大家好,我是加勒比考斯。
Stable Diffusion是一款基于人工智能的图像生成工具,它能够根据用户提供的文本描述生成相应的图像。这款工具使用了先进的深度学习算法,特别适合设计师、艺术家以及任何对AI艺术感兴趣的人。本教程将带领你了解Stable Diffusion的基本概念,并指导你完成从安装到生成图像的整个过程。
Stable Diffusion最大的特征,就是由于其开源的特性,可以在电脑本地上离线运行,生成速度快,且对硬件要求相对较低。这是AI绘画第一次能在可以在消费级显卡上运行,任何人都可以下载模型并生成自己的图像。另外,相比较于midjourney等封闭系统的AI绘图软件,Stable Diffusion强大的自由度(自定义、个性化)也受到很多业内人士的追捧。



生成的图片只要用对配置,基本均可达到个人预期。
Stable Diffusion的主要功能:
文本转图像生成:最常见和最基础的功能。Stable Diffusion 会根据文本提示生成图像。
图像转图像生成:使用输入图像和文本提示,您可以根据输入图像创建新图像。典型的案例是使用草图和合适的提示。
创作图形、插图和徽标:使用一系列提示,可以创建各种风格的插图、图形和徽标。
图像编辑和修正:可以使用 Stable Diffusion 来编辑和修正照片。例如,可以修复旧照片、移除图片中的对象、更改主体特征以及向图片添加新元素。
视频创作:使用 GitHub 中的 Deforum 等功能,可以借助 Stable Diffusion 创作短视频片段和动画。另一种应用是为电影添加不同的风格。 还可以通过营造运动印象(例如流水)来为照片制作动画。
需要注意的是,Stable Diffusion对电脑的配置是有要求的。

以上是最低的要求,但是真的以这个配置来,肯定生成效率极低。
随着年初40系Super显卡发布,无论是AIGC玩家与游戏玩家都已经瞄准4070TiSuper了,这张卡作为4070Ti的升级版本,加量不加价,相对来说性价比最高,同时也是2K游戏随便跑、4K游戏守门员级别的存在。今天,我们使用英特尔14700K,金百达DDR5 6800 24GB*2、技嘉Z7907冰雕X以及乔思伯的鱼缸机箱来试试AIGC效果咋样。

显卡我用的是技嘉雪鹰RTX 4070 Ti SUPER AERO OC 16G,由技嘉(GIGABYTE)公司生产,基于NVIDIA的Ampere架构。这款显卡专为追求极致游戏体验和高效能需求的用户设计,提供了强大的图形处理能力。它拥有大量的CUDA核心,能够处理复杂的图形任务和并行计算任务。同时配备了16GB GDDR6显存,能够轻松应对高分辨率和大型游戏场景的数据需求。

在核心性能方面,技嘉RTX 4070 Ti SUPER雪鹰显卡搭载了AD103-275芯片以及16GB GDDR6X显存的超实力组合。得益于全新升级的架构,该显卡在4nm工艺下相近的面积内实现了约3倍晶体管的集成度,拥有66个SM单元、8448个CUDA核心,并能支持最新的SER和DLSS 3。因此,无论是在4K分辨率游戏还是常规内容创作负载方面,这款显卡都能轻松应对。显存方面,技嘉RTX 4070 Ti SUPER雪鹰显卡采用了源自美光的GDDR6X显存,共计8颗,每颗容量为2GB,总显存容量达到16GB,显存带宽高达672GB/s。
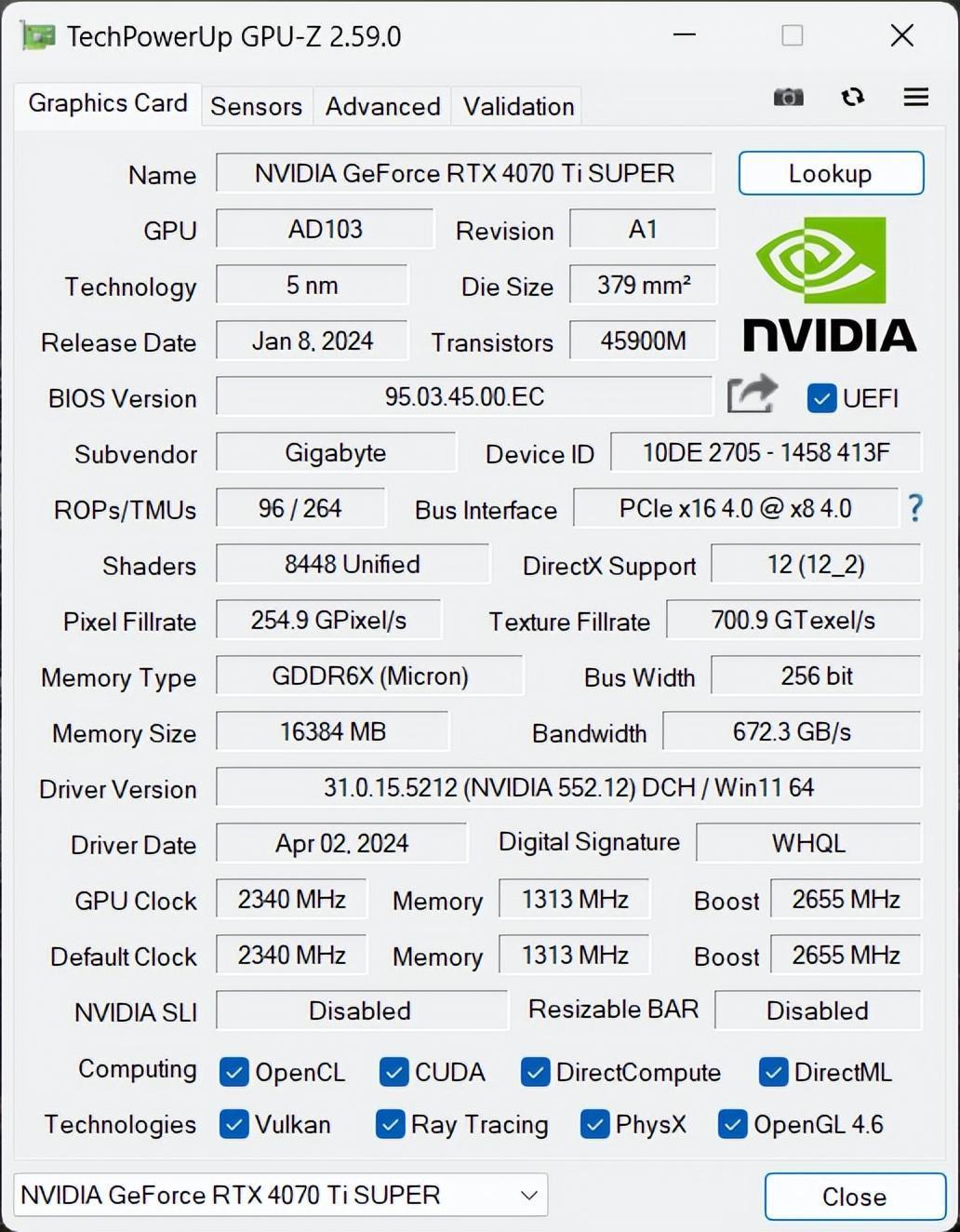
根据GPU-Z,我们可以看到技嘉RTX 4070 Ti SUPER雪鹰的核心Bosst频率达到了2655MHz。

