
馬上就要過年了,差評君這幾天還正忙着辦年貨,結果回家剛拿起手機,就被 AI 刷屏了。

還記得前幾周跟六代機前後腳的 DeepSeek 不?他家那個 V3 模型震驚硅谷還沒幾天,現在又整出來一個絕世狠活。
如果說上次的 V3 模型,是讓硅谷對中國 AI 側目的話,那這次就直接是被掀了桌子了,他們發佈了一個叫 DeepSeek-R1 的大模型,完全比得上 OpenAI-o1 那種,結果亮相以後引起的反響比上次還要大!
Meta 聯合創始人看了都直呼改變歷史,不惜溢美之詞,還在後面的推文裏跟 DeepSeek 的黑子對噴。
參投過 OpenAI 、 Databricks 、 Character.AI 等知名企業的風投大佬馬克 · 安德森也對 DeepSeek-R1 一頓猛誇,說它最令人驚歎、最印象深刻,是對世界的一份深刻饋贈。
而其他 AI 愛好者和網友們也是紛紛選擇用腳投票,每月幾百塊的 ChatGPT 拜拜了您內!

哥們這就下載免費的 DeepSeek !
然後就跟之前小紅書爆火類似, DeepSeek 的應用商店排名迅速上升,現在已經成了 APPSTORE 排名第一的軟件。

不僅美國人被搞得友邦驚詫, DeepSeek 現在在國內更是紅的沒邊。
這幾天微博熱搜上跟它相關的,每天都要掛好幾個。
甚至不少 AI 行業的圈外人都深有感觸,比如做黑神話的馮驥,也在微博上感慨良多,說這是 “ 國運級別的科技成果 ” 。

就連差評編輯部的主編老師,體驗完以後都直呼好用,能拿來做培訓了。

其他網友們實際體驗下來,也紛紛表示這玩意確實牛逼。
不說別的,就拿跟 OpenAI-o1 對比來看,某網友讓這倆分別寫個腳本,要用 python 畫一個紅球在旋轉的三角形裏彈跳,結果左邊 OpenAI 搞出來一坨,右邊的 DeepSeek 倒是表現的相當流暢。

一句話, o1 辦得了的它能辦, o1 辦不了的它也能辦,這簡直是踢館行爲,一腳踹飛了國產 AI 只能屈居人後的牌匾。
不過除了揚眉吐氣以外,估計不少差友也跟差評君一樣有點疑問,畢竟 DeepSeek 這麼一個以前都沒怎麼聽說過的小廠,咋突然就能支棱起來、名揚世界了呢?

在暗湧採訪 DeepSeek 創始人梁文鋒的報道中,咱還是找到了一部分原因,因爲這是一個相當重視創新的公司。

就拿之前在行業內大放異彩的 V2 、 V3 模型來說,這裏面有一個非常重要的多頭注意力機制,而這個技術最開始只是來自團隊內一位年輕開發者的創意,隨後大家一起在這個方案上鑽研才最終搞定。
而這種創新驅動的技術突破在這個團隊內並不罕見。

不過比起單個技術點的突破,這次 R1 牛的地方卻在於路徑創新,甚至能改變整個 AI 領域的技術路線。
這麼說吧,傳統大模型訓練裏邊,非常注重標註數據微調( SFT ),也就是讓大模型先按人類標註好的標準答案來學習,學着說人話;如果想要大模型性能強些,那還要再在 SFT 基礎上加一些強化學習( RL ),讓大模型的理解能力更好。
換句話說,傳統大廠搞AI就像應試教育:先給海量標註數據搞填鴨式教學( SFT ),再拿強化學習( RL )做考前突擊。結果就是訓練出 GPT-4o 這種 " 別人家孩子 " ——解題步驟工整規範,但總感覺少了點靈性。
而更要命的是,這種訓練需要花大量的資源,很多時間和資金都得花在數據標註跟微調上。
但 DeepSeek 牛的地方在於,他們這個推理模型的核心全靠強化學習,完事用一個叫 GRPO 的算法給模型的回答打分,然後繼續優化,這些步驟裏一點 SFT 都不帶用的。

