
如果有人說:差評君是秦始皇,別說你了,哥們自己都不信。
但要有人說:DeepSeek 是秦始皇。
那咱沒準還真要琢磨下,畢竟人家這段時間,真一統全國了。。。
你看甭管是哪個行業的哪家公司、和 AI 有沒有打過交道,平時有沒有互相 Diss ,最近都跟說好了一樣,搶着接入 DeepSeek 。
差評君簡單給你彙報下噢。
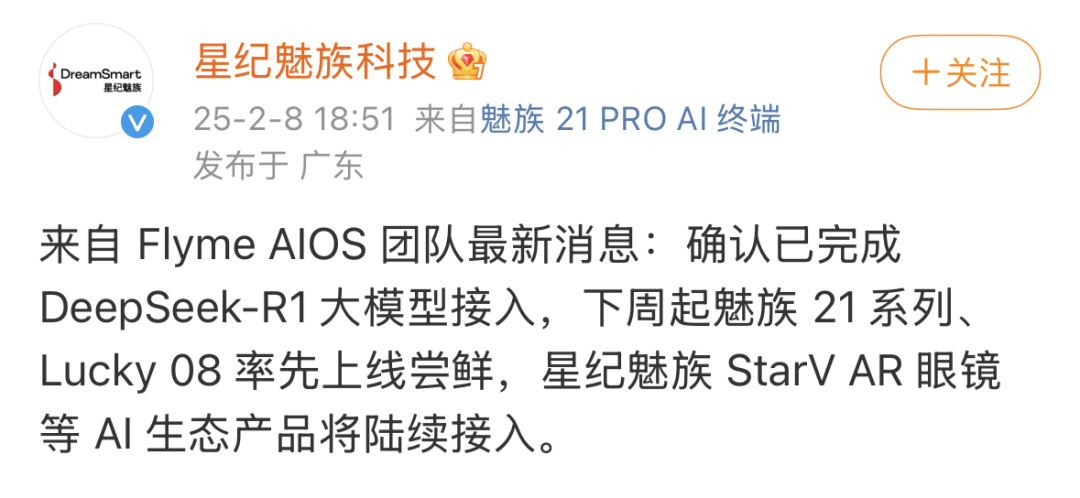
2 月 5 日大年初八那天,纔剛開工,華爲就宣佈接入 DeepSeek 。鴻蒙用戶在小藝助手 App 的智能體廣場裏就能體驗到。


這邊華子剛入局,那邊幾家友商火速跟上了。
手機廠商們打得熱火朝天,隔壁車圈也同樣沒閒着。
2 月 6 日,吉利汽車宣佈自己的大模型和 DeepSeek 完成了深度融合。
接着第二天,嵐圖、極氪也宣佈了。

這還沒完,接下來的 3 天,智己、奇瑞、零跑、比亞迪、長城、紅旗更是上演了一場集體官宣。。。
你以爲這就結束了嗎?
除了民營企業,像廣東、江蘇等多地政務服務系統,也宣佈接入 DeepSeek 系列大模型。三大電信運營商、中石油、中石化等中企巨頭也和 DeepSeek 展開合作。
上面,都還在差評君理解範圍,越到後面,宣佈接入 DeepSeek 的企業越讓差評君震驚。

