凌晨两点,你的毕业论文因为DeepSeek云端服务崩溃而卡在最后一章,这种绝望时刻只需要一个7B大小的『AI备胎』就能拯救。虽然本地部署的模型像迷你便利店不如云端沃尔玛商品齐全,但在云端服务还在显示正在故障或者繁忙却紧急需要访问LLM类服务时,本地部署的Deepseek-千问蒸馏7B模型能提供快速响应。日常的大部分LLM需求(如简单Python代码生成、问题解答)都可被本地模型消化。
但是本地化的推理不可避免的会遇到算力的问题,GPU的显存是非常珍贵的资源,一个7B模型大概就要消耗5GB显存,这样本地部署一个大模型,当前的GPU就只能处理LLM推理任务,就没办法游戏或者进行生产。如果使用CPU,虽然可以使用非常大的内存,但是LLM的计算负载又会大量占用CPU,导致系统卡顿。但是核显就是一个既能够使用主机内存,又能和CPU独立运行的中间地带。而且高性能主机上一般都是独显负责视频输出和游戏,核显都是闲置资源。所以使用核显进行本地模型的部署也不会对整机性能带来影响。
最近具备高性能核显和NPU的Ultra系列CPU大降价,所以入手了一颗Ultra 245K,用来本地化自己的DeepSeek模型,自建了一台能跑AI的工作站,本文详细记录了使用UltraGPU本地部署DeepSeek模型的详细流程和踩坑记录,希望各位大神能够轻喷哈哈哈。
装机方案
装机使用了如下方案:
1. CPU: Intel ultra 245K
2. 主板: 铭宣终结者B860M
3. 内存: 光威 龙武 DDR5 16*2 6000mhz 套条 (这个之前搞活动400多就能到手)
4. 机箱:拓扑龙 开放式机箱 (拓扑龙的nas机箱很出名,没想到还做开放式机箱,只要30就能到手,比鞋盒豪华多了😂)
5. 爱国者EP650 650w电源 两百块左右的全模组电源,用起来还算稳定
Ultra245K采用了精致的小黑盒作为其包装设计,这种包装不仅给人一种高端而低调的感觉,还特别在正面设置了一个透明的观察窗。通过这个观察窗,消费者可以直接看到内部CPU的模样,无需打开包装就能一窥这款处理器的风采。这样的设计既满足了用户的好奇心,也增加了产品的吸引力,让人一眼就能感受到Ultra245K的强大性能与独特魅力。此外,透明窗口的设计也让产品更加直观地展示给了潜在买家,有助于提升购买欲望。总之,从外包装到内核展现,Ultra245K都体现了对细节的关注和对用户体验的重视。


打开包装箱后,首先映入眼帘的是中央处理器(CPU)的正面。在这个表面上,精心雕刻着关于该CPU的重要信息,比如型号、序列号以及制造商等细节。除此之外,还印有一个二维码。

背面为触电和电容,排布的非常规整。CPU整体为长方形,同时CPU偏心开了两个凹槽,这样装机时无需对CPU的小三角,直接通过凹槽就能确定CPU的安装方向。