這就相當於把孩子扔到魷魚遊戲這種大逃殺劇本里,逼着模型自己琢磨最優路徑,要是開擺做不出題就寄了。
於是在這種高強度的淬鍊中,一個只花了 600 萬美元,兩個月時間鍛造出來的宗門天才,出場就達到了世家大族花了幾個億資金練了幾年的水平。

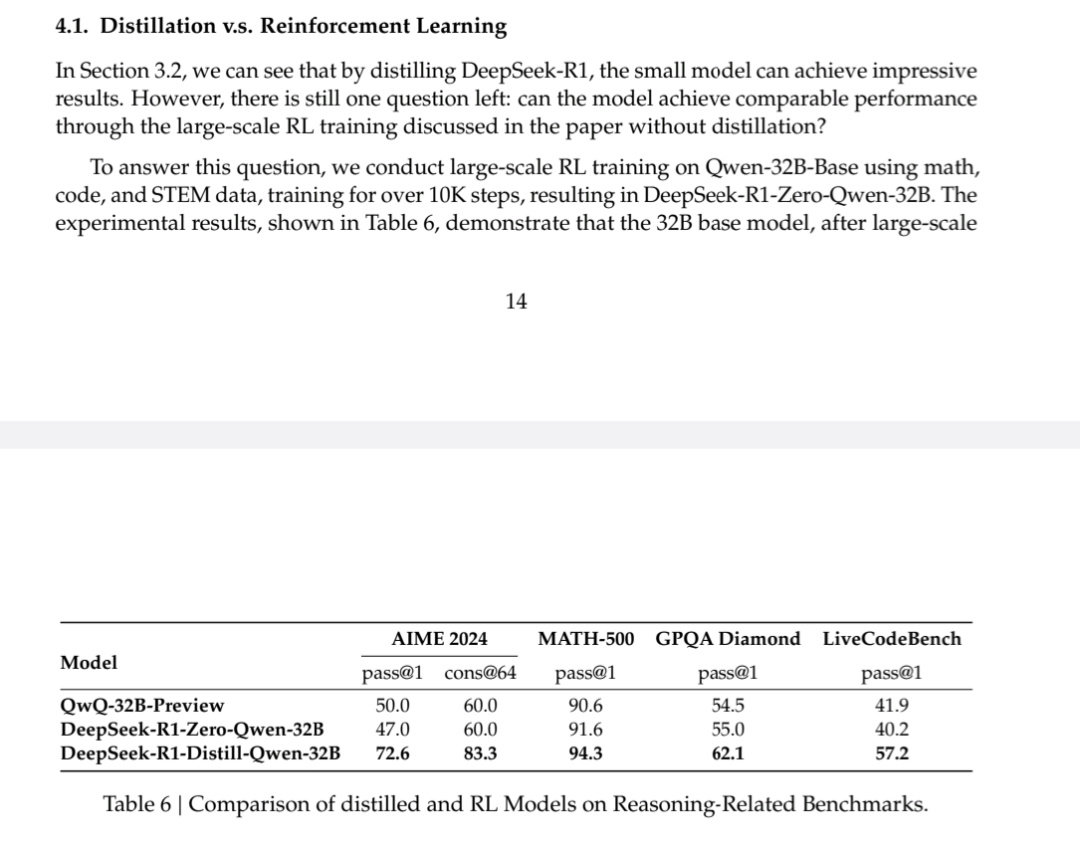
實際上,早在幾周前, DeepSeek 團隊的研究人員就用這種思路,在原先那個 V3 的基礎上完全靠強化學習搞出來了一個 R1-Zero 版本
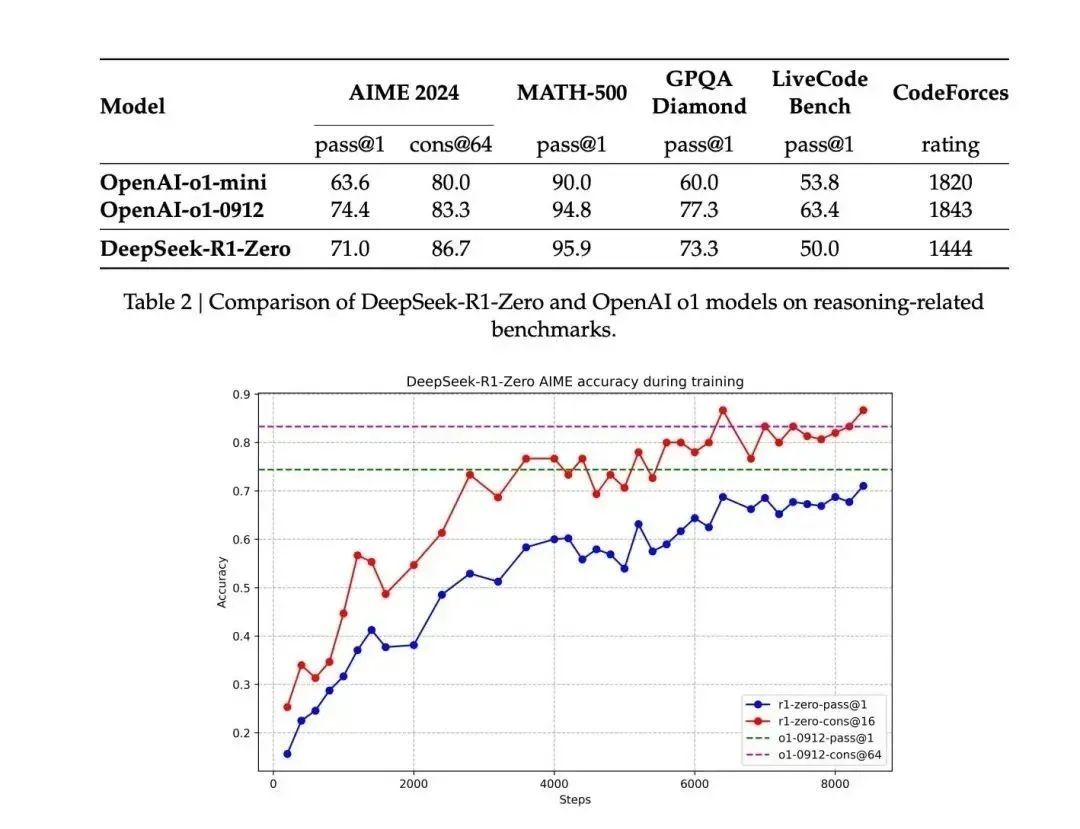
前幾天 DeepSeek 放出來的的技術報告裏提到, Zero 版本在訓練中進化速度非常明顯,很快就能跟 OpenAI-o1 掰掰手腕了,在部分測試項目中甚至還高於 o1 。
除了推理能力在明顯進步,Zero 甚至在推理中表現出了主動覆盤反思糾錯的行爲,在做題的過程中它突然就意識到自己做錯了,然後開始回頭演算。
官方的備註裏說,大模型在這裏突然用了一個擬人化的說法 aha moment ( 頓悟時刻 ),不僅 Zero“ 頓悟了 ” 了,研究人員看到這的時候也 “ 頓悟了 ” 。