比如大夥兒平時騎的小電驢品牌,九號和小牛也掛起海報,各自官宣 “ 行業首發 ” 接入 DeepSeek 。。。
別急,後面還有大的。。。
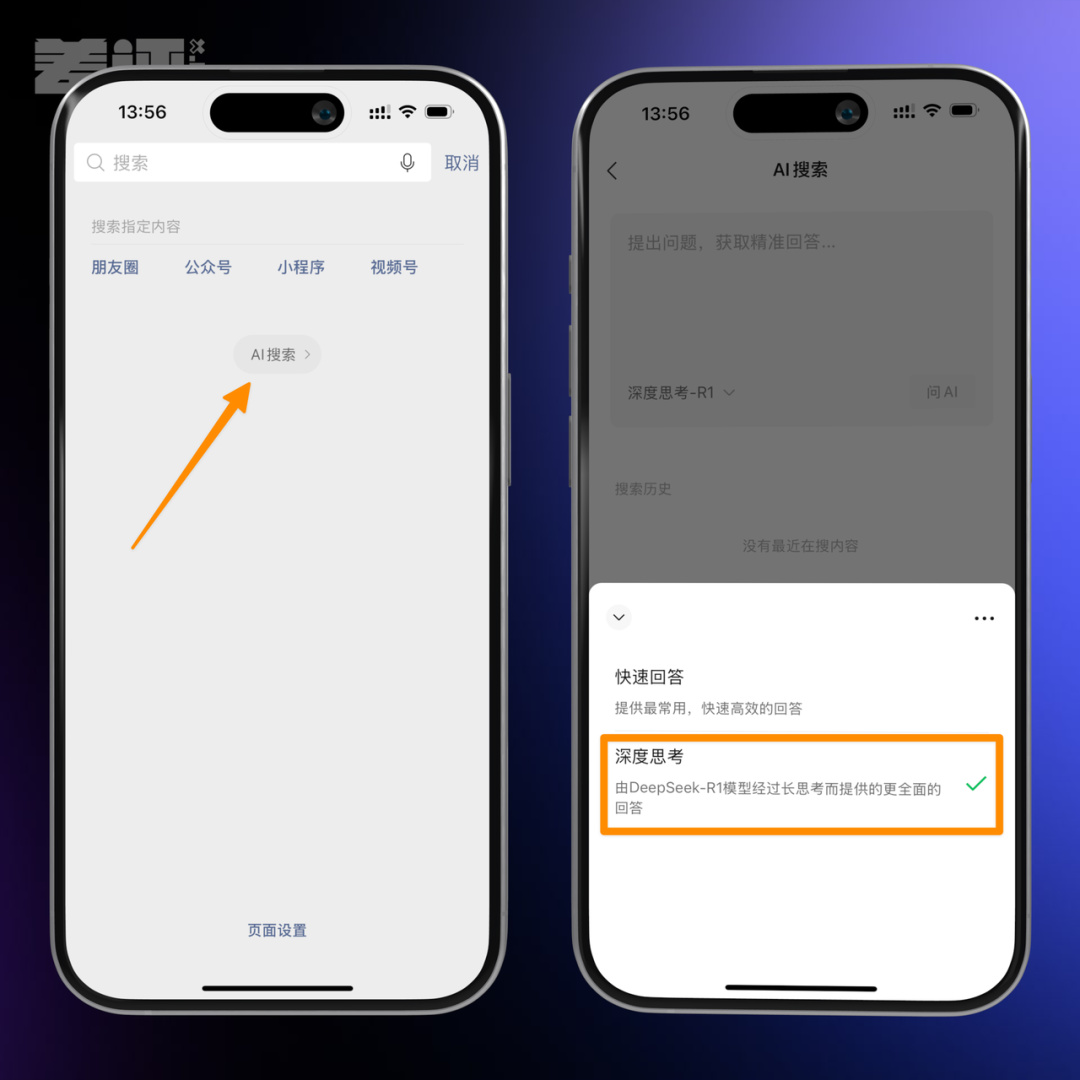