主板使用了铭宣的B860M终结者,整体为黑白色调,采用了12相供电,能够保证UltraCPU的稳定运行。同时,拥有支持双通道4根DDR5内存,目前最大支持128GB内存。Ultra CPU彻底抛弃了对DDR4内存的支持,转向原生的DDR5内存控制器,这直接带来的就是对7000Mhz DDR5内存频率的原生支持。在高内存负载的场景中,DDR4→DDR5升级可带来15-35%的典型速度提升,极端情况下可达40%+。

机箱使用了拓扑龙的开放式机架,整体组装完成后效果如下:

CPU性能测试
1. 3DMark CPU性能测试
3DMark CPU Profile 是一种新的CPU性能测试方法。与只给出一个总分不同,它能显示CPU在使用不同数量的核心和线程时的表现如何变化。这个测试包括六个部分,可以帮助你了解CPU在各种情况下的性能,并进行比较。
这六个测试都用同样的任务,只是改变使用的线程数。分数越高,说明CPU处理速度越快。
每个测试都是物理计算和自定义模拟的组合。为了不让显卡性能影响结果,我们测量的是每帧的平均模拟时间,而不是帧率。然后把这个时间转换成分数。
+ **核心**:是CPU的实际组成部分。核心越多,同时能做的工作就越多。
+ **线程**:是一种虚拟组件,负责给CPU分配任务。线程越多,可以同时处理的任务就越多。