當其他 AI 還在背公式時, Zero 已經學會在草稿紙上畫輔助線了,這完全可以說是 AI 推理上的里程碑事件:
沒有預先的數據標註、沒有微調,僅僅只靠模型的強化學習,模型就可以湧現出這個程度的推理能力。
這相當於給全世界搞 AI 的人上了一課,原來還可以這麼玩。。。

雖然推理能力已經被證明了,不過 Zero 的缺點也很明顯。
純強化學習養出來的 AI ,活脫脫就是個鋼鐵直男,模型輸出的可讀性較差,或者說,講話不怎麼符合人類預期。
這就好比一個偏科天才,數學題解得出神入化,但表達能力堪憂,讓它寫篇小作文,分分鐘給你整出《 三體 》 ETO 既視感。
這時候就到了 SFT 上場表演的時候了, DeepSeek 團隊在 Zero 強而有力的推理基礎上,又增加了一部分 SFT 訓練來讓模型會說人話,於是, DeepSeek-R1 堂堂誕生!

神奇的是,在 Zero 基礎上經過這麼一套 " 文理雙修 " 的騷操作後,優化後的 R1 推理能力甚至還進一步提高了,還是看測試數據:
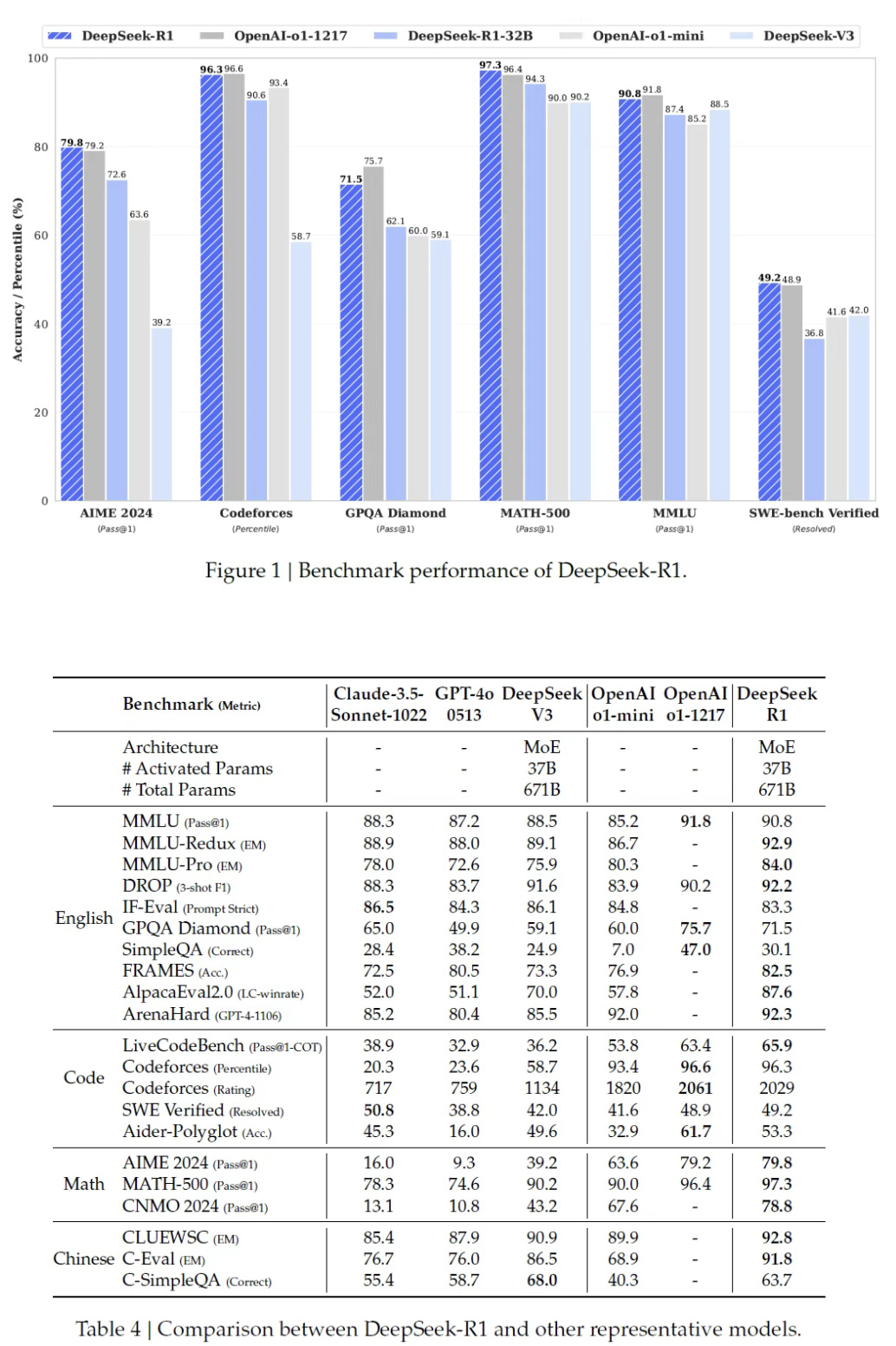
STEM 測評中的數學題目正確率達到了 97.3% ,比 OpenAI-o1 還高一點,遙遙領先了屬於是;代碼測試中 R1 也高達 65.9% ,遠超 Claude-3.5-Sonnet 的 38.9% 和 GPT-4o 的 32.9% ;
MMLU 和 AlpacaEval 2.0 綜合知識測試中, R1 的勝率分別達到 90.8% 和 87.6% ,力壓一衆閉源大模型。
用 Yann Lecun 的話說,這波是開源的偉大勝利!這下誰還敢說開源就是落後啊。( 戰術後仰 )
不過要說 R1 的成功還只是證明了開源模型的實力,那 R1 技術報告最後一部分纔是最離譜的。。。