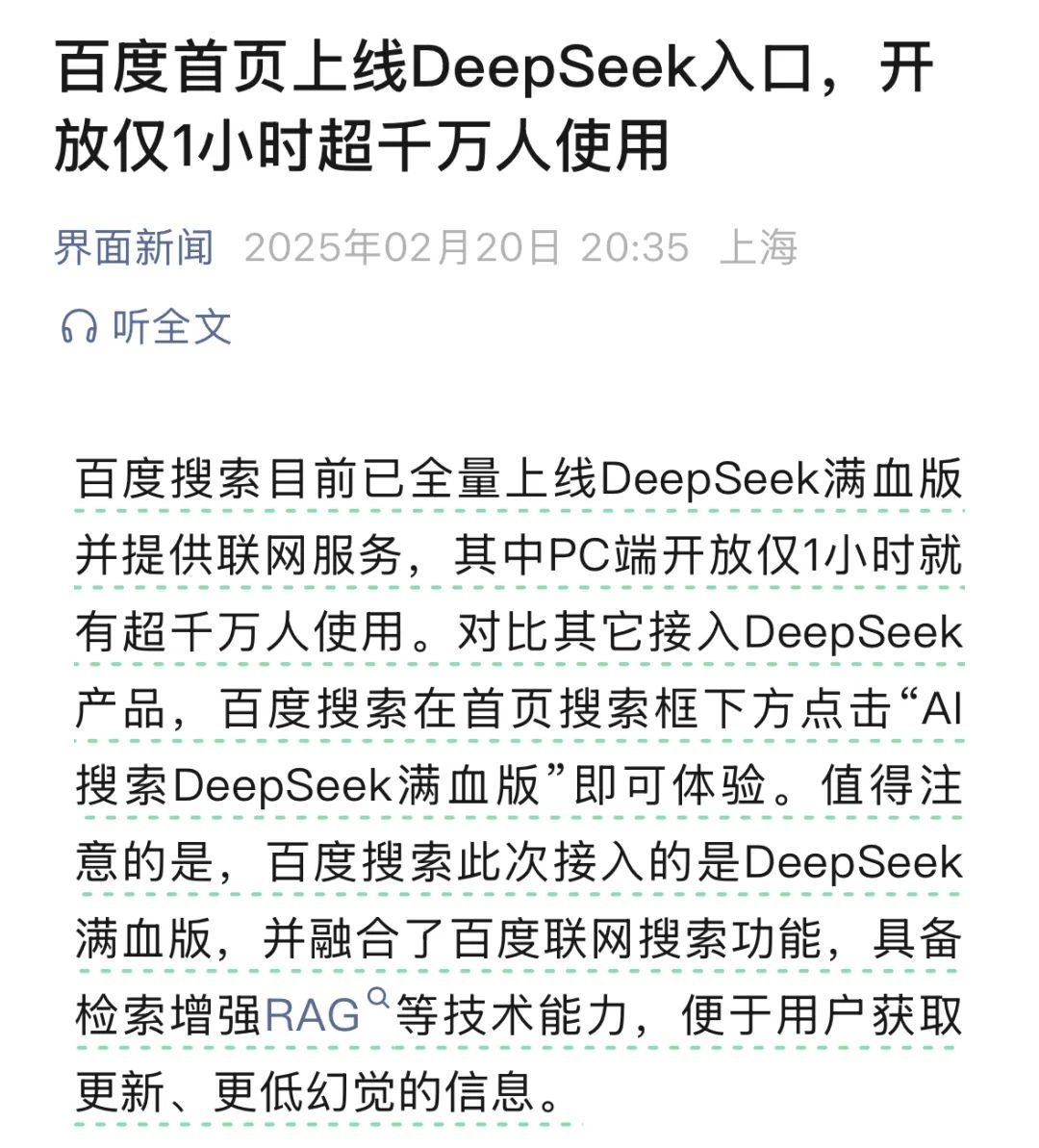
自家已經有文心大模型的百度搜索,居然也接入了 DeepSeek 。
甚至一向不愛湊熱鬧的微信也在搜索中接入了,編輯部有幾個小夥伴已經灰度上了。

