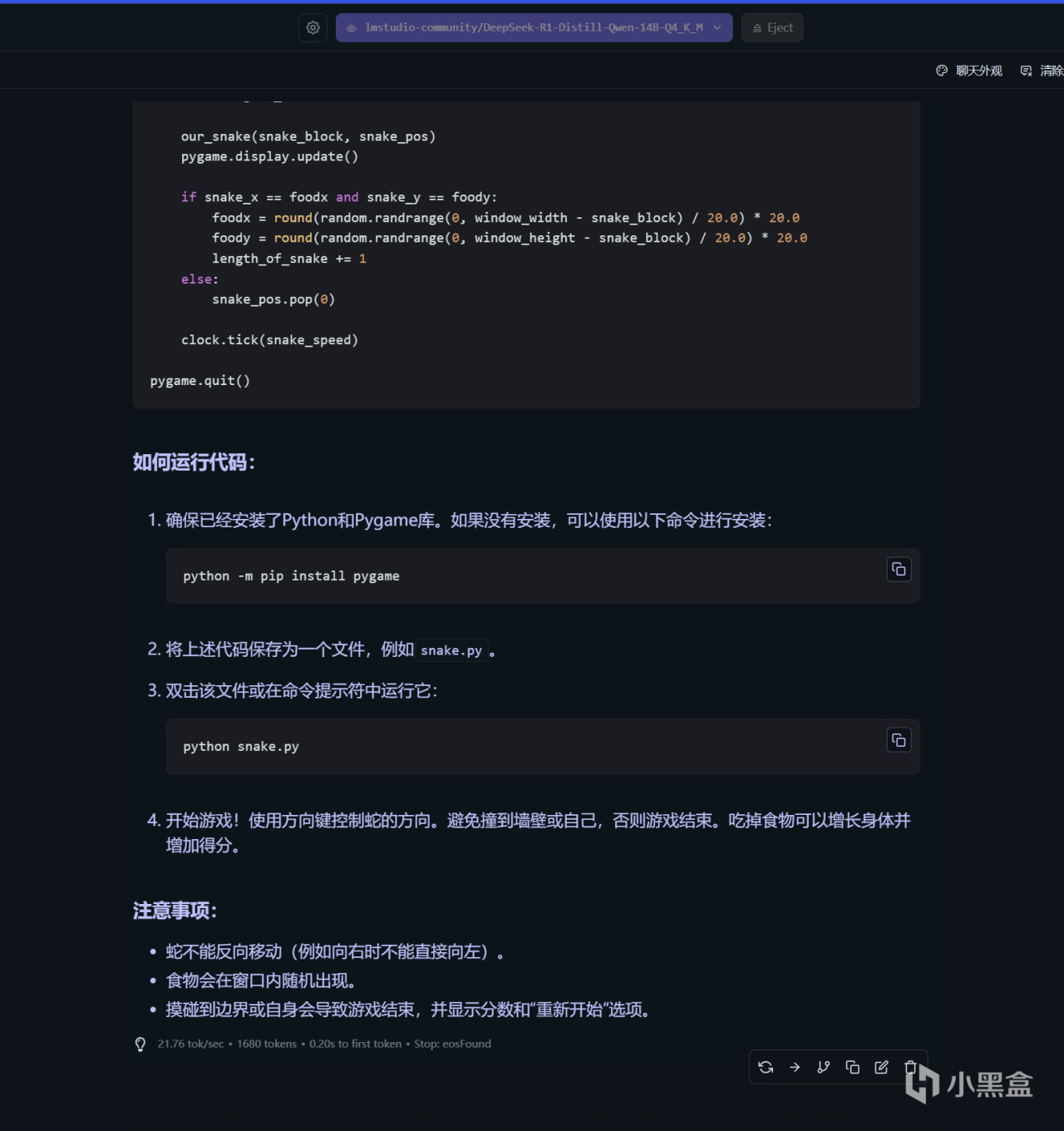
測試問題二:我是一名12歲的小學生,幫我寫一個貪喫蛇遊戲的代碼,可以直接在Windows 11中運行
DeepSeek-R1蒸餾14B版本回答如上
DeepSeek-R1基礎能力表現或許可以反映在直播話術方面的相關問題,即使滿血版和蒸餾版回答都略顯浮誇,但卻能明顯看出答案的區別,滿血版顯然文學水平更高一些,每一句都文采飛揚,而蒸餾版話語平和不少。至於寫代碼或者推理相關問題,兩者區別其實並不大,交代提問者背景後,滿血版和蒸餾版均會採用更爲簡單的形式來實現。
RX 7900 XT和RTX 4070 Ti SUPER在DeepSeek-R1中的表現
