在AI领域一路高歌猛进的NVIDIA,在CES 2026上也没有忘记将注意力放在游戏上。黄仁勋CES 2026特别演讲过后,笔者有幸参观了GeForce RTX新技术展示区,一整套游戏新技术组合拳着实带劲,比如DLSS 4.5动态多帧生成最高可以将帧率提升6倍,G-SYNC Pulsar显示器也终于蓄势待发,围绕RTX AI PC构建出的创作生态也展现出了全新可能,趁着现场体验,不妨让我们直观的感受一下GeForce RTX给PC带来的更多可能性。

DLSS 4.5:游戏帧率暴增6倍
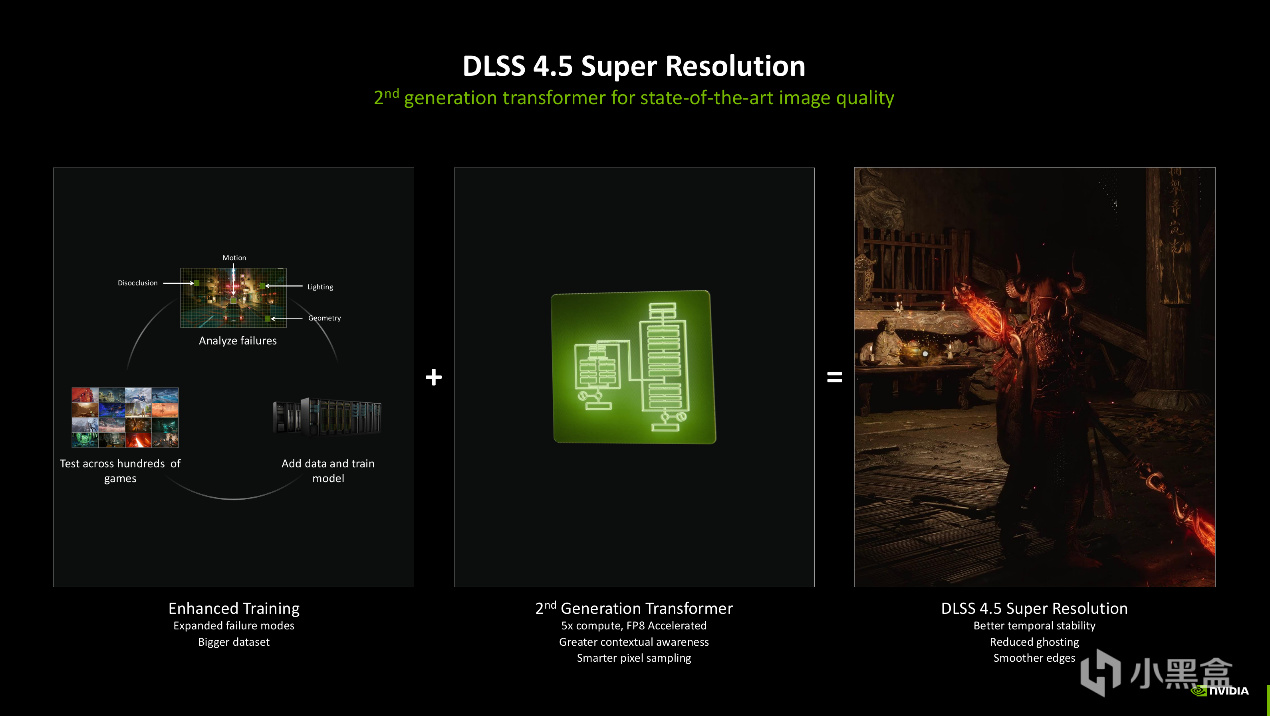
DLSS 4.5带来的最重要的更新之一是第二代Transformer和DLSS 4.5 超分辨率模型。它的工作方式在AI服务器集群上将画质训练提升至16K分辨率下开启路径追踪画质作为最终参考帧,针对游戏新增700+小时的录像训练,并重点采集高运动、高对比、粒子密集的场景,确保画质提升有更多可能性。