它的散热采用了技嘉独特的雪鹰散热技术,包括大面积散热片和三个90mm的大直径风扇,支持正逆转设计和智能启停功能,有效提升散热效率并降低噪音,确保显卡在高负载下也能保持低温运行。

紧接着是性能优化部分,AERO OC版本意味着这款显卡经过了技嘉的特殊超频处理,相比标准版能够提供更高的性能。技嘉提供了自家的超频软件,允许用户根据需要调整显卡的性能设置,以达到最佳的性能和稳定性平衡。

除了上述规格之外,技嘉RTX 4070 Ti SUPER雪鹰基于Ada Lovelace架构还具备以下关键特性:
1.采用TSMC 4N工艺,晶体管集成度更高,规模更强,能耗比更优异;
2.Ada架构采用了第三代光线追踪模块,具备Opacity Micromap、DMME以及SER等新技术,大幅度提升了光线追踪计算效率;
3.采用了第四代AI张量核心,拥有支持AV1格式的第八代NVENC编码器;
4.支持全新的DLSS 3.5技术,在DLSS 2的基础上增加了Frame Generation帧生成功能,能够在DLSS 2的基础上将游戏帧率再翻倍,并且不影响整体画质,同时还增加了增强光追游戏画质的光线重建功能;
5.面向设计师群体进行了相关升级,包括Studio、Racer RTX以及RTX REMIX;
我之前一直以为Stable Diffusion很难安装,但自己尝试了一次之后才发现,原来本地安装其实非常简单。
下载安装包我选择的是秋叶大神开发的Stable Diffusion整合包,只需要把整合包下载到电脑上,就可以一键安装了。
解压完文件,点击绘世启动器,接下来就可以全自动安装了。安装过程中,需要先安装启动器所需要的环境,整个过程大概只需要几分钟即可完成。