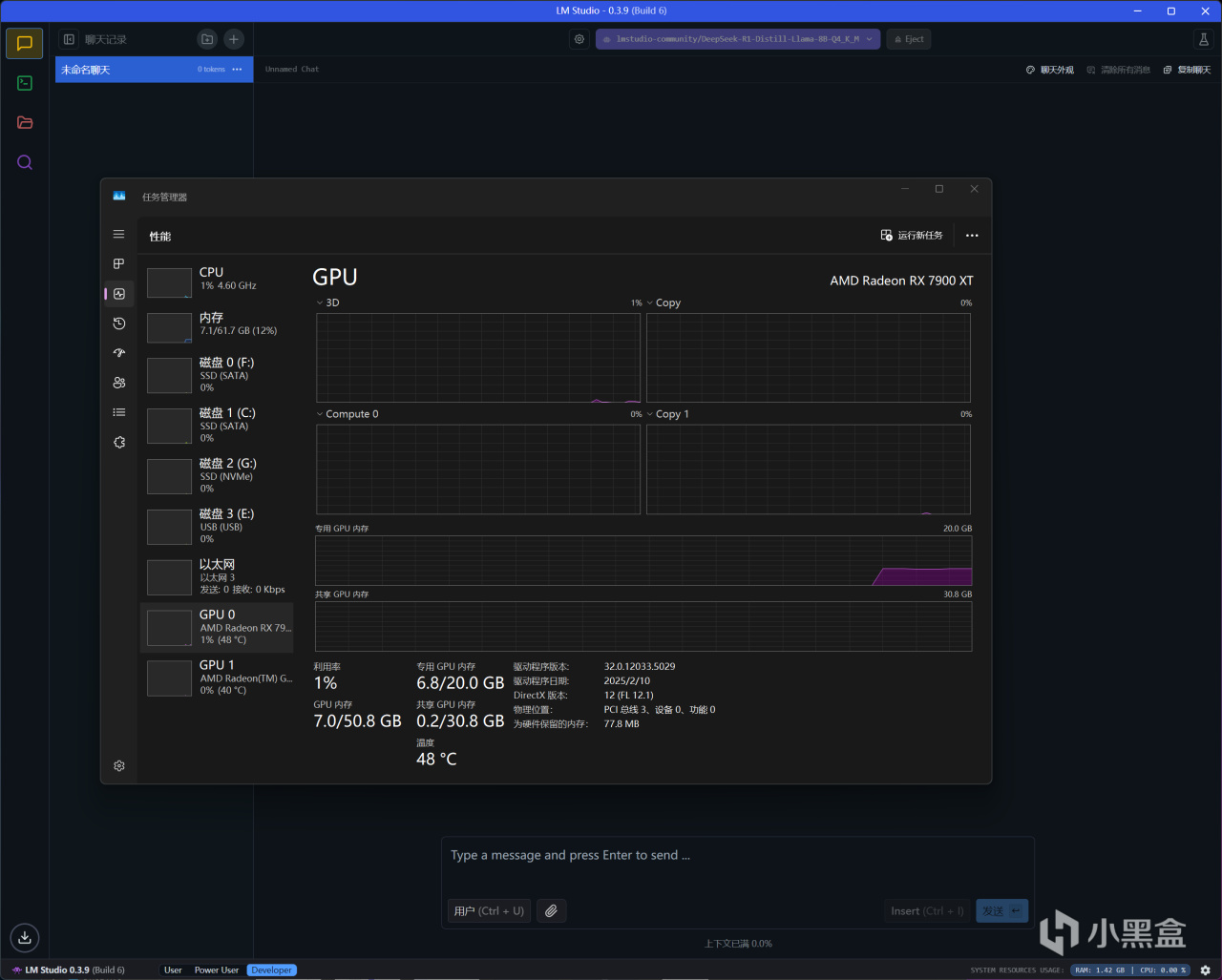
RX 7900 XT載入
DeepSeek-R1-Distill-Llama-8B-Q4_K_M後(GPU卸載MAX+上下文長度4096)
內存使用7.1GB,顯存則是6.8GB
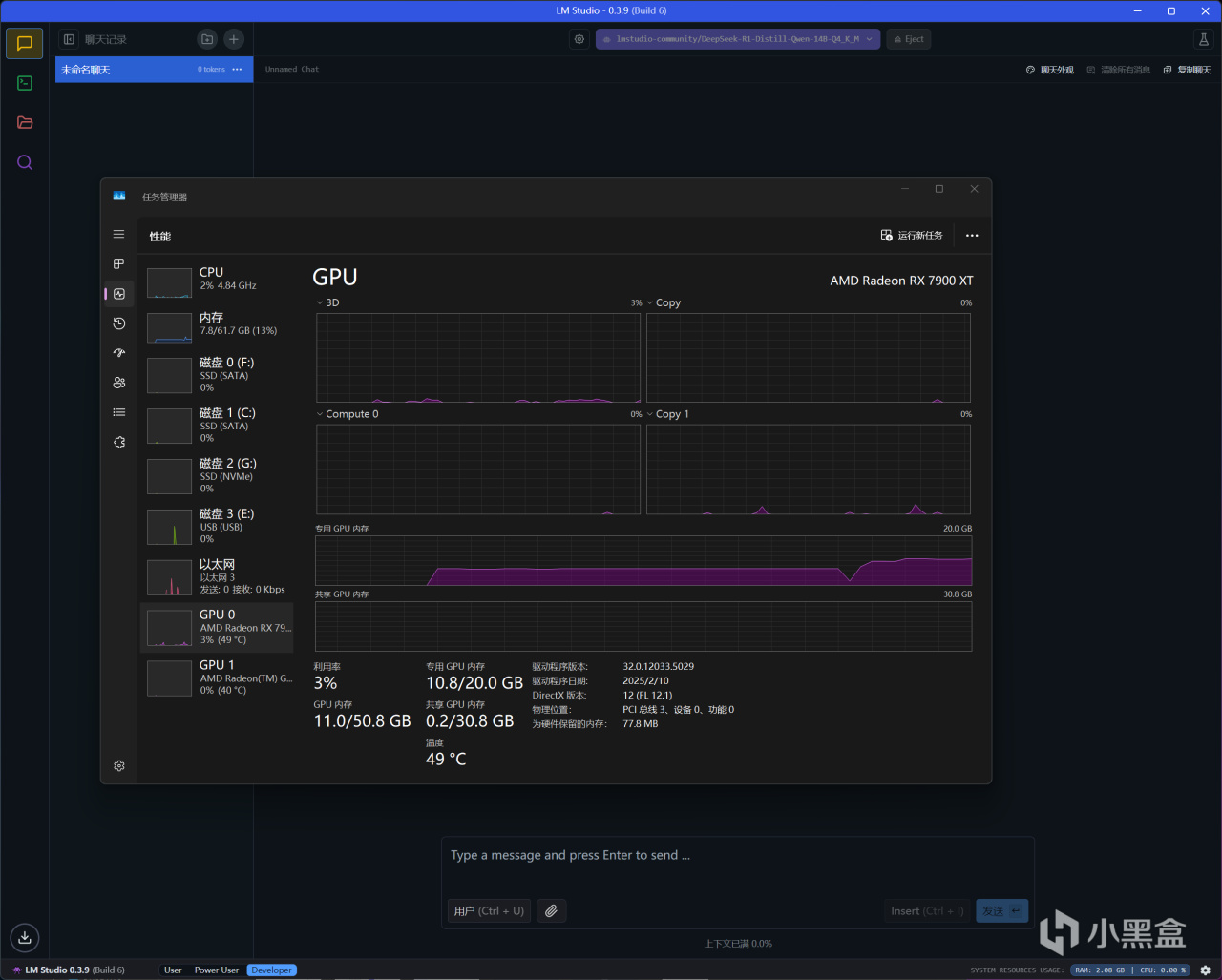
RX 7900 XT載入
DeepSeek-R1-Distill-Qwen-14B-Q4_K_M後(GPU卸載MAX+上下文長度4096)
內存使用7.8GB,顯存則是10.8GB