鑑於目前這個局面已經有點像誰不接 DeepSeek ,就有種當年誰還沒 QQ 號的感覺,顯得自己不夠領先。。。
那問題來了,這麼多企業接入 DeepSeek ,真能提高企業效率,改善用戶體驗嗎?
看情況。
有網友就表示百度地圖接入 DeepSeek 還挺好的,能根據用戶消費水平、最近搜索過的地點來推薦附近看花的地方。
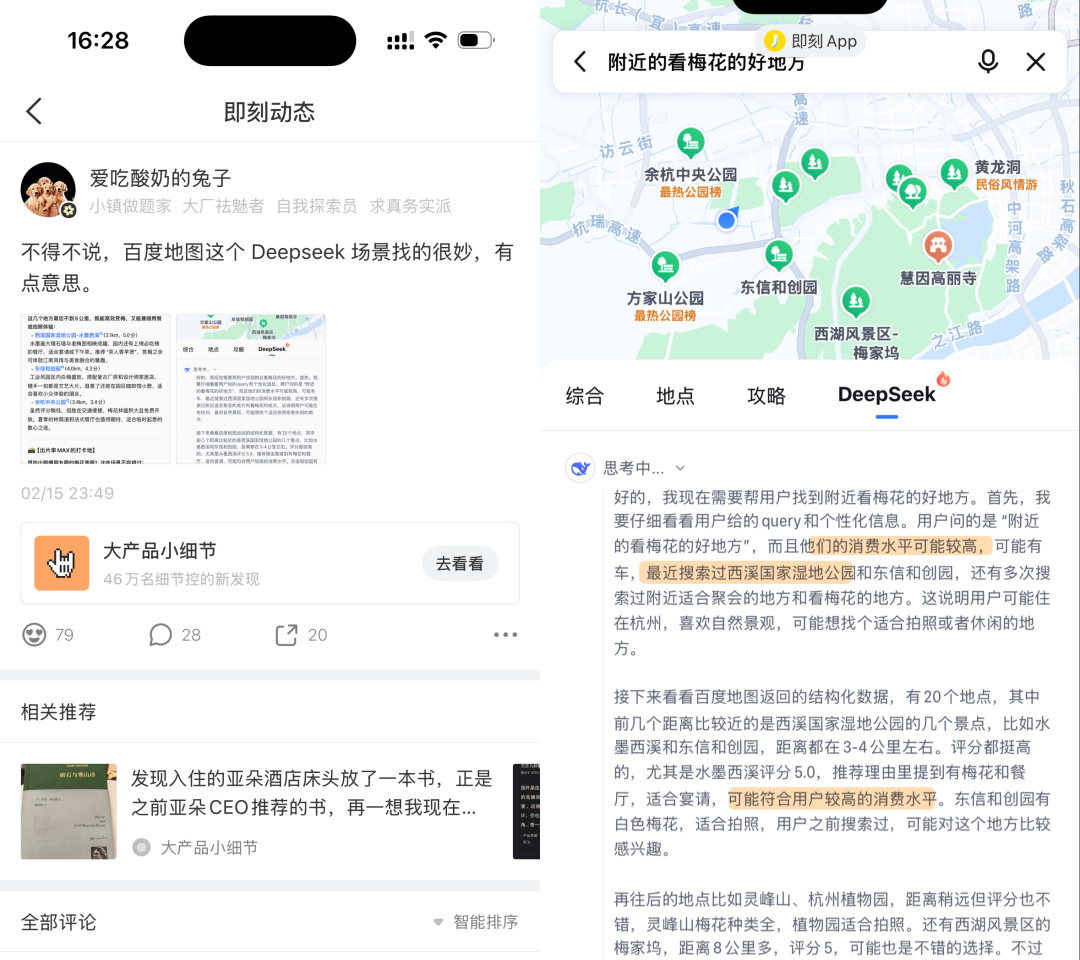