同时DLSS 4.5也首次引入大模型训练中常见的反向标注方式,通过人工和AI的方式找到原来模型训练中鬼影、撕裂、闪烁的反向样本,然后针对性进行训练,以避免DLSS开启后可能产生的不真实感。
这些DLSS 4.5的训练都是在H100上通过FP8精度训练超过六周完成的。由于FP8只能在Blackwell,也就是GeForce RTX 50系列GPU上实现,GeForce RTX 40以前的GPU在运行DLSS 4.5的时候则会使用FP16完成,在画质相同的前提下,GeForce RTX 50系列无疑更有优势。
在帧生成过程中,Transformer 模型会把前后4帧的运动矢量、深度、粗糙辐照度一起送进注意力,提前预测遮挡,进而将鬼影可能性降低42%。同时还会在1/4分辨率下运行一次边缘检测,进而补偿几何边缘可能出现的损失,让抗锯齿AA质量提升0.8 dB LPIPS。与此同时,粒子/透明支路有所增强,避免火焰、雨水、UI因为开启DLSS之后被抹掉,最显著的例子就是火焰迸发出的火星得意保留。
在提前沟通会上,NVIDIA展示了《心灵杀手Remastered》手电筒高速会动时候残影情况,原本会出现至少3层残影的手电筒光照现在降低到了1层。《天国:拯救2》中木纹桌面上的抖动完全静止。《夺宝奇兵:古老之圈》中铁栏的断裂情况概率显著降低。


即将发布的《影之刃零》也同样会在新技术中受益,由于《影之刃零》注重细腻的雨水渲染场景气氛,传统方式会模糊雨滴的细节,让画面产生模糊感,DLSS 4.5中的第二代Transformer 模型很好解决了这个问题,在大幅提升帧率的同时,还能获得更为细腻和清晰的沉浸感,显然也是玩家最愿意见到的。

得益于FP8加持,第二代Transformer模型可以帮助Blackwell GPU在不增加任何能耗的前提下提升相应速度,例如140W GeForce RTX 5080 Laptop GPU笔记本获得更好的画质和帧率后,功耗没有任何提升。
在这个基础上,引入6x的Dynamic Multi-Frame Generation动态多帧生成变得顺理成章。以往的帧生成是按照原生帧和生成帧的固定比例完成的,比如DLSS 3的1:1,即1帧原帧,1帧生成帧,DLSS 4的1:3,即1帧原帧,3帧生成帧。在动态多帧生成下,帧生成变成了0-5帧随机调整,这样做的目的是让帧生成永远吃满显示器VRR上限。
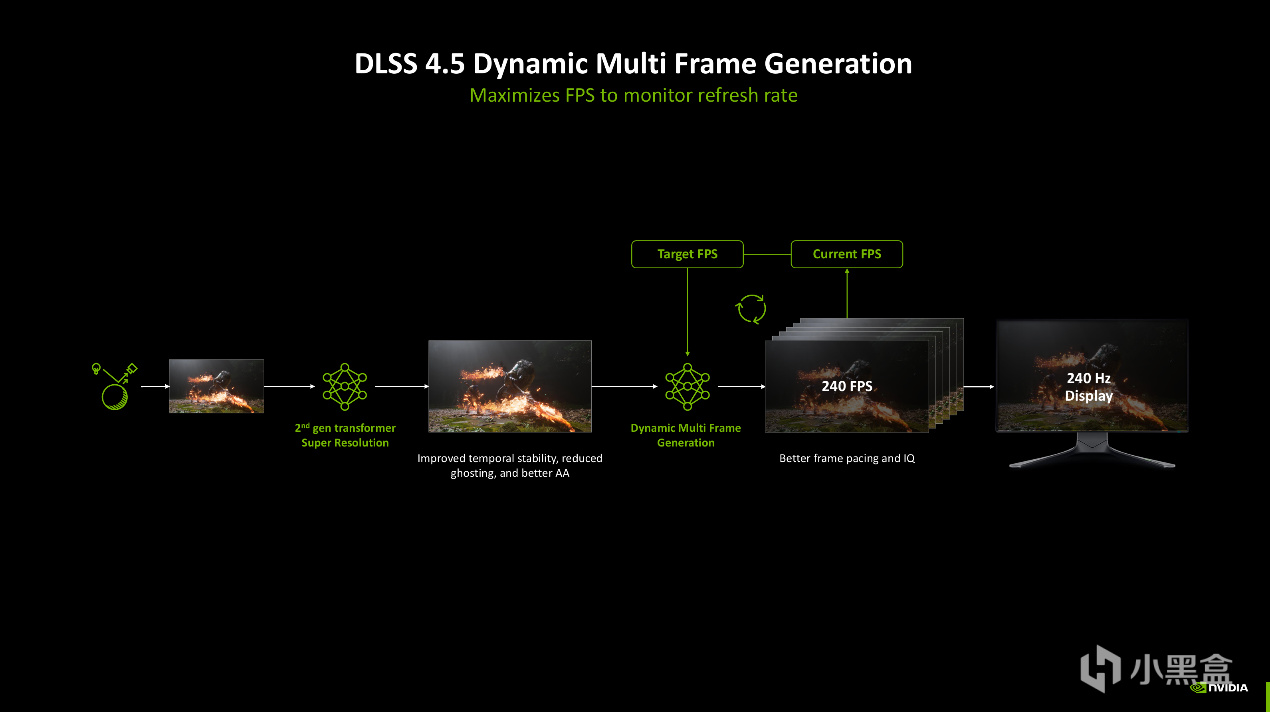
比如显示器有240Hz刷新率,那么动态多帧生成就会泡在240FPS,没必要运算出更多的帧率,即浪费GPU资源,还增加系统延迟。
NVIDIA在启动中埋入了2ms为单位的检测动作,即每2ms查看GPU占用率,帧时间抖动情况,显示器实时刷新率,根据实际情况做出调整。根据这三个变量实时调整,在16.7ms内就能完成0到5帧生成的来回切换,做到6x动态多帧生成。