安装完成之后,可以把绘世启动器发送到桌面快捷方式,这样下次直接点击快捷方式就可以一键启动Stable Diffusion了。
注意的是,如果有安装老版本的Stable Diffusion,可以选择版本管理,可以一键更新到最新版本。
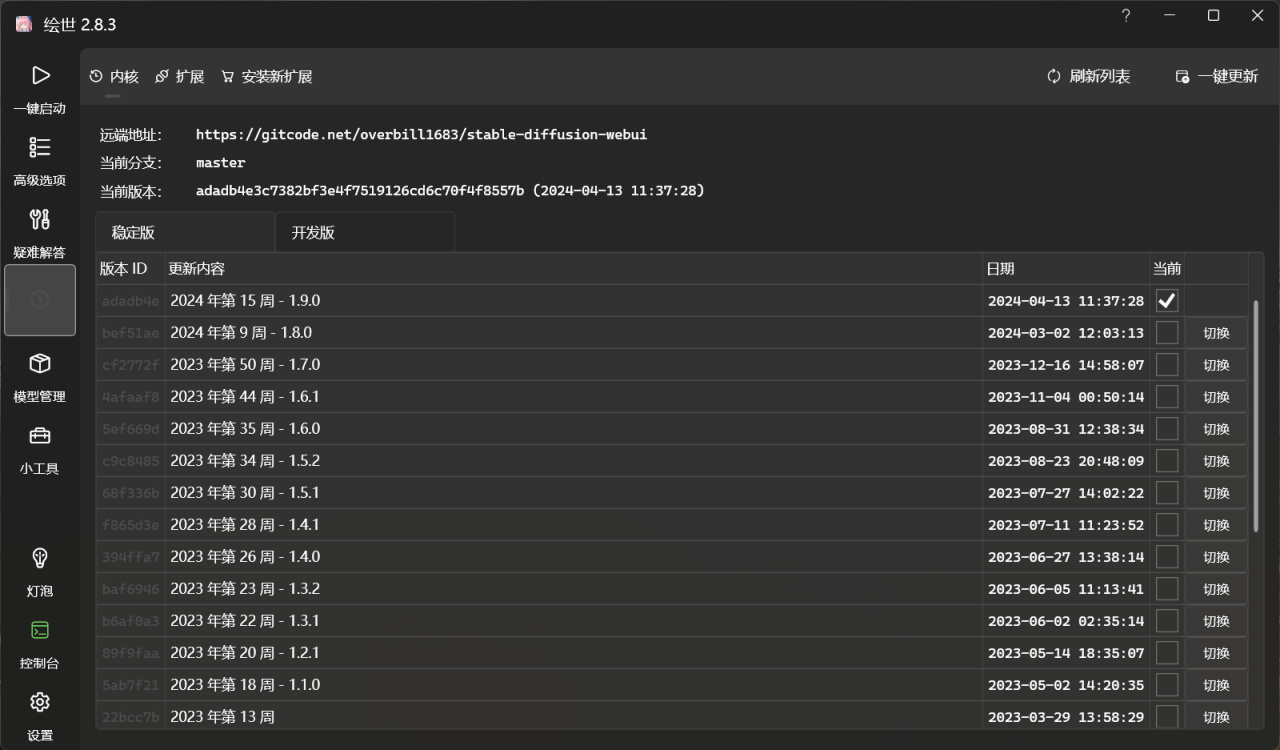
点击一键启动,会自动在浏览器当中打开一个网页版的UI页面。这个页面就是我们的操作台了,接下来就可以在里面愉快地进行AI绘画了。
秋叶大神的整合包里包含了anyting-V5模型在内的几个基本的模型,但是没有最新的SDXL模型,因此我单独下载了SDXL模型,只需要存储到整合包文件夹的 models/Stable-diffusion
目录内,重新启动即可一键加载。
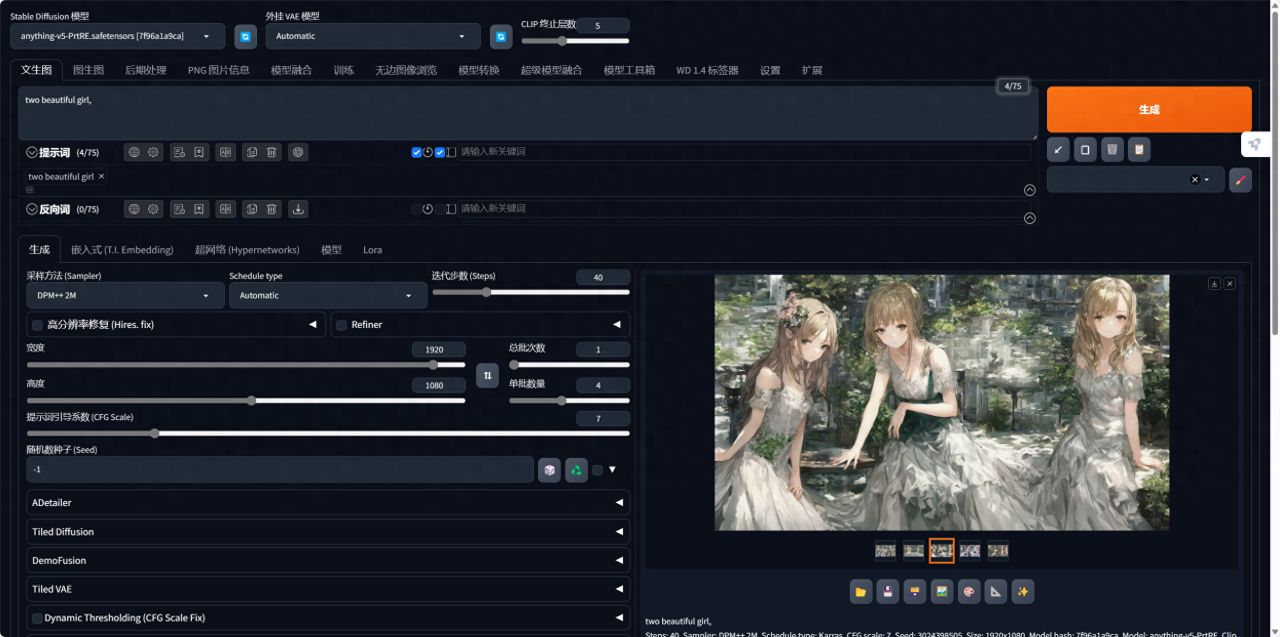
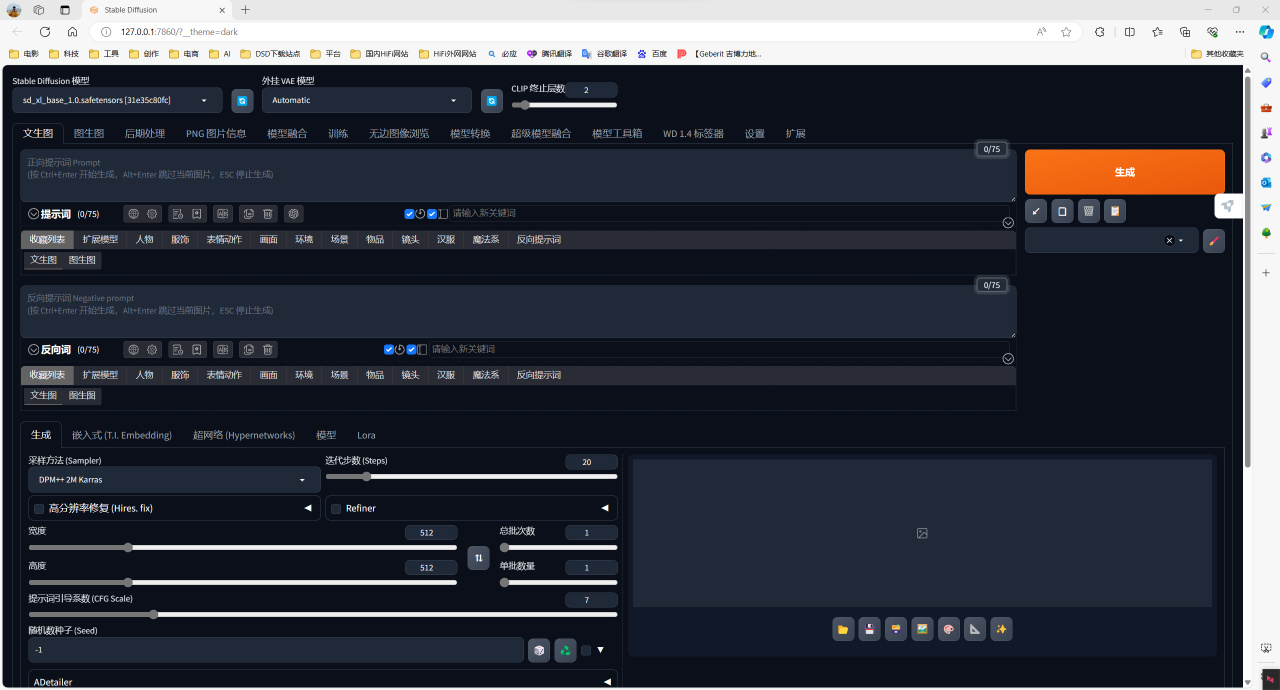
Stable Diffusion 的关键就是在于设置【提示词】和【负向提示词】,AI 会根据提示词去匹配模型库中的案例,进而渲染生成特定的图片。我先尝试了「1gril」的简单提示词,分辨率调整为1920*1080,迭代步数为40,可以看到单张耗时在 26.5秒。
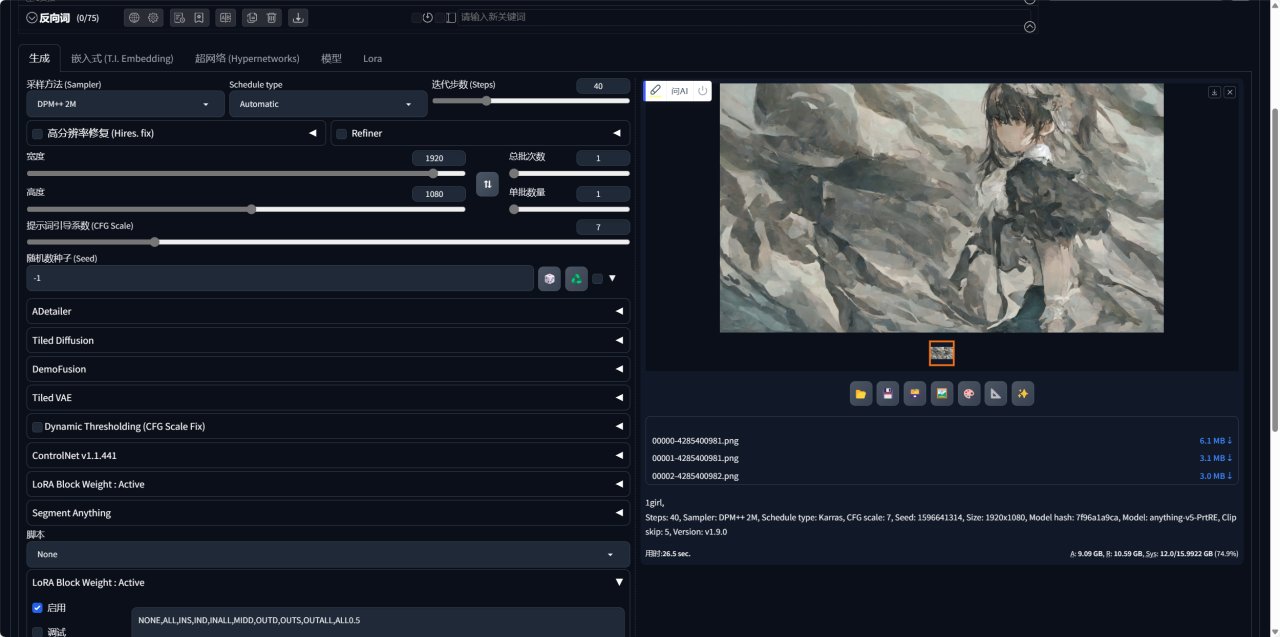
我尝试了 1 批 4 张图,平均单张耗时在26 秒,生成速度可以说相当快了。
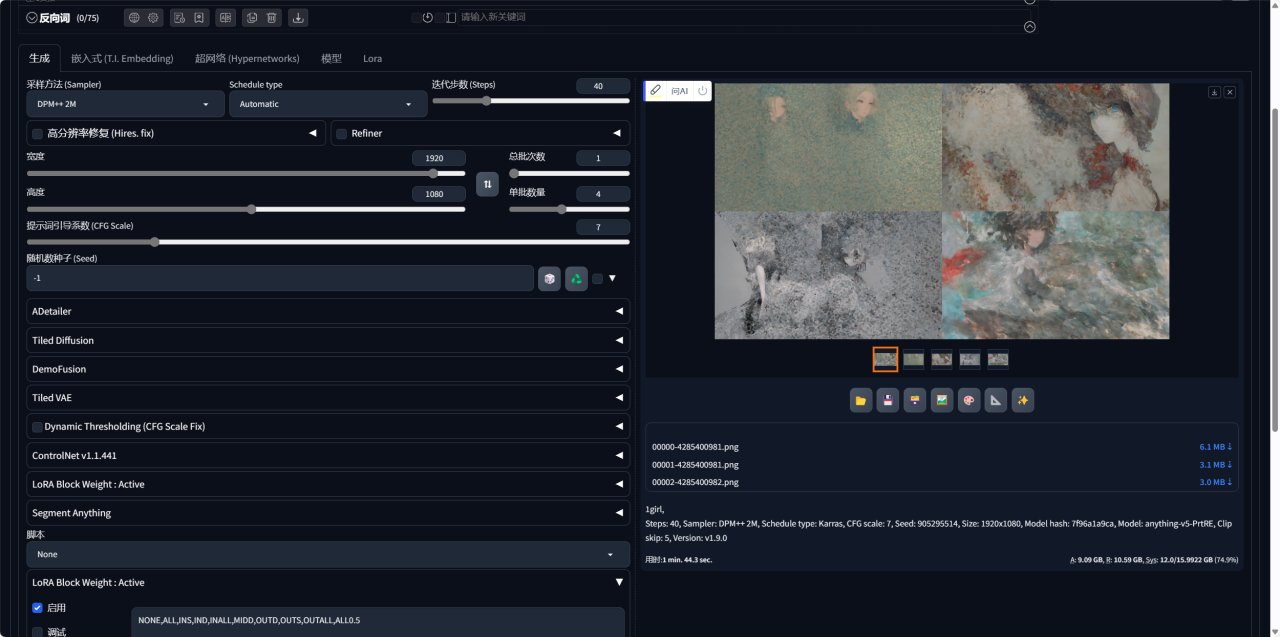
实测生成一张图的时间大概在5秒左右,同时生成4张图,渲染所需时间也基本都在10秒钟之内。

