寫在前面:
如今這個時代,注意力和專注力都是我們自身寶貴的稀缺資源,
我總是很貪心地在一篇文章裏塞下很多東西,總是想盡可能把我知道的東西儘量有邏輯,有條理地分享給大家,比如這篇,又爆了6000字,我通篇看來看去,怎麼也縮不下去。
原因有很多,內容要由淺到深、要在必要的地方擴展補充關鍵信息、要文章形成完整的邏輯架構...
這往往導致一篇文的篇幅太長,閱讀要花費的時間太多,就算這樣,很多主題都只是點到表面,並沒有深入。
其實我自己也知道這樣不好。我們平時的事情那麼多,大家哪有那麼多精力和功夫花這麼多時間來看完?
但是我又不想把一篇文章的內容拆散來發,因爲我覺得這樣會丟失文章裏體現的思考過程,也會讓大家不能順理成章將一些信息之間建立邏輯關係,
說到底這也是我的私心,但目前也不知道該怎麼優化,如果有什麼想法,十分希望你們能在評論區告訴我。
如果願意看文章的盒友們,我強烈建議你們先看目錄,然後直接看自己感興趣、想了解的部分即可
---

本文約 6200 字,預計閱讀時間約 14 分鐘。
我想搭個知識庫,要不要用RAG?
這個問題看似簡單,但答案取決於具體情況。
先簡單複習一下RAG是什麼。
🔍 RAG:給大模型裝個"外掛知識庫"
RAG(Retrieval-Augmented Generation,檢索增強生成)最早由Meta AI在2020年提出。核心思路很簡單:大模型的知識是有限的、靜態的,但可以通過"檢索"把外部知識動態地餵給它。
具體來說,RAG的工作流程是:
1⃣ 切片
把文檔切成小塊(每塊500-1000字)。爲什麼切?整篇文檔太長,檢索和匹配都不方便。就像圖書館不會把整本書塞進檢索系統,而是按章節、段落建立索引。
2⃣ 向量化
用嵌入模型(Embedding Model)把每個文本塊轉成一串數字向量。
向量是什麼?可以理解爲文本的**“語義座標”**——語義相近的文本,向量在空間裏的距離也近。“蘋果公司"和"Apple Inc.“的向量距離很近,和"紅富士蘋果"的距離就遠了。
3⃣ 存儲
把這些向量存進向量數據庫。
4⃣ 檢索
用戶提問時,把問題也轉成向量,在數據庫裏找最相似的幾個文本塊。
5⃣ 生成
把檢索到的文本塊塞進提示詞,讓大模型基於這些材料回答。
爲什麼RAG曾經是搭建知識庫的標配?
因爲大模型有兩個致命缺陷:
知識有截止日期,不知道最新發生的事
沒有私有數據,不知道公司內部的文檔、產品手冊、技術規範
RAG恰好解決了這兩個問題——可以隨時更新知識庫,也可以把私有數據餵給模型。
📈 長上下文來了,RAG還需要嗎?
2024年,Gemini推出100萬Token的上下文窗口,“RAG已死"的言論甚囂塵上。
2025年,DeepSeek把緩存Token的價格打到了原來的1%,長上下文模型變得異常便宜。
於是很多人開始想:既然模型能記住這麼多內容,爲什麼不直接把所有筆記塞進去?
不需要切分文檔、不需要向量檢索、不需要複雜的RAG流水線,直接全量輸入,讓模型自己找答案。
聽起來很美好。但實際效果如何?
🎯 長上下文的"中間迷失”
業界用NIAH(Needle In A Haystack,大海撈針)測試來評估長上下文模型的檢索能力。
早期的測試很簡單:把一個關鍵信息(“針”)藏在大量文本(“乾草堆”)裏,看模型能不能找到。
2025年的測試標準升級了——Multi-Needle Reasoning(多針推理)。比如:在100份財報(共100萬Token)裏,找到A公司和B公司在Q3的研發投入數據,並比較增長率。模型不僅要找到兩個散落在不同位置的數據點,還要進行跨文檔的邏輯比較。
測試結果揭示了一個物理規律:Lost in the Middle(中間迷失)。
模型對開頭和結尾的內容記得最清楚,對中間的內容注意力會衰減。研究表明,當輸入文本超過5萬字時,中間位置信息的檢索準確率可能下降40%以上。
🧠 爲什麼會"中間迷失”?