配合第二代Transformer,帧生成会先做1/4分辨率的全局运动判断,然后向上逆采样,进而节省显存带宽。在技术上还增加了遮挡置信图,主要是防止UI、十字准心、血条在帧生成状态下闪烁的问题。
在现场《黑神话:悟空》体验中,最高特效开启DLSS 4.5后,会自动将游戏帧率匹配到4K 240Hz显示器的上限,可以看到右侧成功开启了6x多帧生成,且系统延迟没有降低。将帧率维持在显示器上限另一个好处就是不会浪费额外帧率计算的功耗,对于节能而言更有效果。

事实上现场展示的GeForce RTX 50系列Laptop GPU就使用了类似的结束,在《赛博朋克2077》中,开启DLSS 4.5不仅获得了更好的画质,同时也没有超额消耗GPU资源,能够确保笔记本更容易低发热、风扇安静的前提下运行。

G-SYNC Pulsar蓄势待发
NVIDIA G-SYNC Pulsar定位高端电竞显示器认证,即把NVIDIA G-SYNC算法和协议一次性做到27英寸电竞显示器中,从而获得360Hz高刷、1000Hz感知运动清晰度,提供环境光感应,并且能够直接检测Reflex延迟。首发的四款产品型号包括:
– AOC AGON PRO AG276QSG2
– Acer Predator XB273U F5
– ASUS ROG STRIX XG27AQNGV
– MSI MPG 272QRF X36
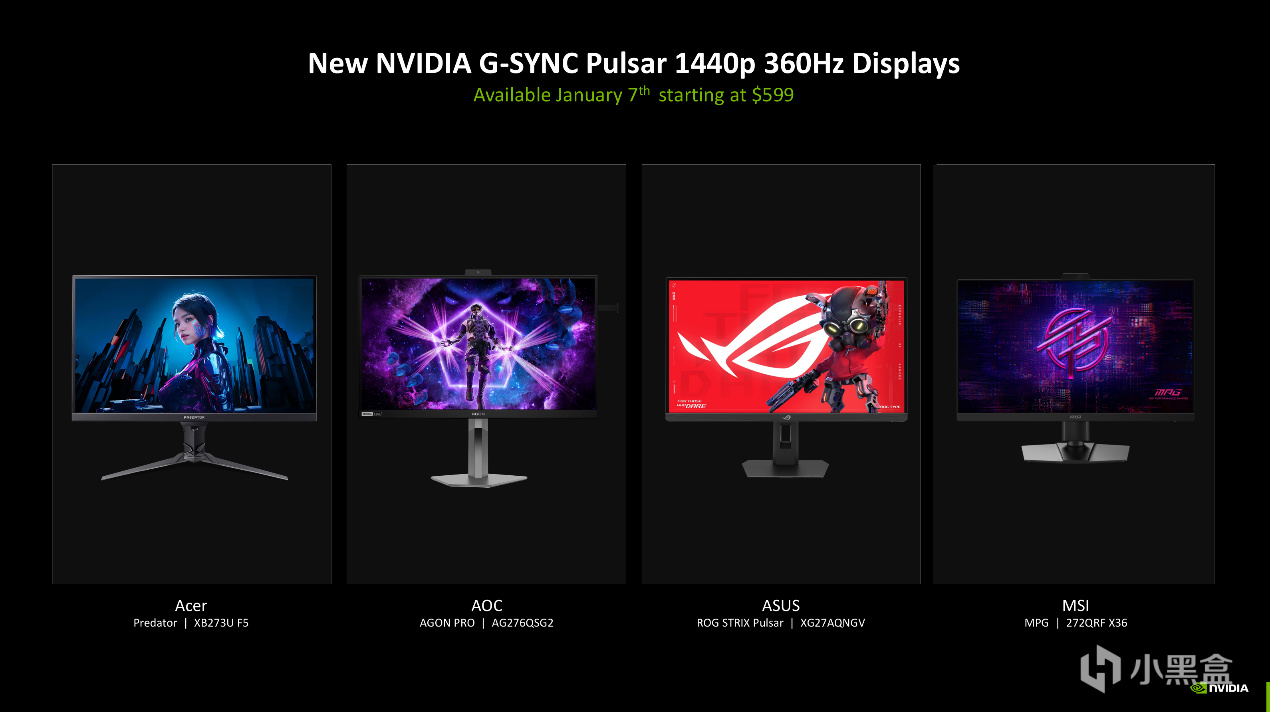
不过NVIDIA G-SYNC Pulsar显示器并非第一次发布,此前NVIDIA已经公布了技术白皮书和Project Pulsar计划,这次G-SYNC Pulsar显示器终于算是开售,并与时俱进增加Ambient Adaptive环境光传感器、Reflex Analyzer USB-C等细节。
现场用《守望先锋2》和《纪元117:罗马和平》进行了对比。由于NVIDIA G-SYNC Pulsar显示器可变频率背光频闪技术,实现超过1000Hz的有效动态清晰度,大幅提升动态画面的清晰度和可见性,即使是同样的帧率,仍然可以直观感受到G-SYNC Pulsar有着更为明显的清晰度,敌人和画面移动更为清晰流畅。