接下来我们上点难度,采用了 Omniinfer 的一套显卡标准测试提示词,将图像长宽设置为512×512,采样迭代步数 100。
「提示词」:A beautiful girl, best quality, ultra-detailed, extremely detailed CG unity 8k wallpaper, best illustration, an extremely delicate and beautiful, floating, high resolution.
「负向提示词」: Low resolution, bad anatomy, bad hands, text error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, bad feet, fused body.
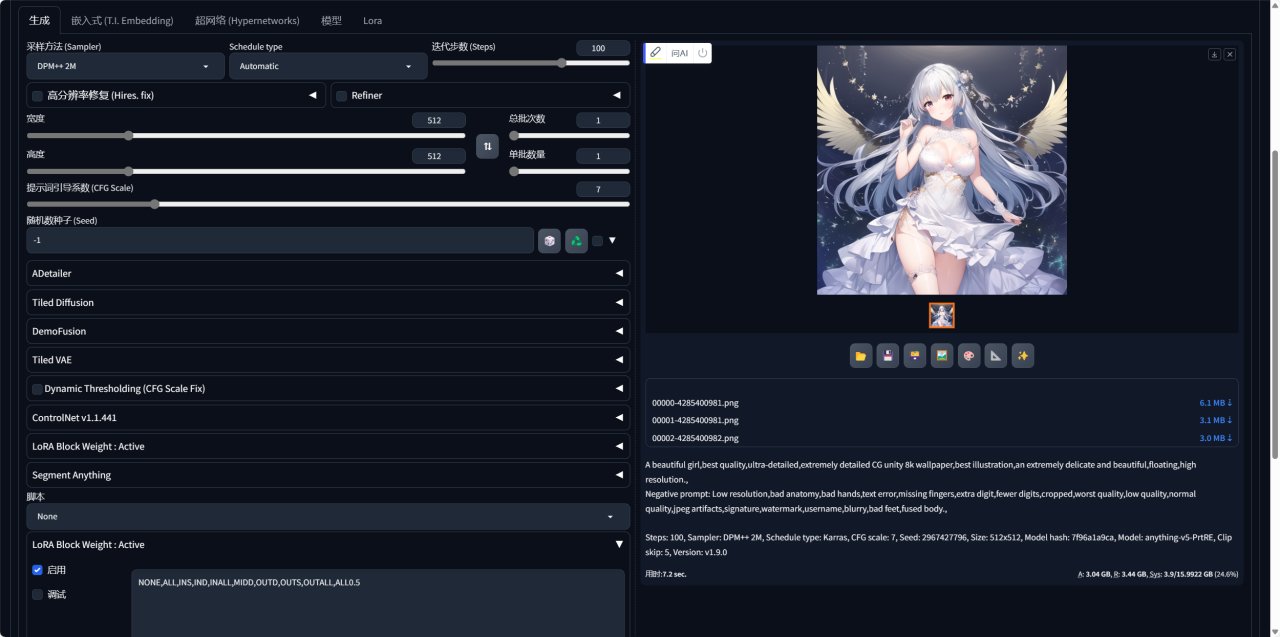
可以看到使用技嘉4070TiS单张耗时在7.2秒,尝试了 1 批 4 张图,平均单张耗时在4.4 秒,表现极佳。

