一、基本架構與組件
1. CUDA核心(僅限NVIDIA):NVIDIA GPU中的基本計算單元,用於執行並行計算任務,如浮點和整數運算。
2. 流處理器(AMD):AMD GPU中的基本計算單元,類似於NVIDIA的CUDA核心,用於並行處理圖形和計算任務。
3. 張量核心(Tensor Core,僅限NVIDIA):專門用於加速深度學習和人工智能任務的硬件單元,能夠高效執行矩陣運算。
4. 光線追蹤核心(RT Core,僅限NVIDIA):專門用於加速光線追蹤計算的硬件單元,提高圖形渲染的真實感。
5. 計算單元(CU,AMD):AMD GPU中的計算單元,包含多個流處理器和其他資源,用於並行處理任務。
6. 流式多處理器(SM,NVIDIA):NVIDIA GPU中的核心計算單元,包含多個CUDA核心、張量核心和其他資源。
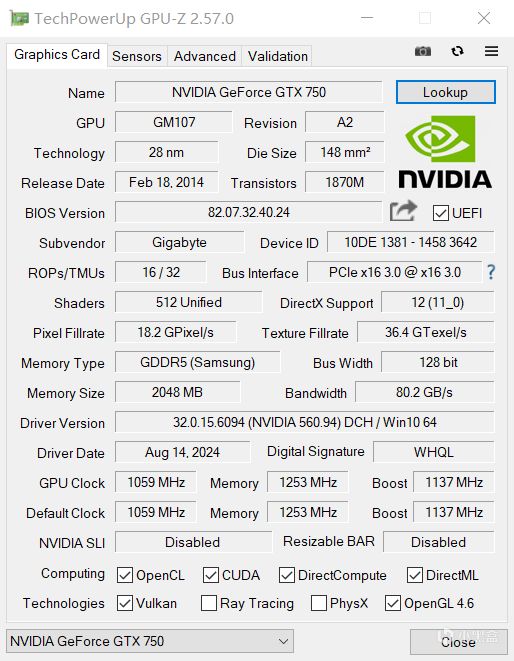
二、顯存與帶寬
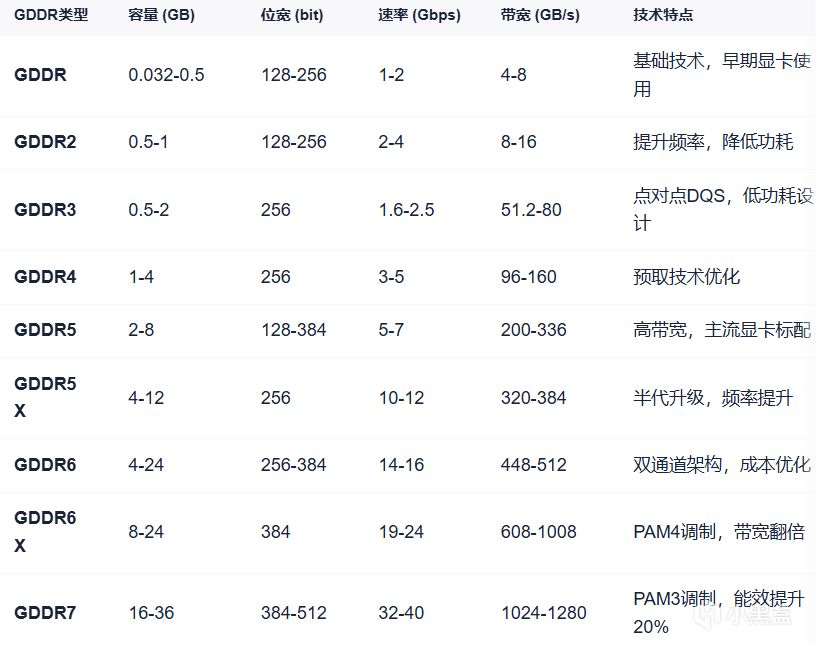
7.GDDR5/GDDR6:不同代的顯存類型,GDDR6相比GDDR5提供更高的速度和帶寬。
8. HBM/HBM2/HBM3(High Bandwidth Memory):不同代的高帶寬顯存技術,通過堆疊多個內存芯片來提高帶寬和容量。
9. 顯存帶寬:衡量GPU與顯存之間數據傳輸速度的指標,影響GPU處理高分辨率和複雜圖形任務的能力。
10. 顯存容量:GPU用於臨時存儲圖像數據的內存容量,越大處理複雜圖形任務的能力越強。
三、性能指標與技術
11. 浮點運算能力(FLOPS):衡量GPU計算性能的重要指標,表示每秒可執行的浮點運算次數。
12. TFLOPS(TeraFLOPS):每秒萬億次浮點運算,用於衡量高端GPU的計算能力。
13. 光線追蹤性能:衡量GPU在光線追蹤技術中的表現,影響圖形渲染的真實感。
14. NVLink(NVIDIA):NVIDIA的高速互連技術,用於連接多個GPU,提高數據傳輸速度。
15. Infinity Fabric(AMD):AMD的高速互連技術,用於連接GPU和其他系統組件,提高整體性能。