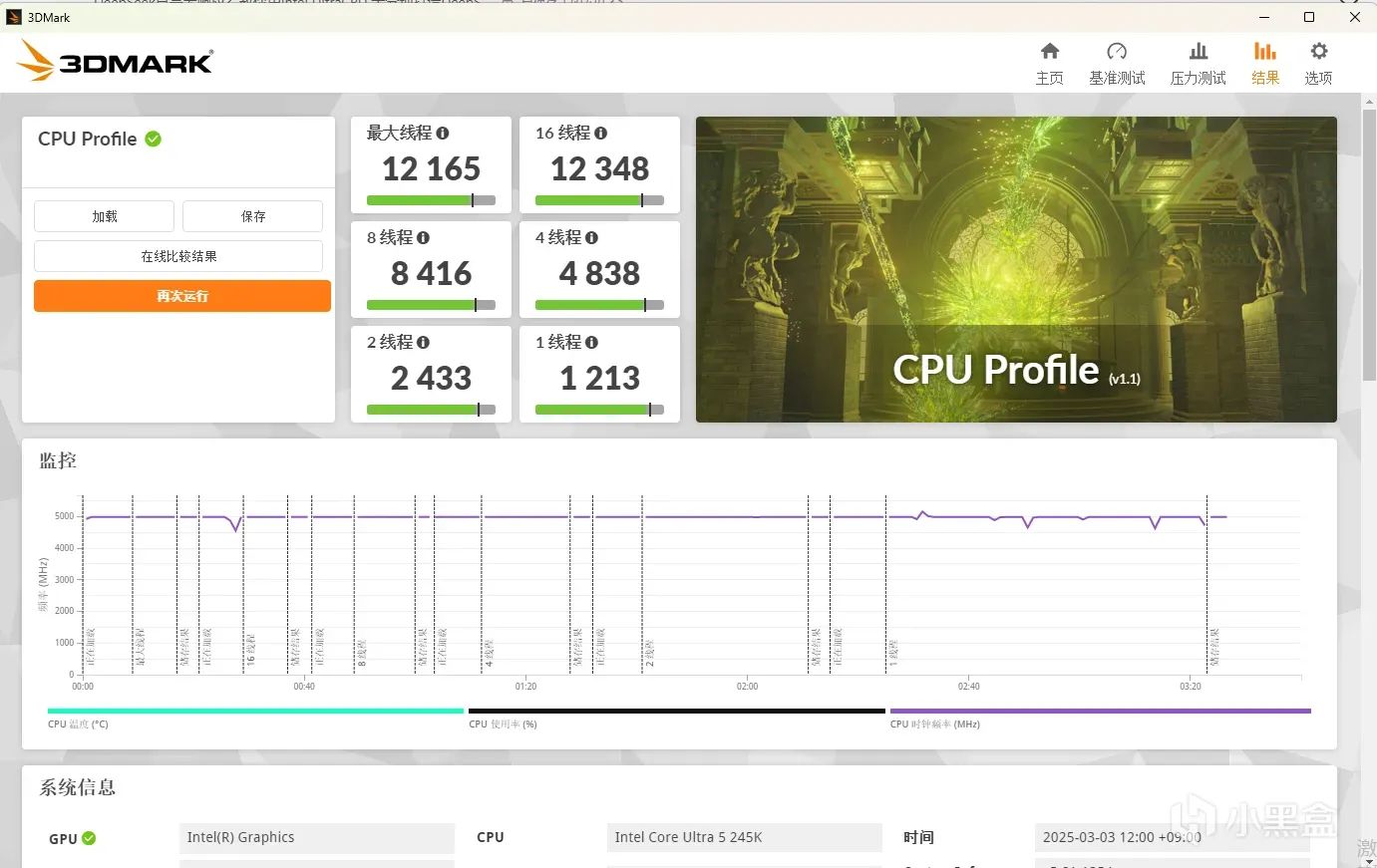
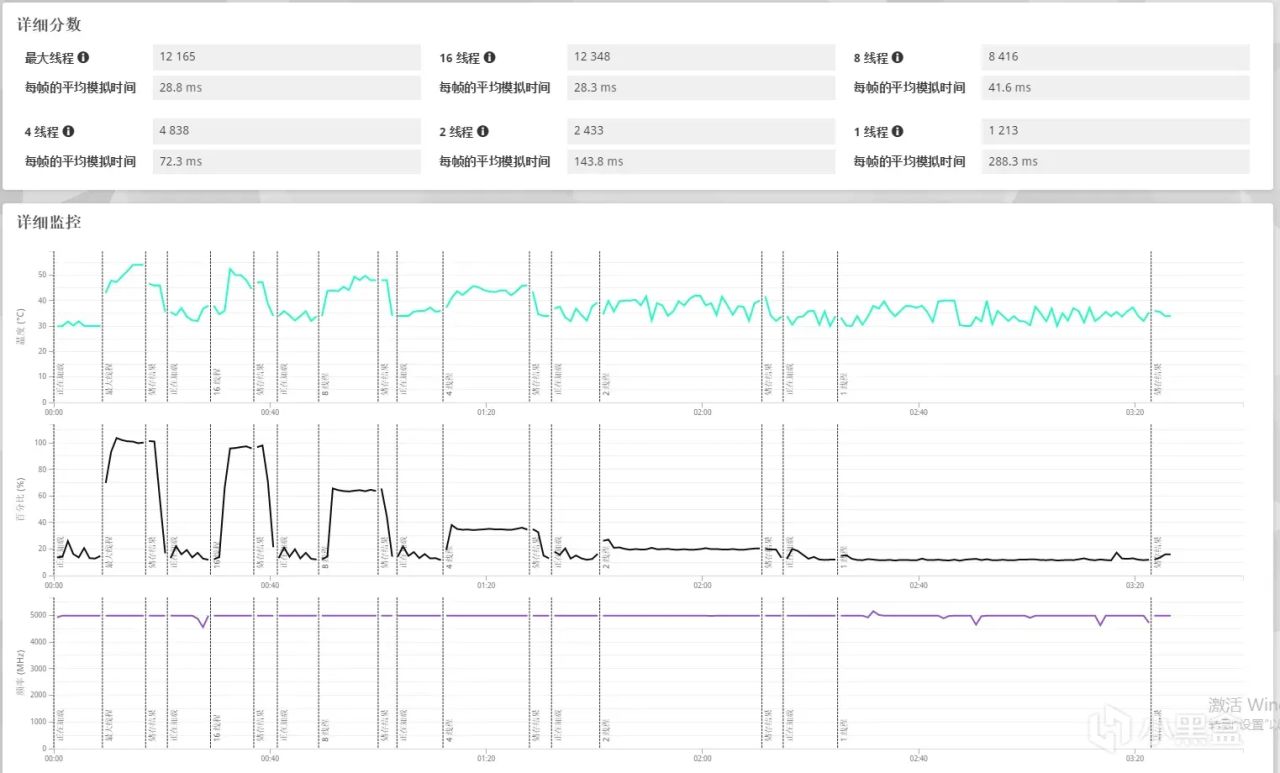
在这次性能测试中,处理器展现了非常出色的单线程处理能力,其单线程分数达到了1213分,这一成绩表明它在执行依赖于单一核心性能的任务时表现优异。此外,当利用到处理器的所有核心和线程进行多任务并行处理时,该处理器的最大线程得分更是高达12348分,这说明它不仅在单线程应用上有着卓越的表现,在需要高度并行计算的场景下也能提供强大的支持,满足复杂应用场景的需求。这样的性能指标对于追求高效能计算体验的用户来说无疑是个好消息。
2. CPU-Z性能跑分
在CPU-Z测试中,用户可以全面地评估其计算机处理器的性能和规格。用户还可以对自己电脑上的CPU执行一系列标准化测试,以量化其单核与多核处理能力。
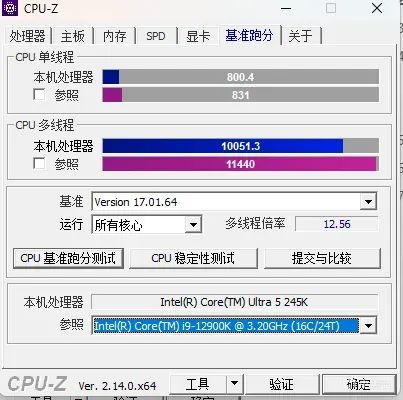
在单核心性能方面,Ultra245K获得了800分,这表明它在处理依赖于单个核心性能的任务时表现优异。而更令人印象深刻的是其多核心得分达到了10051分,这一成绩几乎与曾经被誉为顶级处理器之一的12900K持平。这样的结果不仅证明了Ultra245K在多任务处理能力上的强大,也标志着它能够为用户提供流畅、高效的计算体验,无论是对于日常使用还是更为复杂的专业应用环境而言都是如此。
