抓包
我们要爬取之前,要先拿到获取视频的网络请求包,按下键盘上的F12,打开“开发者工具(DevTools)”,点击网络(Network),然后找一个别人的抖音主页
点进去之后,点击刷新,找到一个叫“post/?device=”的请求包
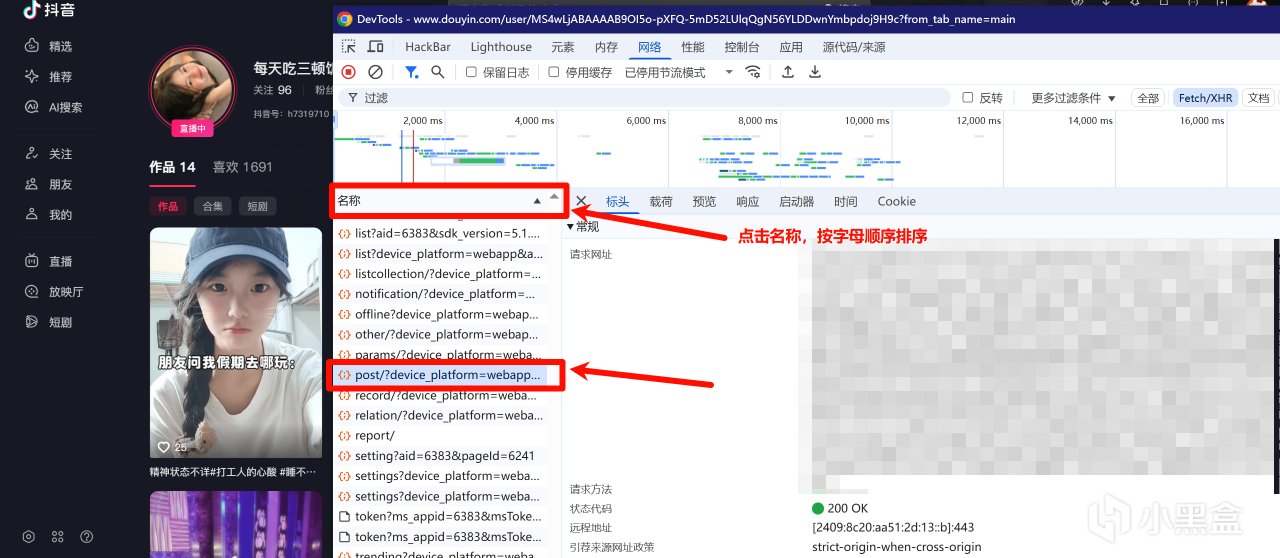
然后右键复制,以cURL(bash)格式复制,随便找一个cURL转python的网站,转换成python代码,然后将代码创建为python文件
最后只需要在代码最后添加如下代码
aweme_list = response.json().get('aweme_list')
for aweme in aweme_list:
title = aweme.get('desc')
url = aweme.get('video').get('play_addr').get('url_list')[-1]
video_content = requests.get(url, cookies=cookies, headers=headers)
with open(f"./dou_video/{title}.mp4", "wb") as f:
f.write(video_content.content)
print(f"视频:{title}-----下载完成!")
f.close()
以上代码意思:通过解析响应的json文件,获取其中aweme列表,然后循环这个列表,获取每个视频的信息,从中取出视频标题,视频链接,然后打开文件,将视频内容保存到dou_video文件中,以视频名作为文件名
如果想要修改爬取的抖音主页,可以修改params字典中sec_user_id的值
这里只是进行一下简单的json解析,只解析了title和视频,如果想要增加更多功能,比如按照视频作者、视频标签分类,或是增加运行效率,可以采用多线程方式,进一步解析并构建代码
最后来看一下爬取的效果
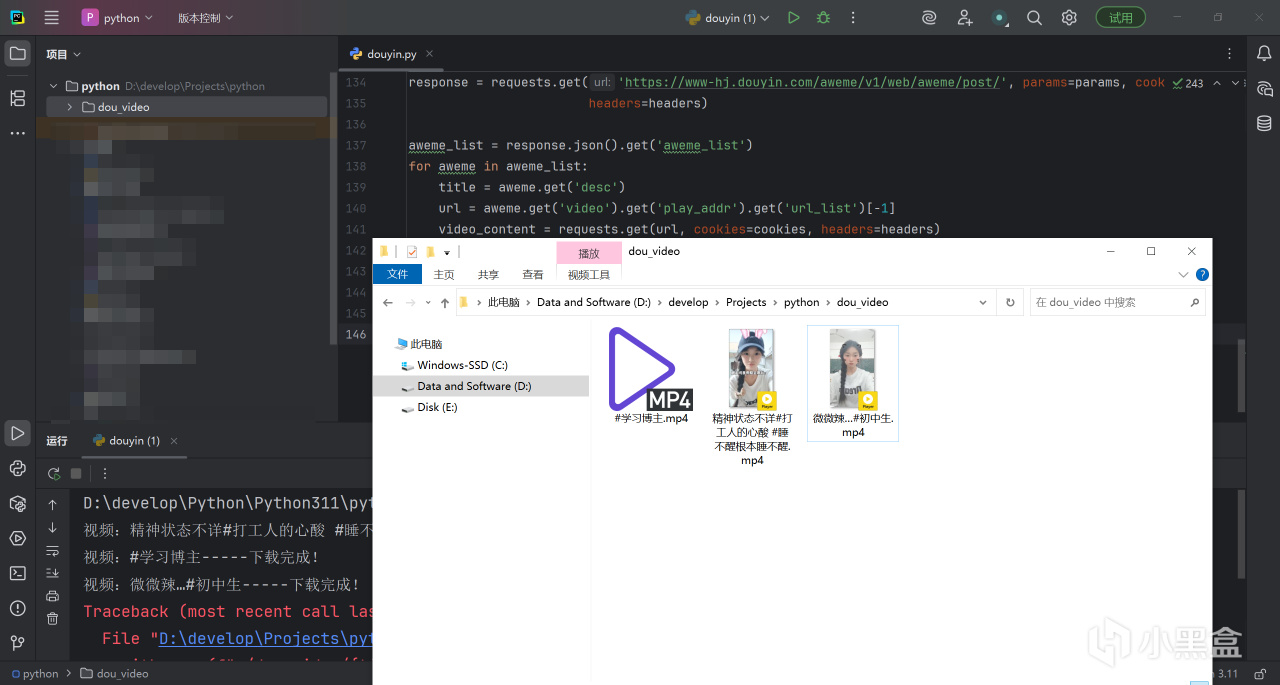
这里报错是因为视频标题存在特殊符号,所以代码还需要进一步完善,比如对标题中的特殊符号进行处理
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