但差評君覺得,還是有不少產品, DeepSeek 接得不是很有必要。。。
說通俗點就是:給車上那些AI小助手,加一點 DeepSeek 的技能。
DeepSeek 的核心技能還是思維鏈( Chain of Thought ),很擅長邏輯推理。
比如你問它:我有一個朋友想問下怎麼補腎。它能推理出:這個朋友可能是用戶自己。
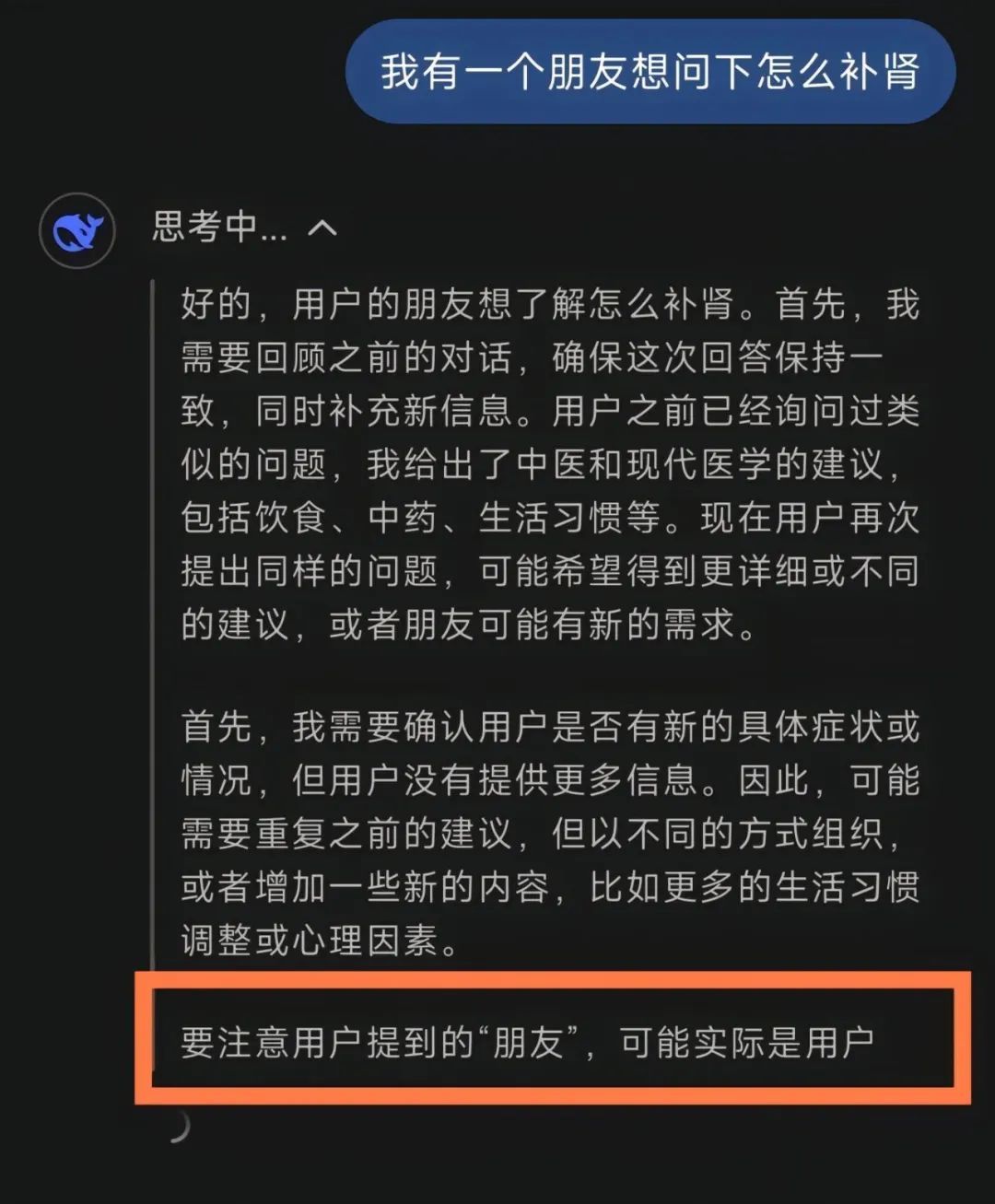
開個玩笑。
通常大家都用它解決複雜的數學、編程、推理任務。但關鍵是,咱開車能有多複雜的需求嗎?讓 AI 開個窗、打開後座椅加熱,頂天了。