RTX Remix Logic:一步到位加个氛围
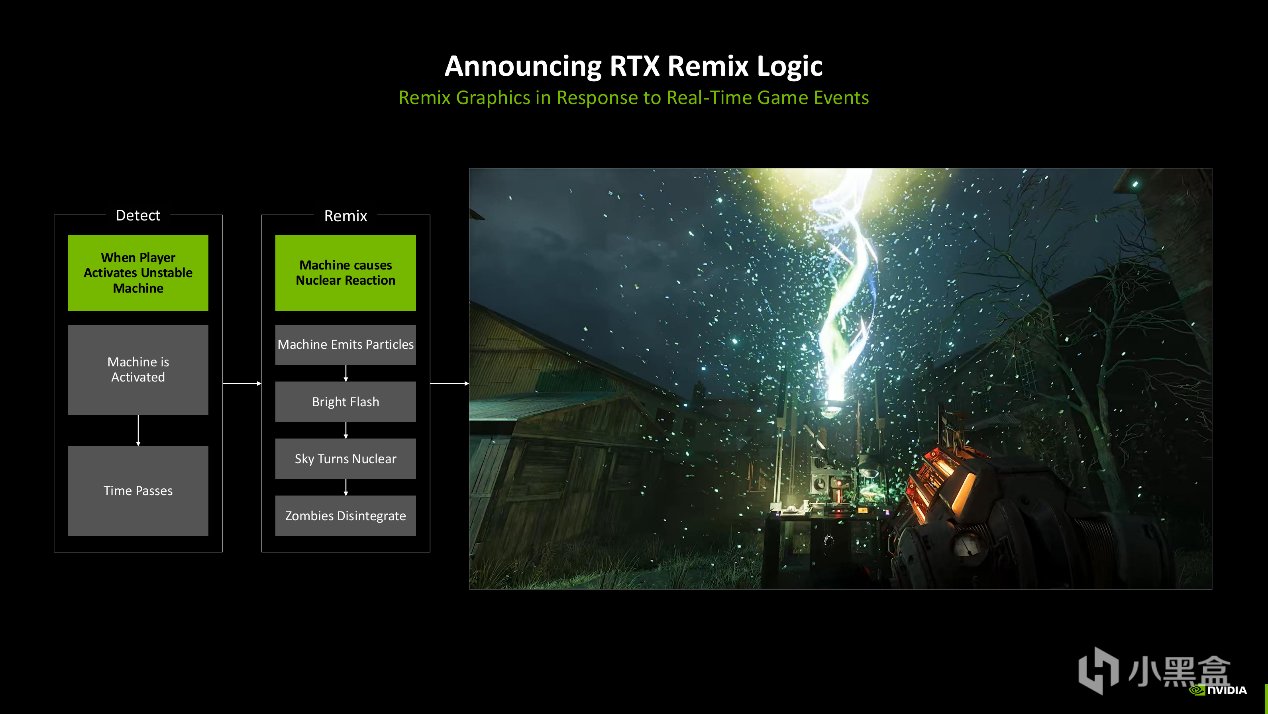
RTX Remix的使用逻辑是在原游戏的基础上,通过全局替换的方式给经典老游戏换上高清材质、模型和光追效果。RTX Remix Logic则是更进一步,相当于在渲染管线上增加了一条无代码的事件总线,让游戏画面可以随着游戏中的变量,比如主角血条、关卡、开关、NPC状态等随时变换,这些动作在RTX Remix上都是需要创作者手动一个一个调整的,现在可以一步到位了。
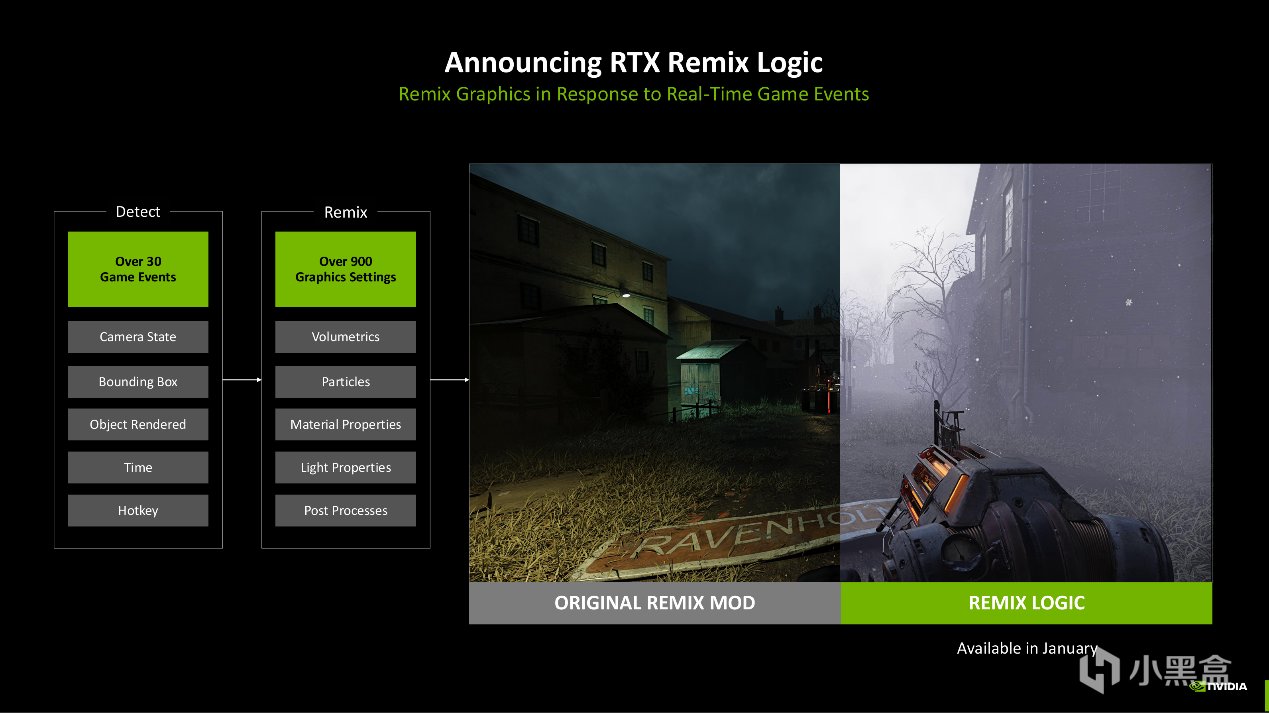
这个过程的实现原理是Remix Runtime把DirectX 8和DirectX 9 Draw Call拦截到USD场景图中,将超过30种游戏事件注册成命名信号,随后依靠逻辑层Node-Graph UI绑定到超过900种图形参数中做匹配。比如天气中的体积雾密度、散射颜色,材质的粗糙度、自发光强度,后处理中的曝光、色散、暗角等。
最后RTX Remix Logic可以在渲染层将节点编译成USD层栈,实时Hot-Reload,0.3 ms内完成切换,无需重启关卡,对于Modder而言,所见即所得的游戏重置体验,五一是很酸爽的。