当然如果想要生成更好的效果,还可以自己下载更多的预训练模型,网上已经有很多大神调教好的相关模型, CivitAI(俗称 C 站, )是业内比较成熟的一个 Stable Diffusion 模型社区,上面汇集了上千个模型,以及上万张附带提示词的图像,出图效果非常哇塞,大家可以自己去挑选自己喜欢的模型。
CivitAI 上的模型主要分为四类:Checkpoint、LoRA、Textual Inversion、Hypernetwork,通常情况 Checkpoint 模型搭配 LoRA 或 Textual Inversion 模型使用,可以获得更好的出图效果。
Checkpoint模型存放路径:/stabl-diffusio-webui/models/Stable-diffusion
LoRA模型存放径:/stable-diffusion-webui/models/Lora
Tetual Inversion模型存放路径:/stable-diffusion-webui/embeddings

此外,还值得一提的是一个插件工具,TensorRT,它可以对stable diffusion进行推理加速。
TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个C++推理框架。我们利用Pytorch、TF或者其他框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行我们这个模型,从而提升这个模型在英伟达GPU上运行的速度。速度提升的比例是比较可观的。
借官方的话来说:
“The core of NVIDIA TensorRT is a C++ library that facilitates high-performance inference on NVIDIA graphics processing units (GPUs). TensorRT takes a trained network, which consists of a network definition and a set of trained parameters, and produces a highly optimized runtime engine that performs inference for that network. TensorRT provides API's via C++ and Python that help to express deep learning models via the Network Definition API or load a pre-defined model via the parsers that allow TensorRT to optimize and run them on an NVIDIA GPU. TensorRT applies graph optimizations, layer fusion, among other optimizations, while also finding the fastest implementation of that model leveraging a diverse collection of highly optimized kernels. TensorRT also supplies a runtime that you can use to execute this network on all of NVIDIA’s GPU’s from the Kepler generation onwards. TensorRT also includes optional high speed mixed precision capabilities introduced in the Tegra™ X1, and extended with the Pascal™, Volta™, Turing™, and NVIDIA® Ampere GPU architectures.”
翻译如下:
“NVIDIA TensorRT的核心是一个C++库,它有助于在NVIDIA图形处理单元(GPU)上进行高性能推理。TensorRT接受一个训练好的网络,该网络由一个网络定义和一组训练好的参数组成,并生成一个高度优化的运行时引擎,为该网络执行推理。TensorRT通过C++和Python提供API,帮助使用网络定义API表达深度学习模型,或者通过允许TensorRT优化并在NVIDIA GPU上运行它们的解析器加载预定义模型。TensorRT应用图优化、层融合等优化,同时还找到该模型的最快实现,利用多样化的高度优化内核集合。TensorRT还提供了一个运行时,您可以在所有NVIDIA的GPU上从Kepler一代开始执行这个网络。TensorRT还包括在Tegra™X1中引入的可选高速混合精度功能,并通过Pascal™、Volta™、Turing™和NVIDIA®Ampere GPU架构扩展。”
2023年10月18日Nvidia终于推出了官方的TensorRT插件Stable-Difusion-WebUl-TensorRT,该插件可以直接在 webui的 extension 中安装即可,默认支持cuda11.x。
环境配置要求
要使用Stable-Difusion-WebUl-TensorRT插件加速,有几个重要的前提条件,GPU必须是NVIDIA的(俗称N卡),GPU的显存必须在8G以上,包含8G,GPU驱动版本大于等于537.58,如果电脑没有别的深度学习模型要训练,建议驱动更新到最新的版本。物理内存大于等于16G。
支持Stable-Diffusion1.5.2.1.SDXL,SDXL Turbo和 LCM,对干 SDXL和 SDXL Turbo,官方推荐使用具有12GB 或更多 VRAM 的GPU,以获得最佳性能。
操作步骤:
1、首先进入Stable-Difusion-WebUl-TensorRT插件的github页面,复制项目地址。