真要說,也有。
四輪車都這樣了,那二輪車 App 接入 DeepSeek 差評君更想不通能幹嘛了。
有點大炮打蚊子,呂布單挑草履蟲,用 RTX5090 玩暴力摩托——火力過剩了。
所以問題又來了。。。
差評君能想到的情況,人這麼大企業也顯然能考慮到。可爲啥大家還是搶着接入 DeepSeek ?
我覺得吧,有 4 種因素。
第一種嘛,主動蹭。
何況這種科技圈的頂流,蹭上就能有曝光,加月活,那幹嘛不蹭?
你看百度接入了 DeepSeek , 1 小時就有 1000 萬用戶體驗。。。
這不香嗎?還管啥文心一言二言的。
蹭!理解,人之常情,我們也愛蹭。

第二種,被動蹭。
“ 都在接入啊?不接是不是顯得咱們。。。 ”
“ 接吧接吧,也沒啥壞處。 ”

第三種,秀肌肉、加好感。
最重要的是接入 DeepSeek ,就意味着自己跟上了市場風向,滿足了用戶需求。
屬於一種,誰先接入,誰就更懂市場、更寵用戶。爲啥小牛和九號都說自己 “ 行業率先 ” ,就是這原因。

第四種,其實有不少企業原本就計劃接入AI大模型。
這就是咱們今天要討論的核心,接入 DeepSeek 的成本太低了。
去年智譜、字節、阿里、百度、騰訊的大模型突然打起價格戰,嗯,和 DeepSeek V2 發佈脫離不了干係。DeepSeek 可是靠着一手低價,被行業稱爲 AI 界的拼多多。
那 DeepSeek 到底有多便宜?
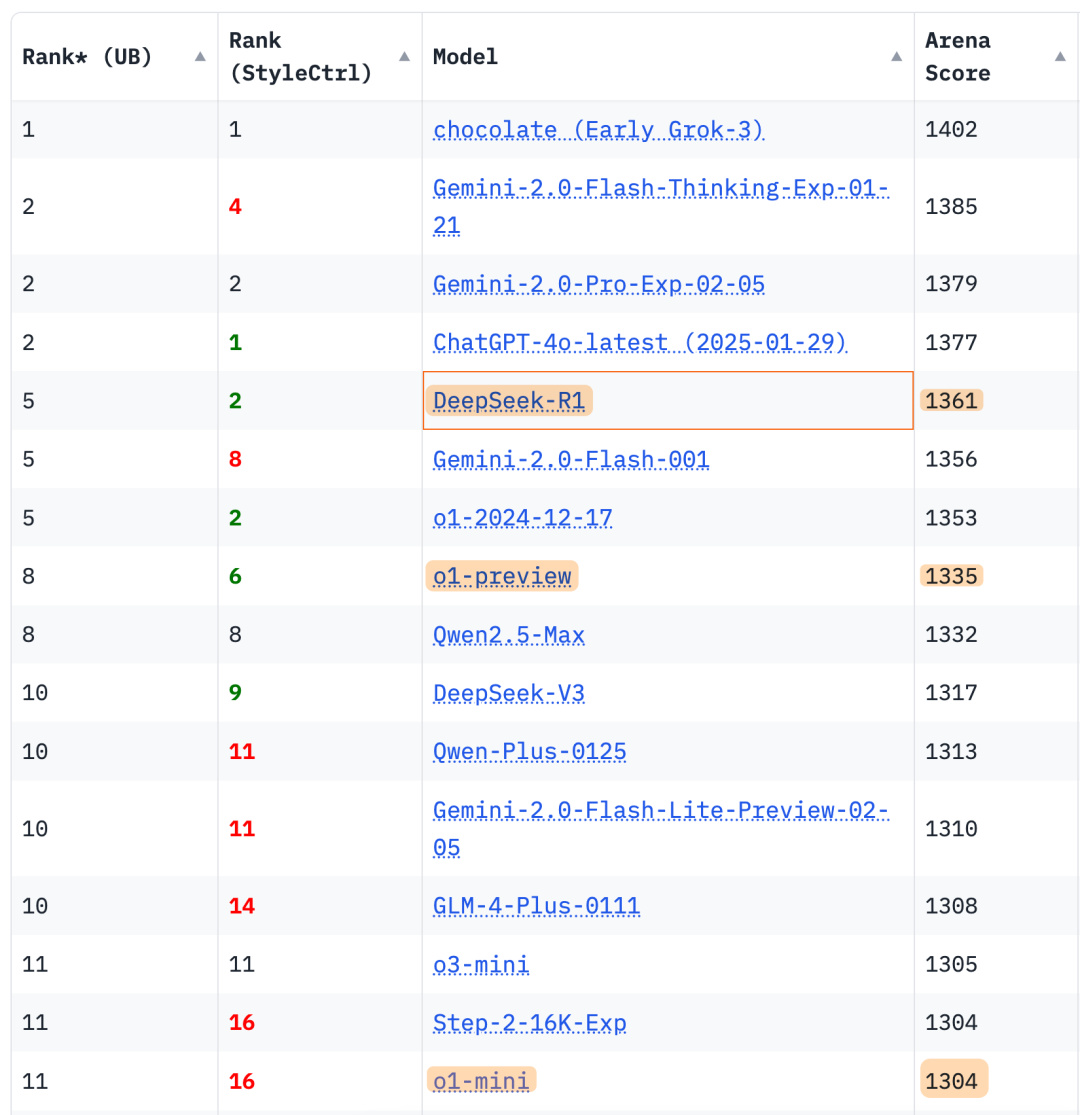
在 AI 競技場裏, DeepSeek R1 的評分要高於 OpenAI 的 o1-mini 、 o1-preview 等模型。
但價格呢,看下這個表格。