這不是模型的"缺陷”,而是注意力機制的固有特性。
Transformer的核心是自注意力。每個Token都要和所有其他Token計算關聯度。注意力權重經過Softmax歸一化後,所有位置的總和是1。
當序列長度從100變成10000,每個位置能分到的"注意力預算"被稀釋了100倍。
但開頭和結尾有天然優勢:
開頭:作爲第一個位置,累積了最多的"被關注"機會
結尾:在生成時已經"看過"所有前置內容,天然帶有全局視角
中間位置沒有這種優勢——它們既不是起點,也不是終點。
還有一個因素:位置偏好是訓練數據的產物。
模型在訓練時看到的大多是短文本。在這些文本里,開頭往往是主題句、標題、摘要——信息密度高。結尾往往是結論、總結——也很重要。中間則是展開論述,信息相對稀釋。
模型學到了這個模式:開頭和結尾更值得"關注"。
🎧 一個類比
想象在聽一場3小時的講座。
開頭10分鐘很專注,因爲不知道要講什麼。結尾10分鐘也很專注,因爲想知道結論。
中間2小時40分鐘呢?注意力會不自覺地飄走——不是因爲內容不重要,而是因爲**“注意力預算"有限**。
模型也一樣。
💾 Context Caching:讓長上下文變得實用
長上下文還有另一個問題:成本和延遲。
把100萬Token的文檔塞進模型時,模型要對每個Token做前向傳播,計算出每一層的Key和Value向量——這些統稱爲KV States。這個過程需要大量GPU時間。
問第二個問題?模型又要重新算一遍。
Context Caching的核心思路:把第一次計算出來的KV States存起來,下次直接用。
就像讀一本書——第一次讀要逐字逐句理解,第二次讀時已經"記住"了內容,只需要關注新問題。
以DeepSeek V3爲例,緩存命中後:
100萬Token的輸入成本從 $5.00 → $0.02(對比GPT-4o的$5/1M tokens)
延遲從 60秒 → 5秒
但緩存是有限的資源——顯存不是無限的,服務商不可能無限期保存KV States。
不同服務商的策略:
Anthropic:緩存有最小token要求,有效期有限
DeepSeek:緩存時間較長,適合長對話場景
🖥 本地能實現緩存嗎?
實現KV緩存的前提是:能訪問模型的中間狀態。這取決於用什麼方式運行模型。
方案一:vLLM
vLLM是目前最流行的開源推理框架,內置PagedAttention機制,本質上就是一種高效的KV緩存管理。用vLLM部署本地模型(比如Llama、Qwen),緩存是開箱即用的。
方案二:HuggingFace Transformers
原生Transformers庫不提供緩存管理,但可以手動實現。要做成生產可用的緩存系統,還需要緩存索引、緩存淘汰、緩存失效檢測。
方案三:Ollama
Ollama默認不暴露KV緩存接口,但內部有類似的優化機制。問題是:無法直接控制Ollama的緩存行爲。它更像一個黑盒,適合簡單場景。
但有一個硬限制:KV緩存是存在顯存裏的。
以Llama-3-8B爲例,每Token的KV緩存大約佔用50KB顯存。100萬Token的緩存需要約50GB顯存——這遠超大多數消費級顯卡。
實際可行的方案:
用量化模型
只緩存高頻訪問的文檔片段
用CPU內存做二級緩存(但會犧牲延遲)
對個人用戶來說,如果知識庫小於10萬Token,且用DeepSeek或類似低價模型,直接用長上下文是最簡單的方案。不需要搭建向量數據庫,不需要調優檢索參數,把所有筆記塞進去就行。
但如果知識庫更大呢?
🔄 2025年的主流架構:Hybrid Context
“RAG vs 長上下文"這個二元對立在2025年被打破了。
主流架構變成了Hybrid Context(混合上下文):用RAG做寬召回,用長上下文做深推理。
具體流程三步走:
1⃣ 寬召回
用向量檢索+關鍵詞檢索,召回Top-100個相關文檔(約50k-100k Token)。
這相當於把"大海"縮小成"池塘”。
2⃣ 上下文重組
用Rerank模型,把最相關的Top-10文檔放在提示詞的首部和尾部(利用注意力機制),其餘90個文檔放在中間。
3⃣ 長窗口推理
把這100k Token一次性餵給長文本模型。
📊 召回是什麼意思?