2、接下来启动WEBUI,无论你是通过 Github 安装还是秋叶安装,都会有extensions插件的标签,进入打开Extensions插件或者“拓展”选项,打开从网址安装,黏贴刚才的项目地址。
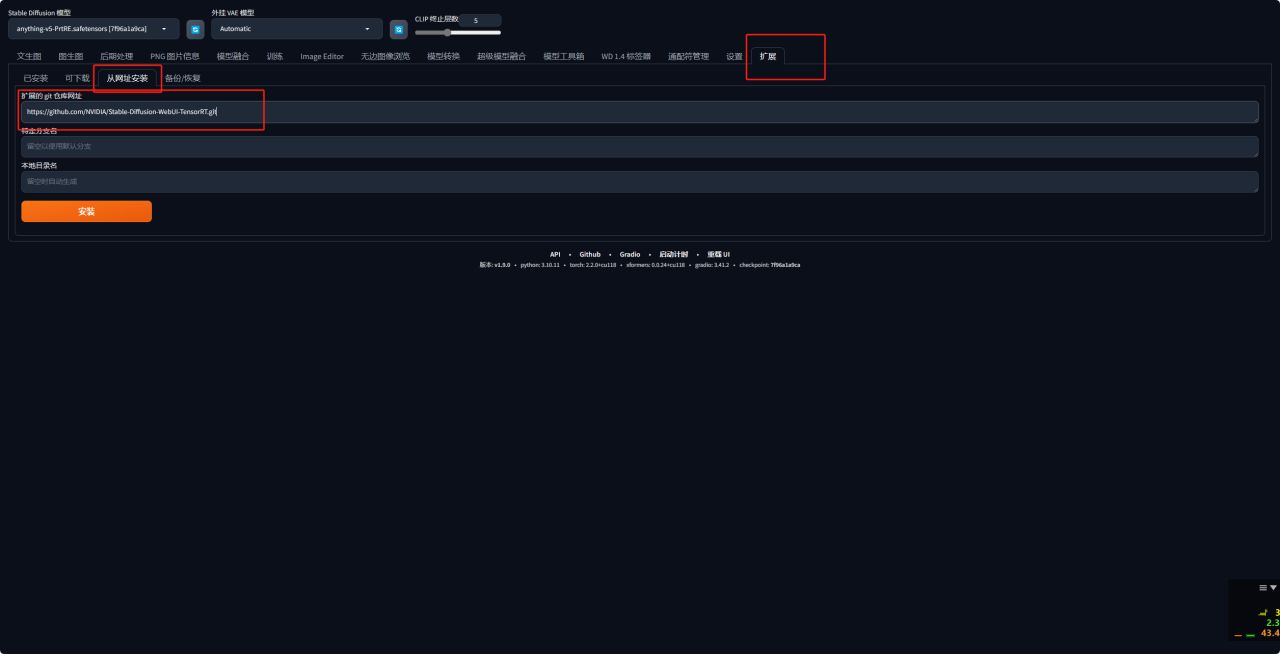
3、安装完成后点击应用更改并重启即可。
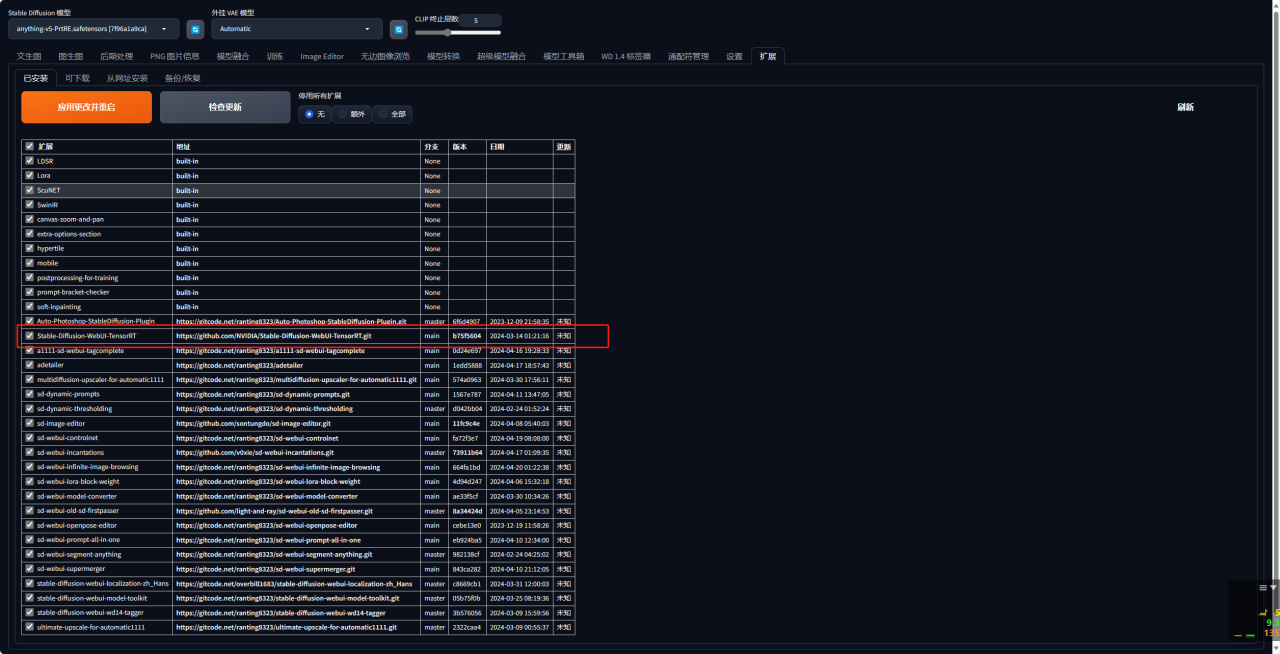
4、再次打开页面后就可以看到WebUI里会多了一个TensorRT 的页面。
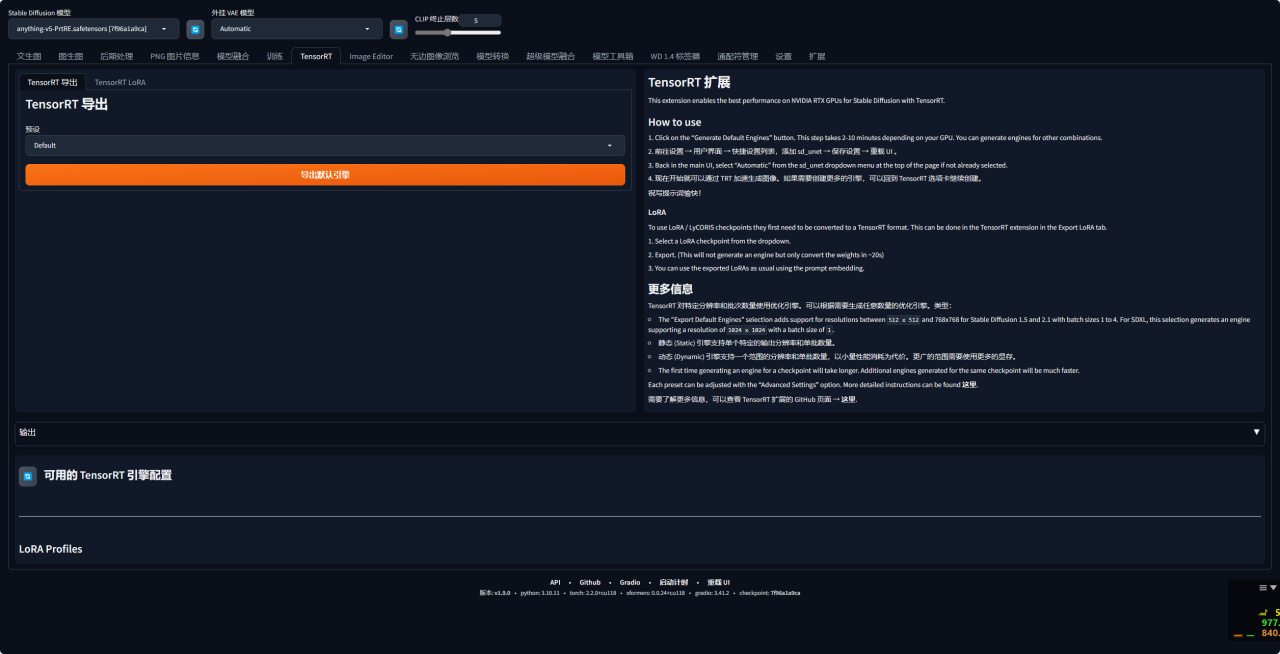
5、如何使用?
首先咱们需要知道这个原理。
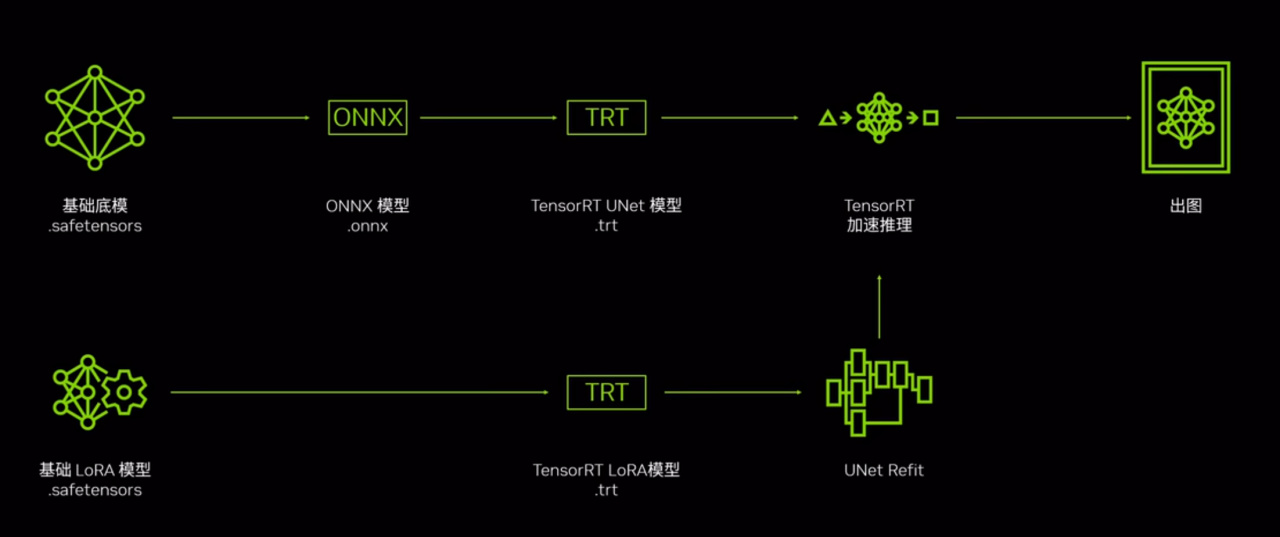
第一步,我们首先需要使用底模构建 TensorRT 模型,构建的过程是 TensorRT 的插件会自动的由底模输出 ONNX 模型,并构建一个以trt为后缀的 UNet 优化模型,在得到这个模型之后 我们就可以使用这个trt优化的 UNet 模型进行推理加速了。
而对于 LORA而言,则需要将使用的 LORA 模型也进行 TensorRT 模型的构建,再通过正常的 LORA的使用方法 TensorRT 的插件会自动将 LORA的 TensorRT 优化模型与底模的 UNet TensorRT 优化模型进行融合,来完成底模加上 LORA 的加速。
6、接下来选择想要导出的底模,你可以选择任意支持的底模,接下来我们打开 Preset 下拉框,这里会提供多个 Stable Diffusion 模型的预设推理参数,自己选择好就好。