四、編程與並行計算
16. CUDA(Compute Unified Device Architecture):NVIDIA的並行計算平臺和編程模型,允許開發者利用GPU進行通用計算。
17. HIP(AMD):AMD的異構編程接口,兼容CUDA代碼,允許在AMD GPU上運行。
18. 線程(Thread):GPU中的最小執行單元,多個線程並行執行以實現高性能計算。
19. 線程塊(Block):多個線程的邏輯分組,可以共享內存並同步執行。
20. 網格(Grid):多個線程塊的集合,構成一個完整的並行計算任務。
五、其他關鍵技術
21. DLSS(Deep Learning Super Sampling,NVIDIA):基於深度學習的圖像超採樣技術,提高遊戲幀率同時保持圖像質量。
22. FSR(FidelityFX Super Resolution,AMD):AMD的圖像超分辨率技術,通過算法提高遊戲幀率。
23. 稀疏技術(Sparse Technology):通過減少模型中的參數數量來提高計算效率,適用於深度學習模型。
24. 混合精度訓練(Mixed Precision Training):使用不同精度的數據類型(如FP16和FP32)進行訓練,以節省顯存並提高計算速度。
25. 量化(Quantization):將高精度數據類型轉換爲低精度數據類型,以減少計算量和顯存使用。

六、功耗與散熱
26. TDP(Thermal Design Power):衡量GPU最大功耗的指標,影響散熱需求和系統配置。
27. 製造工藝(Process Node):GPU芯片製造時使用的半導體技術,以納米(nm)爲單位,更先進的工藝通常意味着更高的性能和更低的功耗。
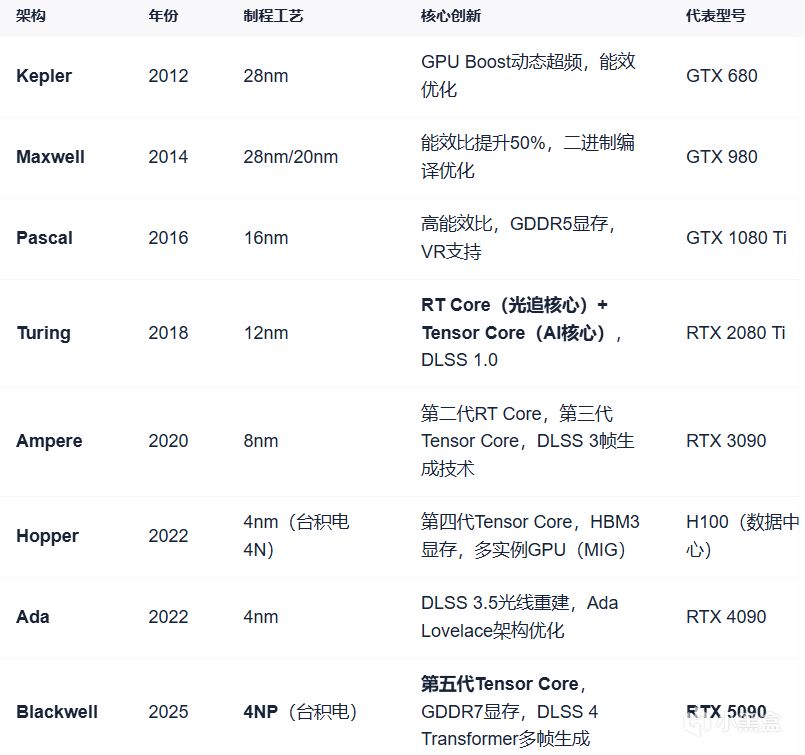
英偉達(NVIDIA)顯卡工藝發展
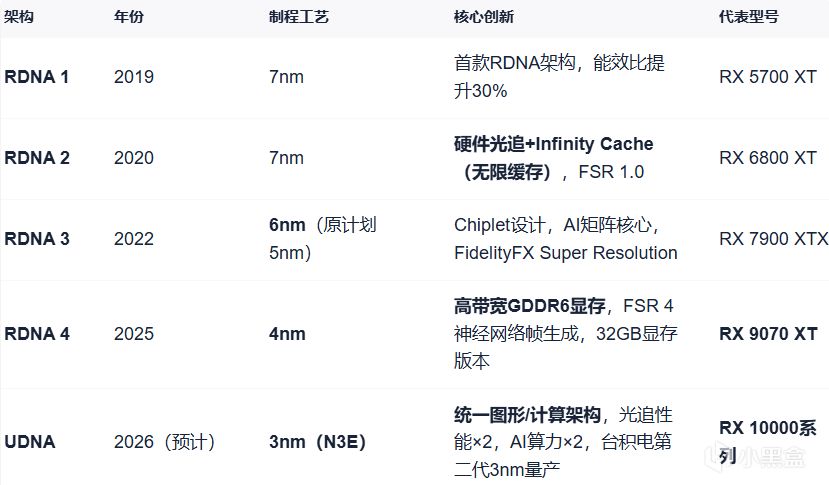
AMD顯卡工藝發展
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