核显性能评估
14代CPU带有的核显为HD770,其具体参数如下所示

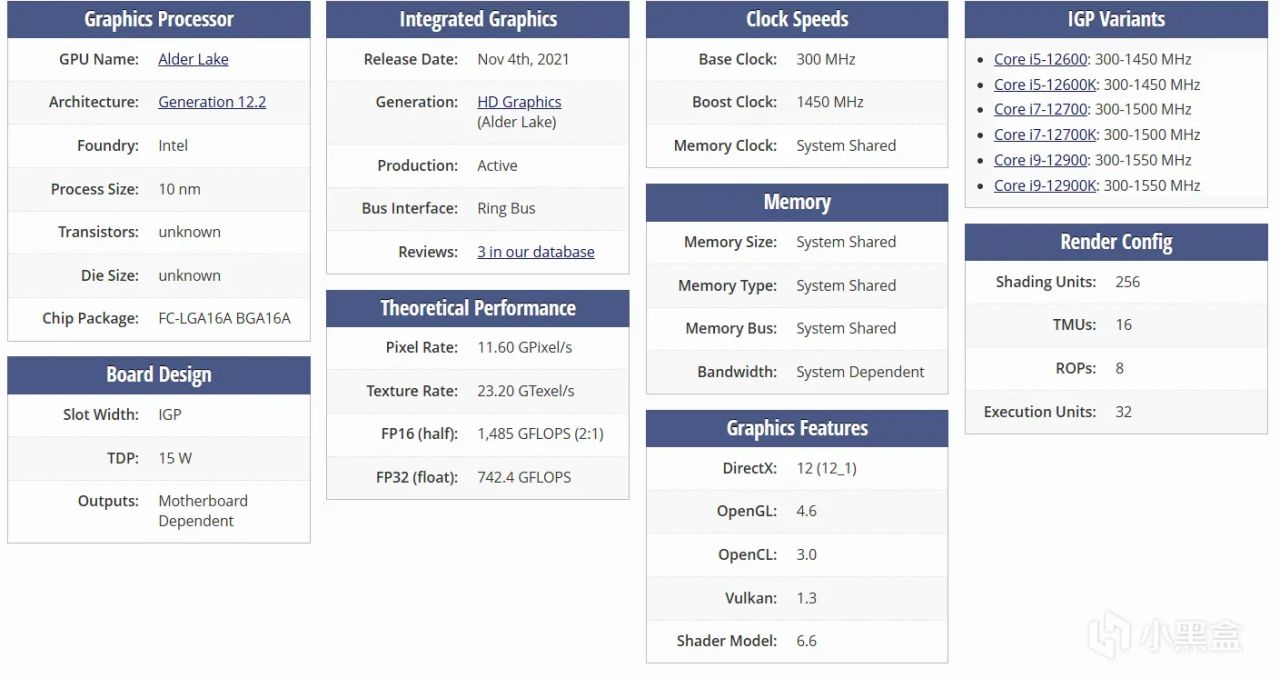
在核显方面,245K相比与14代的HD770升级到了4Xe-core的新式核显

新的Xe核显架构性能上实现了明显的突破,具备4个1.9GHz的Xecore,最大支持8K 60hz编解码,其AI算力在int8精度下达到8TOPS,较前代HD770核显的3TOPS实现2.6倍性能跃升。更值得关注的是,该核显支持英特尔DLBoost深度学习加速技术,当大模型推理采用int4量化部署时,算力为16TOPS。真正达到大模型端侧部署的10TOPS算力门槛要求(以瑞芯微RK3588的NPU算力为基准)。通过硬件级低精度加速能力,Ultra核显为本地化AI推理任务提供了更高效的运算支持。
依赖软件安装
安装IntelGPU驱动
前往链接下载最新的官网GPU驱动
[https://www.intel.cn/content/www/cn/zh/products/sku/241067/intel-core-ultra-5-processor-245k-24m-cache-up-to-5-20-ghz/downloads.html](https://www.intel.cn/content/www