7、接着前往设置→用户界面→快捷设置列表,添加 sd _unet→ 保存设置→ 重载 UI。
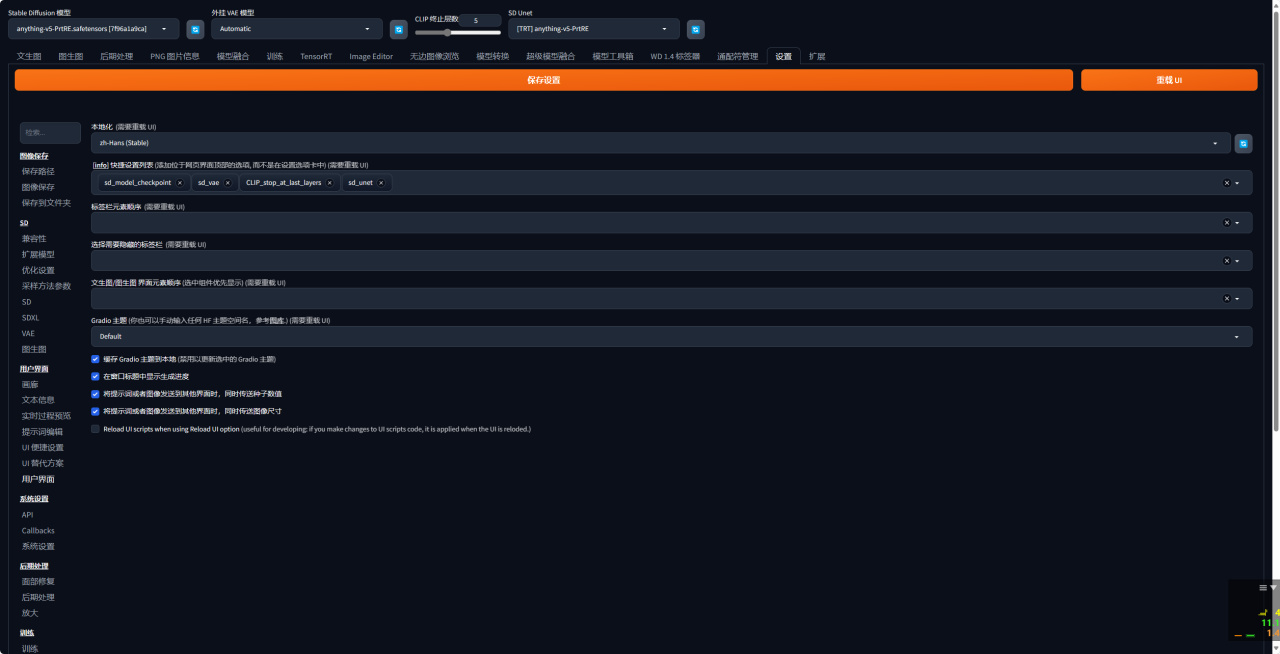
8、完成后WEBUI会多一个SD Unet的设置项。在这里可以选择使用TRT加速。

