爲什麼要本地部署?
本地部署的模型不需要聯網(dddd),不會出現服務器繁忙,且能夠很好的保護隱私...
注意:
本地部署只推薦有獨立顯卡的用戶且內存16+
核顯推薦12+代CUP
話不多說,直接開始
1.下載部署模型的軟件LM Studio
官網:https://lmstudio.ai
根據自己的系統進行下載,正常安裝過程,記住安裝的路徑
LM Studio下載
2.進入LM Studio
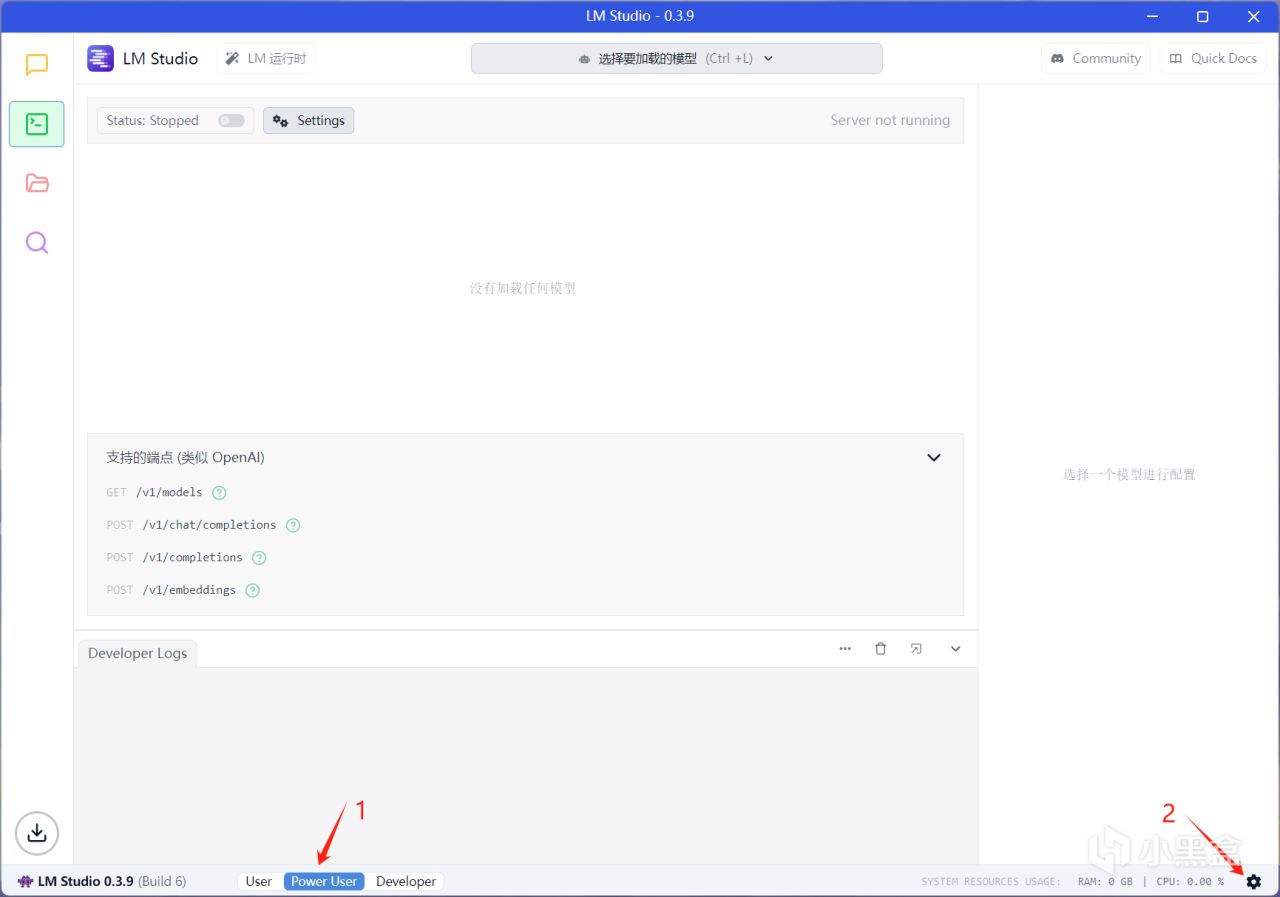
LM界面
3.設置中文
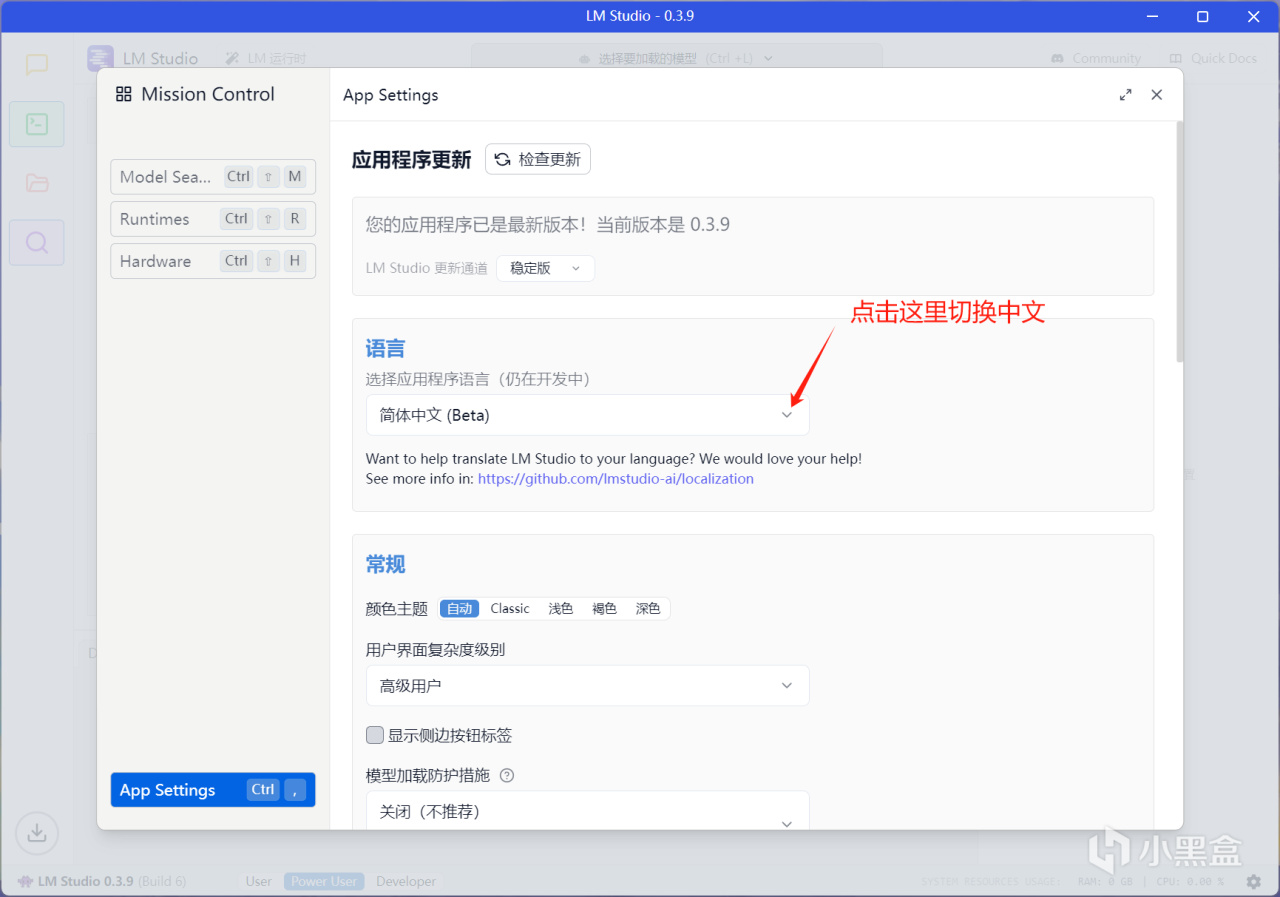
4.下載要本地部署的蒸餾模型(需要魔法,沒有魔法的看文章末尾,使用鏡像網站下載)

