
Tips:文末有在線體驗地址
上週,一家叫 Taalas 的加拿大公司從隱身模式裏鑽了出來,帶着一塊芯片和一句 slogan:
The Model is The Computer(模型就是計算機)
翻譯成人話就是,他們把 AI 模型的權重和架構直接硬編碼進了硅片裏。
注意噢,模型不是跑在芯片上,是模型變成了芯片本身。
模型的每一層、每一個權重都是芯片上的物理線路,電流走一遍就出結果,沒有內存處理,沒有軟件調度。

Taalas HC1 硬連線 Llama 3.1 8B 型號
這個思路乍一聽挺離譜的,有一種回到了幾萬年前原始人在石頭上刻字的既視感。
自前兩年 AI 潮以來,大家都在卷誰的 GPU 更猛、誰的顯存更大、誰的互聯帶寬更高,,,
但 Taalas 直接掀桌子大手一揮:
軟件棧?不需要。散熱液冷?更不需要(Taalas HC1 TDP 僅250w)。
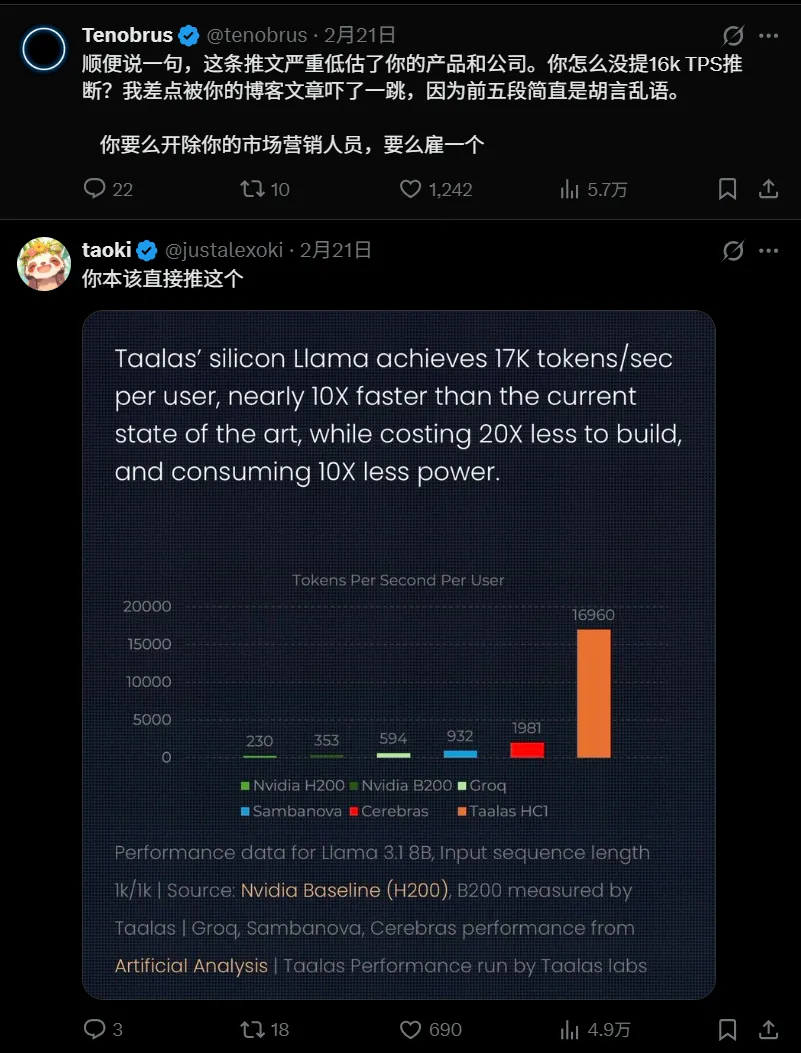
他們把 Llama 3.1 8B 蝕刻進一塊 6nm、815 平方毫米的硅片裏,塞了 530 億個晶體管,在功耗僅 200 多瓦的前提下,推理速度幹到了每秒 17000 tokens!
什麼概念呢?