召回(Recall)指的是:在所有相關的內容中,找出了多少。
知識庫有1000篇文檔,其中50篇和問題相關。系統找出了40篇,召回率就是80%。召回率越高,意味着漏掉相關內容的概率越低。
召回和精度往往是矛盾的:
召回100篇文檔 → 召回率高,但裏面有很多無關內容(精度低)
召回5篇文檔 → 精度高,但可能漏掉重要內容(召回率低)
“寬召回"就是放寬召回的標準,寧可多找一些。
爲什麼敢召回這麼多?因爲後面還有長上下文模型來處理。模型會自己判斷哪些內容真正相關——這是"深推理"的部分。
🎯 Rerank:把關鍵信息放在"對"的位置
Rerank模型的作用是重新評估"相關性”——不是看語義像不像,而是看對回答這個問題有多重要。
向量相似度只是"語義接近”,不等於"對回答問題最重要"。
舉個例子:用戶問"對比A公司和B公司的研發投入"。召回的文檔裏可能有50篇提到A公司,30篇提到B公司。按向量相似度排序,前10篇可能都是關於A公司的——B公司的信息被擠到中間位置,模型可能忽略。
Rerank模型輸入"問題+文檔",輸出"相關性分數"。它比向量相似度更精準,因爲能看到問題和文檔之間的交互。
但Rerank不是必須的。如果知識庫不大,且查詢不復雜,向量檢索的排序已經夠用。
🔧 不用Rerank的替代方案
方案一:接受精度損失
如果查詢相對簡單,或者對精度要求不高,可以跳過Rerank。長上下文模型本身有一定"抗噪"能力。
方案二:用規則替代
比如關鍵詞匹配度高的排前面、文檔新鮮度高的排前面、文檔來源權威性高的排前面。這比Rerank便宜,但效果取決於規則設計。
方案三:用LLM做Rerank
把問題和文檔摘要一起餵給一個便宜的小模型,讓它判斷相關性。效果可能比專用Rerank模型差,但比規則方法靈活。
建議:知識庫不大(<1000篇文檔)且查詢不復雜,Rerank的價值有限。知識庫很大,或者查詢需要跨文檔推理,Rerank值得投入。開源的Rerank模型(如BGE-Reranker、Cohere Rerank)部署成本不高。
💰 成本對比
假設知識庫有100萬Token:
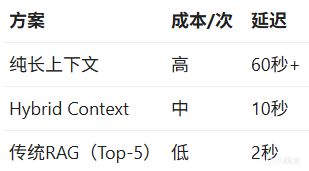
三種方案
Hybrid Context比純長上下文便宜10倍,比傳統RAG貴50倍。
爲什麼不用傳統RAG?因爲傳統RAG的召回率低。Top-5可能漏掉關鍵信息,尤其是需要跨文檔推理的場景。
Hybrid Context的思路是:用稍高的成本,換取更高的召回率和推理能力。
它填補了傳統RAG和純長上下文之間的空白——不是"最便宜"的方案,而是**“性價比最高"的方案**。
📋 三個維度,幫你做選擇
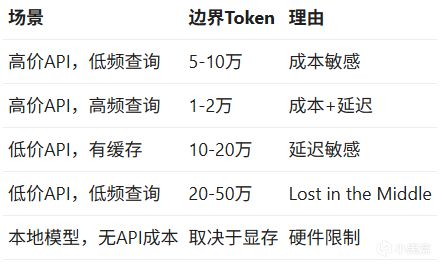
怎麼判斷用哪種方案?看三個因素:成本、延遲、模型能力。
維度一:成本
例如用GPT-4o的價格來算,月查詢量100次的情況下:
10萬Token的月成本是$50,開始有點貴了
50萬Token的月成本是$250,對個人用戶來說不便宜
但如果用DeepSeek V3(帶緩存),10萬Token的緩存後成本是$0.002/次——幾乎可以忽略。
價格信息有時效性,僅供參考,以官方價格爲準
維度二:延遲
大多數用戶能接受的等待時間是10秒以內。按這個標準,邊界大約在10萬Token。
但如果用緩存,第二次查詢的延遲會大幅下降。
維度三:模型能力
這是最硬的限制。
當輸入超過10萬Token時,Lost in the Middle效應開始明顯。模型可能漏掉中間位置的關鍵信息。
可以通過"上下文重組"來緩解——把最重要的內容放在開頭和結尾。但這需要額外的處理邏輯,本質上已經開始接近Hybrid Context的思路了。
📊 綜合判斷
💡 對個人用戶的建議
知識庫<10萬Token:直接用長上下文,不需要RAG。把所有筆記塞進去就行,簡單直接。
知識庫10-50萬Token:考慮Hybrid Context。用簡單的向量檢索召回Top-100,然後餵給長上下文。
知識庫>50萬Token:RAG是必要的。純長上下文在成本、延遲、準確性上都會出問題。
還有一個維度是更新頻率:
知識庫很少更新 → 長上下文+緩存很划算
知識庫每天更新 → RAG更靈活,不需要重新計算緩存
🤖 Agentic RAG:RAG的進化方向
如果關注AI領域,可能聽說過"Agentic RAG"這個詞。它和傳統RAG有什麼區別?