/cn/zh/products/sku/241067/intel-core-ultra-5-processor-245k-24m-cache-up-to-5-20-ghz/downloads.html)
下载ipex-llm ollama部署包
ipex-llm是intel官方的开源大模型项目,支持使用intelgpu进行高性能大模型推理和训练微调。
从该链接进入intel ipex-llm官方页面[https://github.com/intel/ipex-llm/releases/tag/v2.2.0-nightly](https://github.com/intel/ipex-llm/releases/tag/v2.2.0-nightly)

下载[llama-cpp-ipex-llm-2.2.0b20250224-win-npu.zip](https://github.com/intel/ipex-llm/releases/download/v2.2.0-nightly/llama-cpp-ipex-llm-2.2.0b20250224-win-npu.zip)到本地解压即可
Ollama启动和模型部署
在文件夹中按住`Shift`+右键,选择在终端中打开
在命令行中输入
```plain
./start-ollama.bat
```
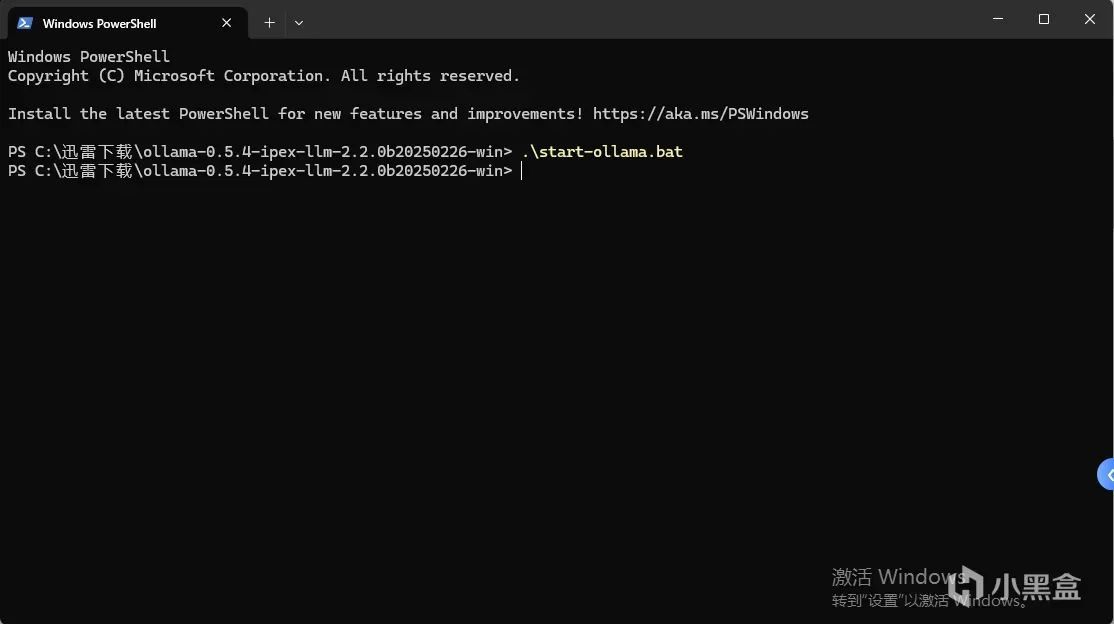
然后就会弹出来一个跑了很多日志的命令行窗口,这就代表ollama启动成功了,记得不要关闭他
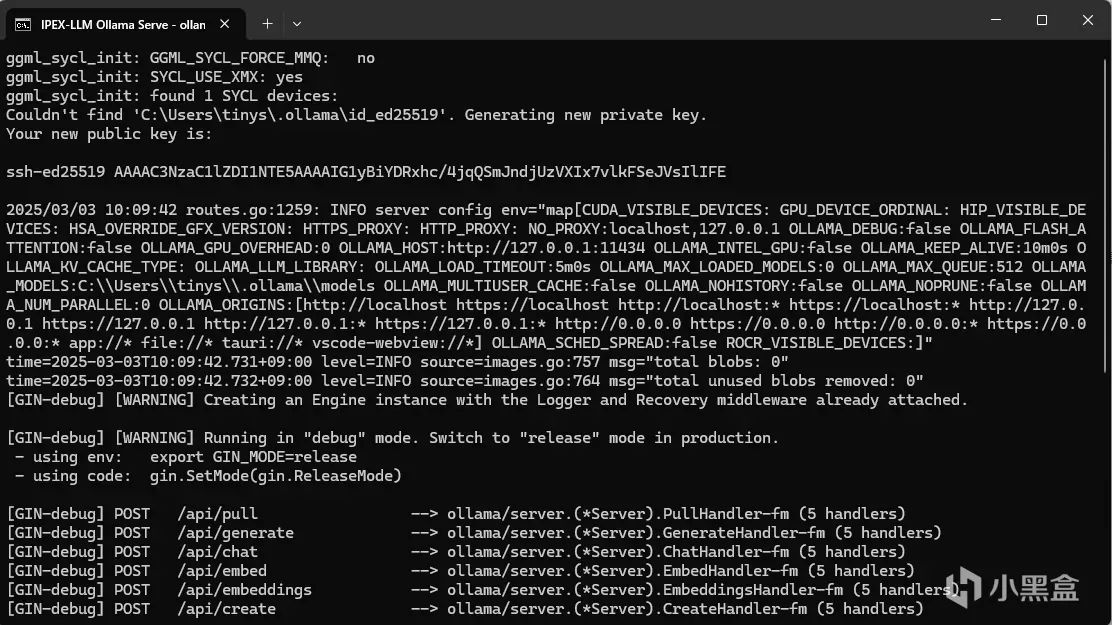
然后在前面我们自己打开的命令行窗口里面输入如下命令
```plain
.\ollama.exe pull deepseek-r1:7b
```
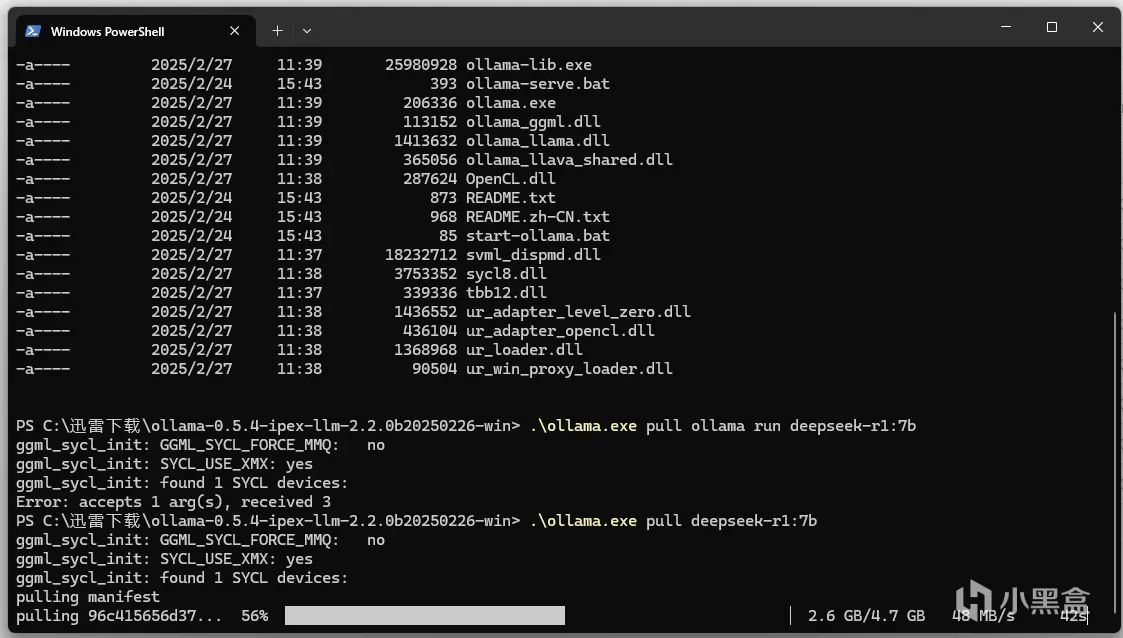
等待模型加载完毕即可
启动大模型前端
等待模型下载完成后,我们的ollama已经在后台就绪了,这时候需要我们就可以和大模型进行对话了,但是命令行的方式比较复杂并且不美观,所以这里我们直接使用一键安装的软件`AnythingLLM`来使用刚才我们搭建好的Ollama服务。
前往AnythingLLM官网:[AnythingLLM | The all-in-one AI application for everyone](https://anythingllm.com/)
下载并安装
安装完成后启动软件
模型选择位置我们选择ollama
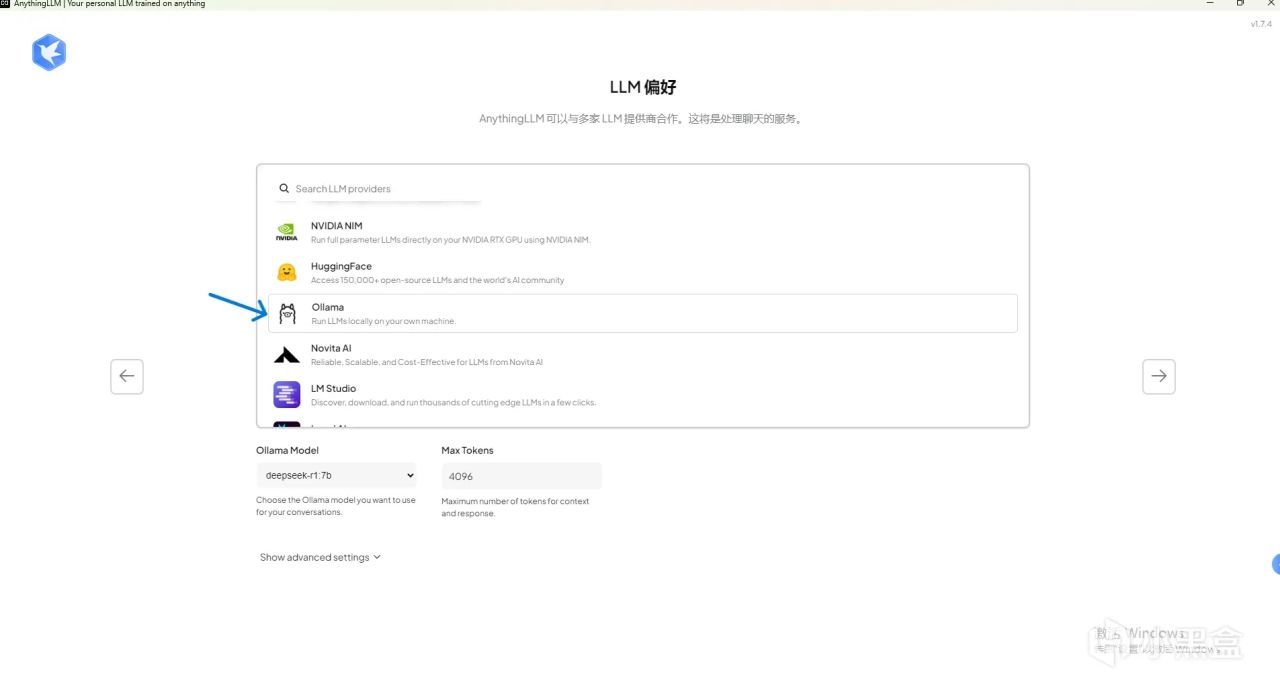
可以看到我们的DeepSeekR1已经被识别出来了.
后面创建工作区,这个随便取名,我就直接写了DeepSeek-iGPU