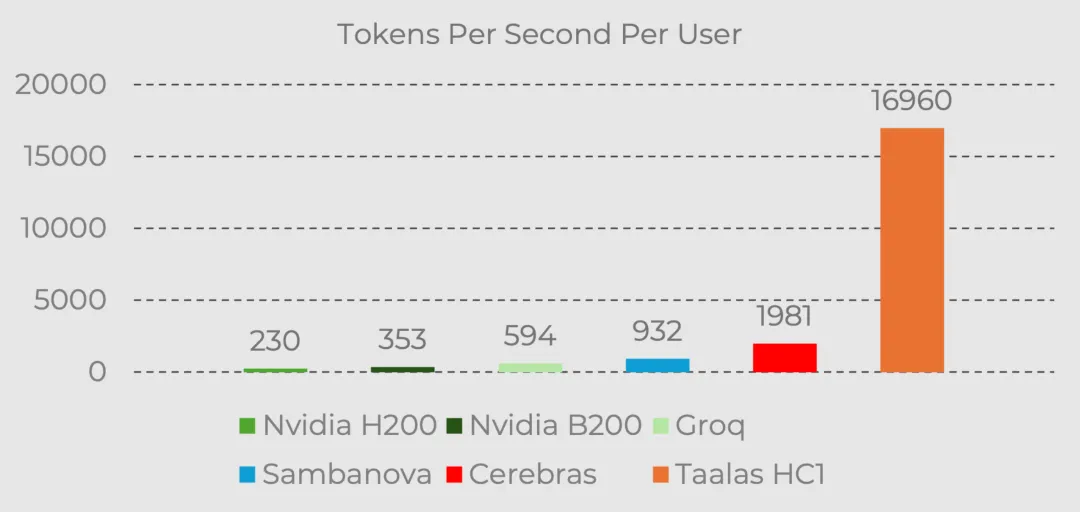
目前推理速度的天花板 Cerebras 大概是 2000 tokens/s,Groq(LPU,張量流處理器架構) 是 594,NVIDIA 的 B200 才 353。
對 Cerebras 沒概念?簡單點理解其實就是超大GPU👇
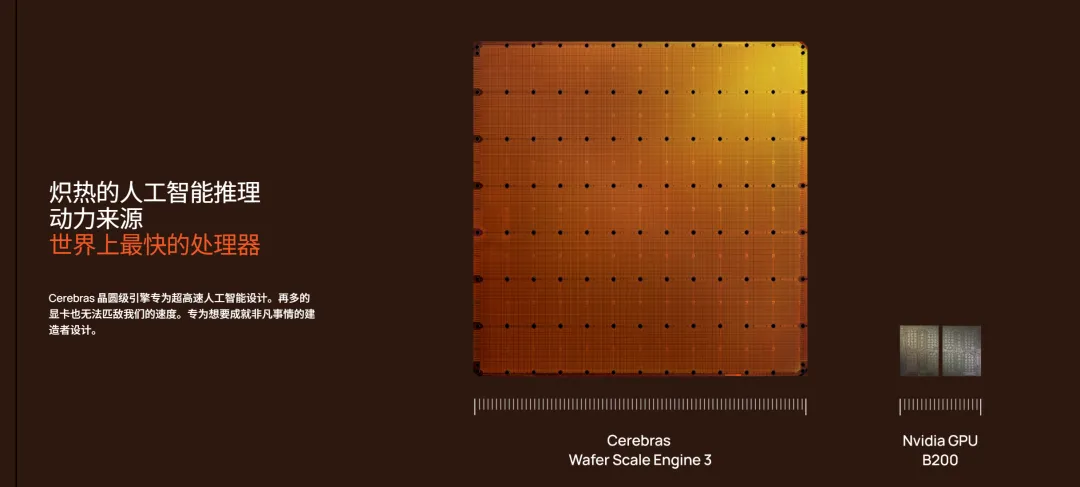
Taalas 的 HC1 是 Cerebras 的將近十倍,是 B200 的快五十倍,其官方給出的實測 demo 裏跑出過 16960 tokens/s,一整條回覆 0.138 秒就吐完了。
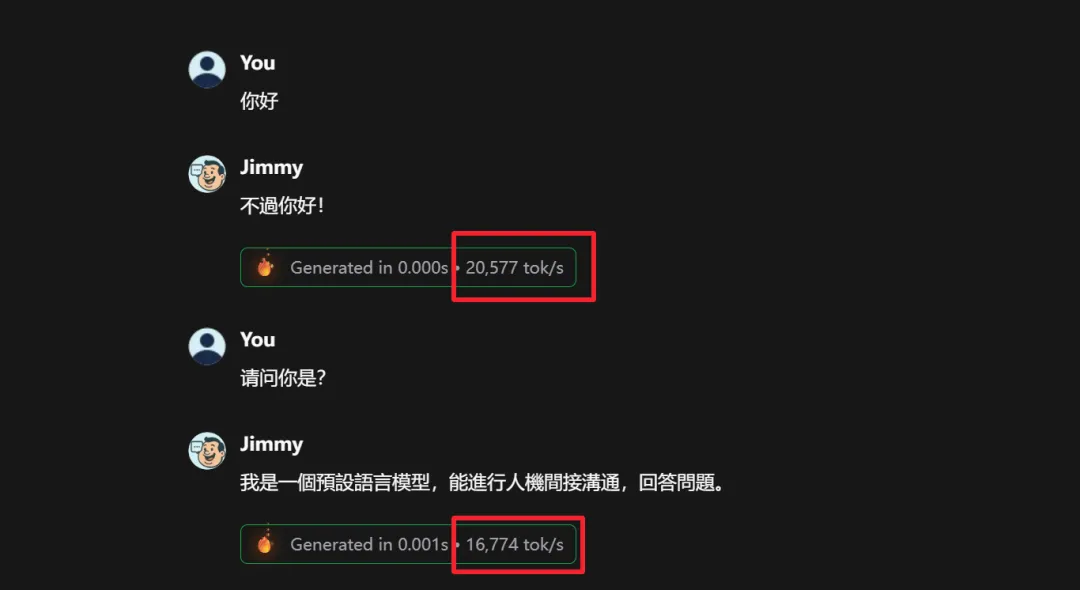
我去他們的 demo 站 chatjimmy 實際試了一下,體驗確實很魔幻。
回覆基本是瞬間出現的,不是一個字一個字蹦,是整段話啪地糊你臉上,跑出來的素服甚至比其官方聲稱得更快,快到你會懷疑它是不是提前緩存好的。👇
但聊了幾輪就發現問題了:這玩意兒挺弱智的。
問它稍微難點得問題,回答質量肉眼可見地拉跨,更別提邏輯推理了,基本沒這方面能力,偶爾還會胡言亂語。
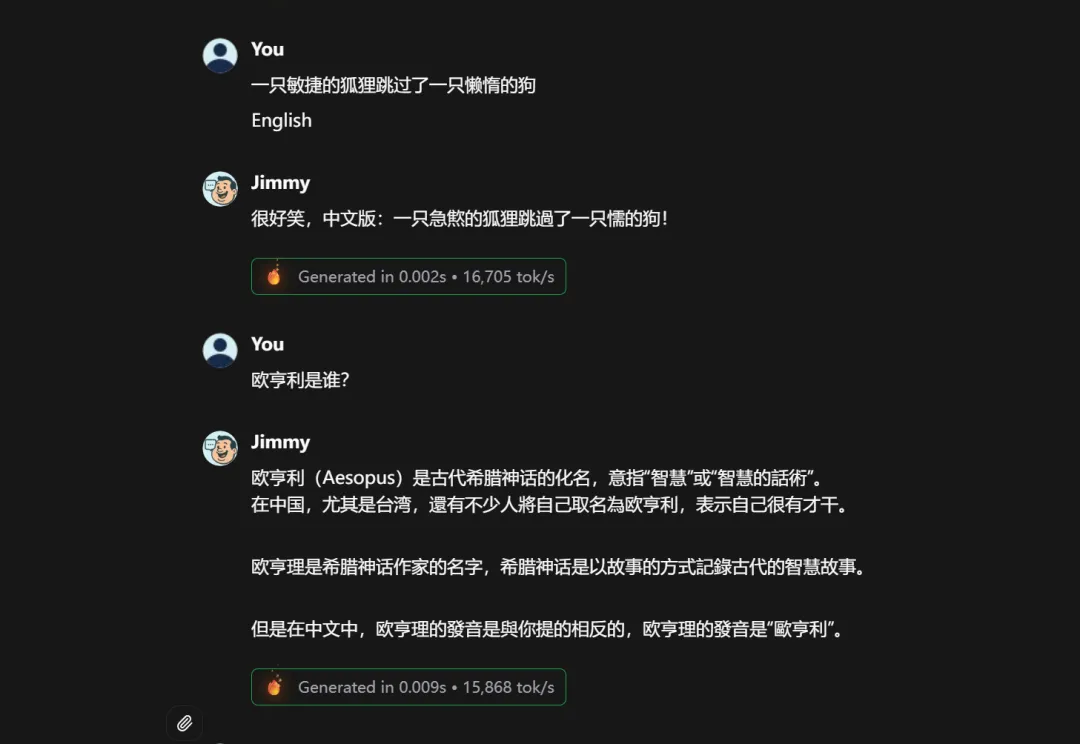
不過這也正常,底層是個 8B 參數的模型,還被激進量化到了 3-bit,能保持基本對話流暢已經算超常發揮了。
速度極快,聰明程度明顯不夠,這就是 HC1 目前最真實的狀態。
“說100000次你好”然後我成功吧模型乾死了
所以 Taalas 做的事情本質上是一個極端的工程權衡:用模型靈活性換推理速度。