先看看硬件使用情況,8B和14B模型在常規設置載入後,前者對應8GB顯存、後者則是對應12GB以上顯存的顯卡,此時內存需求量其實是很小的,作爲高端顯卡,RX 7900 XT和RTX 4070 Ti SUPER都足以應付。
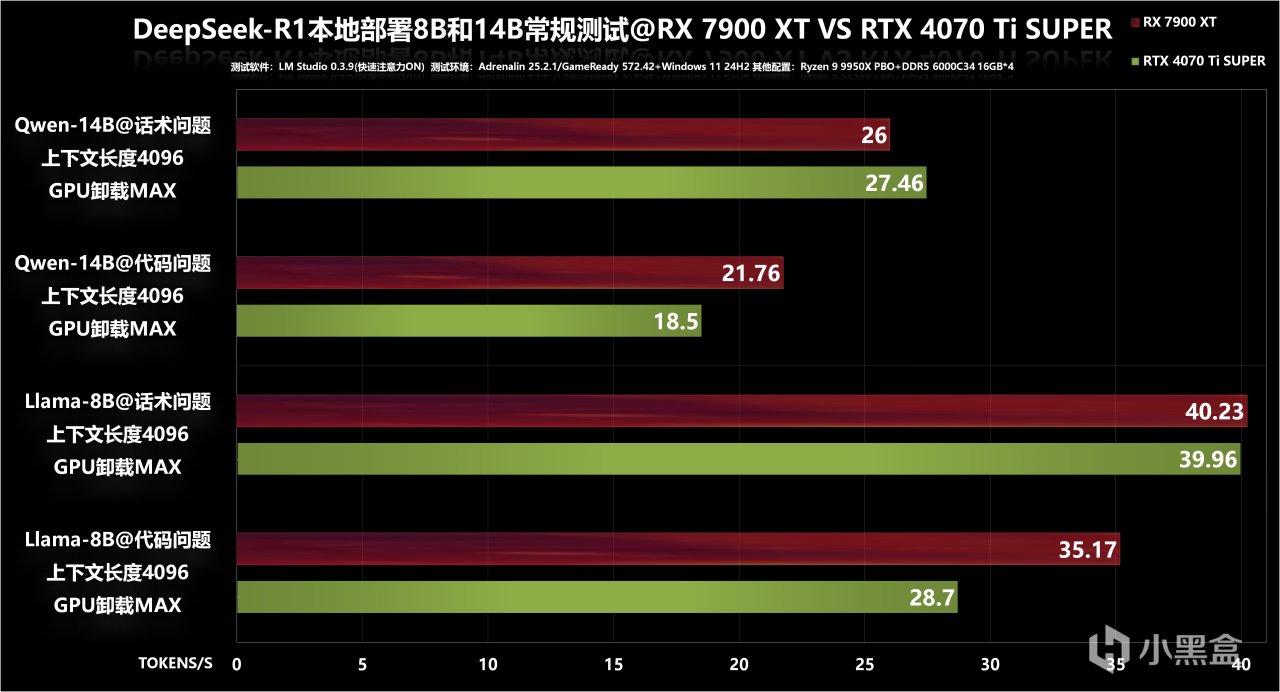
在常規設置下,能看到RX 7900 XT在以上四個項目中,有三個性能表現是高於的RTX 4070 Ti SUPER,尤其是代碼相關問題推理速度要快上不少,領先幅度達到了20%以上,而RTX 4070 Ti SUPER唯一優勢只在14B模式、且屬於話術相關問題中,領先幅度只有6%。綜合四個項目,RX 7900 XT平均領先RTX 4070 Ti SUPER幅度達到9%。