这意味着整个过程中,创作者即使不会C++语言,Modder也能做到随着剧情需要切换光追天气变化,并且创作节点可以随时复用,可以直接将RTX Remix Logic的文件复制给其他游戏关卡或者游戏,实现同样的效果。在SDK的生态中,社区已经准备好了Blender和Substance插件,这个过程可以一键导入。
NVIDIA计划将RTX Remix Logic在1月份的Remix 2025.1 SDK中添加,并且已经给50位《半衰期2 RTX》创作者提前内测,后续会在GitHub中同步开源示例节点图。NVIDIA在现场也提供了《半衰期2 RTX》演示DEMO,比如推开门后检测到事件,游戏环境中的体积雾、冷色调体积光线、落叶粒子瞬间切换到冬季预设。

游戏中敌人靠近但尚未进入主角视野,也会出发隐藏敌人事件,RTX Remix Logic随即做出对应的Paranoia滤镜效果,包括脉冲暗角、色差强度随距离线性提升,UI血条边缘同步闪烁。

当玩家在《半衰期2 RTX》游戏中启动机器,引发MachineActivate事件,时间轴节点依次拉高粒子速率、屏幕泛白、最终核爆闪屏,敌人角色被同步消灭的着色器也随之被触发。
RTX AI:3分钟内生成4K视频
NVIDIA ACE也迎来了全面升级,可以在本地运行14B大模型,并且支持RAG检索实时独挡。整个功能链路在本地实现,无需联网,但需要6GB的常驻显存,如果后期使用FP4量化之后,可以压缩到3.8GB左右。
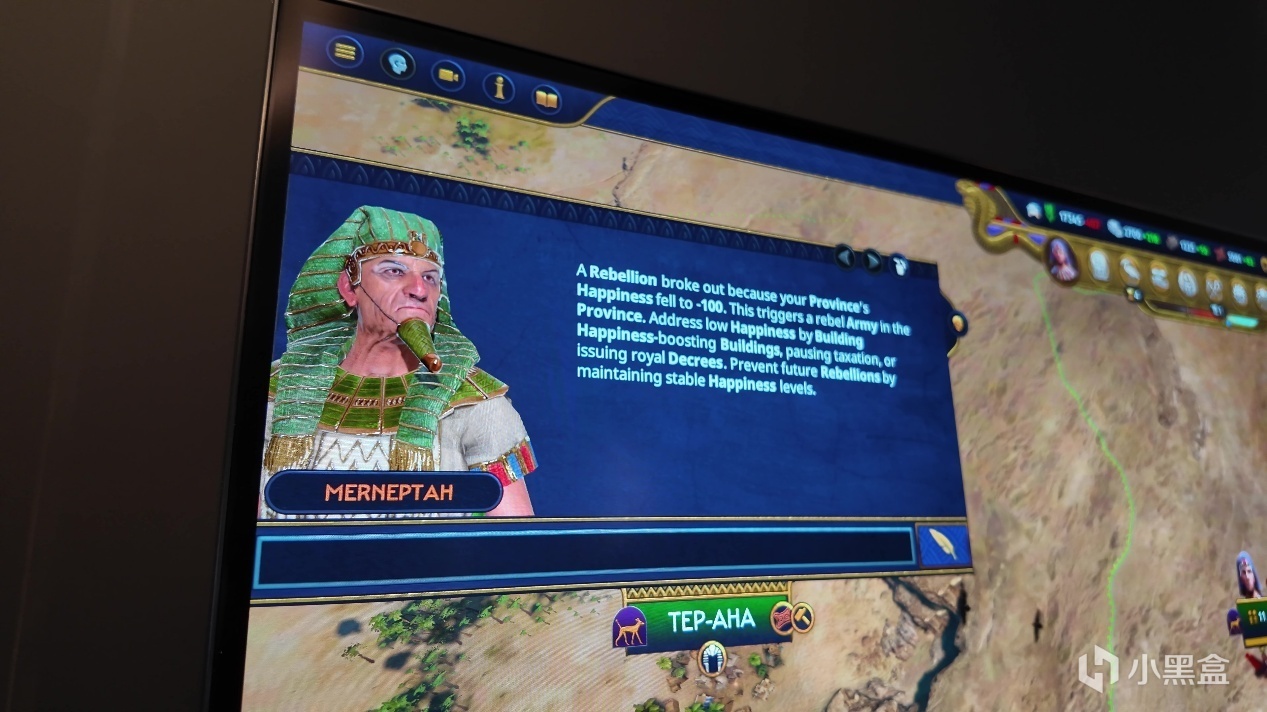
NVIDIA ACE可以做到根据游戏实时状态进行RAG检索,以现场展示的《全面战争:法老》为例,新版的NVIDIA ACE会把每个回合中的经济、外交、兵力、科技树情况导入向量库进行判断,整个过程只需要80ms不到的延迟。

比如玩家问游戏中为什么忽然产生叛乱,NVIDIA ACE主导的游戏顾问会以自然语言的形式总结原因,并且提供对应的决策。或者玩家提出下一步的方向,让游戏顾问根据玩家希望的方向指定游戏中的策略,确保游戏顺利进行。有意思的是,NVIDIA ACE还可以根据游戏场景切换到不同的角色,比如在扮演埃及国王的时候,游戏顾问是埃及祭司,还会发出法老腔音色给游戏产生沉浸感。
这一套NVIDIA ACE至少需要GeForce RTX 4070 8GB以上的显存才能进行,NVIDIA也推荐12GB显存以上保证游戏体验。首发将支持中文、英语、日语和德语,后续语种会在2026 Q2后追加。