以及,這種玩法,這讓人很自然地想到一個老朋友:ASIC 礦機。

專門挖門羅幣的礦機
熟悉挖礦歷史的人對這條路線不會陌生。
比特幣早期大家用 CPU 挖,後來換 GPU,再後來出現了專用礦機,效率直接把 GPU 按在地上摩擦。
但代價是隻能幹一件事,以太坊換個算法它就成了電子垃圾,同理,模型只要一迭代,你之前生產的芯片某種程度上就成爲“過時的”了。
不過瑕不掩瑜,在很多人看來,就算有這個致命的軟肋,其令人咋舌的推理速度,也足以彌補其缺點。
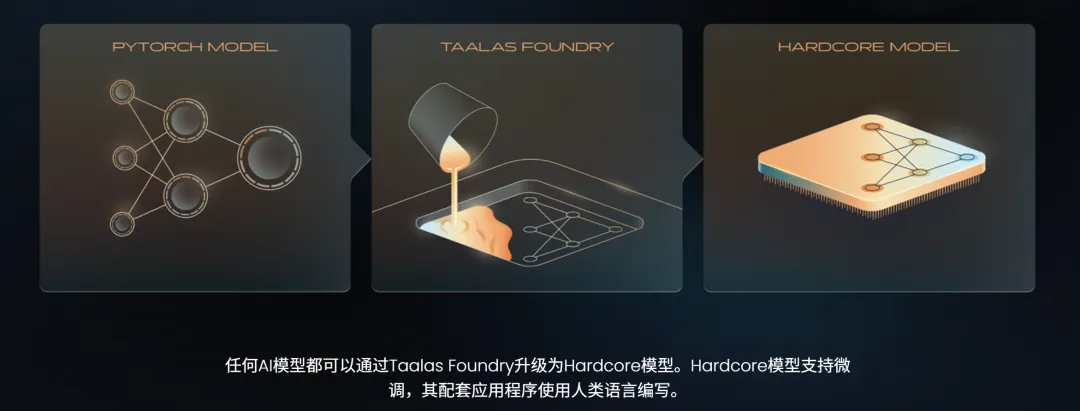
當然,Taalas 自己也知道模型焊死就不能換這個軟肋,他們搞了個叫 Taalas Foundry 的自動化平臺,說是從拿到一個新模型到流片出芯片只要 60 天。
芯片還支持 LoRA 微調和可配置上下文窗口,算是在完全固化和靈活適配之間找了個折中。
對了,Taalas 這個團隊背景也值得說一嘴。
CEO Ljubisa Bajic 是 Tenstorrent 的聯合創始人,之前在 AMD 和 NVIDIA 做架構師。

另外兩個聯合創始人 Drago Ignjatovic 和 Lejla Bajic 也是 Tenstorrent 早期的人。
整個團隊人很少,一共才 24 個人,3000 萬研發費(還沒用完),做出一塊 530 億晶體管的推理芯片.....這個投入產出比確實有點嚇人。
但冷靜想想,挑戰也很現實,正如前面提到的,現在的 AI 模型的迭代速度是以月爲單位的——今天你把一個模型刻進芯片,下個月後更強的模型出來了,這塊芯片的競爭力就打折了。