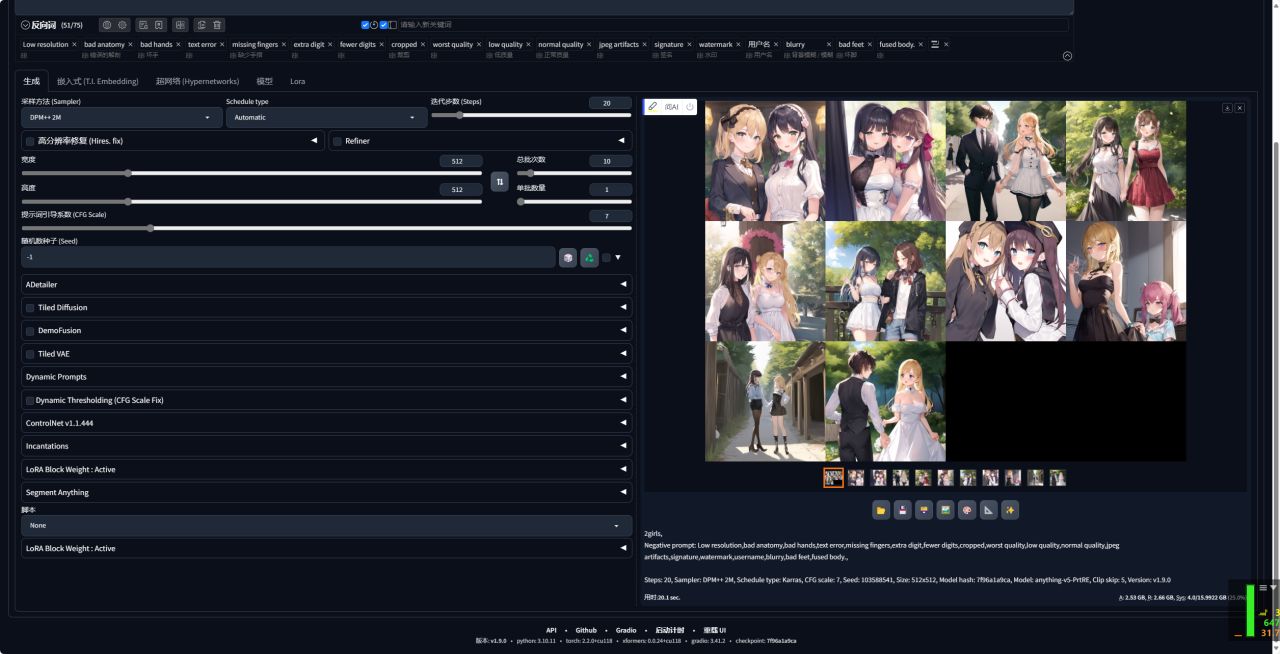
9、首先我们选择不加速,生成10张图片,用时20.1秒。
然后再选择使用TRT加速,生成10张图片,用时16秒。
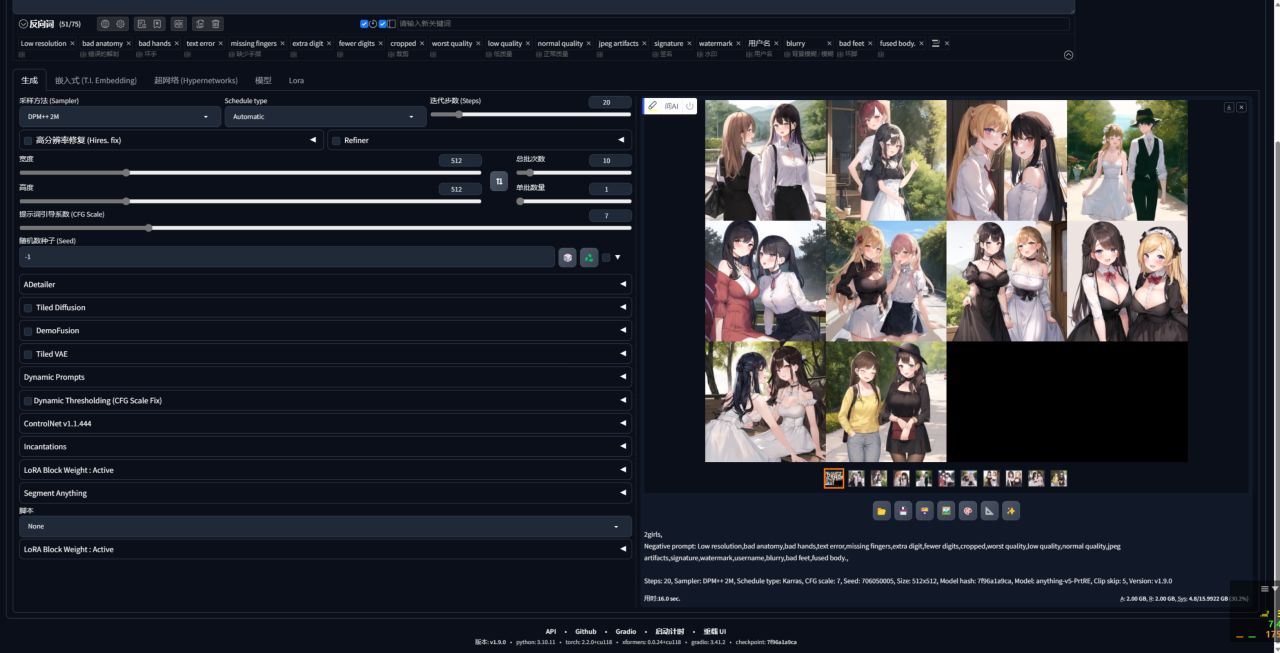
10、我们选择不加速,生成20张图片,用时38.1秒。
然后再选择使用TRT加速,生成20张图片,用时27.2秒。
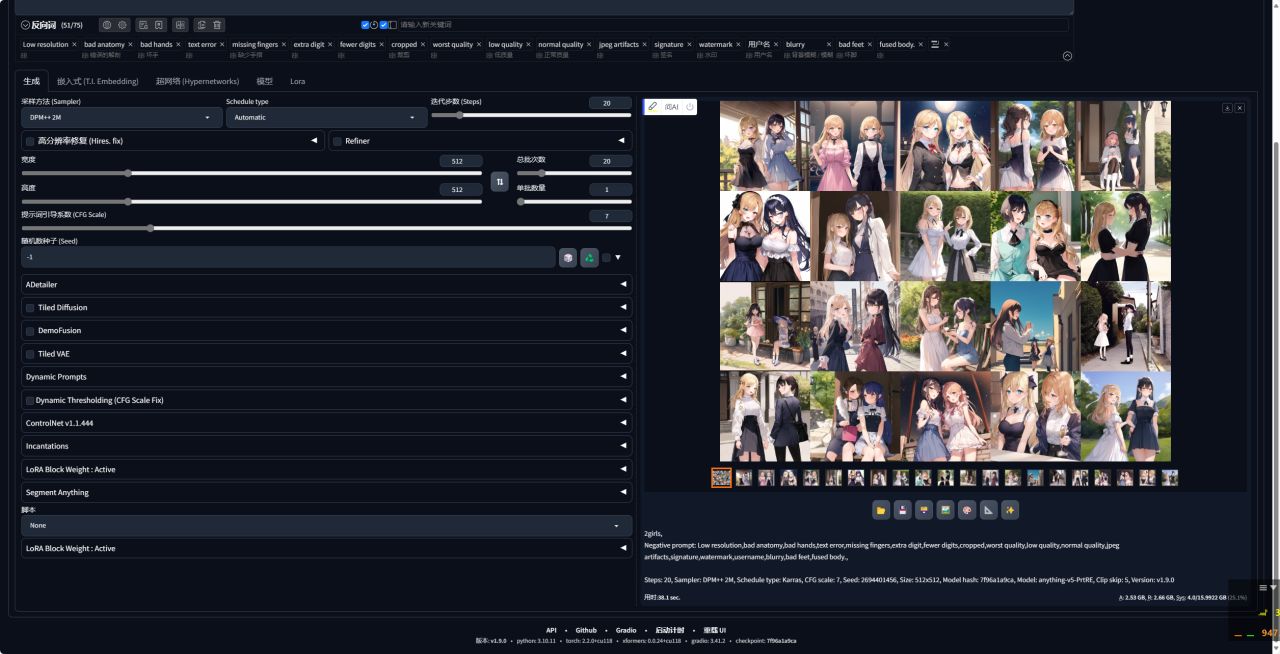

使用TensorRT插件后,Stable Diffusion生成效率提升较大。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com













![IGN 9 分实至名归!一篇文章告诉你《黑旗 记忆重置》都[重置]了啥](https://imgheybox1.max-c.com/web/bbs/2026/07/08/0ba0251830d443c28879a959b36bd994.png?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)