核心區別在於:誰在控制檢索過程。
傳統RAG:固定流程,用戶提問 → 向量檢索 → 返回答案
Agentic RAG:Agent自主決定,需要什麼信息?去哪裏找?要不要繼續檢索?
舉個例子:用戶問"比較A公司和B公司去年的研發投入,並分析對股價的影響”。
傳統RAG的流程:
把問題轉成向量
在知識庫裏檢索Top-K文檔
把文檔餵給模型生成答案
問題:如果知識庫裏只有研發數據,沒有股價數據,模型只能基於不完整的信息回答。
Agentic RAG的流程:
Agent分析問題:需要兩類信息——研發投入 + 股價
Agent先檢索研發數據
Agent判斷:研發數據有了,但缺股價數據
Agent決定:調用股價API獲取數據
Agent整合兩類信息,生成答案
關鍵區別:Agent有"規劃"和"反思"能力。
它不是機械地執行檢索,而是像一個研究員一樣思考:我需要什麼信息?我有了什麼?還缺什麼?去哪裏補?
🔄 Agentic RAG vs RAG作爲數據基座
這是兩個相關但不同的概念。
Agentic RAG:RAG系統自己具有Agent能力,能自主規劃檢索策略、判斷檢索結果是否足夠、調用多種數據源。
RAG作爲數據基座:RAG系統被其他Agent調用,Agent需要數據時調用RAG,RAG只是Agent的一個"工具"。
一個類比:
Agentic RAG像一個"智能研究助理",自己能規劃、執行、反思
RAG作爲數據基座像一個"圖書館",等其他Agent來查資料
它們可以結合:一個Agentic RAG系統,既可以自己作爲Agent完成任務,也可以被其他Agent調用提供數據。
💡 對個人用戶的啓示
Agentic RAG更強大,但也更復雜:
成本更高:可能多次調用模型進行規劃和反思
延遲更長:多輪檢索和推理需要時間
搭建難度更大:需要設計Agent的工作流程
對於個人知識庫,如果查詢相對簡單(主要是事實查詢),傳統RAG或長上下文就夠了。如果需要複雜的多步推理,Agentic RAG可能更有價值。
主流框架(LangChain、LlamaIndex)都提供了Agentic RAG組件的封裝,搭建門檻比想象中低。
🎯 回到最初的問題
2026年了,搭建自己的知識庫還需要RAG嗎?
答案不是簡單的"需要"或"不需要"。
RAG沒有死,但RAG的定義被重寫了。它不再只是"檢索工具",而是正在進化爲AI Agent的"神經中樞"——上下文引擎、數據基座、記憶系統。
對於個人知識庫:
數據量小、查詢簡單 → 長上下文可能是更簡單的選擇
追求更低成本、更快響應、更靈活擴展 → RAG依然值得投入
真正重要的不是選擇RAG還是長上下文,而是理解它們各自的邊界和協同方式。
2025年的主流架構是Hybrid Context——用RAG做寬召回,用長上下文做深推理。這種"檢索前置,長上下文容納"的範式,可能是未來幾年的最優解。
而Agentic RAG代表的是另一個維度的進化:從"被動檢索工具"向"主動智能系統"的轉變。
這個方向處於快速發展期,剛剛開始走向成熟。
感謝大家的耐心閱讀,這篇文章是上篇文章Skill到底是什麼,會影響以後用AI的方法嗎?的投票結果決定的。對於問題:文檔數量大時怎麼優化RAG,看完這篇文章相信心裏也已經有思路了。
如果還有什麼想看的內容,歡迎在評論區告訴我。同時放出新一期的選題投票
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