在這部分他們說到,把 R1 的 SFT 數據蒸餾,餵給其他小模型進行 SFT ,會給其他開源模型來一波超級加強。
也就是說,只要把 R1 的 " 學習筆記 " 做成教輔資料,打包餵給其他的小模型 AI ,讓它們也跟着抄作業,學會這些好學生的作業思路,結果居然能提高小模型的水平!

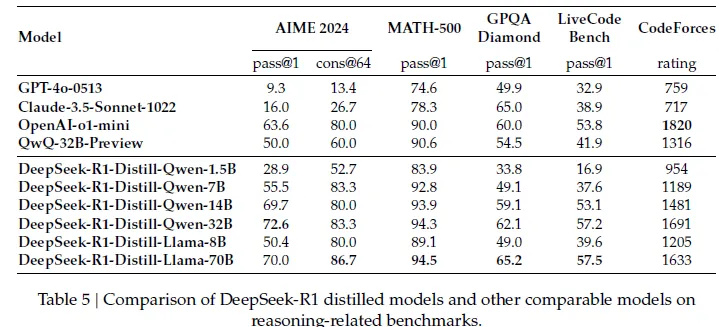
比如說把 R1 的錯題本發給 Qwen 和 Llama 架構,結果抄完作業的 Qwen-7B 模型,在 AIME 測試中通過率達到了 55.5% ,已經趕上了參數體量大了快 5 倍的 QwQ-32B-Preview ( 50.0% );
像 70B 參數版看完了學霸筆記以後也跟打通了任督二脈似的,在 GPQA Diamond ( 65.2% )、 LiveCodeBench ( 57.5% )等任務中甚至閉都能跟閉源模型 o1-mini 掰掰手腕。
換句話說, DeepSeek 這波這不僅驗證了 " 小模型 + 好老師 " 的技術路線,更讓個人開發者也能調教出匹敵 GPT-4 的 AI 。

小模型只需要按優秀大模型搞 SFT 抄作業就行了,壓根不需要再在上面搞機器學習燒顯卡。
於是現在全球開源社區已經瘋了, HuggingFace 連夜成立項目組,準備復刻整個訓練流程。不少網友都說這特麼的纔算 Open !這個項目也被叫做 Open R1 。
也有網友算過賬:用 R1 方案訓練 7B 模型,成本從百萬美元級直接砍到二十萬級別,顯卡用量比挖礦還省,這簡直是真正的科技平權行爲,活該它爆火!
巧合的是,跟 R1 這波爆火同時,衆多賽博基建大廠們的股價開始下跌,英偉達盤前跌了 10% 以上。不少人覺得或許是因爲 DeepSeek 的逆天訓練成本,影響了投資人的判斷。
不過在海的這頭,這樣一個完全由中國團隊做出來的爆火產品,卻再一次向世界證明了中國年輕人的潛力和開創精神。
就像梁文鋒說的, “ 我們經常說中國 AI 和美國有一兩年差距,但真實的 gap 是原創和模仿之差……有些探索也是逃不掉的。 ”
“ 中國AI不可能永遠處在跟隨的位置。 ”
順帶一提,今天小紅書上有網友被DeepSeek的性能嚇到了,擔心自己被AI取代,而當她向DeepSeek 表達出擔憂後,它給出了這樣的回答:

撰文:納西
編輯:江江 & 面線
美編:陽光
圖片、資料來源:
DeepSeek-R1 : Incentivizing Reasoning Capability in LLMs viaReinforcement Learning
暗湧 Waves :揭祕 DeepSeek : 一個極致的中國理想技術主義故事
機器學習算法與自然語言處理:大模型 SFT 的 100 個關鍵點
深度學習與 NLP ,新智元, X 等,部分圖源網絡

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