随着NVFP4和NVFP8量化付诸实践,模型体积还可以降低60%,显存需求也同步降低40%到60%,并且支持Tensor Core原生指令,不再依赖于Hopper或者Blackwell GPU中的专属硬件,这也是NVIDIA近期技术发展趋势之一。
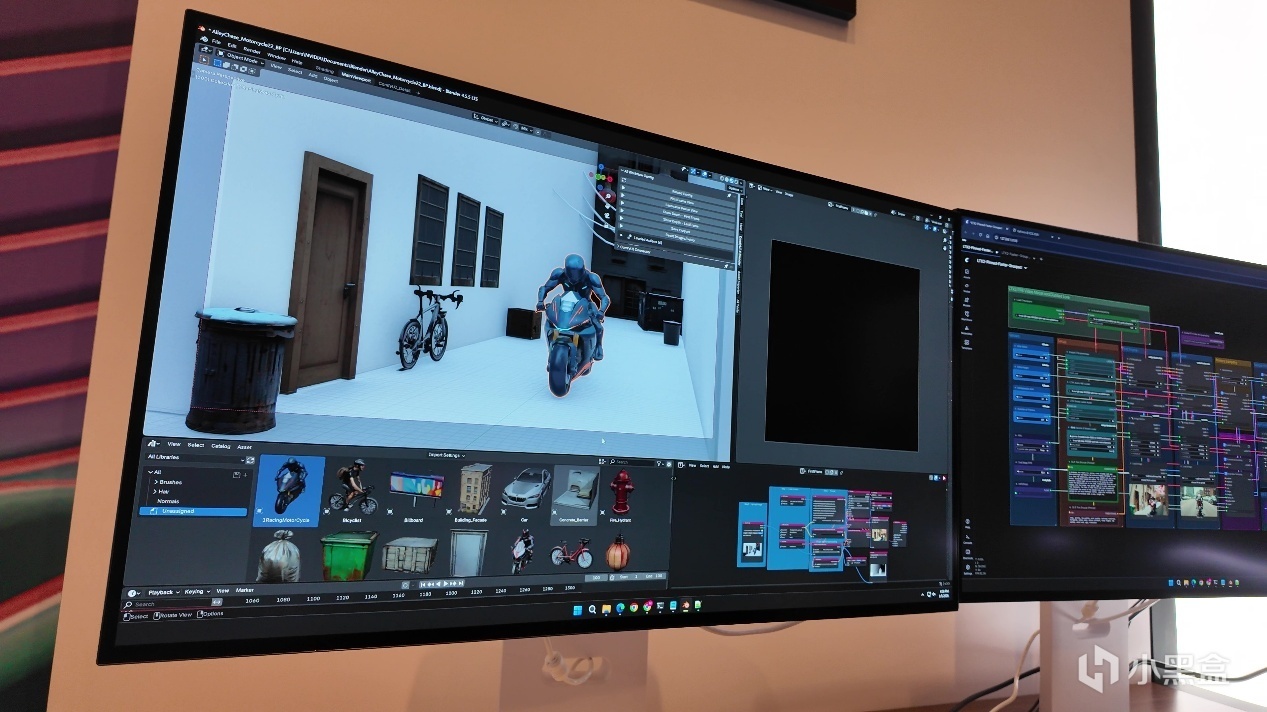
在现场NVIDIA展示通过PyTorch-CUDA形式将FLUX.1生成速度提升3.7倍,并且在显存用满之后,自动切换到DDR5内存,FLUX.2 87GB在本地AI PC上完成4K图生图也完全没有问题。

NVIDIA描述了这一套升级组合拳带来的可能性,创作者可以通过文本Qwen SLM直接生场景描述,然后利用Trellis 3D建立基础模型并通过Blender手动调整需要的摆放位置。随后通过FLUX Image直接完成4K起始帧和结束帧。并通过LTX-2模型完成720p的视频输出,最后通过RTX Video Super-Resolution将视频分辨率提升至4K。

如果通过GeForce RTX 4090在FP 16上运行,上述一套工作至少需要8分钟,但通过GeForce RTX 5090 FP4,现在只需要3分钟就能完成了。NVIDIA表示FLUX.1/2 NVFP4、LTX-2模型会在发布活动结束后同步在HuggingFace 和ComfyUI上线,RTX 视频超分辨率则会在2月份融入到ComfyUI中。
重点是这一套功能都是免费的,所有功能都是基于GeForce RTX 50系列GPU实现,从而获得效率最大化。
DGX Spark:性能瞬秒M4 MAX
在演示现场,我们也看到了近期刚刚开卖的NVIDIA DGX Spark。
NVIDIA将DGX Spark定位一款紧凑型 AI 超级计算机,它可以独立使用,也可以作为家用服务器中的一员,通过PC、MAC或者其他设备访问使用,定制化Linus平台意味着对模型的广阔兼容性,也使得家里任何设备都有机会拥有AI加速的超级算力。