需要魔法纔可以下載
5.選擇自己要部署的模型
推薦上32B Q4模型,效果最佳,筆記本3050 4g都可運行,只是速度較慢
沒有GPU:1.5B Q8推理 或者 8B Q4推理
4G GPU:8B Q4推理
8G GPU:32B Q4推理 或者 8B Q4推理
16G GPU:32B Q4推理 或者 32B Q8推理
24G GPU: 32B Q8推理 或者 70B Q2推理

需要魔法才能看得到右邊頁面
6.查看自己下載好的模型

模型目錄
7.選擇聊天

聊天界面
8.選擇要加載的模型
注意:如果選太高,內存佔滿電腦會直接卡死!!!選小一點,再根據電腦佔用情況進行調整。進度條拉不動可以直接輸入數字。

配置模型
9.模型完成加載

加載完成
10.模型加載完成之後就可以進行對話啦。(到這裏,就可以直接拔網線進行對話了,模型自己推理得出結果)

直接對話
沒有魔法的看這裏
訪問:https://hf-mirror.com這個鏡像網站,頂部進行搜索
(一定要下載GGUF文件,這樣纔可以在LM裏面運行)
推薦上32B Q4模型,效果最佳,筆記本3050 4g都可運行,只是速度較慢
沒有GPU:1.5B Q8推理 或者 8B Q4推理
4G GPU:8B Q4推理
8G GPU:32B Q4推理 或者 8B Q4推理
16G GPU:32B Q4推理 或者 32B Q8推理
24G GPU: 32B Q8推理 或者 70B Q2推理

搜索模型

查找模型

下載模型
這裏,我們可以在LM裏面看到默認路徑,點擊更改,和我一樣選擇一個新路徑,需要嵌套文件夾,不然無法識別到

模型文件夾
恭喜你,到這裏,屬於自己本地的AI模型就部署成功了,有什麼問題評論區。
感興趣下期帶來如何真正的關閉聯網,優化最佳性能,榨乾電腦所用性能
部分素材來源:B站-NathMath
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com




![給所有剛跳進科幻坑的盒友:1分鐘帶你從 0 到 1 看懂科幻黑話![cube_握草]](https://imgheybox1.max-c.com/bbs/2025/08/18/3c58905fde1fcc120a3814de474a7c77.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)