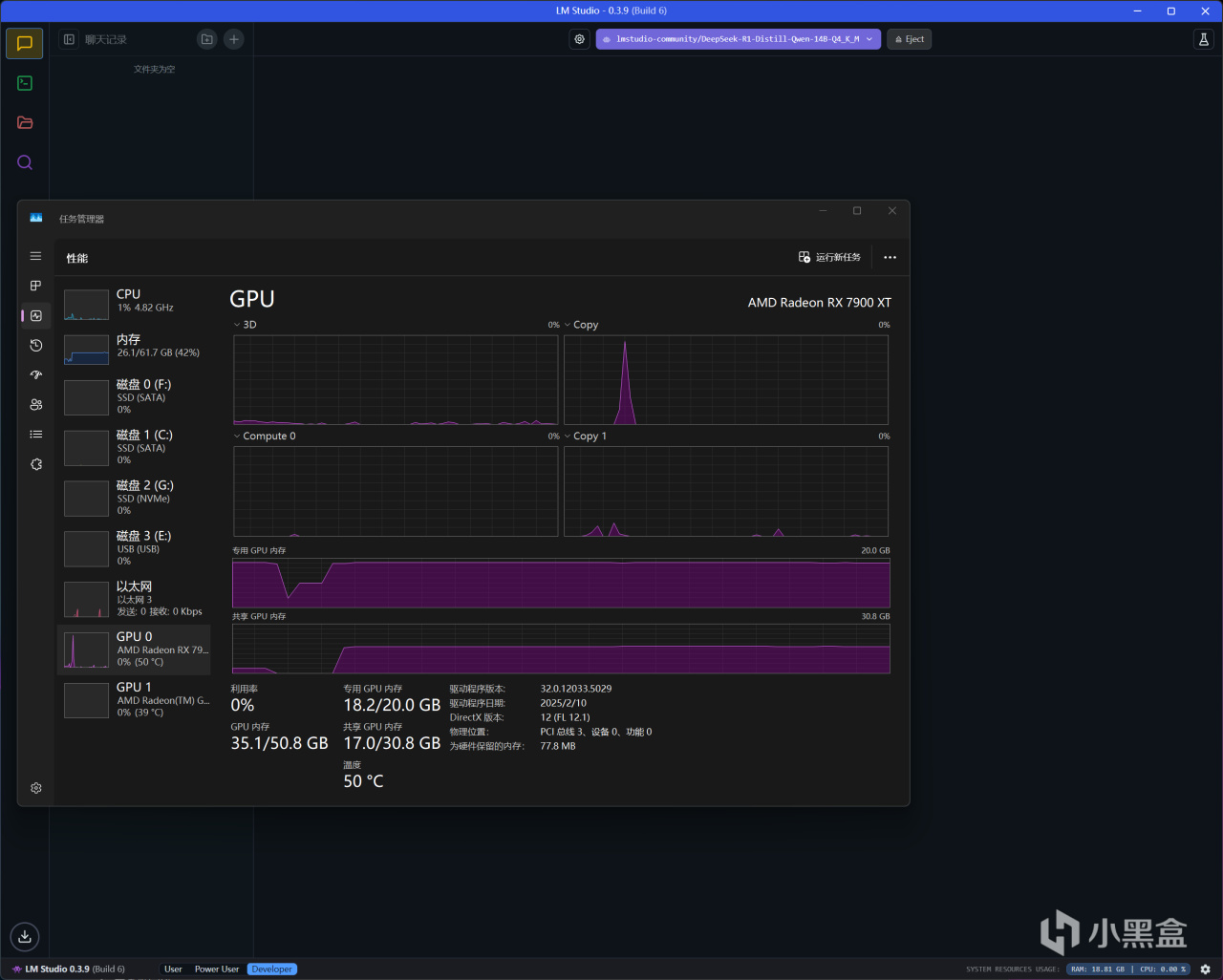
RX 7900 XT載入
DeepSeek-R1-Distill-Llama-14B-Q4_K_M後(GPU卸載MAX+上下文長度MAX)
內存使用26.1GB,顯存則是18.2GB
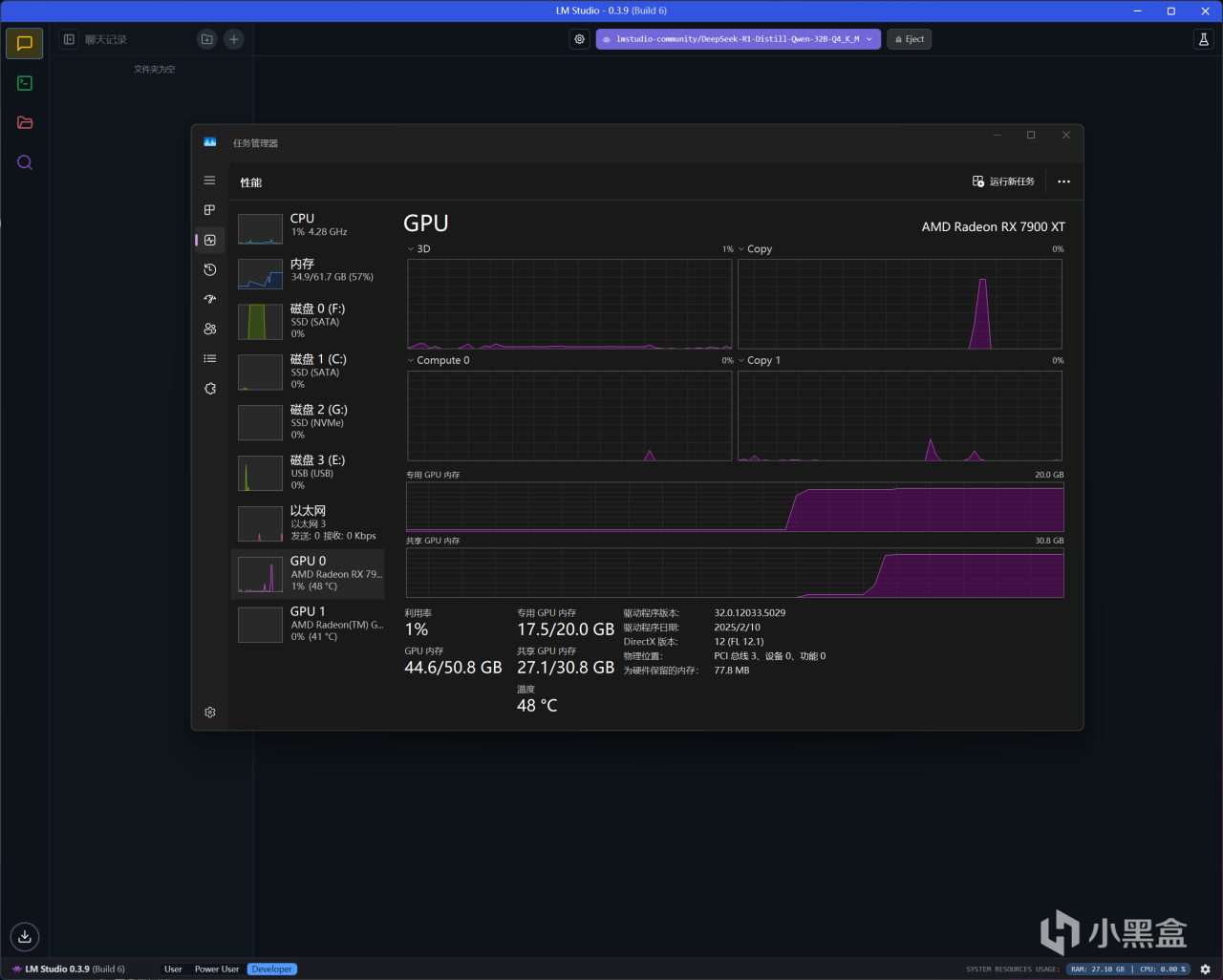
RX 7900 XT載入
DeepSeek-R1-Distill-Qwen-32B-Q4_K_M後(GPU卸載MAX+上下文長度100000)
內存使用34.9GB,顯存則是17.5GB