首先点击选中我们的工作区,然后选中`NewThread`开启新对话即可
我们先让DeepSeek介绍一下Ultra系列处理器吧
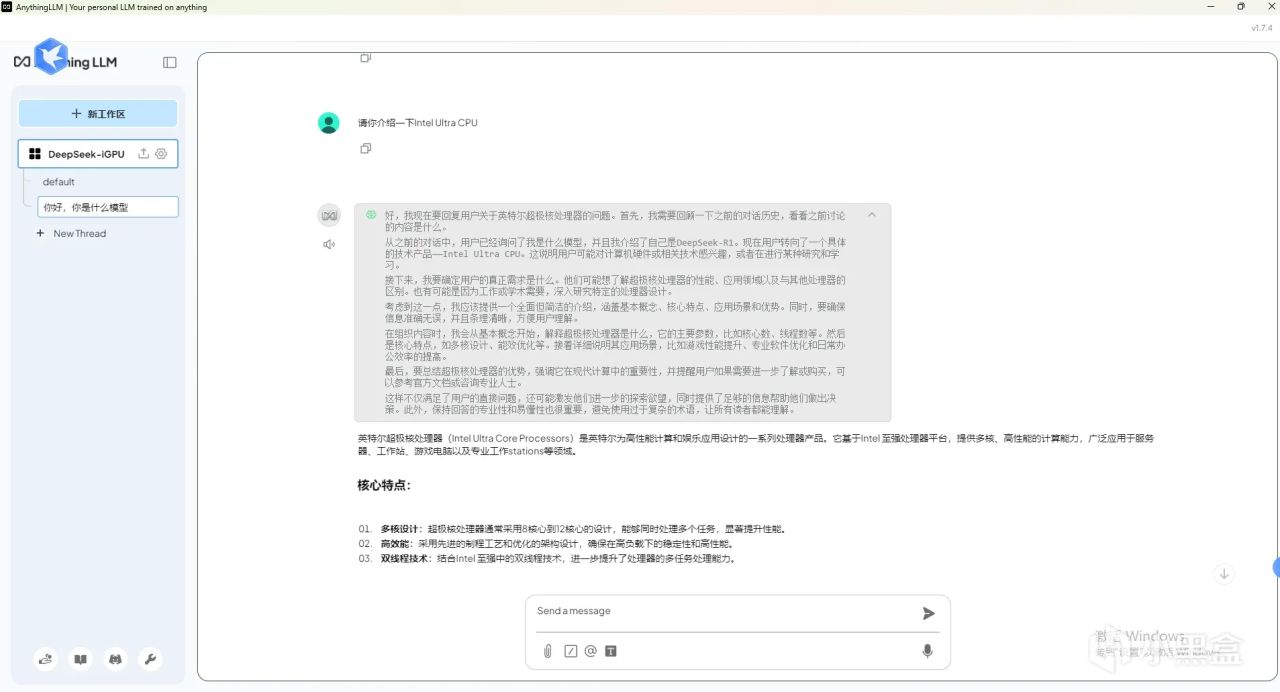
可以看到,DeepSeekR1的思考链也能够正常工作。
开启任务管理器可以看到,核显基本上已经被榨干,并且使用了7.2G的主机内存
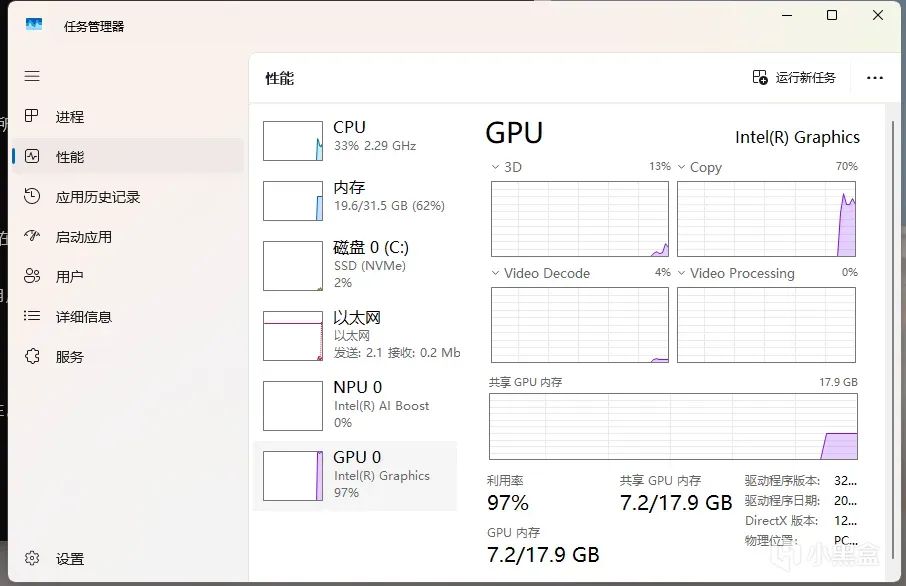
模型的token生成速率(近似每秒生成的单词数量)大约为10token/s,对于个人使用的话已经可以做到流畅的对话了!
Ultra 245K另一大亮点就是引入了NPU。本文其实一开始想用NPU进行部署。目前,intel ipex-llm给出了测试阶段的npu大模型部署工具,因为Ultra245K的NPU太新了(相比Ultra1和UltraV),NPU部署过程遇到了若干bug,目前这些Bug已经提交到Intel ipex-llm中。按照ipex-llm目前高速的更新速度来说,大约下个月应该就能使用NPU进行模型的推理与部署,这可以进一步解放核显,同时构建一台更高性能的AI工作站。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