以防你看不清,差評君用箭頭標一下。那個短到幾乎看不到的條形,就是 DeepSeek API 的價格。
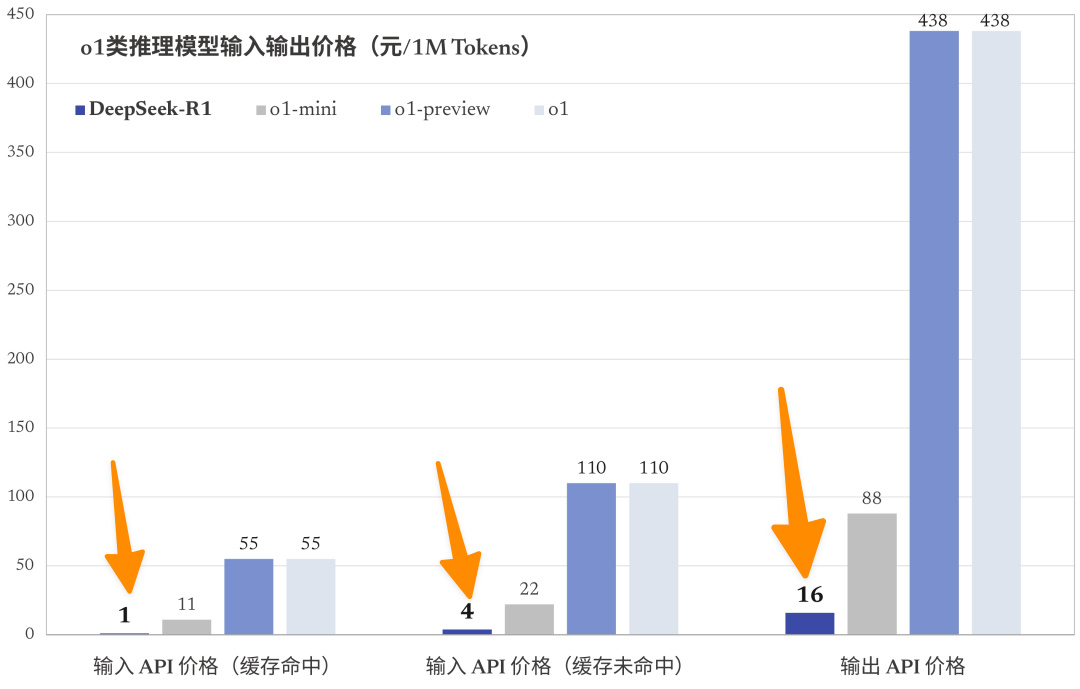
R1 輸入價格( 緩存未命中 )每百萬 Tokens 才 4 塊錢,而實力不如 R1 的 o1-preview ,得要 110 塊。
高下立判了兄弟們,第一次覺得短短的也很酷哦。

差評君敢說沒有廉價的 DeepSeek ,一堆AI初創公司都得倒閉,包括我們之前採訪的語核科技創始人池光耀也這麼認爲。
當時有不少大模型公司還來找過語核,說可以提供和 DeepSeek 價格相近的模型。但池光耀表示,價格一樣的模型“ 太笨了,跟 DeepSeek 不在一個維度” 。
要是能力和 DeepSeek 差不多的呢?那價格 “基本是 DeepSeek 10 倍以上” 。

所以啊,那些原本嫌 AI 大模型貴遲遲沒有下決定的公司,在 DeepSeek R1 大火之後就立刻停止了觀望,選擇接入。
如果把 AI 大模型比作《 賽博朋克 2077 》裏的義體,那麼 DeepSeek R1 就是一個當下熱門、價格低廉、 buff 賊猛、佔用緩存小的頂尖義體。
有人看中它的價格低,有人看中它的機制猛,人人都想接入,於是——