在CES 2026上,NVIDIA发布了Spark的重大AI性能更新,使其相较于不到三个月前首次发布时,最高可获得高达2.6倍的性能提升。在展示区,工作人员通过使用旗舰款MacBook Pro M4 MAX笔记本与NVIDIA DGX Spark进行性能比较。
通过ComfyUI动态调节一段4K高清视频,将视频中的绿色跑车调成红色。两者同时开始运行。NVIDIA DGX Spark利用NVFP4的优势在数秒内就完成了颜色切换,同样的操作在顶配的MacBook Pro M4 MAX上运行超过三分钟,差距非常大。
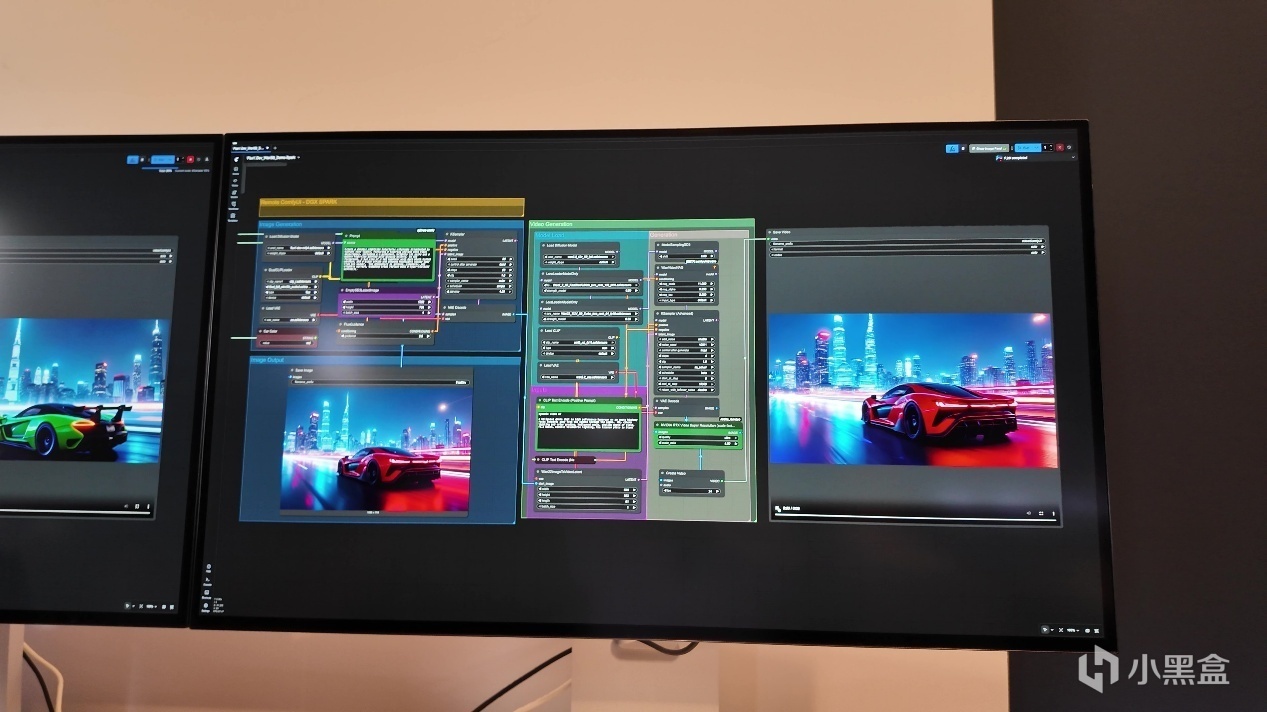
有意思的是,现场展示的NVIDIA DGX Spark利用旁边的MacBook Pro即可直接访问,省略大量的调试和部署成本,足以一窥Spark的便利性。

写在最后:
无论是将14B模型的NVIDIA ACE塞入游戏顾问中,让游戏体验获得深入的一对一指导,再或者3分钟内从无到有生成一整套高规格的4K视频,不发布任何新硬件的前提下,GeForce RTX 50系列的AI含金量依然在持续提升。


对于N卡用户而言,软件和技术的免费升级也已经成为日常显卡增值的一部分,虽然CES 2026没有发布新款的消费级GPU,但一波迅猛的软件升级,对于已经配好GeForce RTX 50系列AI PC的同学而言,显然已经赚翻了。


更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com















![[6月26夏促第二弹]——30款平价游戏推荐,最低价仅需3元!](https://imgheybox1.max-c.com/web/bbs/2026/06/26/ba0fd9cdbf0e5489453a605ce7cd90c1.png?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)