進階測試的硬件使用情況又不一樣了,因爲把上下文長度都儘可能往高拉,可以顯著提高AI回答的準確性和可靠性,尤其是在一些需要深入理解人類語言、處理大量文檔/報告等場景中更有效果。
在14B模型中,RX 7900 XT拉滿上下文長度(131072)是沒有問題的,只是內存會多佔用一些,而RTX 4070 Ti SUPER最多隻能拉到39000,再多就會提示崩潰。
至於32B模型對於兩款顯卡壓力都挺大,RX 7900 XT上下文長度最多拉到100000,內存需求劇增到35GB,所以48GB容量內存就是最低門檻了。而RTX 4070 Ti SUPER本身GPU卸載都只能達到29(最大64),再拉上下文長度已經沒有意義了,只能保持默認4096了。
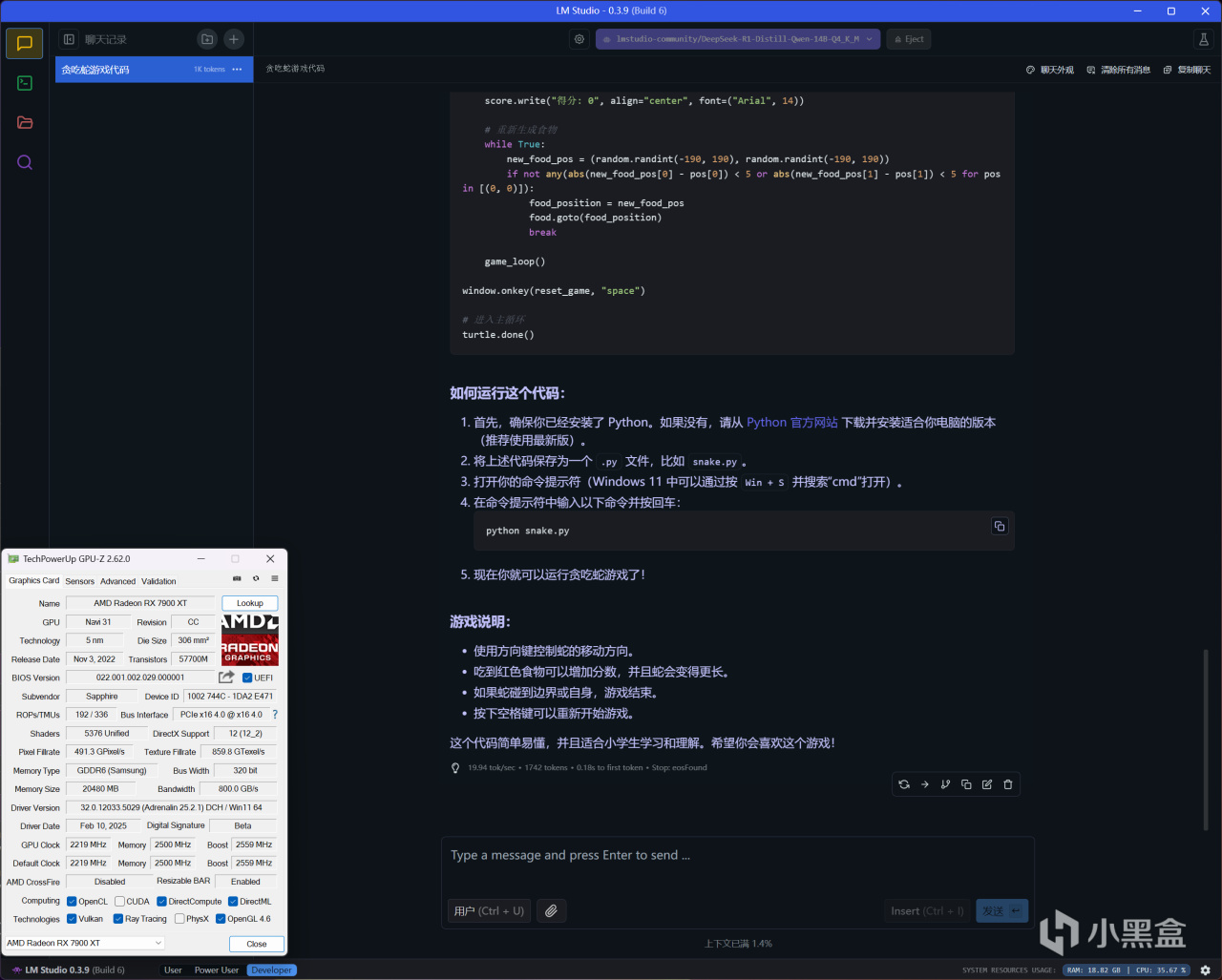
RX 7900 XT運行
DeepSeek-R1-Distill-Llama-14B-Q4_K_M(GPU卸載MAX+上下文長度MAX)
回答代碼相關問題,推理速度爲19.94 tok/s
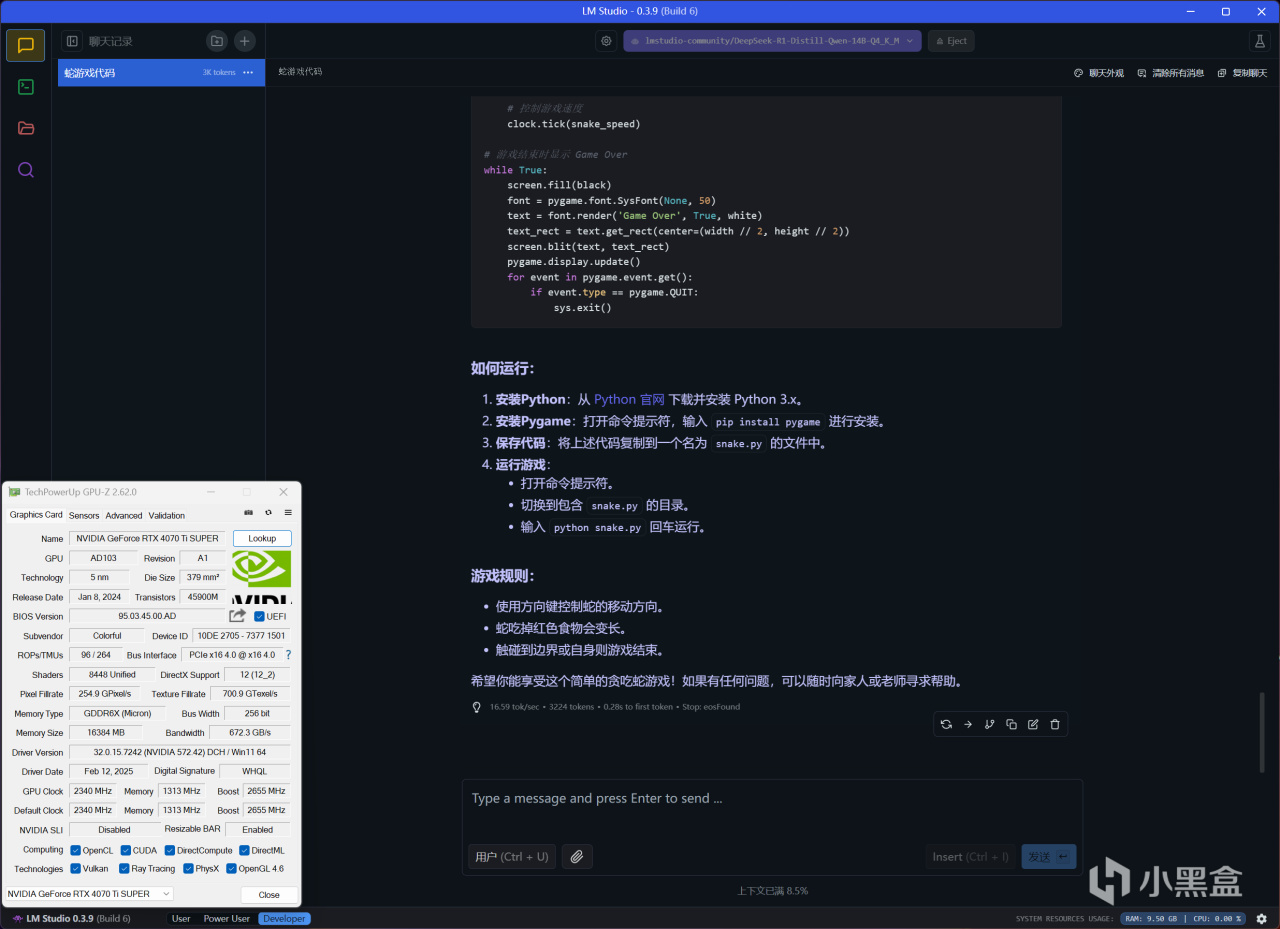
RTX 4070 Ti SUPER運行
DeepSeek-R1-Distill-Llama-14B-Q4_K_M(GPU卸載MAX+上下文長度39000)
回答代碼相關問題,推理速度爲16.59 tok/s