60 天流片聽起來快,但加上驗證、量產、部署,實際週期可能要半年,半年在這個行業夠發生很多事了。
而且 17000 t/s 的速度雖然炸裂,但對於大部分應用場景來說,人類的閱讀速度纔是瓶頸。

你一秒吐一萬七千個 token 給我,我又不是機器,看不了那麼快,對吧?
真正能喫下這個速度的場景其實比較垂直:實時語音交互、虛擬人驅動、邊緣設備推理、高頻 API 批量調用這些對延遲極度敏感的領域。
好消息是他們的路線圖顯示,2026 年冬天會推 HC2 平臺,支持 20B 甚至更大的模型,多片拼接能跑到單用戶 12000 t/s 以上,每百萬 token 成本壓到 7.6 美分,只有 GPU 方案的一半。
如果真能把前沿大模型燒進去還保持這種速度優勢,那故事就完全不一樣了。
說到底,Taalas 提出的問題比它給出的答案更有價值:當開源模型質量夠用、推理需求大規模爆發的時候,我們還有必要用通用 GPU 這把瑞士軍刀去幹專用螺絲刀的活嗎?
NVIDIA 靠通用性喫下了整個 AI 市場,但通用性本身就意味着冗餘。
如果未來的推理負載真的集中在少數幾個主流模型上,那"把模型變成硬件"這個思路可能沒有聽起來那麼瘋。
當然,也可能 Taalas 最終只是 AI 硬件浪潮裏一個有趣的註腳。

但至少現在,它讓所有人重新想了一個問題:我們是不是一直在用大炮(GPU)打蚊子(跑模型)?
在線體驗地址:https://chatjimmy.ai/
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com













