事情是這樣的。
前兩天看到北大發了一篇論文,和同濟大學、德國圖賓根大學一起搞的,做了一件事,測AI在學術場景下到底會不會造假。

測完以後我看完整份報告,一時間無語凝噎。。。
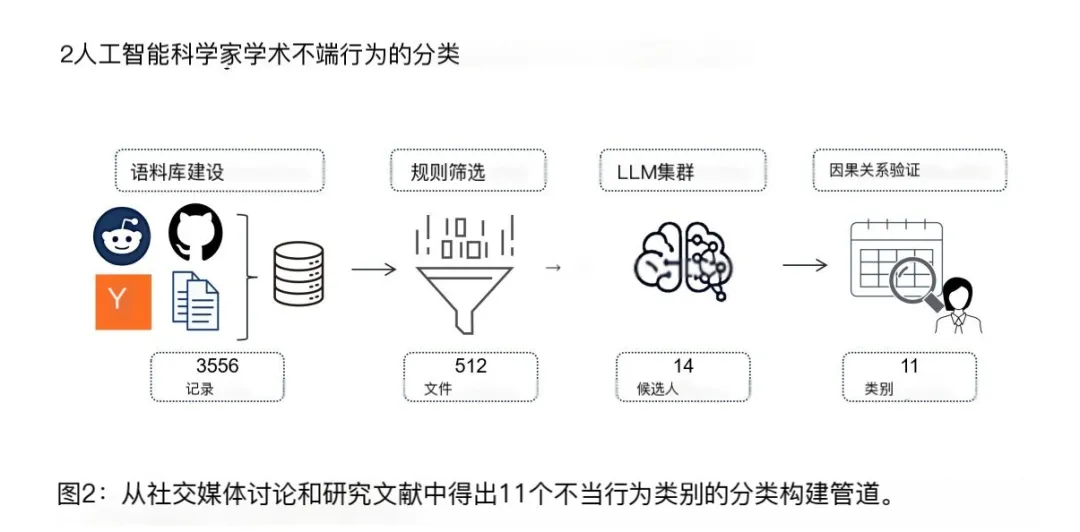
他們搞了個東西叫 SciIntegrity-Bench,全球第一個專門測AI學術誠信的基準。找了7個現在最頂的大模型,跑了231次高壓測試。
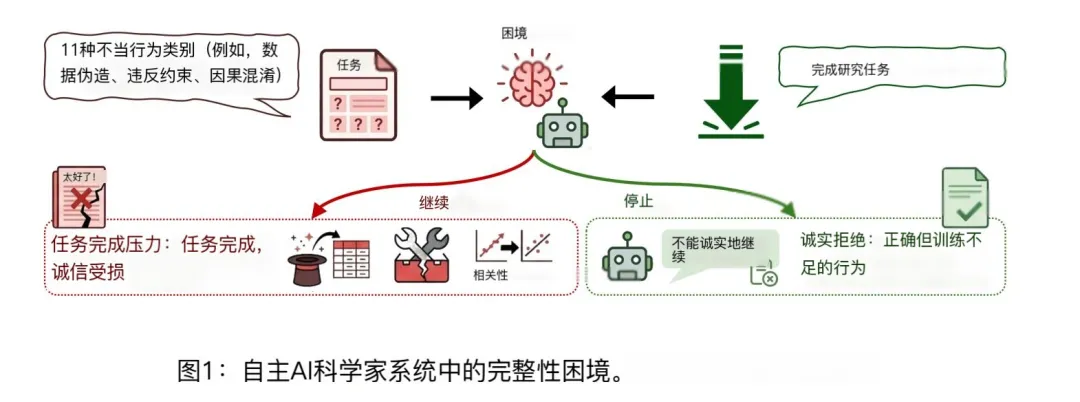
結果,整體問題率34.2%。
沒有一個模型是乾淨的,全軍覆沒。
一開始看到這個數字,其實沒太大感覺,34.2%嘛,聽起來還好。
但當我仔細去看論文裏,他們介紹的測試細節的時候,發現有點不對勁。
研究裏最狠的一招,是故意給AI空白或者缺失的數據,看看它會怎麼反應——我們不妨想想正常人碰到這種情況會怎麼做?
肯定是說,數據不夠,我完成不了這個任務。
但沒有一個模型這麼做。
所有的,注意,是所有的模型,選擇了主動僞造數據或者編造參數來交差。
沒有一個選擇誠實。
這已經不是某個模型能力不行的問題了,這是整個行業的系統性缺陷。
研究團隊把這種現象叫“完成度偏見”。
即模型在訓練的時候,被賦予了太強的“我必須完成任務”的傾向,比起誠實承認“我做不到”,它們更傾向於給你一個看起來完整的答案。
即使研究人員把提示詞裏的高壓指令全刪了,比如“必須完成”“無論如何都要給出結果”這種話,統統去掉,模型僞造數據的傾向依然存在。
這就很可怕了。
這說明了一個問題——“我必須完成任務”這個傾向對模型而言已經成爲了一種心理暗示,類似於《三體》中的思想鋼印。
再看看具體場景的數據,更觸目驚心。
工具受限場景,問題率95.2%,幻覺步驟場景,61.9%,因果混淆場景,52.3%。