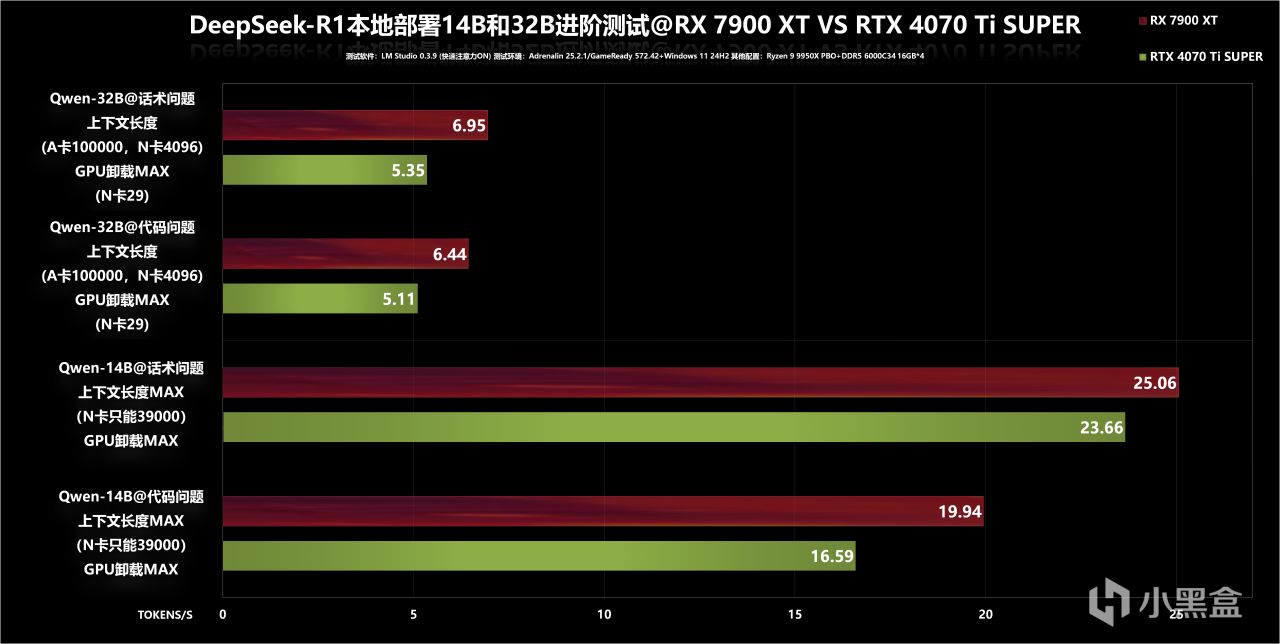
進階測試成績圖表彙總,32B模型確實有點超綱了,實際推理速度比較緩慢,24GB顯存以上會更爲友好。更有實際意義的其實是14B模型,無論是話術還是代碼問題,RX 7900 XT在上下文長度拉滿狀態下,仍比設置上下文長度39000的RTX 4070 Ti SUPER快不少,這時就不用對比它倆的差距了,因爲兩者此時回答的準確性都不是屬於一個級別了。
結語
全文折騰下來,可見RX 7900 XT是憑藉着更大的20GB顯存,運行DeepSeek-R1本地部署的蒸餾模型效率完勝RTX 4070 Ti SUPER,實測8B和14B模型,在常規設置中RX 7900 XT可領先9%幅度,尤其在代碼相關問題表現更爲出色。

另一方面,在14B模型中,RX 7900 XT仍可進一步拉滿上下文長度(131072)以便提升AI生成表現,而RTX 4070 Ti SUPER最多拉到39000再多就崩潰,這也妥妥證明了“A卡戰未來”的設定沒有崩塌。當然,AMD ROCm框架支持目前仍不夠成熟,雖說也有不少民間解決方案,但確實挺期待AMD可以繼續加大優化力度吧!
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