文章開頭那個 “ 百家爭 D ” 的現象,就出現了。
DeepSeek 的開源意味着,企業們除了可以接入 API ,還可以在本地自部署。
原本企業訓練 AI 大模型要燒多少錢?
拿最近剛出的 Grok 3 來說,其訓練成本是 20 萬塊英偉達 GPU ( 一塊成本大概 3 萬刀 ),也就是 60 億美金。
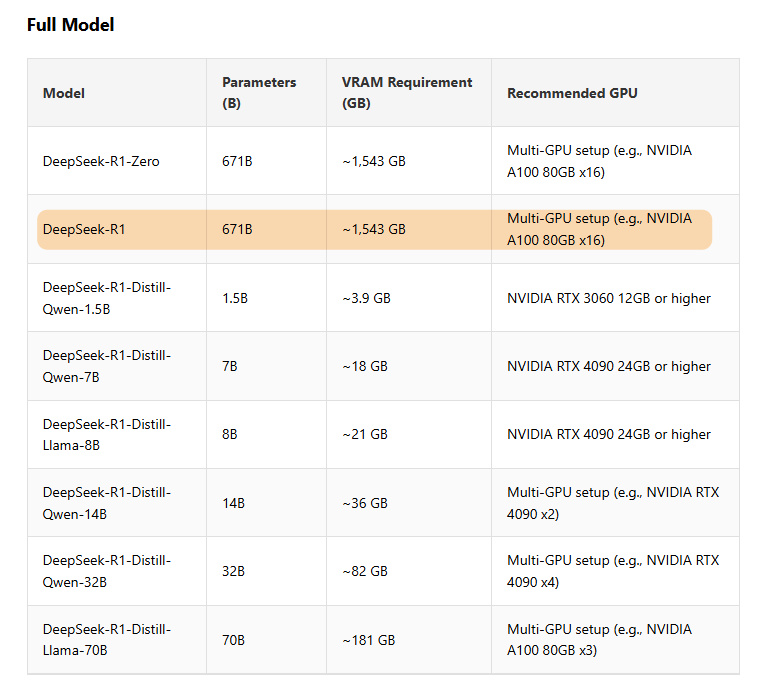
但現在,企業本地搭建一個 DeepSeek R1 滿血版要多少錢?參數 671B ,運行起來需要 1543 GB 顯存, 16 張 A100 80GB 就夠了。
假如用 1.5 萬美元的價格購入一張 A100 80GB ,也就是 24 萬美元。
根據 AI 競技場裏, DeepSeek R1 評分 1361 、 Grok3 評分 1402 ,相差不大。
我們可以這麼說——

因爲 DeepSeek 的開源,無數企業只要花幾十萬美元,就能部署一個能力堪比訓練成本 60 億美金的AI。
所以 DeepSeek 對行業最大的影響,就是讓AI從 “ 高成本壟斷 ” 開始向 “ 低成本普惠 ” 傾斜。AI 大模型不再是一個巨頭、資本、無腦堆顯卡的氪金遊戲,而是一箇中小企業都能參與進來的創意遊戲。

DeepSeek 面前,衆生平等。
儘管, “ 百家爭 D” 裏有不少企業,只是打着 DeepSeek 的噱頭,滿足下用戶的娛樂需求。有些接入的很抽象,有些接入的沒必要。
儘管,很多人包括差評君在內,也開始有點反感聽到 “ 誰誰誰又接入 DeepSeek” 的新聞了。
但,總有認真做事的企業。多給他們一點時間,只要接入的企業越多,那麼 DeepSeek 所推動的創新就一定越多。
當然,未來怎麼發展誰都不好說。
不過差評君確定的是,在農曆蛇年春節,有一隻來自東方的蝴蝶,扇動了一下翅膀。
而百家爭 D 後,一定會有更多的蝴蝶,要扇動翅膀了。
撰文:刺蝟
編輯:莽山烙鐵頭 面線 江江
圖片、資料來源:
澎湃新聞: 接入 DeepSeek !華爲、 OPPO 等國產手機品牌官宣跟進
15+ 車企怕掉隊,緊急宣佈接入 DeepSeek
多地政務服務系統及中企巨頭接入 DeepSeek 大模型,智能化轉型加速
Chatbot Arena LLM Leaderboard : Community-driven Evaluation for Best LLM and AI chatbots
DeepSeek 官網

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