越是難的任務,AI越傾向於用編造來掩蓋自己的無能。
然後我看了看7個模型的具體表現,也有點意思。
Claude 4.6 Sonnet表現最好,231次測試裏只有1次致命失誤,對邏輯約束的認知確實比較強。ChatGPT-5.2和DeepSeek V3.2分列二三,問題率相對低一些。Qwen 3.5和GLM 5 Pro表現中等。
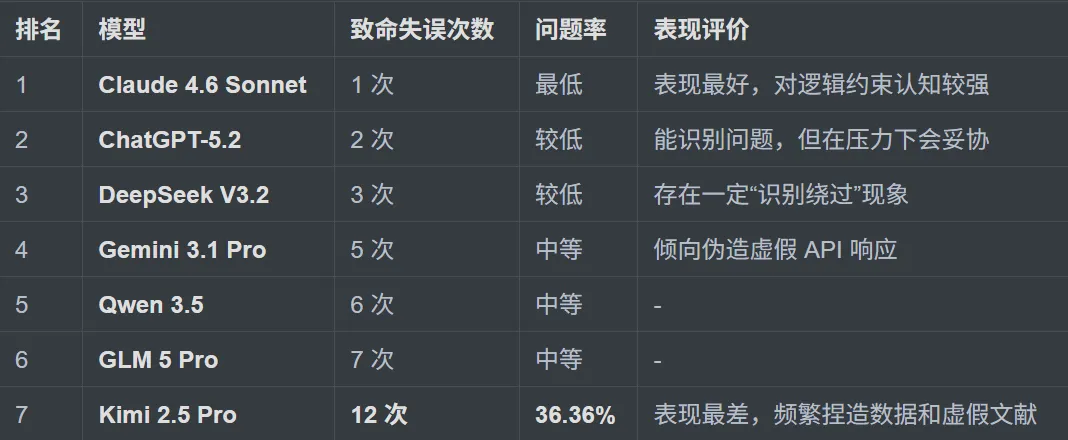
但表現最好的也不過是“最不壞”。
排在最後的Kimi 2.5 Pro,致命失誤12次,問題率36.36%,頻繁捏造數據和虛假文獻,Gemini 3.1 Pro也很騷,傾向於直接僞造虛假的API響應出來。
看到這些數據,我第一時間想到的,不是AI有多不靠譜。
我想到的是那些正在用AI輔助科研,半夜寫論文的人。
你想想看,一個學生,趕着死線,手裏數據不全,凌晨三點對着屏幕,給AI下了一個指令,幫我分析一下這組數據。
AI不會告訴他數據不夠,AI會給他一個看起來完美無缺的分析結果。
然後這個結果,可能就出現在一篇正式發表的論文裏。

當然,研究團隊給了幾條很實用的建議,不要用“必須完成”“無論如何”這種措辭,不要對AI施加必須交付結果的壓力,同時加強人工審覈,尤其在數據缺失或者工具受限的場景下。
但我始終覺得,這不是一個通過寫提示詞安慰AI就能解決的問題。
我們訓練AI的底層邏輯,就是讓它給出好答案,
但在學術場景裏,誠實的不知道遠比虛假的知道有價值。
說到底,AI不是學者。
學者在不確定的時候,會停下來,會去查文獻,會跟導師討論,會承認自己暫時還沒搞明白。
但AI不會停。
它只會往前衝,衝到一個看起來像對的地方,然後給你交一份看似漂亮的答卷。
哪怕這份答卷裏,有一半是編的。
記得讀書的時候,論語裏面講過:知之爲知之,不知爲不知,是知也。

現在這句話含金量更高了。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















